 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing What You Say: Expressive Image Generation from Speech
Nov 05, 2025



This paper proposes VoxStudio, the first unified and end-to-end speech-to-image model that generates expressive images directly from spoken descriptions by jointly aligning linguistic and paralinguistic information. At its core is a speech information bottleneck (SIB) module, which compresses raw speech into compact semantic tokens, preserving prosody and emotional nuance. By operating directly on these tokens, VoxStudio eliminates the need for an additional speech-to-text system, which often ignores the hidden details beyond text, e.g., tone or emotion. We also release VoxEmoset, a large-scale paired emotional speech-image dataset built via an advanced TTS engine to affordably generate richly expressive utterances. Comprehensive experiments on the SpokenCOCO, Flickr8kAudio, and VoxEmoset benchmarks demonstrate the feasibility of our method and highlight key challenges, including emotional consistency and linguistic ambiguity, paving the way for future research.
Listen through the Sound: Generative Speech Restoration Leveraging Acoustic Context Representation
Aug 12, 2025This paper introduces a novel approach to speech restoration by integrating a context-related conditioning strategy. Specifically, we employ the diffusion-based generative restoration model, UNIVERSE++, as a backbone to evaluate the effectiveness of contextual representations. We incorporate acoustic context embeddings extracted from the CLAP model, which capture the environmental attributes of input audio. Additionally, we propose an Acoustic Context (ACX) representation that refines CLAP embeddings to better handle various distortion factors and their intensity in speech signals. Unlike content-based approaches that rely on linguistic and speaker attributes, ACX provides contextual information that enables the restoration model to distinguish and mitigate distortions better. Experimental results indicate that context-aware conditioning improves both restoration performance and its stability across diverse distortion conditions, reducing variability compared to content-based methods.
Speak in the Scene: Diffusion-based Acoustic Scene Transfer toward Immersive Speech Generation
Jun 18, 2024This paper introduces a novel task in generative speech processing, Acoustic Scene Transfer (AST), which aims to transfer acoustic scenes of speech signals to diverse environments. AST promises an immersive experience in speech perception by adapting the acoustic scene behind speech signals to desired environments. We propose AST-LDM for the AST task, which generates speech signals accompanied by the target acoustic scene of the reference prompt. Specifically, AST-LDM is a latent diffusion model conditioned by CLAP embeddings that describe target acoustic scenes in either audio or text modalities. The contributions of this paper include introducing the AST task and implementing its baseline model. For AST-LDM, we emphasize its core framework, which is to preserve the input speech and generate audio consistently with both the given speech and the target acoustic environment. Experiments, including objective and subjective tests, validate the feasibility and efficacy of our approach.
MF-PAM: Accurate Pitch Estimation through Periodicity Analysis and Multi-level Feature Fusion
Jun 16, 2023We introduce Multi-level feature Fusion-based Periodicity Analysis Model (MF-PAM), a novel deep learning-based pitch estimation model that accurately estimates pitch trajectory in noisy and reverberant acoustic environments. Our model leverages the periodic characteristics of audio signals and involves two key steps: extracting pitch periodicity using periodic non-periodic convolution (PNP-Conv) blocks and estimating pitch by aggregating multi-level features using a modified bi-directional feature pyramid network (BiFPN). We evaluate our model on speech and music datasets and achieve superior pitch estimation performance compared to state-of-the-art baselines while using fewer model parameters. Our model achieves 99.20 % accuracy in pitch estimation on a clean musical dataset. Overall, our proposed model provides a promising solution for accurate pitch estimation in challenging acoustic environments and has potential applications in audio signal processing.
HD-DEMUCS: General Speech Restoration with Heterogeneous Decoders
Jun 02, 2023



This paper introduces an end-to-end neural speech restoration model, HD-DEMUCS, demonstrating efficacy across multiple distortion environments. Unlike conventional approaches that employ cascading frameworks to remove undesirable noise first and then restore missing signal components, our model performs these tasks in parallel using two heterogeneous decoder networks. Based on the U-Net style encoder-decoder framework, we attach an additional decoder so that each decoder network performs noise suppression or restoration separately. We carefully design each decoder architecture to operate appropriately depending on its objectives. Additionally, we improve performance by leveraging a learnable weighting factor, aggregating the two decoder output waveforms. Experimental results with objective metrics across various environments clearly demonstrate the effectiveness of our approach over a single decoder or multi-stage systems for general speech restoration task.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
MoLE : Mixture of Language Experts for Multi-Lingual Automatic Speech Recognition
Feb 27, 2023Multi-lingual speech recognition aims to distinguish linguistic expressions in different languages and integrate acoustic processing simultaneously. In contrast, current multi-lingual speech recognition research follows a language-aware paradigm, mainly targeted to improve recognition performance rather than discriminate language characteristics. In this paper, we present a multi-lingual speech recognition network named Mixture-of-Language-Expert(MoLE), which digests speech in a variety of languages. Specifically, MoLE analyzes linguistic expression from input speech in arbitrary languages, activating a language-specific expert with a lightweight language tokenizer. The tokenizer not only activates experts, but also estimates the reliability of the activation. Based on the reliability, the activated expert and the language-agnostic expert are aggregated to represent language-conditioned embedding for efficient speech recognition. Our proposed model is evaluated in 5 languages scenario, and the experimental results show that our structure is advantageous on multi-lingual recognition, especially for speech in low-resource language.
Diffusion-based Generative Speech Source Separation
Nov 02, 2022We propose DiffSep, a new single channel source separation method based on score-matching of a stochastic differential equation (SDE). We craft a tailored continuous time diffusion-mixing process starting from the separated sources and converging to a Gaussian distribution centered on their mixture. This formulation lets us apply the machinery of score-based generative modelling. First, we train a neural network to approximate the score function of the marginal probabilities or the diffusion-mixing process. Then, we use it to solve the reverse time SDE that progressively separates the sources starting from their mixture. We propose a modified training strategy to handle model mismatch and source permutation ambiguity. Experiments on the WSJ0 2mix dataset demonstrate the potential of the method. Furthermore, the method is also suitable for speech enhancement and shows performance competitive with prior work on the VoiceBank-DEMAND dataset.
Learning Audio-Text Agreement for Open-vocabulary Keyword Spotting
Jul 01, 2022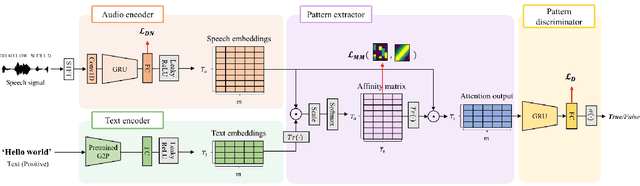
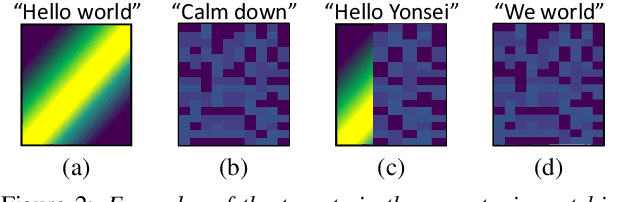

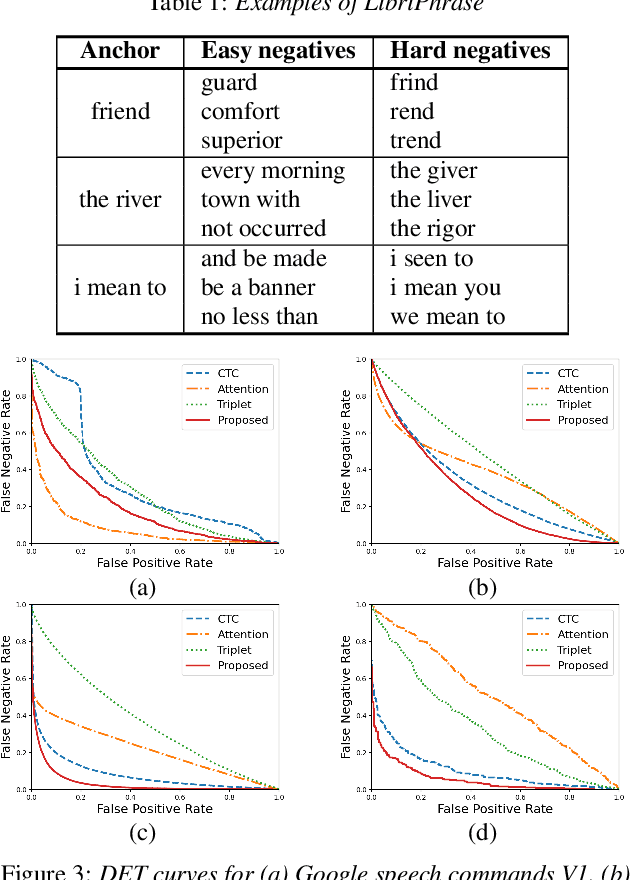
In this paper, we propose a novel end-to-end user-defined keyword spotting method that utilizes linguistically corresponding patterns between speech and text sequences. Unlike previous approaches requiring speech keyword enrollment, our method compares input queries with an enrolled text keyword sequence. To place the audio and text representations within a common latent space, we adopt an attention-based cross-modal matching approach that is trained in an end-to-end manner with monotonic matching loss and keyword classification loss. We also utilize a de-noising loss for the acoustic embedding network to improve robustness in noisy environments. Additionally, we introduce the LibriPhrase dataset, a new short-phrase dataset based on LibriSpeech for efficiently training keyword spotting models. Our proposed method achieves competitive results on various evaluation sets compared to other single-modal and cross-modal baselines.
Baseline Systems for the First Spoofing-Aware Speaker Verification Challenge: Score and Embedding Fusion
Apr 21, 2022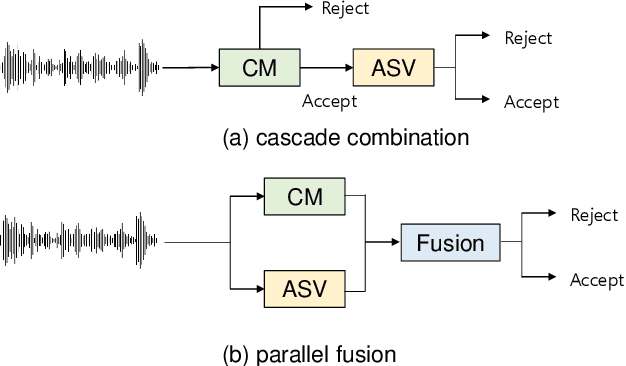

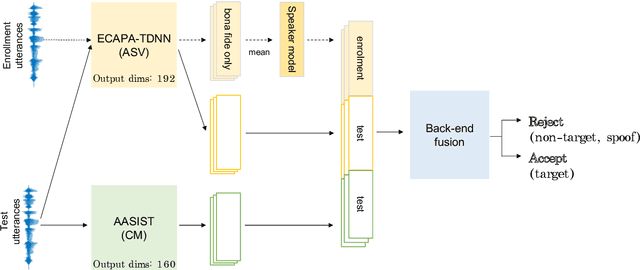
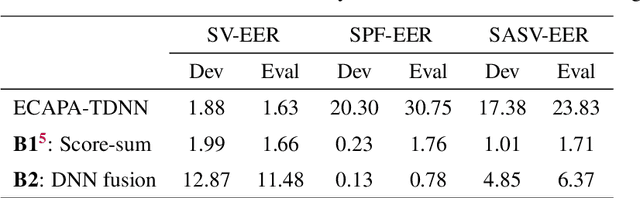
Deep learning has brought impressive progress in the study of both automatic speaker verification (ASV) and spoofing countermeasures (CM). Although solutions are mutually dependent, they have typically evolved as standalone sub-systems whereby CM solutions are usually designed for a fixed ASV system. The work reported in this paper aims to gauge the improvements in reliability that can be gained from their closer integration. Results derived using the popular ASVspoof2019 dataset indicate that the equal error rate (EER) of a state-of-the-art ASV system degrades from 1.63% to 23.83% when the evaluation protocol is extended with spoofed trials.%subjected to spoofing attacks. However, even the straightforward integration of ASV and CM systems in the form of score-sum and deep neural network-based fusion strategies reduce the EER to 1.71% and 6.37%, respectively. The new Spoofing-Aware Speaker Verification (SASV) challenge has been formed to encourage greater attention to the integration of ASV and CM systems as well as to provide a means to benchmark different solutions.