 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNNRank: Learning Global Rankings from Pairwise Comparisons via Directed Graph Neural Networks
Feb 01, 2022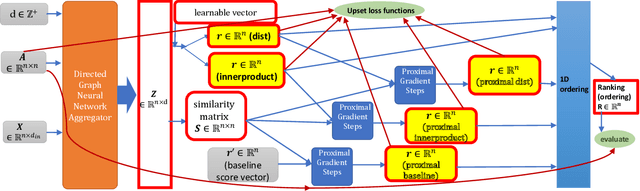
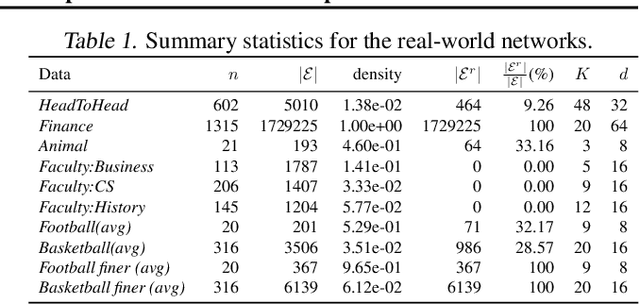
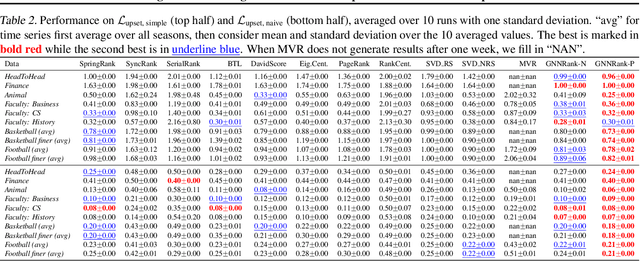

Recovering global rankings from pairwise comparisons is an important problem with many applications, ranging from time synchronization to sports team ranking. Pairwise comparisons corresponding to matches in a competition can naturally be construed as edges in a directed graph (digraph), whose nodes represent competitors with an unknown rank or skill strength. However, existing methods addressing the rank estimation problem have thus far not utilized powerful neural network architectures to optimize ranking objectives. Hence, we propose to augment an algorithm with neural network, in particular graph neural network (GNN) for its coherence to the problem at hand. In this paper, we introduce GNNRank, a modeling framework that is compatible with any GNN capable of learning digraph embeddings, and we devise trainable objectives to encode ranking upsets/violations. This framework includes a ranking score estimation approach, and adds a useful inductive bias by unfolding the Fiedler vector computation of the graph constructed from a learnable similarity matrix. Experimental results on a wide range of data sets show that our methods attain competitive and often superior performance compared with existing approaches. It also shows promising transfer ability to new data based on the trained GNN model.
Why Propagate Alone? Parallel Use of Labels and Features on Graphs
Oct 14, 2021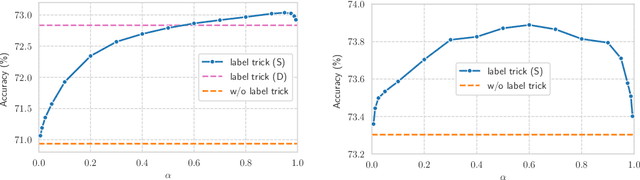



Graph neural networks (GNNs) and label propagation represent two interrelated modeling strategies designed to exploit graph structure in tasks such as node property prediction. The former is typically based on stacked message-passing layers that share neighborhood information to transform node features into predictive embeddings. In contrast, the latter involves spreading label information to unlabeled nodes via a parameter-free diffusion process, but operates independently of the node features. Given then that the material difference is merely whether features or labels are smoothed across the graph, it is natural to consider combinations of the two for improving performance. In this regard, it has recently been proposed to use a randomly-selected portion of the training labels as GNN inputs, concatenated with the original node features for making predictions on the remaining labels. This so-called label trick accommodates the parallel use of features and labels, and is foundational to many of the top-ranking submissions on the Open Graph Benchmark (OGB) leaderboard. And yet despite its wide-spread adoption, thus far there has been little attempt to carefully unpack exactly what statistical properties the label trick introduces into the training pipeline, intended or otherwise. To this end, we prove that under certain simplifying assumptions, the stochastic label trick can be reduced to an interpretable, deterministic training objective composed of two factors. The first is a data-fitting term that naturally resolves potential label leakage issues, while the second serves as a regularization factor conditioned on graph structure that adapts to graph size and connectivity. Later, we leverage this perspective to motivate a broader range of label trick use cases, and provide experiments to verify the efficacy of these extensions.
TraverseNet: Unifying Space and Time in Message Passing
Aug 25, 2021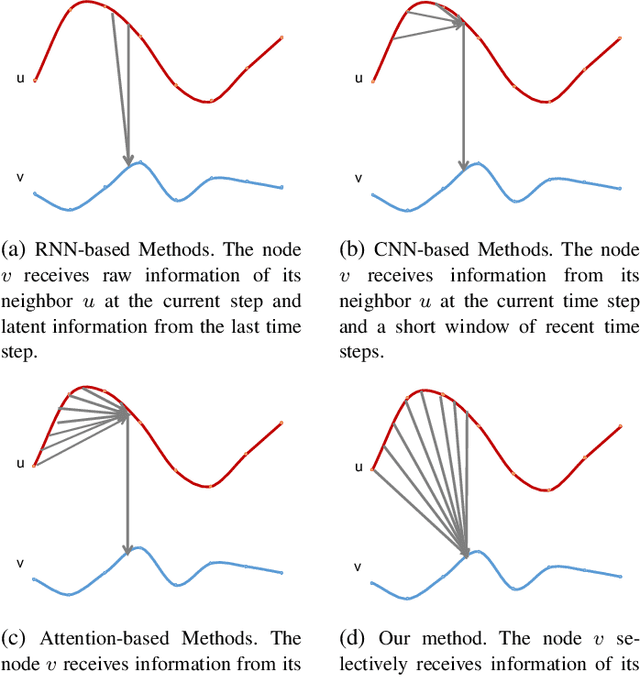
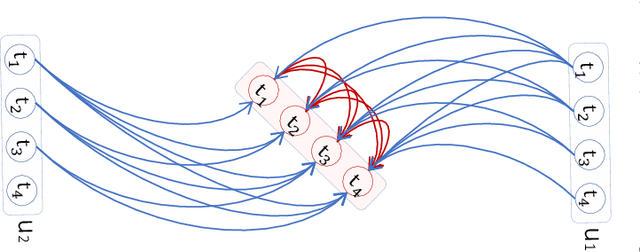

This paper aims to unify spatial dependency and temporal dependency in a non-Euclidean space while capturing the inner spatial-temporal dependencies for spatial-temporal graph data. For spatial-temporal attribute entities with topological structure, the space-time is consecutive and unified while each node's current status is influenced by its neighbors' past states over variant periods of each neighbor. Most spatial-temporal neural networks study spatial dependency and temporal correlation separately in processing, gravely impaired the space-time continuum, and ignore the fact that the neighbors' temporal dependency period for a node can be delayed and dynamic. To model this actual condition, we propose TraverseNet, a novel spatial-temporal graph neural network, viewing space and time as an inseparable whole, to mine spatial-temporal graphs while exploiting the evolving spatial-temporal dependencies for each node via message traverse mechanisms. Experiments with ablation and parameter studies have validated the effectiveness of the proposed TraverseNets, and the detailed implementation can be found from https://github.com/nnzhan/TraverseNet.
Graph Neural Networks Inspired by Classical Iterative Algorithms
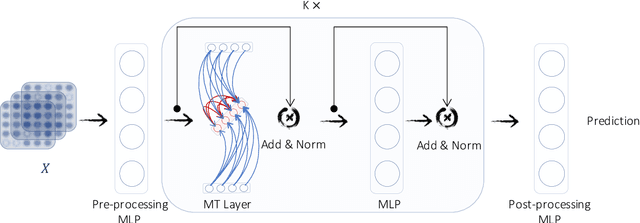
Mar 10, 2021
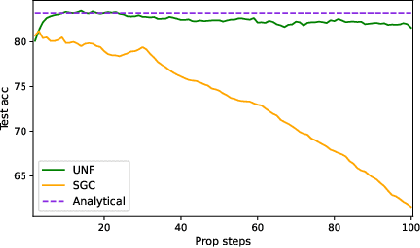
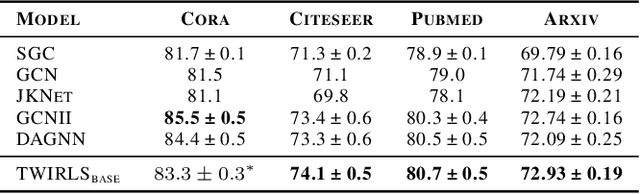
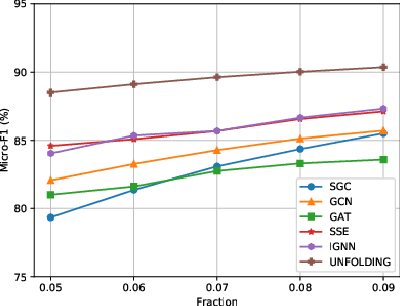
Despite the recent success of graph neural networks (GNN), common architectures often exhibit significant limitations, including sensitivity to oversmoothing, long-range dependencies, and spurious edges, e.g., as can occur as a result of graph heterophily or adversarial attacks. To at least partially address these issues within a simple transparent framework, we consider a new family of GNN layers designed to mimic and integrate the update rules of two classical iterative algorithms, namely, proximal gradient descent and iterative reweighted least squares (IRLS). The former defines an extensible base GNN architecture that is immune to oversmoothing while nonetheless capturing long-range dependencies by allowing arbitrary propagation steps. In contrast, the latter produces a novel attention mechanism that is explicitly anchored to an underlying end-toend energy function, contributing stability with respect to edge uncertainty. When combined we obtain an extremely simple yet robust model that we evaluate across disparate scenarios including standardized benchmarks, adversarially-perturbated graphs, graphs with heterophily, and graphs involving long-range dependencies. In doing so, we compare against SOTA GNN approaches that have been explicitly designed for the respective task, achieving competitive or superior node classification accuracy.
A Biased Graph Neural Network Sampler with Near-Optimal Regret
Mar 01, 2021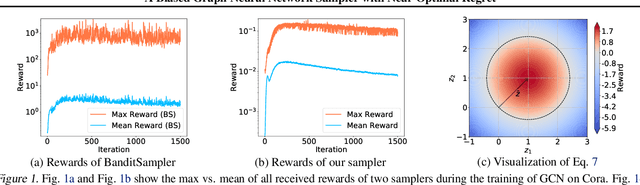

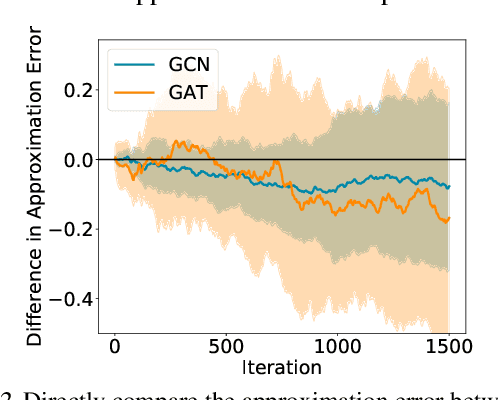

Graph neural networks (GNN) have recently emerged as a vehicle for applying deep network architectures to graph and relational data. However, given the increasing size of industrial datasets, in many practical situations, the message passing computations required for sharing information across GNN layers are no longer scalable. Although various sampling methods have been introduced to approximate full-graph training within a tractable budget, there remain unresolved complications such as high variances and limited theoretical guarantees. To address these issues, we build upon existing work and treat GNN neighbor sampling as a multi-armed bandit problem but with a newly-designed reward function that introduces some degree of bias designed to reduce variance and avoid unstable, possibly-unbounded payouts. And unlike prior bandit-GNN use cases, the resulting policy leads to near-optimal regret while accounting for the GNN training dynamics introduced by SGD. From a practical standpoint, this translates into lower variance estimates and competitive or superior test accuracy across several benchmarks.
DistDGL: Distributed Graph Neural Network Training for Billion-Scale Graphs
Oct 16, 2020
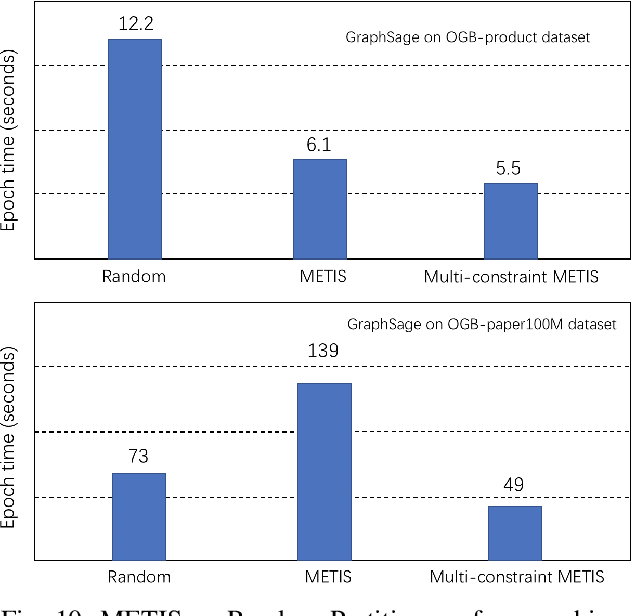
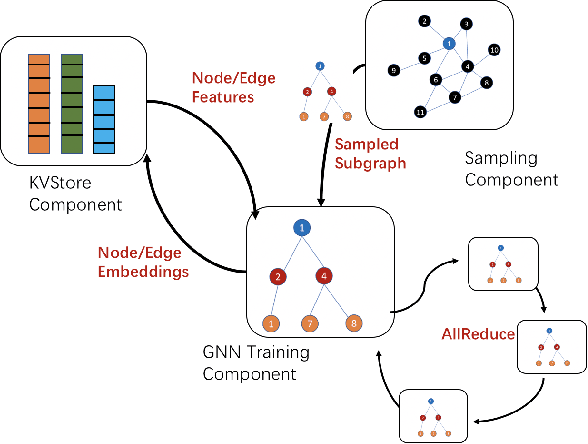
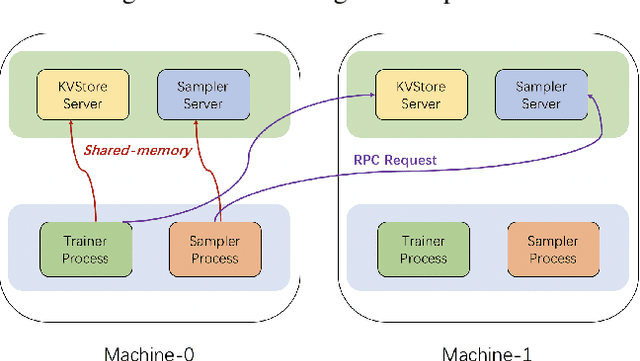
Graph neural networks (GNN) have shown great success in learning from graph-structured data. They are widely used in various applications, such as recommendation, fraud detection, and search. In these domains, the graphs are typically large, containing hundreds of millions of nodes and several billions of edges. To tackle this challenge, we develop DistDGL, a system for training GNNs in a mini-batch fashion on a cluster of machines. DistDGL is based on the Deep Graph Library (DGL), a popular GNN development framework. DistDGL distributes the graph and its associated data (initial features and embeddings) across the machines and uses this distribution to derive a computational decomposition by following an owner-compute rule. DistDGL follows a synchronous training approach and allows ego-networks forming the mini-batches to include non-local nodes. To minimize the overheads associated with distributed computations, DistDGL uses a high-quality and light-weight min-cut graph partitioning algorithm along with multiple balancing constraints. This allows it to reduce communication overheads and statically balance the computations. It further reduces the communication by replicating halo nodes and by using sparse embedding updates. The combination of these design choices allows DistDGL to train high-quality models while achieving high parallel efficiency and memory scalability. We demonstrate our optimizations on both inductive and transductive GNN models. Our results show that DistDGL achieves linear speedup without compromising model accuracy and requires only 13 seconds to complete a training epoch for a graph with 100 million nodes and 3 billion edges on a cluster with 16 machines.
BP-Transformer: Modelling Long-Range Context via Binary Partitioning
Nov 11, 2019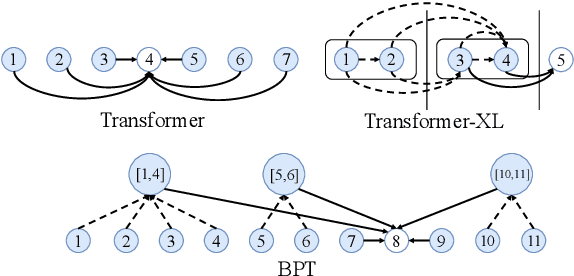
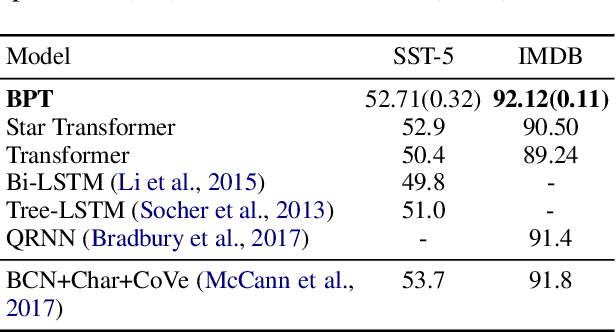


The Transformer model is widely successful on many natural language processing tasks. However, the quadratic complexity of self-attention limit its application on long text. In this paper, adopting a fine-to-coarse attention mechanism on multi-scale spans via binary partitioning (BP), we propose BP-Transformer (BPT for short). BPT yields $O(k\cdot n\log (n/k))$ connections where $k$ is a hyperparameter to control the density of attention. BPT has a good balance between computation complexity and model capacity. A series of experiments on text classification, machine translation and language modeling shows BPT has a superior performance for long text than previous self-attention models. Our code, hyperparameters and CUDA kernels for sparse attention are available in PyTorch.
Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs
Sep 03, 2019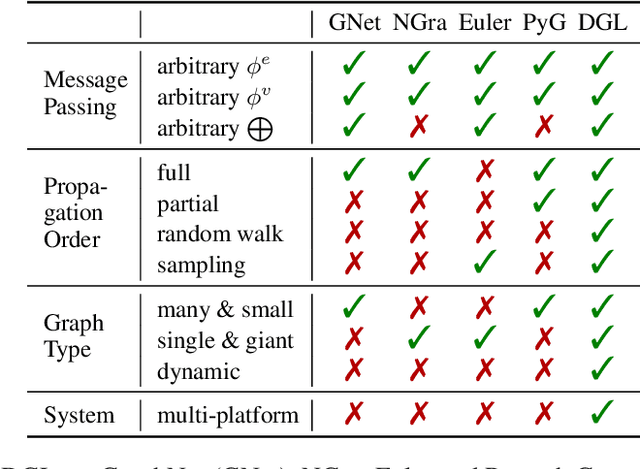
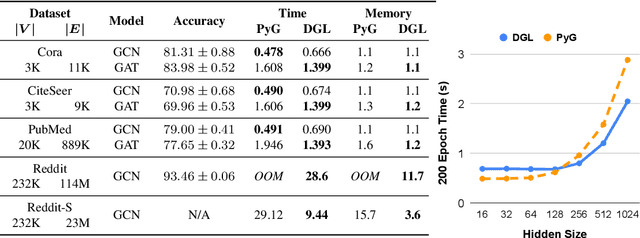
Accelerating research in the emerging field of deep graph learning requires new tools. Such systems should support graph as the core abstraction and take care to maintain both forward (i.e. supporting new research ideas) and backward (i.e. integration with existing components) compatibility. In this paper, we present Deep Graph Library (DGL). DGL enables arbitrary message handling and mutation operators, flexible propagation rules, and is framework agnostic so as to leverage high-performance tensor, autograd operations, and other feature extraction modules already available in existing frameworks. DGL carefully handles the sparse and irregular graph structure, deals with graphs big and small which may change dynamically, fuses operations, and performs auto-batching, all to take advantages of modern hardware. DGL has been tested on a variety of models, including but not limited to the popular Graph Neural Networks (GNN) and its variants, with promising speed, memory footprint and scalability.
First Step toward Model-Free, Anonymous Object Tracking with Recurrent Neural Networks
Nov 25, 2015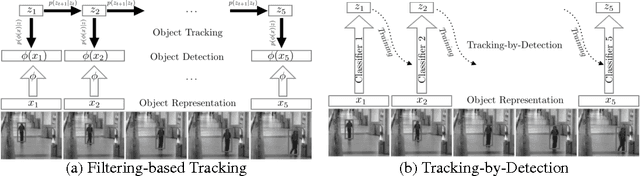
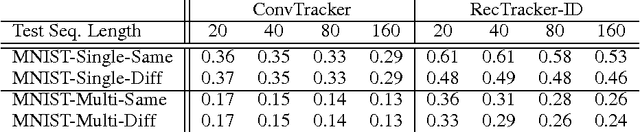
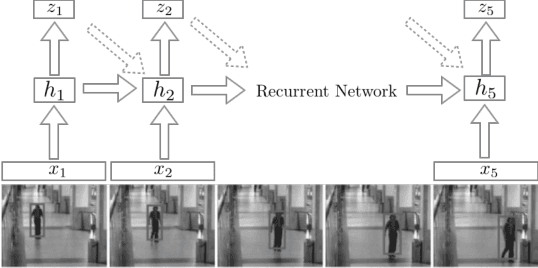
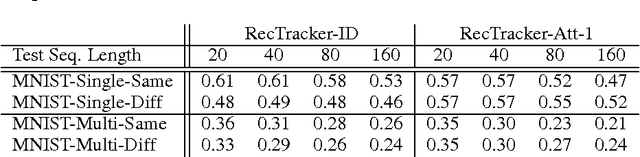
In this paper, we propose and study a novel visual object tracking approach based on convolutional networks and recurrent networks. The proposed approach is distinct from the existing approaches to visual object tracking, such as filtering-based ones and tracking-by-detection ones, in the sense that the tracking system is explicitly trained off-line to track anonymous objects in a noisy environment. The proposed visual tracking model is end-to-end trainable, minimizing any adversarial effect from mismatches in object representation and between the true underlying dynamics and learning dynamics. We empirically show that the proposed tracking approach works well in various scenarios by generating artificial video sequences with varying conditions; the number of objects, amount of noise and the match between the training shapes and test shapes.