 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-shot Phase Retrieval from a Fractional Fourier Transform Perspective
Nov 18, 2023



The realm of classical phase retrieval concerns itself with the arduous task of recovering a signal from its Fourier magnitude measurements, which are fraught with inherent ambiguities. A single-exposure intensity measurement is commonly deemed insufficient for the reconstruction of the primal signal, given that the absent phase component is imperative for the inverse transformation. In this work, we present a novel single-shot phase retrieval paradigm from a fractional Fourier transform (FrFT) perspective, which involves integrating the FrFT-based physical measurement model within a self-supervised reconstruction scheme. Specifically, the proposed FrFT-based measurement model addresses the aliasing artifacts problem in the numerical calculation of Fresnel diffraction, featuring adaptability to both short-distance and long-distance propagation scenarios. Moreover, the intensity measurement in the FrFT domain proves highly effective in alleviating the ambiguities of phase retrieval and relaxing the previous conditions on oversampled or multiple measurements in the Fourier domain. Furthermore, the proposed self-supervised reconstruction approach harnesses the fast discrete algorithm of FrFT alongside untrained neural network priors, thereby attaining preeminent results. Through numerical simulations, we demonstrate that both amplitude and phase objects can be effectively retrieved from a single-shot intensity measurement using the proposed approach and provide a promising technique for support-free coherent diffraction imaging.
Concealed Electronic Countermeasures of Radar Signal with Adversarial Examples
Oct 12, 2023



Electronic countermeasures involving radar signals are an important aspect of modern warfare. Traditional electronic countermeasures techniques typically add large-scale interference signals to ensure interference effects, which can lead to attacks being too obvious. In recent years, AI-based attack methods have emerged that can effectively solve this problem, but the attack scenarios are currently limited to time domain radar signal classification. In this paper, we focus on the time-frequency images classification scenario of radar signals. We first propose an attack pipeline under the time-frequency images scenario and DITIMI-FGSM attack algorithm with high transferability. Then, we propose STFT-based time domain signal attack(STDS) algorithm to solve the problem of non-invertibility in time-frequency analysis, thus obtaining the time-domain representation of the interference signal. A large number of experiments show that our attack pipeline is feasible and the proposed attack method has a high success rate.
An easy zero-shot learning combination: Texture Sensitive Semantic Segmentation IceHrNet and Advanced Style Transfer Learning Strategy
Sep 30, 2023



We proposed an easy method of Zero-Shot semantic segmentation by using style transfer. In this case, we successfully used a medical imaging dataset (Blood Cell Imagery) to train a model for river ice semantic segmentation. First, we built a river ice semantic segmentation dataset IPC_RI_SEG using a fixed camera and covering the entire ice melting process of the river. Second, a high-resolution texture fusion semantic segmentation network named IceHrNet is proposed. The network used HRNet as the backbone and added ASPP and Decoder segmentation heads to retain low-level texture features for fine semantic segmentation. Finally, a simple and effective advanced style transfer learning strategy was proposed, which can perform zero-shot transfer learning based on cross-domain semantic segmentation datasets, achieving a practical effect of 87% mIoU for semantic segmentation of river ice without target training dataset (25% mIoU for None Stylized, 65% mIoU for Conventional Stylized, our strategy improved by 22%). Experiments showed that the IceHrNet outperformed the state-of-the-art methods on the texture-focused dataset IPC_RI_SEG, and achieved an excellent result on the shape-focused river ice datasets. In zero-shot transfer learning, IceHrNet achieved an increase of 2 percentage points compared to other methods. Our code and model are published on https://github.com/PL23K/IceHrNet.
Understanding and Mitigating the Label Noise in Pre-training on Downstream Tasks
Sep 29, 2023



Pre-training on large-scale datasets and then fine-tuning on downstream tasks have become a standard practice in deep learning. However, pre-training data often contain label noise that may adversely affect the generalization of the model. This paper aims to understand the nature of noise in pre-training datasets and to mitigate its impact on downstream tasks. More specifically, through extensive experiments of supervised pre-training models on synthetic noisy ImageNet-1K and YFCC15M datasets, we demonstrate that while slight noise in pre-training can benefit in-domain (ID) transfer performance, where the training and testing data share the same distribution, it always deteriorates out-of-domain (OOD) performance, where training and testing data distribution are different. We empirically verify that the reason behind is noise in pre-training shapes the feature space differently. We then propose a lightweight black-box tuning method (NMTune) to affine the feature space to mitigate the malignant effect of noise and improve generalization on both ID and OOD tasks, considering one may not be able to fully fine-tune or even access the pre-trained models. We conduct practical experiments on popular vision and language models that are pre-trained on noisy data for evaluation of our approach. Our analysis and results show the importance of this interesting and novel research direction, which we term Noisy Model Learning.
Targeted Multispectral Filter Array Design for Endoscopic Cancer Detection in the Gastrointestinal Tract
Aug 15, 2023Colour differences between healthy and diseased tissue in the gastrointestinal tract are detected visually by clinicians during white light endoscopy (WLE); however, the earliest signs of disease are often just a slightly different shade of pink compared to healthy tissue. Here, we propose to target alternative colours for imaging to improve contrast using custom multispectral filter arrays (MSFAs) that could be deployed in an endoscopic chip-on-tip configuration. Using an open-source toolbox, Opti-MSFA, we examined the optimal design of MSFAs for early cancer detection in the gastrointestinal tract. The toolbox was first extended to use additional classification models (k-Nearest Neighbour, Support Vector Machine, and Spectral Angle Mapper). Using input spectral data from published clinical trials examining the oesophagus and colon, we optimised the design of MSFAs with 3 to 9 different bands. We examined the variation of the spectral and spatial classification accuracy as a function of number of bands. The MSFA designs have high classification accuracies, suggesting that future implementation in endoscopy hardware could potentially enable improved early detection of disease in the gastrointestinal tract during routine screening and surveillance. Optimal MSFA configurations can achieve similar classification accuracies as the full spectral data in an implementation that could be realised in far simpler hardware. The reduced number of spectral bands could enable future deployment of multispectral imaging in an endoscopic chip-on-tip configuration.
Imprecise Label Learning: A Unified Framework for Learning with Various Imprecise Label Configurations
May 23, 2023In this paper, we introduce the imprecise label learning (ILL) framework, a unified approach to handle various imprecise label configurations, which are commonplace challenges in machine learning tasks. ILL leverages an expectation-maximization (EM) algorithm for the maximum likelihood estimation (MLE) of the imprecise label information, treating the precise labels as latent variables. Compared to previous versatile methods attempting to infer correct labels from the imprecise label information, our ILL framework considers all possible labeling imposed by the imprecise label information, allowing a unified solution to deal with any imprecise labels. With comprehensive experimental results, we demonstrate that ILL can seamlessly adapt to various situations, including partial label learning, semi-supervised learning, noisy label learning, and a mixture of these settings. Notably, our simple method surpasses the existing techniques for handling imprecise labels, marking the first unified framework with robust and effective performance across various imprecise labels. We believe that our approach has the potential to significantly enhance the performance of machine learning models on tasks where obtaining precise labels is expensive and complicated. We hope our work will inspire further research on this topic with an open-source codebase release.
SoftMatch: Addressing the Quantity-Quality Trade-off in Semi-supervised Learning
Jan 26, 2023



The critical challenge of Semi-Supervised Learning (SSL) is how to effectively leverage the limited labeled data and massive unlabeled data to improve the model's generalization performance. In this paper, we first revisit the popular pseudo-labeling methods via a unified sample weighting formulation and demonstrate the inherent quantity-quality trade-off problem of pseudo-labeling with thresholding, which may prohibit learning. To this end, we propose SoftMatch to overcome the trade-off by maintaining both high quantity and high quality of pseudo-labels during training, effectively exploiting the unlabeled data. We derive a truncated Gaussian function to weight samples based on their confidence, which can be viewed as a soft version of the confidence threshold. We further enhance the utilization of weakly-learned classes by proposing a uniform alignment approach. In experiments, SoftMatch shows substantial improvements across a wide variety of benchmarks, including image, text, and imbalanced classification.
Physics-informed deep diffusion MRI reconstruction: break the bottleneck of training data in artificial intelligence
Oct 20, 2022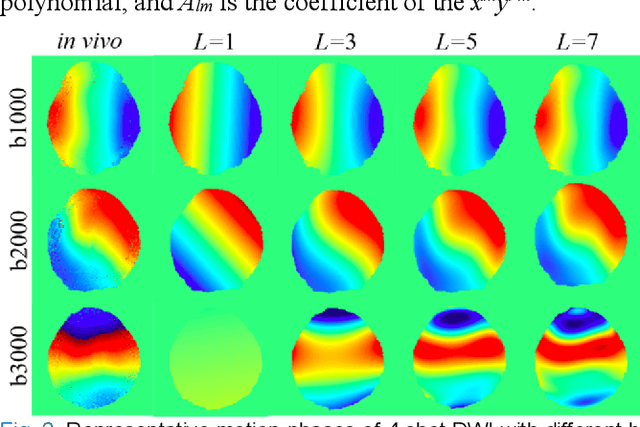
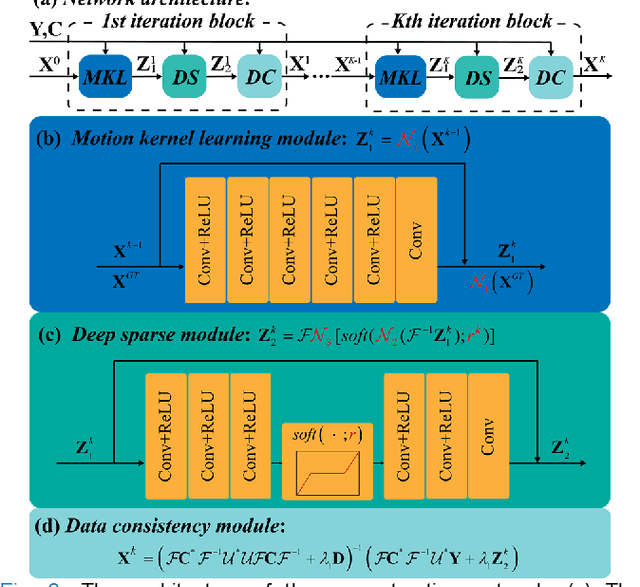
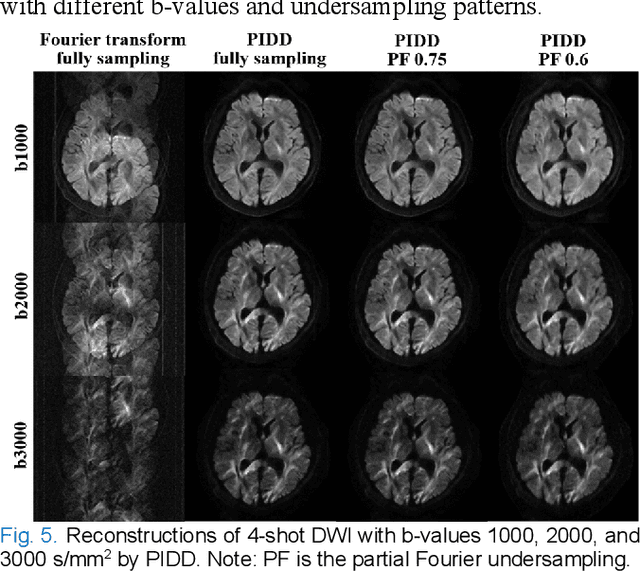
In this work, we propose a Physics-Informed Deep Diffusion magnetic resonance imaging (DWI) reconstruction method (PIDD). PIDD contains two main components: The multi-shot DWI data synthesis and a deep learning reconstruction network. For data synthesis, we first mathematically analyze the motion during the multi-shot data acquisition and approach it by a simplified physical motion model. The motion model inspires a polynomial model for motion-induced phase synthesis. Then, lots of synthetic phases are combined with a few real data to generate a large amount of training data. For reconstruction network, we exploit the smoothness property of each shot image phase as learnable convolution kernels in the k-space and complementary sparsity in the image domain. Results on both synthetic and in vivo brain data show that, the proposed PIDD trained on synthetic data enables sub-second ultra-fast, high-quality, and robust reconstruction with different b-values and undersampling patterns.
Optimizing Crop Management with Reinforcement Learning and Imitation Learning
Sep 20, 2022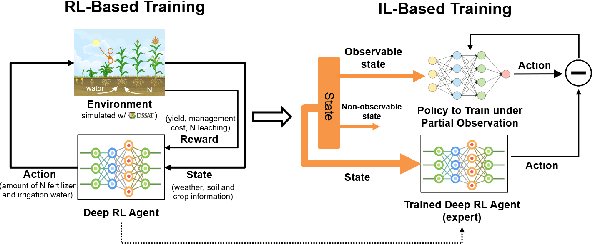
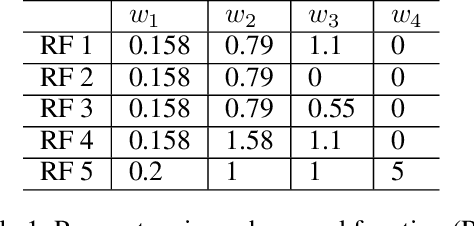
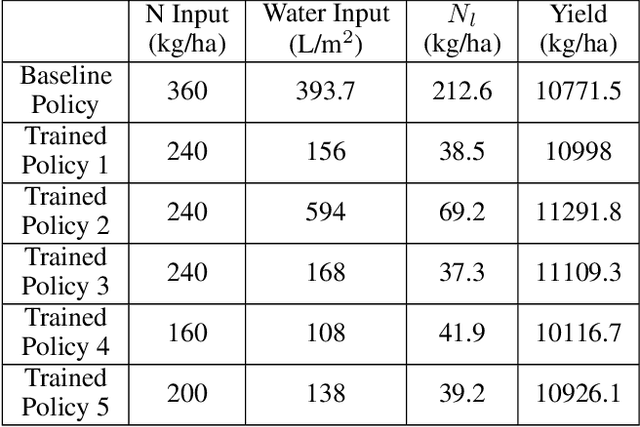
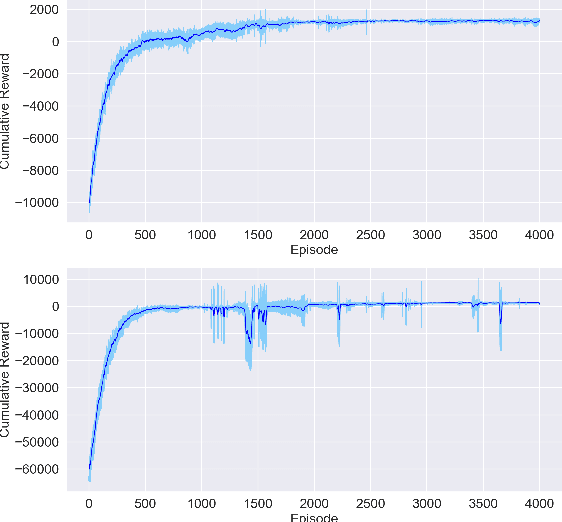
Crop management, including nitrogen (N) fertilization and irrigation management, has a significant impact on the crop yield, economic profit, and the environment. Although management guidelines exist, it is challenging to find the optimal management practices given a specific planting environment and a crop. Previous work used reinforcement learning (RL) and crop simulators to solve the problem, but the trained policies either have limited performance or are not deployable in the real world. In this paper, we present an intelligent crop management system which optimizes the N fertilization and irrigation simultaneously via RL, imitation learning (IL), and crop simulations using the Decision Support System for Agrotechnology Transfer (DSSAT). We first use deep RL, in particular, deep Q-network, to train management policies that require all state information from the simulator as observations (denoted as full observation). We then invoke IL to train management policies that only need a limited amount of state information that can be readily obtained in the real world (denoted as partial observation) by mimicking the actions of the previously RL-trained policies under full observation. We conduct experiments on a case study using maize in Florida and compare trained policies with a maize management guideline in simulations. Our trained policies under both full and partial observations achieve better outcomes, resulting in a higher profit or a similar profit with a smaller environmental impact. Moreover, the partial-observation management policies are directly deployable in the real world as they use readily available information.
LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images
Sep 16, 2022
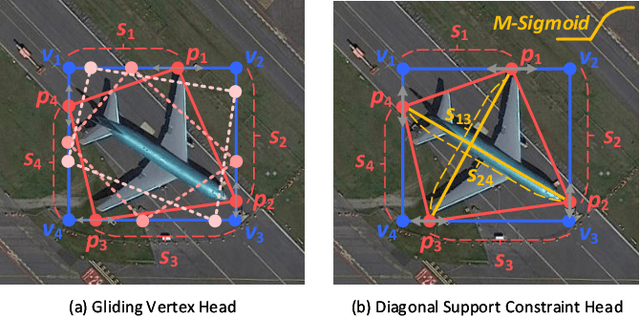
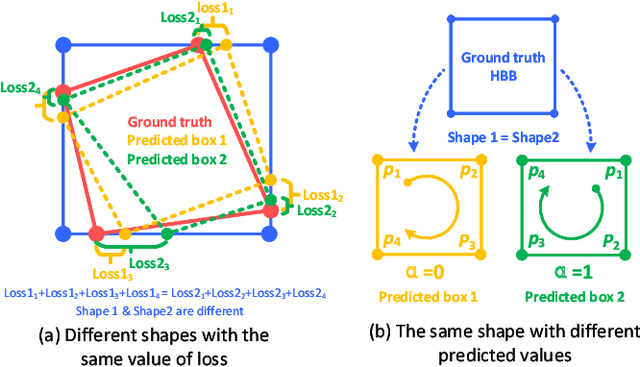
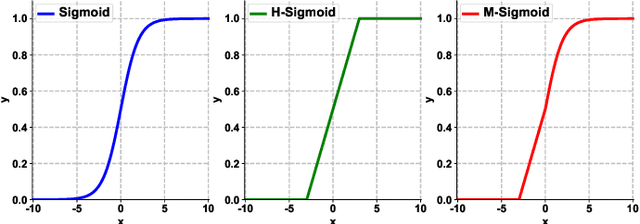
A few lightweight convolutional neural network (CNN) models have been recently designed for remote sensing object detection (RSOD). However, most of them simply replace vanilla convolutions with stacked separable convolutions, which may not be efficient due to a lot of precision losses and may not be able to detect oriented bounding boxes (OBB). Also, the existing OBB detection methods are difficult to constrain the shape of objects predicted by CNNs accurately. In this paper, we propose an effective lightweight oriented object detector (LO-Det). Specifically, a channel separation-aggregation (CSA) structure is designed to simplify the complexity of stacked separable convolutions, and a dynamic receptive field (DRF) mechanism is developed to maintain high accuracy by customizing the convolution kernel and its perception range dynamically when reducing the network complexity. The CSA-DRF component optimizes efficiency while maintaining high accuracy. Then, a diagonal support constraint head (DSC-Head) component is designed to detect OBBs and constrain their shapes more accurately and stably. Extensive experiments on public datasets demonstrate that the proposed LO-Det can run very fast even on embedded devices with the competitive accuracy of detecting oriented objects.
* 15 pages