 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Separation by Flow Matching
Paper and Code



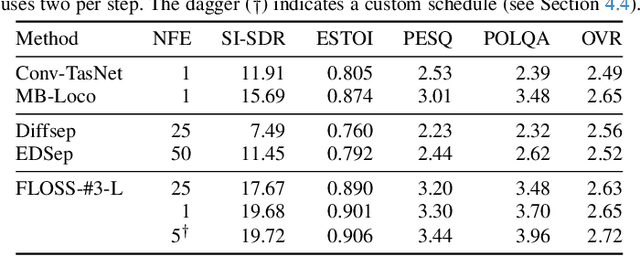
We consider the problem of single-channel audio source separation with the goal of reconstructing $K$ sources from their mixture. We address this ill-posed problem with FLOSS (FLOw matching for Source Separation), a constrained generation method based on flow matching, ensuring strict mixture consistency. Flow matching is a general methodology that, when given samples from two probability distributions defined on the same space, learns an ordinary differential equation to output a sample from one of the distributions when provided with a sample from the other. In our context, we have access to samples from the joint distribution of $K$ sources and so the corresponding samples from the lower-dimensional distribution of their mixture. To apply flow matching, we augment these mixture samples with artificial noise components to ensure the resulting "augmented" distribution matches the dimensionality of the $K$ source distribution. Additionally, as any permutation of the sources yields the same mixture, we adopt an equivariant formulation of flow matching which relies on a suitable custom-designed neural network architecture. We demonstrate the performance of the method for the separation of overlapping speech.