 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Exacerbated Heterogeneity for Robust Models in Federated Learning
Mar 01, 2023



Privacy and security concerns in real-world applications have led to the development of adversarially robust federated models. However, the straightforward combination between adversarial training and federated learning in one framework can lead to the undesired robustness deterioration. We discover that the attribution behind this phenomenon is that the generated adversarial data could exacerbate the data heterogeneity among local clients, making the wrapped federated learning perform poorly. To deal with this problem, we propose a novel framework called Slack Federated Adversarial Training (SFAT), assigning the client-wise slack during aggregation to combat the intensified heterogeneity. Theoretically, we analyze the convergence of the proposed method to properly relax the objective when combining federated learning and adversarial training. Experimentally, we verify the rationality and effectiveness of SFAT on various benchmarked and real-world datasets with different adversarial training and federated optimization methods. The code is publicly available at https://github.com/ZFancy/SFAT.
Search to Capture Long-range Dependency with Stacking GNNs for Graph Classification
Feb 17, 2023



In recent years, Graph Neural Networks (GNNs) have been popular in the graph classification task. Currently, shallow GNNs are more common due to the well-known over-smoothing problem facing deeper GNNs. However, they are sub-optimal without utilizing the information from distant nodes, i.e., the long-range dependencies. The mainstream methods in the graph classification task can extract the long-range dependencies either by designing the pooling operations or incorporating the higher-order neighbors, while they have evident drawbacks by modifying the original graph structure, which may result in information loss in graph structure learning. In this paper, by justifying the smaller influence of the over-smoothing problem in the graph classification task, we evoke the importance of stacking-based GNNs and then employ them to capture the long-range dependencies without modifying the original graph structure. To achieve this, two design needs are given for stacking-based GNNs, i.e., sufficient model depth and adaptive skip-connection schemes. By transforming the two design needs into designing data-specific inter-layer connections, we propose a novel approach with the help of neural architecture search (NAS), which is dubbed LRGNN (Long-Range Graph Neural Networks). Extensive experiments on five datasets show that the proposed LRGNN can achieve the best performance, and obtained data-specific GNNs with different depth and skip-connection schemes, which can better capture the long-range dependencies.
Enhancing Intra-class Information Extraction for Heterophilous Graphs: One Neural Architecture Search Approach
Nov 20, 2022



In recent years, Graph Neural Networks (GNNs) have been popular in graph representation learning which assumes the homophily property, i.e., the connected nodes have the same label or have similar features. However, they may fail to generalize into the heterophilous graphs which in the low/medium level of homophily. Existing methods tend to address this problem by enhancing the intra-class information extraction, i.e., either by designing better GNNs to improve the model effectiveness, or re-designing the graph structures to incorporate more potential intra-class nodes from distant hops. Despite the success, we observe two aspects that can be further improved: (a) enhancing the ego feature information extraction from node itself which is more reliable in extracting the intra-class information; (b) designing node-wise GNNs can better adapt to the nodes with different homophily ratios. In this paper, we propose a novel method IIE-GNN (Intra-class Information Enhanced Graph Neural Networks) to achieve two improvements. A unified framework is proposed based on the literature, in which the intra-class information from the node itself and neighbors can be extracted based on seven carefully designed blocks. With the help of neural architecture search (NAS), we propose a novel search space based on the framework, and then provide an architecture predictor to design GNNs for each node. We further conduct experiments to show that IIE-GNN can improve the model performance by designing node-wise GNNs to enhance intra-class information extraction.
Search to Pass Messages for Temporal Knowledge Graph Completion
Oct 30, 2022



Completing missing facts is a fundamental task for temporal knowledge graphs (TKGs). Recently, graph neural network (GNN) based methods, which can simultaneously explore topological and temporal information, have become the state-of-the-art (SOTA) to complete TKGs. However, these studies are based on hand-designed architectures and fail to explore the diverse topological and temporal properties of TKG. To address this issue, we propose to use neural architecture search (NAS) to design data-specific message passing architecture for TKG completion. In particular, we develop a generalized framework to explore topological and temporal information in TKGs. Based on this framework, we design an expressive search space to fully capture various properties of different TKGs. Meanwhile, we adopt a search algorithm, which trains a supernet structure by sampling single path for efficient search with less cost. We further conduct extensive experiments on three benchmark datasets. The results show that the searched architectures by our method achieve the SOTA performances. Besides, the searched models can also implicitly reveal diverse properties in different TKGs. Our code is released in https://github.com/striderdu/SPA.
Searching a High-Performance Feature Extractor for Text Recognition Network
Sep 27, 2022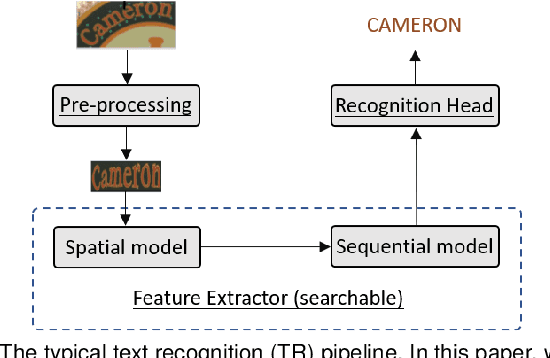

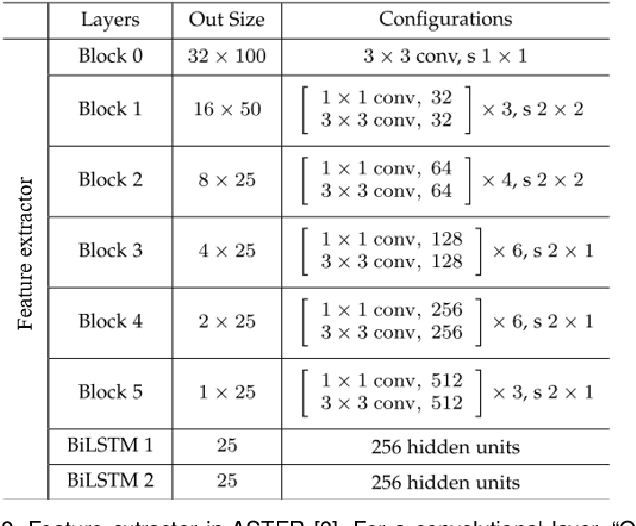
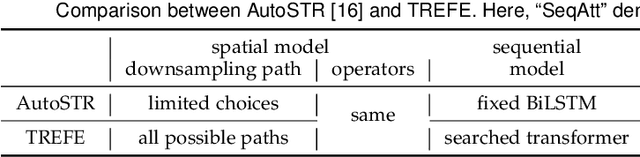
Feature extractor plays a critical role in text recognition (TR), but customizing its architecture is relatively less explored due to expensive manual tweaking. In this work, inspired by the success of neural architecture search (NAS), we propose to search for suitable feature extractors. We design a domain-specific search space by exploring principles for having good feature extractors. The space includes a 3D-structured space for the spatial model and a transformed-based space for the sequential model. As the space is huge and complexly structured, no existing NAS algorithms can be applied. We propose a two-stage algorithm to effectively search in the space. In the first stage, we cut the space into several blocks and progressively train each block with the help of an auxiliary head. We introduce the latency constraint into the second stage and search sub-network from the trained supernet via natural gradient descent. In experiments, a series of ablation studies are performed to better understand the designed space, search algorithm, and searched architectures. We also compare the proposed method with various state-of-the-art ones on both hand-written and scene TR tasks. Extensive results show that our approach can achieve better recognition performance with less latency.
DisenHCN: Disentangled Hypergraph Convolutional Networks for Spatiotemporal Activity Prediction
Aug 14, 2022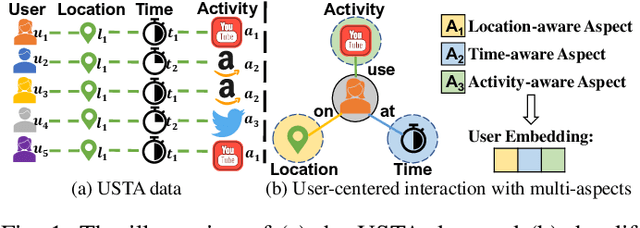
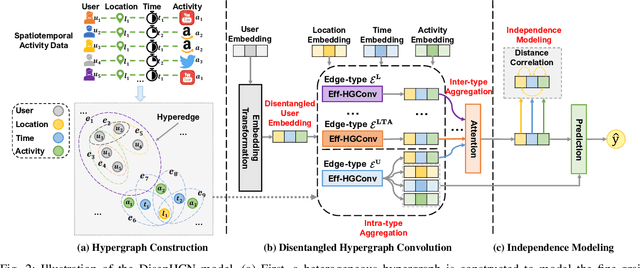
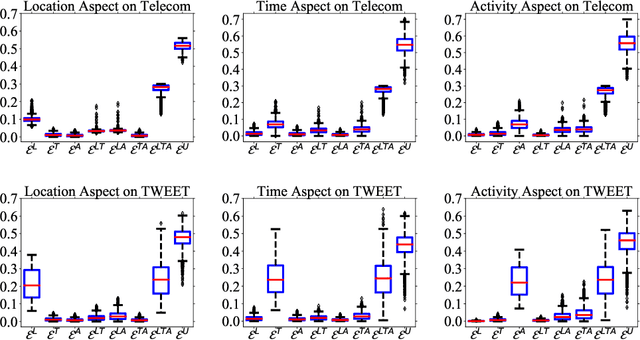
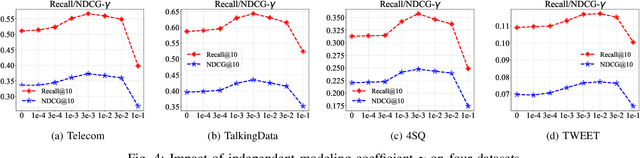
Spatiotemporal activity prediction, aiming to predict user activities at a specific location and time, is crucial for applications like urban planning and mobile advertising. Existing solutions based on tensor decomposition or graph embedding suffer from the following two major limitations: 1) ignoring the fine-grained similarities of user preferences; 2) user's modeling is entangled. In this work, we propose a hypergraph neural network model called DisenHCN to bridge the above gaps. In particular, we first unify the fine-grained user similarity and the complex matching between user preferences and spatiotemporal activity into a heterogeneous hypergraph. We then disentangle the user representations into different aspects (location-aware, time-aware, and activity-aware) and aggregate corresponding aspect's features on the constructed hypergraph, capturing high-order relations from different aspects and disentangles the impact of each aspect for final prediction. Extensive experiments show that our DisenHCN outperforms the state-of-the-art methods by 14.23% to 18.10% on four real-world datasets. Further studies also convincingly verify the rationality of each component in our DisenHCN.
AutoWeird: Weird Translational Scoring Function Identified by Random Search
Jul 24, 2022

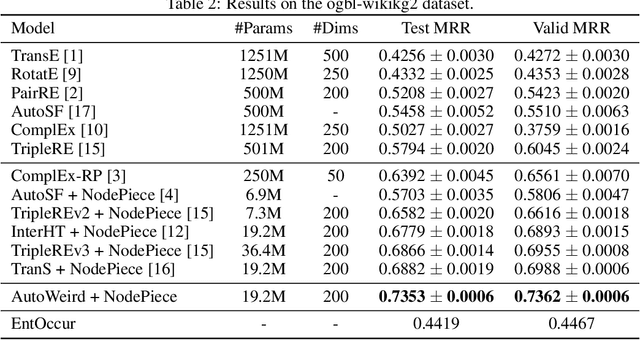
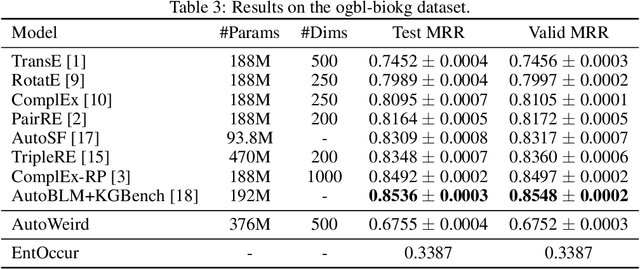
Scoring function (SF) measures the plausibility of triplets in knowledge graphs. Different scoring functions can lead to huge differences in link prediction performances on different knowledge graphs. In this report, we describe a weird scoring function found by random search on the open graph benchmark (OGB). This scoring function, called AutoWeird, only uses tail entity and relation in a triplet to compute its plausibility score. Experimental results show that AutoWeird achieves top-1 performance on ogbl-wikikg2 data set, but has much worse performance than other methods on ogbl-biokg data set. By analyzing the tail entity distribution and evaluation protocol of these two data sets, we attribute the unexpected success of AutoWeird on ogbl-wikikg2 to inappropriate evaluation and concentrated tail entity distribution. Such results may motivate further research on how to accurately evaluate the performance of different link prediction methods for knowledge graphs.
Graph Property Prediction on Open Graph Benchmark: A Winning Solution by Graph Neural Architecture Search
Jul 13, 2022

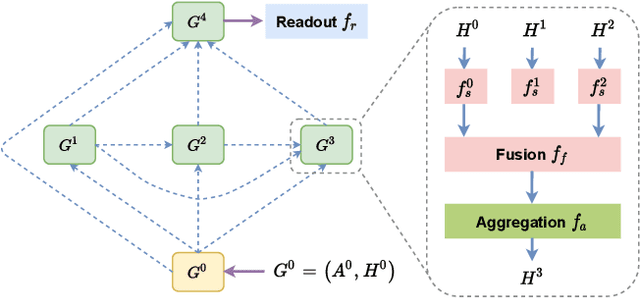
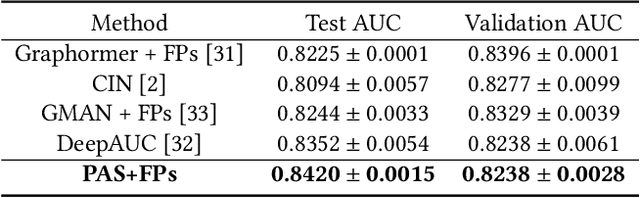
Aiming at two molecular graph datasets and one protein association subgraph dataset in OGB graph classification task, we design a graph neural network framework for graph classification task by introducing PAS(Pooling Architecture Search). At the same time, we improve it based on the GNN topology design method F2GNN to further design the feature selection and fusion strategies, so as to further improve the performance of the model in the graph property prediction task while overcoming the over smoothing problem of deep GNN training. Finally, a performance breakthrough is achieved on these three datasets, which is significantly better than other methods with fixed aggregate function. It is proved that the NAS method has high generalization ability for multiple tasks and the advantage of our method in processing graph property prediction tasks.
Learning Adaptive Propagation for Knowledge Graph Reasoning
May 30, 2022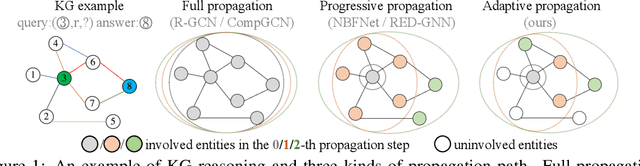

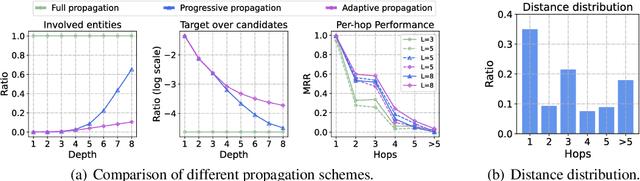
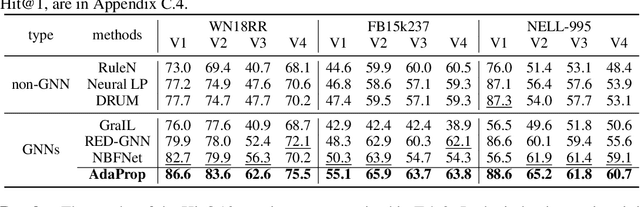
Due to the success of Graph Neural Networks (GNNs) in learning from graph-structured data, various GNN-based methods have been introduced to learn from knowledge graphs (KGs). In this paper, to reveal the key factors underneath existing GNN-based methods, we revisit exemplar works from the lens of the propagation path. We find that the answer entity can be close to queried one, but the information dependency can be long. Thus, better reasoning performance can be obtained by exploring longer propagation paths. However, identifying such a long-range dependency in KG is hard since the number of involved entities grows exponentially. This motivates us to learn an adaptive propagation path that filters out irrelevant entities while preserving promising targets during the propagation. First, we design an incremental sampling mechanism where the close and promising target can be preserved. Second, we design a learning-based sampling distribution to identify the targets with fewer involved entities. In this way, GNN can go deeper to capture long-range information. Extensive experiments show that our method is efficient and achieves state-of-the-art performances in both transductive and inductive reasoning settings, benefiting from the deeper propagation.
Low-rank Tensor Learning with Nonconvex Overlapped Nuclear Norm Regularization
May 06, 2022
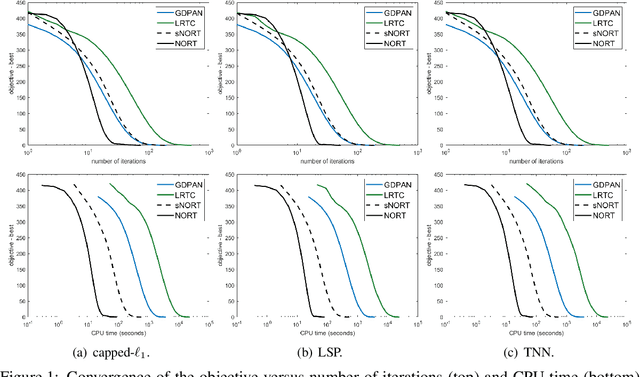

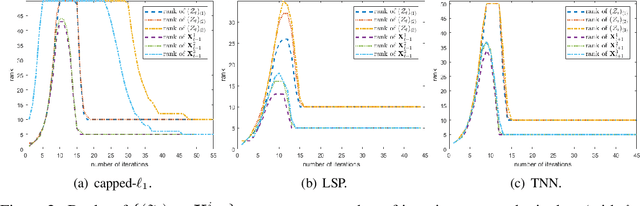
Nonconvex regularization has been popularly used in low-rank matrix learning. However, extending it for low-rank tensor learning is still computationally expensive. To address this problem, we develop an efficient solver for use with a nonconvex extension of the overlapped nuclear norm regularizer. Based on the proximal average algorithm, the proposed algorithm can avoid expensive tensor folding/unfolding operations. A special "sparse plus low-rank" structure is maintained throughout the iterations, and allows fast computation of the individual proximal steps. Empirical convergence is further improved with the use of adaptive momentum. We provide convergence guarantees to critical points on smooth losses and also on objectives satisfying the Kurdyka-{\L}ojasiewicz condition. While the optimization problem is nonconvex and nonsmooth, we show that its critical points still have good statistical performance on the tensor completion problem. Experiments on various synthetic and real-world data sets show that the proposed algorithm is efficient in both time and space and more accurate than the existing state-of-the-art.