 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Design of Cyber-Physical Human Systems
Jan 07, 2020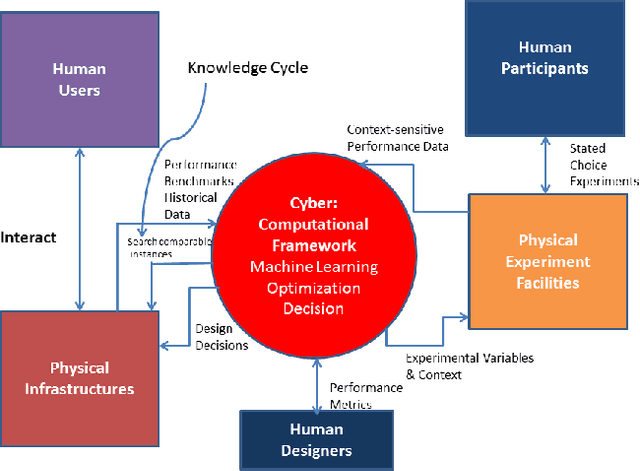
Recently, it has been widely accepted by the research community that interactions between humans and cyber-physical infrastructures have played a significant role in determining the performance of the latter. The existing paradigm for designing cyber-physical systems for optimal performance focuses on developing models based on historical data. The impacts of context factors driving human system interaction are challenging and are difficult to capture and replicate in existing design models. As a result, many existing models do not or only partially address those context factors of a new design owing to the lack of capabilities to capture the context factors. This limitation in many existing models often causes performance gaps between predicted and measured results. We envision a new design environment, a cyber-physical human system (CPHS) where decision-making processes for physical infrastructures under design are intelligently connected to distributed resources over cyberinfrastructure such as experiments on design features and empirical evidence from operations of existing instances. The framework combines existing design models with context-aware design-specific data involving human-infrastructure interactions in new designs, using a machine learning approach to create augmented design models with improved predictive powers.
PCGAN-CHAR: Progressively Trained Classifier Generative Adversarial Networks for Classification of Noisy Handwritten Bangla Characters
Aug 11, 2019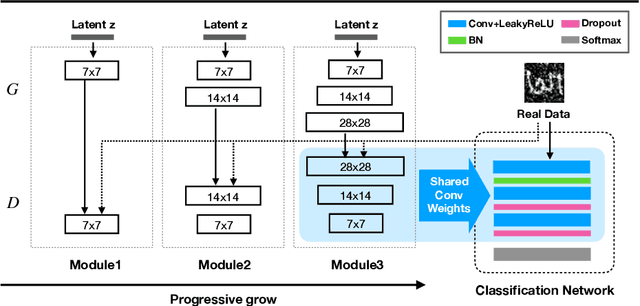
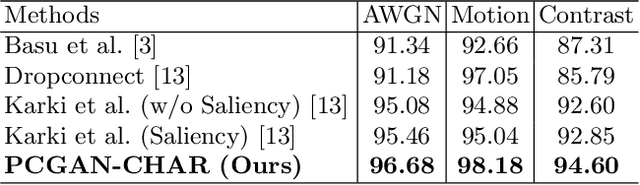

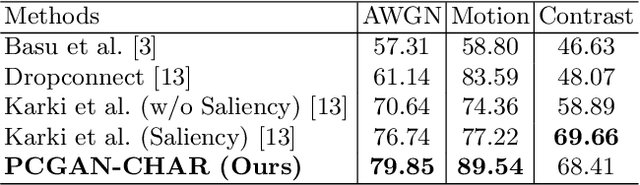
Due to the sparsity of features, noise has proven to be a great inhibitor in the classification of handwritten characters. To combat this, most techniques perform denoising of the data before classification. In this paper, we consolidate the approach by training an all-in-one model that is able to classify even noisy characters. For classification, we progressively train a classifier generative adversarial network on the characters from low to high resolution. We show that by learning the features at each resolution independently a trained model is able to accurately classify characters even in the presence of noise. We experimentally demonstrate the effectiveness of our approach by classifying noisy versions of MNIST, handwritten Bangla Numeral, and Basic Character datasets.
Improving Prediction Accuracy in Building Performance Models Using Generative Adversarial Networks (GANs)
Jun 14, 2019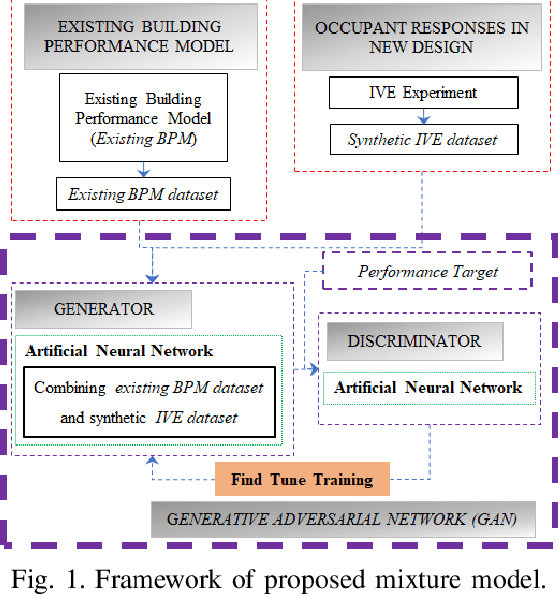

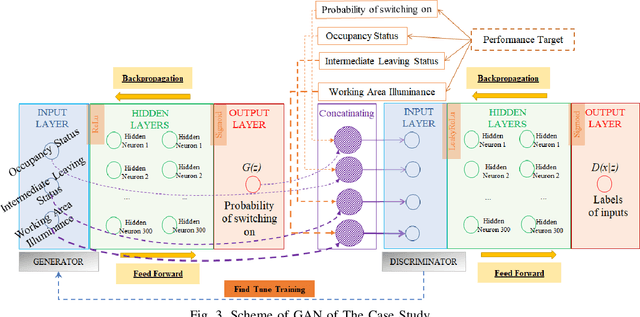
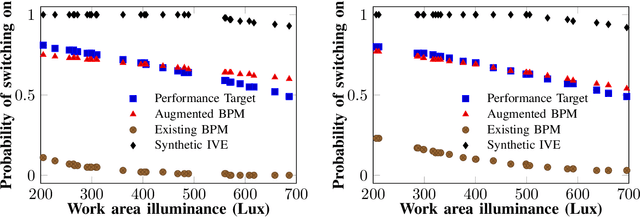
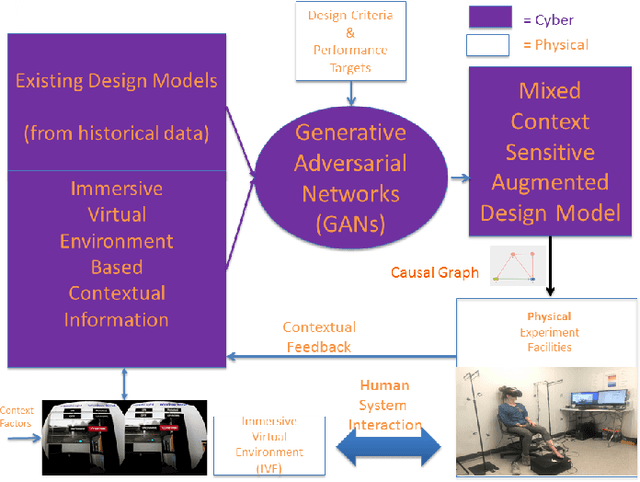
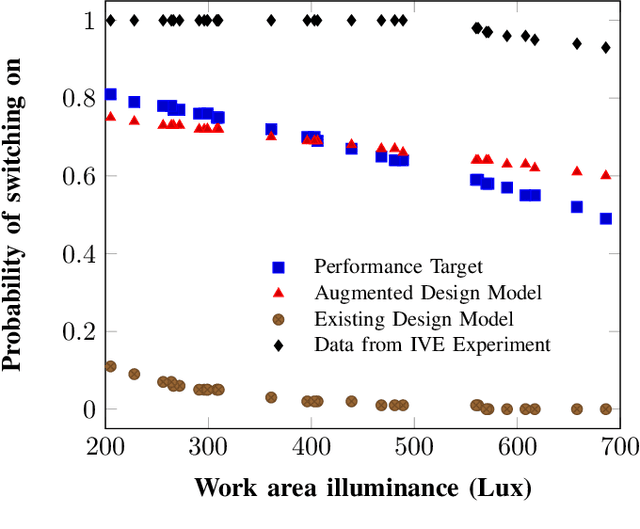
Building performance discrepancies between building design and operation are one of the causes that lead many new designs fail to achieve their goals and objectives. One of main factors contributing to the discrepancy is occupant behaviors. Occupants responding to a new design are influenced by several factors. Existing building performance models (BPMs) ignore or partially address those factors (called contextual factors) while developing BPMs. To potentially reduce the discrepancies and improve the prediction accuracy of BPMs, this paper proposes a computational framework for learning mixture models by using Generative Adversarial Networks (GANs) that appropriately combining existing BPMs with knowledge on occupant behaviors to contextual factors in new designs. Immersive virtual environments (IVEs) experiments are used to acquire data on such behaviors. Performance targets are used to guide appropriate combination of existing BPMs with knowledge on occupant behaviors. The resulting model obtained is called an augmented BPM. Two different experiments related to occupant lighting behaviors are shown as case study. The results reveal that augmented BPMs significantly outperformed existing BPMs with respect to achieving specified performance targets. The case study confirms the potential of the computational framework for improving prediction accuracy of BPMs during design.
Progressively Growing Generative Adversarial Networks for High Resolution Semantic Segmentation of Satellite Images
Feb 12, 2019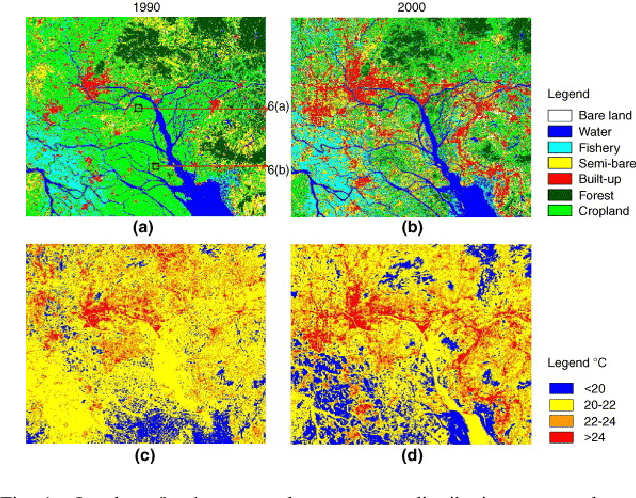

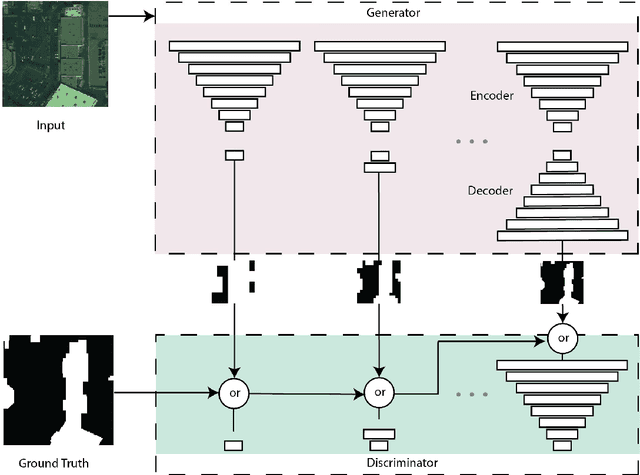

Machine learning has proven to be useful in classification and segmentation of images. In this paper, we evaluate a training methodology for pixel-wise segmentation on high resolution satellite images using progressive growing of generative adversarial networks. We apply our model to segmenting building rooftops and compare these results to conventional methods for rooftop segmentation. We present our findings using the SpaceNet version 2 dataset. Progressive GAN training achieved a test accuracy of 93% compared to 89% for traditional GAN training.
CactusNets: Layer Applicability as a Metric for Transfer Learning
Apr 20, 2018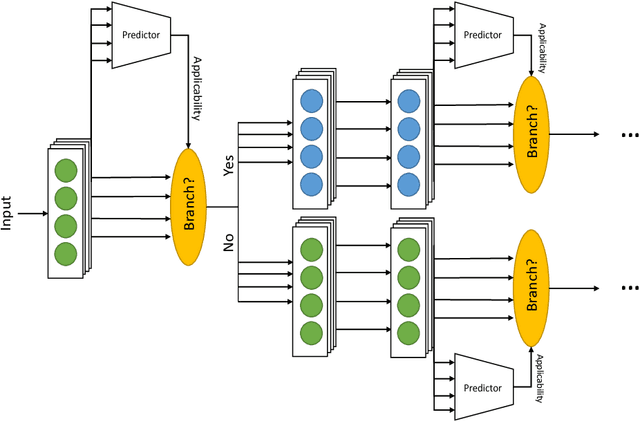
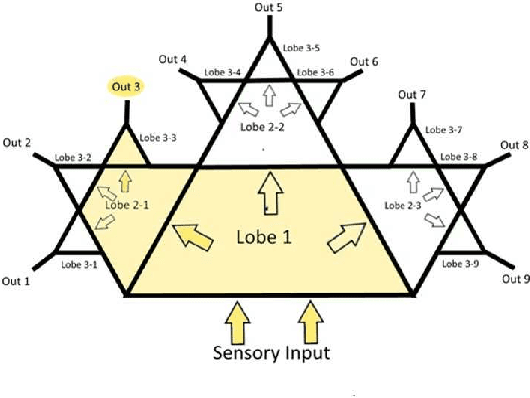
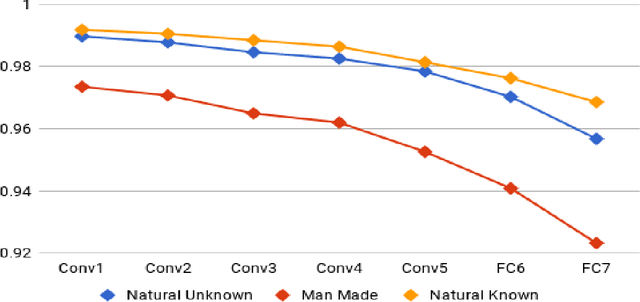
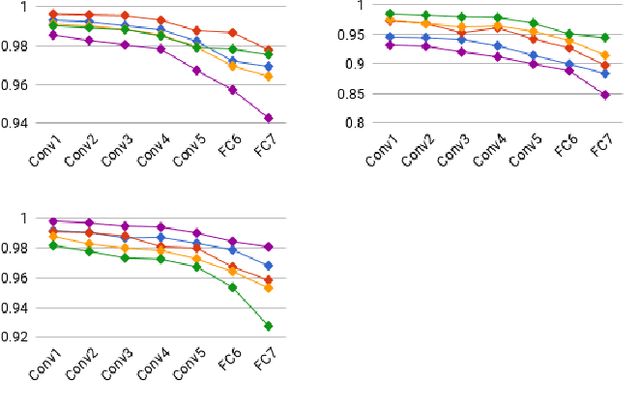
Deep neural networks trained over large datasets learn features that are both generic to the whole dataset, and specific to individual classes in the dataset. Learned features tend towards generic in the lower layers and specific in the higher layers of a network. Methods like fine-tuning are made possible because of the ability for one filter to apply to multiple target classes. Much like the human brain this behavior, can also be used to cluster and separate classes. However, to the best of our knowledge there is no metric for how applicable learned features are to specific classes. In this paper we propose a definition and metric for measuring the applicability of learned features to individual classes, and use this applicability metric to estimate input applicability and produce a new method of unsupervised learning we call the CactusNet.