 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT
Apr 30, 2020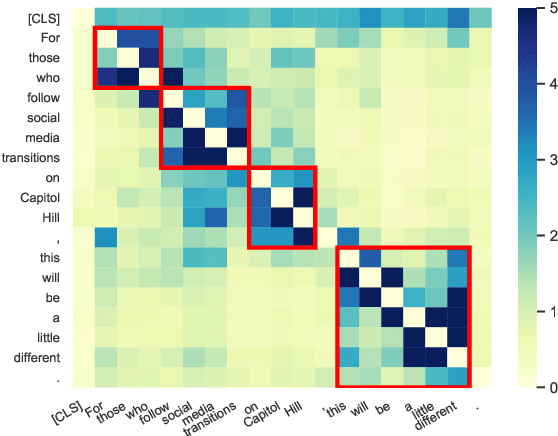
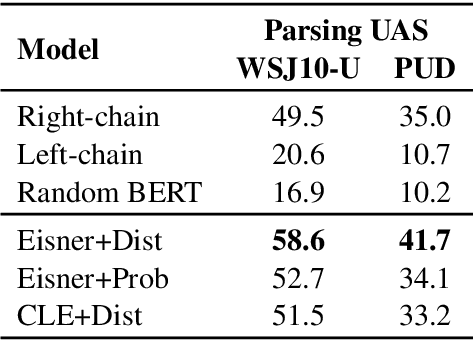
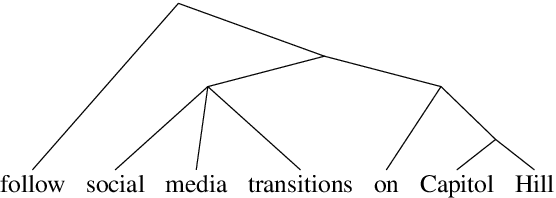
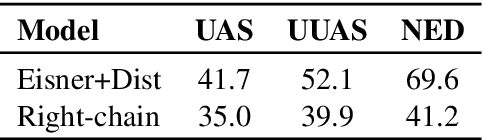
By introducing a small set of additional parameters, a probe learns to solve specific linguistic tasks (e.g., dependency parsing) in a supervised manner using feature representations (e.g., contextualized embeddings). The effectiveness of such probing tasks is taken as evidence that the pre-trained model encodes linguistic knowledge. However, this approach of evaluating a language model is undermined by the uncertainty of the amount of knowledge that is learned by the probe itself. Complementary to those works, we propose a parameter-free probing technique for analyzing pre-trained language models (e.g., BERT). Our method does not require direct supervision from the probing tasks, nor do we introduce additional parameters to the probing process. Our experiments on BERT show that syntactic trees recovered from BERT using our method are significantly better than linguistically-uninformed baselines. We further feed the empirically induced dependency structures into a downstream sentiment classification task and find its improvement compatible with or even superior to a human-designed dependency schema.
Probabilistically Masked Language Model Capable of Autoregressive Generation in Arbitrary Word Order
Apr 24, 2020
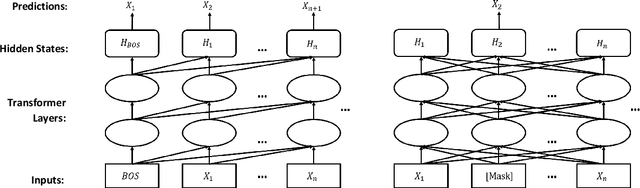
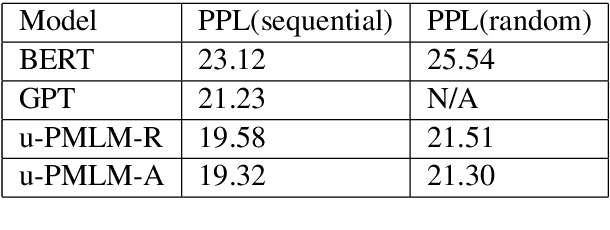
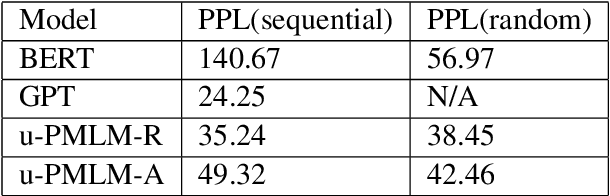
Masked language model and autoregressive language model are two types of language models. While pretrained masked language models such as BERT overwhelm the line of natural language understanding (NLU) tasks, autoregressive language models such as GPT are especially capable in natural language generation (NLG). In this paper, we propose a probabilistic masking scheme for the masked language model, which we call probabilistically masked language model (PMLM). We implement a specific PMLM with a uniform prior distribution on the masking ratio named u-PMLM. We prove that u-PMLM is equivalent to an autoregressive permutated language model. One main advantage of the model is that it supports text generation in arbitrary order with surprisingly good quality, which could potentially enable new applications over traditional unidirectional generation. Besides, the pretrained u-PMLM also outperforms BERT on a set of downstream NLU tasks.
DynaBERT: Dynamic BERT with Adaptive Width and Depth
Apr 08, 2020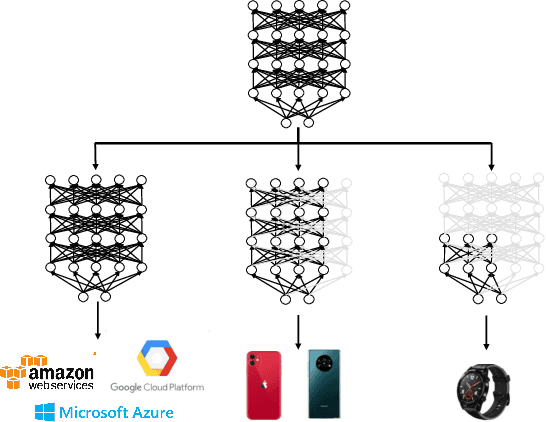
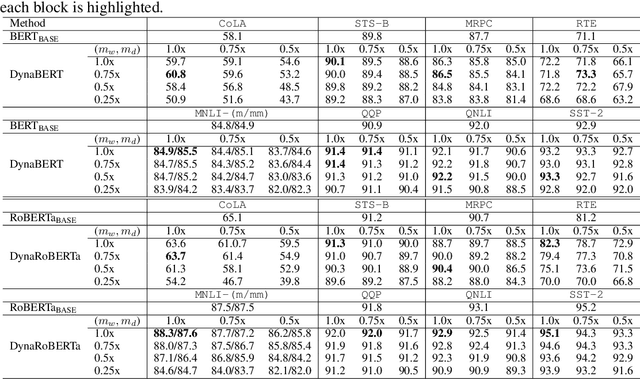
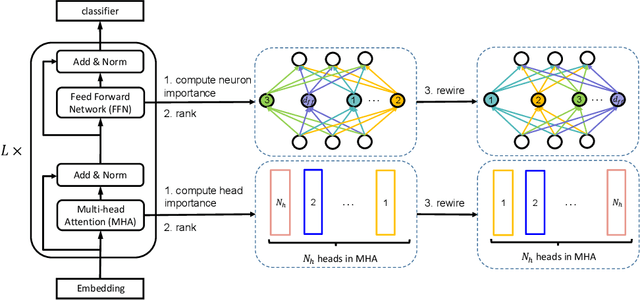

The pre-trained language models like BERT and RoBERTa, though powerful in many natural language processing tasks, are both computational and memory expensive. To alleviate this problem, one approach is to compress them for specific tasks before deployment. However, recent works on BERT compression usually reduce the large BERT model to a fixed smaller size, and can not fully satisfy the requirements of different edge devices with various hardware performances. In this paper, we propose a novel dynamic BERT model (abbreviated as DynaBERT), which can run at adaptive width and depth. The training process of DynaBERT includes first training a width-adaptive BERT and then allows both adaptive width and depth, by distilling knowledge from the full-sized model to small sub-networks. Network rewiring is also used to keep the more important attention heads and neurons shared by more sub-networks. Comprehensive experiments under various efficiency constraints demonstrate that our proposed dynamic BERT (or RoBERTa) at its largest size has comparable performance as BERT (or RoBERTa), while at smaller widths and depths consistently outperforms existing BERT compression methods.
Dictionary-based Data Augmentation for Cross-Domain Neural Machine Translation
Apr 06, 2020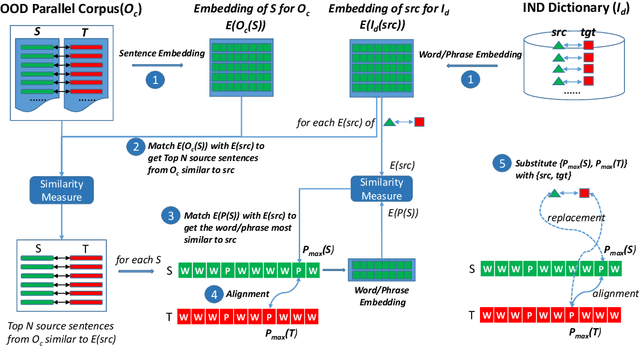

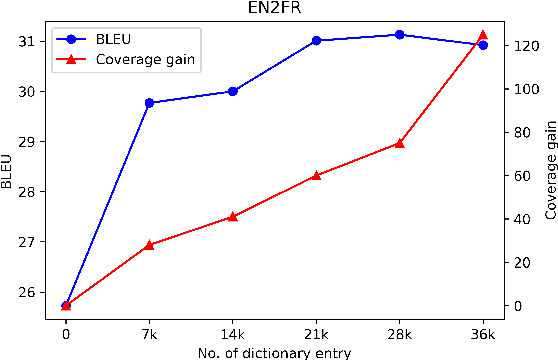
Existing data augmentation approaches for neural machine translation (NMT) have predominantly relied on back-translating in-domain (IND) monolingual corpora. These methods suffer from issues associated with a domain information gap, which leads to translation errors for low frequency and out-of-vocabulary terminology. This paper proposes a dictionary-based data augmentation (DDA) method for cross-domain NMT. DDA synthesizes a domain-specific dictionary with general domain corpora to automatically generate a large-scale pseudo-IND parallel corpus. The generated pseudo-IND data can be used to enhance a general domain trained baseline. The experiments show that the DDA-enhanced NMT models demonstrate consistent significant improvements, outperforming the baseline models by 3.75-11.53 BLEU. The proposed method is also able to further improve the performance of the back-translation based and IND-finetuned NMT models. The improvement is associated with the enhanced domain coverage produced by DDA.
A One-Shot Learning Framework for Assessment of Fibrillar Collagen from Second Harmonic Generation Images of an Infarcted Myocardium
Jan 30, 2020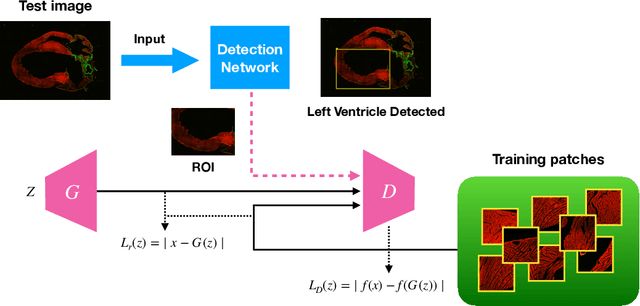
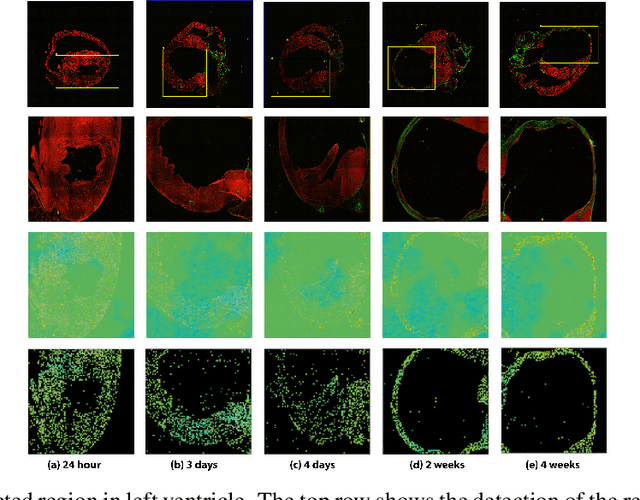
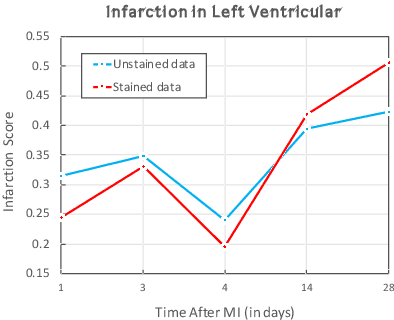
Myocardial infarction (MI) is a scientific term that refers to heart attack. In this study, we infer highly relevant second harmonic generation (SHG) cues from collagen fibers exhibiting highly non-centrosymmetric assembly together with two-photon excited cellular autofluorescence in infarcted mouse heart to quantitatively probe fibrosis, especially targeted at an early stage after MI. We present a robust one-shot machine learning algorithm that enables determination of 2D assembly of collagen with high spatial resolution along with its structural arrangement in heart tissues post-MI with spectral specificity and sensitivity. Detection, evaluation, and precise quantification of fibrosis extent at early stage would guide one to develop treatment therapies that may prevent further progression and determine heart transplant needs for patient survival.
Context-Aware Design of Cyber-Physical Human Systems
Jan 07, 2020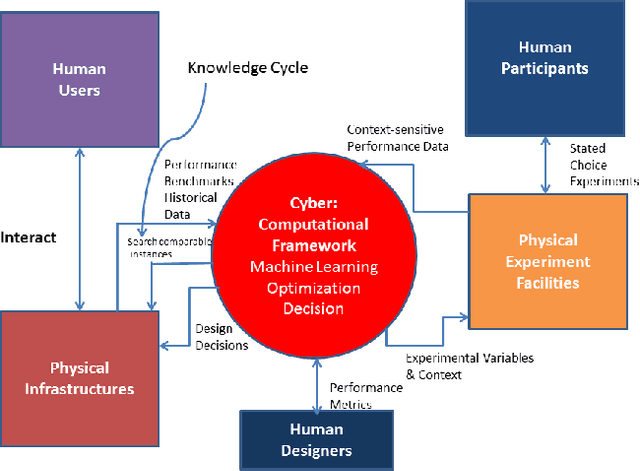
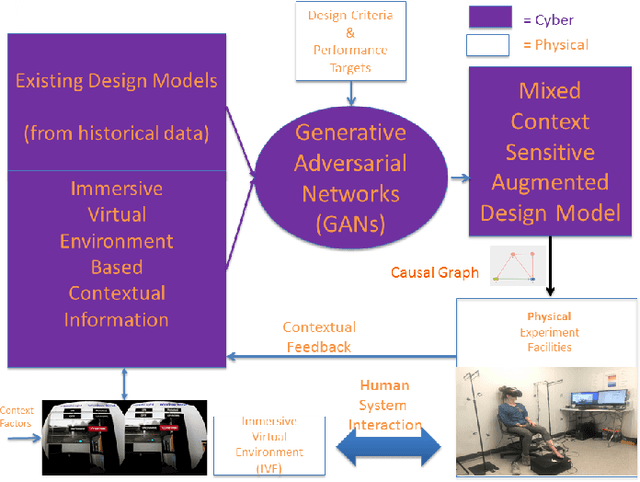
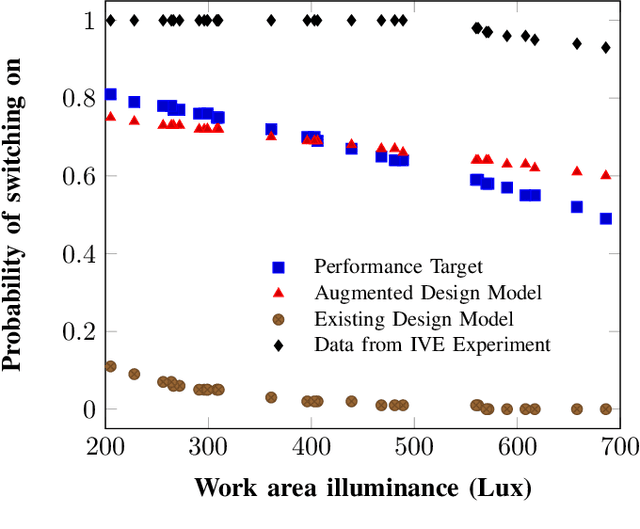
Recently, it has been widely accepted by the research community that interactions between humans and cyber-physical infrastructures have played a significant role in determining the performance of the latter. The existing paradigm for designing cyber-physical systems for optimal performance focuses on developing models based on historical data. The impacts of context factors driving human system interaction are challenging and are difficult to capture and replicate in existing design models. As a result, many existing models do not or only partially address those context factors of a new design owing to the lack of capabilities to capture the context factors. This limitation in many existing models often causes performance gaps between predicted and measured results. We envision a new design environment, a cyber-physical human system (CPHS) where decision-making processes for physical infrastructures under design are intelligently connected to distributed resources over cyberinfrastructure such as experiments on design features and empirical evidence from operations of existing instances. The framework combines existing design models with context-aware design-specific data involving human-infrastructure interactions in new designs, using a machine learning approach to create augmented design models with improved predictive powers.
Multi-channel Reverse Dictionary Model
Dec 19, 2019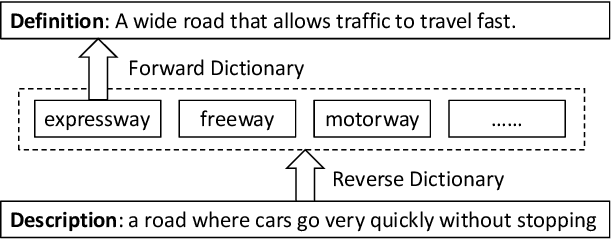
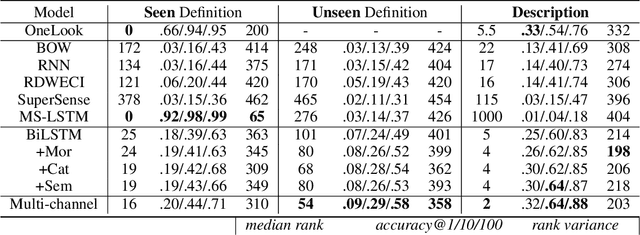
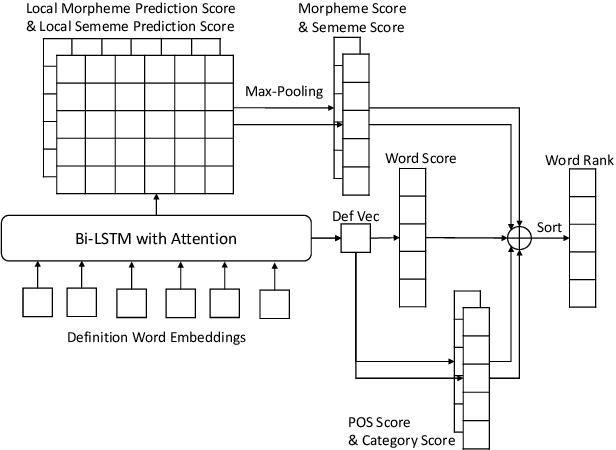
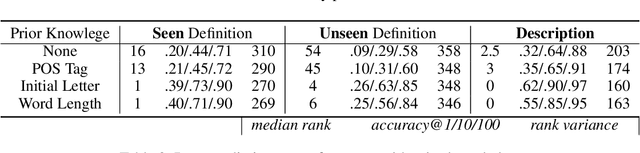
A reverse dictionary takes the description of a target word as input and outputs the target word together with other words that match the description. Existing reverse dictionary methods cannot deal with highly variable input queries and low-frequency target words successfully. Inspired by the description-to-word inference process of humans, we propose the multi-channel reverse dictionary model, which can mitigate the two problems simultaneously. Our model comprises a sentence encoder and multiple predictors. The predictors are expected to identify different characteristics of the target word from the input query. We evaluate our model on English and Chinese datasets including both dictionary definitions and human-written descriptions. Experimental results show that our model achieves the state-of-the-art performance, and even outperforms the most popular commercial reverse dictionary system on the human-written description dataset. We also conduct quantitative analyses and a case study to demonstrate the effectiveness and robustness of our model. All the code and data of this work can be obtained on https://github.com/thunlp/MultiRD.
Deep Learning-Based Feature-Aware Data Modeling for Complex Physics Simulations
Dec 08, 2019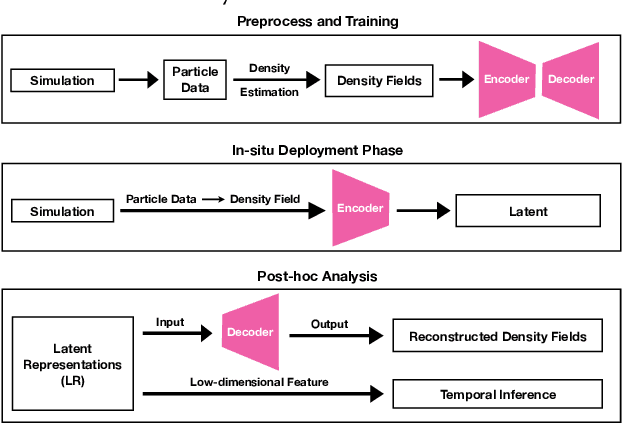
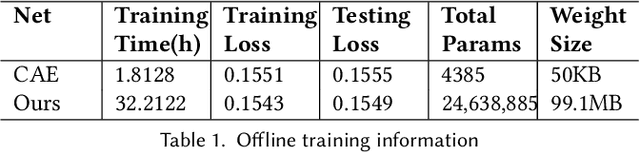
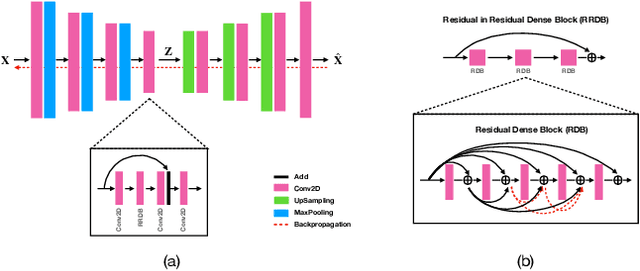

Data modeling and reduction for in situ is important. Feature-driven methods for in situ data analysis and reduction are a priority for future exascale machines as there are currently very few such methods. We investigate a deep-learning based workflow that targets in situ data processing using autoencoders. We propose a Residual Autoencoder integrated Residual in Residual Dense Block (RRDB) to obtain better performance. Our proposed framework compressed our test data into 66 KB from 2.1 MB per 3D volume timestep.
Learning to Predict Explainable Plots for Neural Story Generation
Dec 06, 2019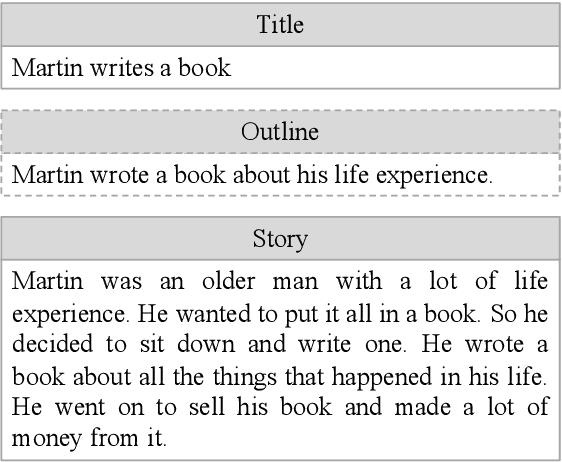
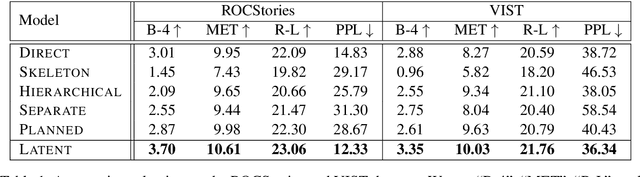
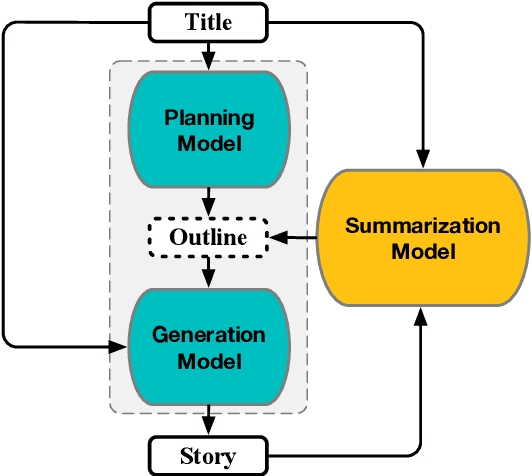
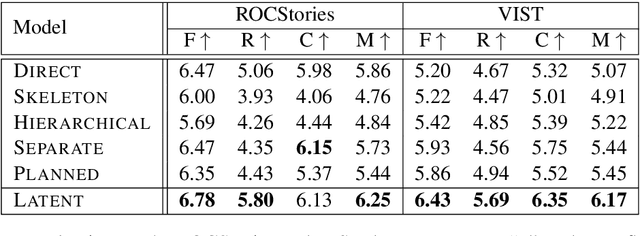
Story generation is an important natural language processing task that aims to generate coherent stories automatically. While the use of neural networks has proven effective in improving story generation, how to learn to generate an explainable high-level plot still remains a major challenge. In this work, we propose a latent variable model for neural story generation. The model treats an outline, which is a natural language sentence explainable to humans, as a latent variable to represent a high-level plot that bridges the input and output. We adopt an external summarization model to guide the latent variable model to learn how to generate outlines from training data. Experiments show that our approach achieves significant improvements over state-of-the-art methods in both automatic and human evaluations.
Integrating Graph Contextualized Knowledge into Pre-trained Language Models
Dec 03, 2019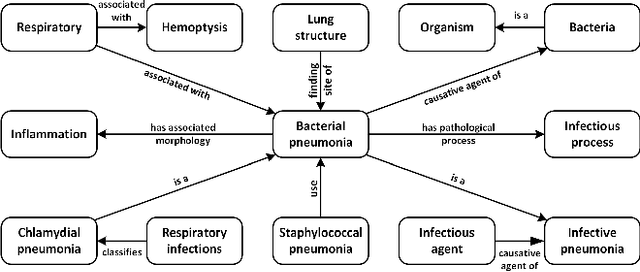

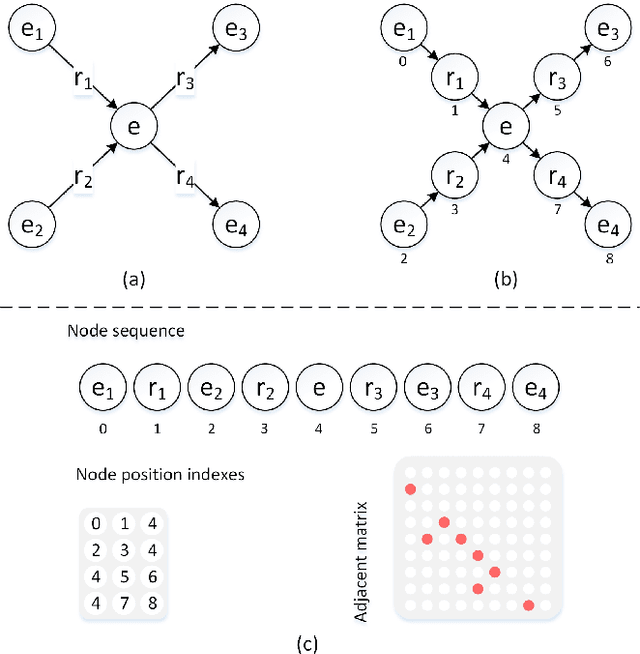

Complex node interactions are common in knowledge graphs, and these interactions also contain rich knowledge information. However, traditional methods usually treat a triple as a training unit during the knowledge representation learning (KRL) procedure, neglecting contextualized information of the nodes in knowledge graphs (KGs). We generalize the modeling object to a very general form, which theoretically supports any subgraph extracted from the knowledge graph, and these subgraphs are fed into a novel transformer-based model to learn the knowledge embeddings. To broaden usage scenarios of knowledge, pre-trained language models are utilized to build a model that incorporates the learned knowledge representations. Experimental results demonstrate that our model achieves the state-of-the-art performance on several medical NLP tasks, and improvement above TransE indicates that our KRL method captures the graph contextualized information effectively.