 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Link Prediction via GNN Layers Induced by Negative Sampling
Oct 14, 2023Graph neural networks (GNNs) for link prediction can loosely be divided into two broad categories. First, \emph{node-wise} architectures pre-compute individual embeddings for each node that are later combined by a simple decoder to make predictions. While extremely efficient at inference time (since node embeddings are only computed once and repeatedly reused), model expressiveness is limited such that isomorphic nodes contributing to candidate edges may not be distinguishable, compromising accuracy. In contrast, \emph{edge-wise} methods rely on the formation of edge-specific subgraph embeddings to enrich the representation of pair-wise relationships, disambiguating isomorphic nodes to improve accuracy, but with the cost of increased model complexity. To better navigate this trade-off, we propose a novel GNN architecture whereby the \emph{forward pass} explicitly depends on \emph{both} positive (as is typical) and negative (unique to our approach) edges to inform more flexible, yet still cheap node-wise embeddings. This is achieved by recasting the embeddings themselves as minimizers of a forward-pass-specific energy function (distinct from the actual training loss) that favors separation of positive and negative samples. As demonstrated by extensive empirical evaluations, the resulting architecture retains the inference speed of node-wise models, while producing competitive accuracy with edge-wise alternatives.
From Hypergraph Energy Functions to Hypergraph Neural Networks
Jun 19, 2023



Hypergraphs are a powerful abstraction for representing higher-order interactions between entities of interest. To exploit these relationships in making downstream predictions, a variety of hypergraph neural network architectures have recently been proposed, in large part building upon precursors from the more traditional graph neural network (GNN) literature. Somewhat differently, in this paper we begin by presenting an expressive family of parameterized, hypergraph-regularized energy functions. We then demonstrate how minimizers of these energies effectively serve as node embeddings that, when paired with a parameterized classifier, can be trained end-to-end via a supervised bilevel optimization process. Later, we draw parallels between the implicit architecture of the predictive models emerging from the proposed bilevel hypergraph optimization, and existing GNN architectures in common use. Empirically, we demonstrate state-of-the-art results on various hypergraph node classification benchmarks. Code is available at https://github.com/yxzwang/PhenomNN.
Continuous sign language recognition based on cross-resolution knowledge distillation
Mar 13, 2023



The goal of continuous sign language recognition(CSLR) research is to apply CSLR models as a communication tool in real life, and the real-time requirement of the models is important. In this paper, we address the model real-time problem through cross-resolution knowledge distillation. In our study, we found that keeping the frame-level feature scales consistent between the output of the student network and the teacher network is better than recovering the frame-level feature sizes for feature distillation. Based on this finding, we propose a new frame-level feature extractor that keeps the output frame-level features at the same scale as the output of by the teacher network. We further combined with the TSCM+2D hybrid convolution proposed in our previous study to form a new lightweight end-to-end CSLR network-Low resolution input net(LRINet). It is then used to combine cross-resolution knowledge distillation and traditional knowledge distillation methods to form a CSLR model based on cross-resolution knowledge distillation (CRKD). The CRKD uses high-resolution frames as input to the teacher network for training, locks the weights after training, and then uses low-resolution frames as input to the student network LRINet to perform knowledge distillation on frame-level features and classification features respectively. Experiments on two large-scale continuous sign language datasets have proved the effectiveness of CRKD. Compared with the model with high-resolution data as input, the calculation amount, parameter amount and inference time of the model have been significantly reduced under the same experimental conditions, while ensuring the accuracy of the model, and has achieved very competitive results in comparison with other advanced methods.
ReFresh: Reducing Memory Access from Exploiting Stable Historical Embeddings for Graph Neural Network Training
Jan 19, 2023



A key performance bottleneck when training graph neural network (GNN) models on large, real-world graphs is loading node features onto a GPU. Due to limited GPU memory, expensive data movement is necessary to facilitate the storage of these features on alternative devices with slower access (e.g. CPU memory). Moreover, the irregularity of graph structures contributes to poor data locality which further exacerbates the problem. Consequently, existing frameworks capable of efficiently training large GNN models usually incur a significant accuracy degradation because of the inevitable shortcuts involved. To address these limitations, we instead propose ReFresh, a general-purpose GNN mini-batch training framework that leverages a historical cache for storing and reusing GNN node embeddings instead of re-computing them through fetching raw features at every iteration. Critical to its success, the corresponding cache policy is designed, using a combination of gradient-based and staleness criteria, to selectively screen those embeddings which are relatively stable and can be cached, from those that need to be re-computed to reduce estimation errors and subsequent downstream accuracy loss. When paired with complementary system enhancements to support this selective historical cache, ReFresh is able to accelerate the training speed on large graph datasets such as ogbn-papers100M and MAG240M by 4.6x up to 23.6x and reduce the memory access by 64.5% (85.7% higher than a raw feature cache), with less than 1% influence on test accuracy.
Refined Edge Usage of Graph Neural Networks for Edge Prediction
Dec 25, 2022



Graph Neural Networks (GNNs), originally proposed for node classification, have also motivated many recent works on edge prediction (a.k.a., link prediction). However, existing methods lack elaborate design regarding the distinctions between two tasks that have been frequently overlooked: (i) edges only constitute the topology in the node classification task but can be used as both the topology and the supervisions (i.e., labels) in the edge prediction task; (ii) the node classification makes prediction over each individual node, while the edge prediction is determinated by each pair of nodes. To this end, we propose a novel edge prediction paradigm named Edge-aware Message PassIng neuRal nEtworks (EMPIRE). Concretely, we first introduce an edge splitting technique to specify use of each edge where each edge is solely used as either the topology or the supervision (named as topology edge or supervision edge). We then develop a new message passing mechanism that generates the messages to source nodes (through topology edges) being aware of target nodes (through supervision edges). In order to emphasize the differences between pairs connected by supervision edges and pairs unconnected, we further weight the messages to highlight the relative ones that can reflect the differences. In addition, we design a novel negative node-pair sampling trick that efficiently samples 'hard' negative instances in the supervision instances, and can significantly improve the performance. Experimental results verify that the proposed method can significantly outperform existing state-of-the-art models regarding the edge prediction task on multiple homogeneous and heterogeneous graph datasets.
Temporal superimposed crossover module for effective continuous sign language
Nov 07, 2022The ultimate goal of continuous sign language recognition(CSLR) is to facilitate the communication between special people and normal people, which requires a certain degree of real-time and deploy-ability of the model. However, in the previous research on CSLR, little attention has been paid to the real-time and deploy-ability. In order to improve the real-time and deploy-ability of the model, this paper proposes a zero parameter, zero computation temporal superposition crossover module(TSCM), and combines it with 2D convolution to form a "TSCM+2D convolution" hybrid convolution, which enables 2D convolution to have strong spatial-temporal modelling capability with zero parameter increase and lower deployment cost compared with other spatial-temporal convolutions. The overall CSLR model based on TSCM is built on the improved ResBlockT network in this paper. The hybrid convolution of "TSCM+2D convolution" is applied to the ResBlock of the ResNet network to form the new ResBlockT, and random gradient stop and multi-level CTC loss are introduced to train the model, which reduces the final recognition WER while reducing the training memory usage, and extends the ResNet network from image classification task to video recognition task. In addition, this study is the first in CSLR to use only 2D convolution extraction of sign language video temporal-spatial features for end-to-end learning for recognition. Experiments on two large-scale continuous sign language datasets demonstrate the effectiveness of the proposed method and achieve highly competitive results.
Continuous Sign Language Recognition via Temporal Super-Resolution Network
Jul 03, 2022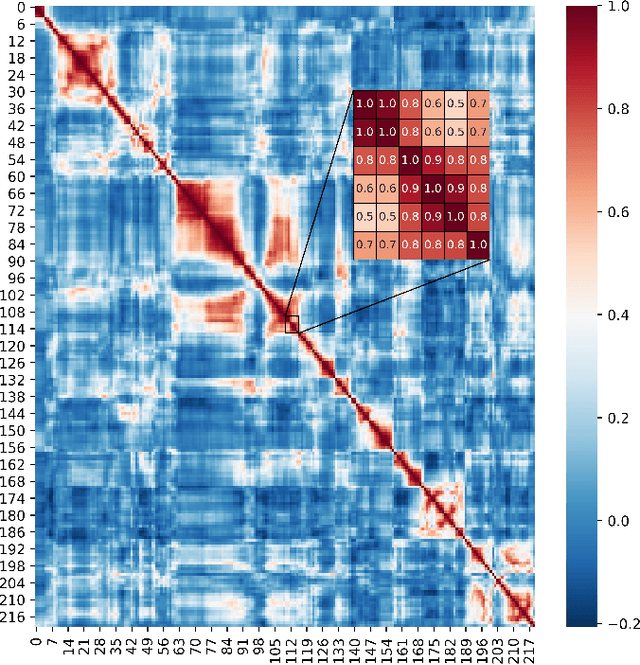
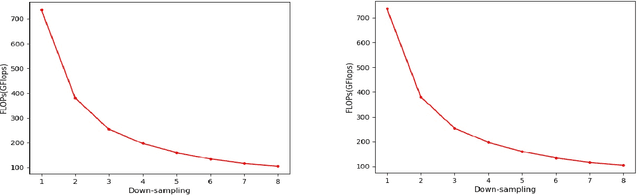
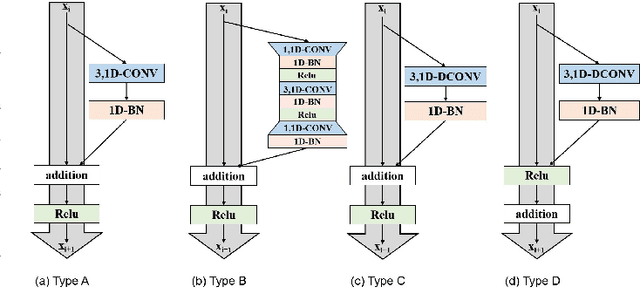
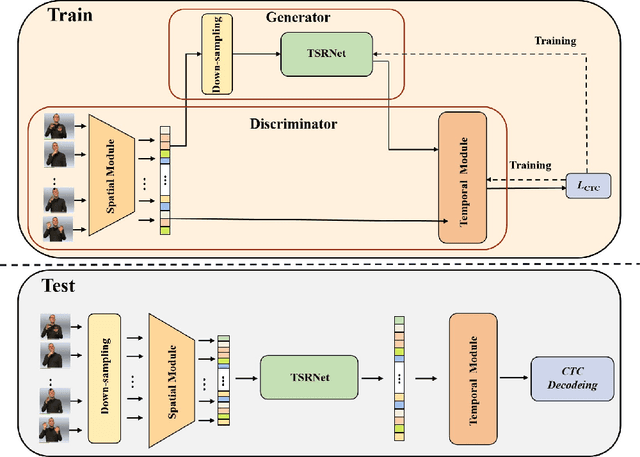
Aiming at the problem that the spatial-temporal hierarchical continuous sign language recognition model based on deep learning has a large amount of computation, which limits the real-time application of the model, this paper proposes a temporal super-resolution network(TSRNet). The data is reconstructed into a dense feature sequence to reduce the overall model computation while keeping the final recognition accuracy loss to a minimum. The continuous sign language recognition model(CSLR) via TSRNet mainly consists of three parts: frame-level feature extraction, time series feature extraction and TSRNet, where TSRNet is located between frame-level feature extraction and time-series feature extraction, which mainly includes two branches: detail descriptor and rough descriptor. The sparse frame-level features are fused through the features obtained by the two designed branches as the reconstructed dense frame-level feature sequence, and the connectionist temporal classification(CTC) loss is used for training and optimization after the time-series feature extraction part. To better recover semantic-level information, the overall model is trained with the self-generating adversarial training method proposed in this paper to reduce the model error rate. The training method regards the TSRNet as the generator, and the frame-level processing part and the temporal processing part as the discriminator. In addition, in order to unify the evaluation criteria of model accuracy loss under different benchmarks, this paper proposes word error rate deviation(WERD), which takes the error rate between the estimated word error rate (WER) and the reference WER obtained by the reconstructed frame-level feature sequence and the complete original frame-level feature sequence as the WERD. Experiments on two large-scale sign language datasets demonstrate the effectiveness of the proposed model.
Descent Steps of a Relation-Aware Energy Produce Heterogeneous Graph Neural Networks
Jun 24, 2022

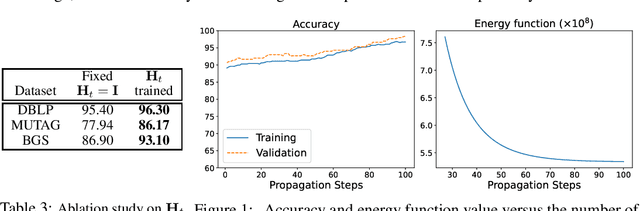
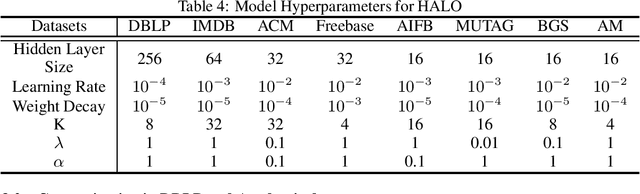
Heterogeneous graph neural networks (GNNs) achieve strong performance on node classification tasks in a semi-supervised learning setting. However, as in the simpler homogeneous GNN case, message-passing-based heterogeneous GNNs may struggle to balance between resisting the oversmoothing occuring in deep models and capturing long-range dependencies graph structured data. Moreover, the complexity of this trade-off is compounded in the heterogeneous graph case due to the disparate heterophily relationships between nodes of different types. To address these issues, we proposed a novel heterogeneous GNN architecture in which layers are derived from optimization steps that descend a novel relation-aware energy function. The corresponding minimizer is fully differentiable with respect to the energy function parameters, such that bilevel optimization can be applied to effectively learn a functional form whose minimum provides optimal node representations for subsequent classification tasks. In particular, this methodology allows us to model diverse heterophily relationships between different node types while avoiding oversmoothing effects. Experimental results on 8 heterogeneous graph benchmarks demonstrates that our proposed method can achieve competitive node classification accuracy.
Learning Enhanced Representations for Tabular Data via Neighborhood Propagation
Jun 14, 2022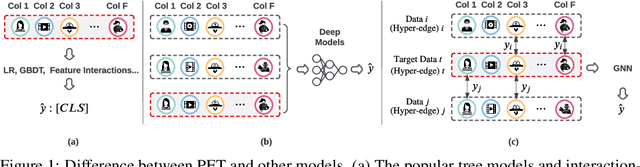
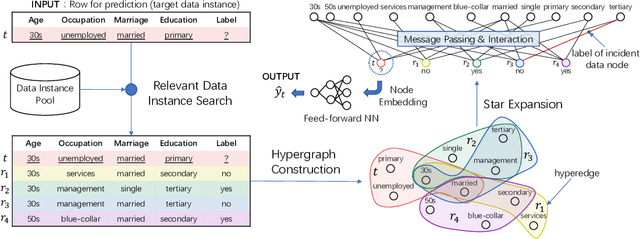
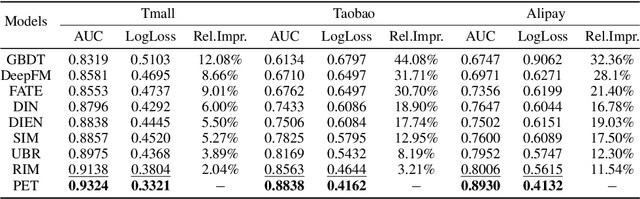
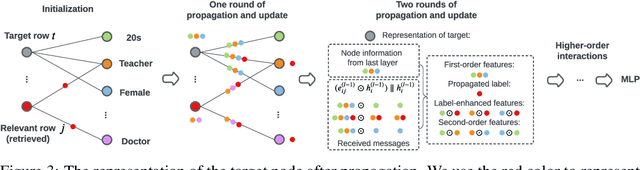
Prediction over tabular data is an essential and fundamental problem in many important downstream tasks. However, existing methods either take a data instance of the table independently as input or do not fully utilize the multi-rows features and labels to directly change and enhance the target data representations. In this paper, we propose to 1) construct a hypergraph from relevant data instance retrieval to model the cross-row and cross-column patterns of those instances, and 2) perform message Propagation to Enhance the target data instance representation for Tabular prediction tasks. Specifically, our specially-designed message propagation step benefits from 1) fusion of label and features during propagation, and 2) locality-aware high-order feature interactions. Experiments on two important tabular data prediction tasks validate the superiority of the proposed PET model against other baselines. Additionally, we demonstrate the effectiveness of the model components and the feature enhancement ability of PET via various ablation studies and visualizations. The code is included in https://github.com/KounianhuaDu/PET.
CEP3: Community Event Prediction with Neural Point Process on Graph
May 21, 2022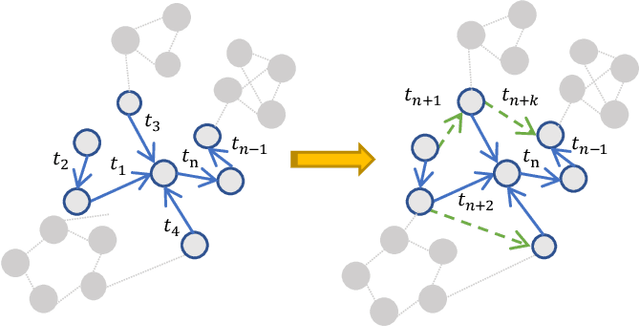
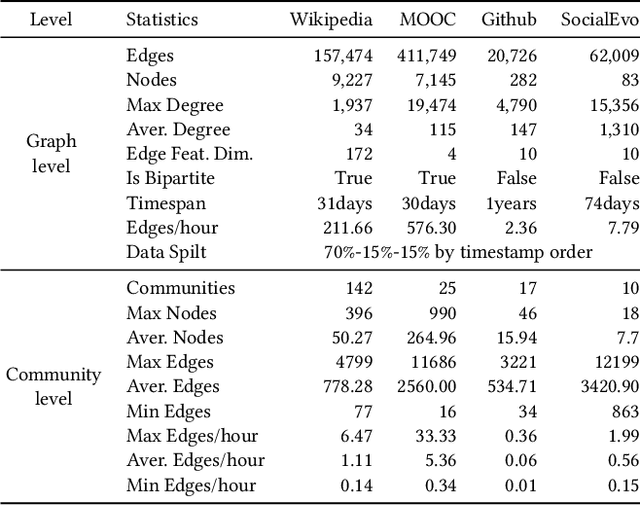
Many real world applications can be formulated as event forecasting on Continuous Time Dynamic Graphs (CTDGs) where the occurrence of a timed event between two entities is represented as an edge along with its occurrence timestamp in the graphs.However, most previous works approach the problem in compromised settings, either formulating it as a link prediction task on the graph given the event time or a time prediction problem given which event will happen next. In this paper, we propose a novel model combining Graph Neural Networks and Marked Temporal Point Process (MTPP) that jointly forecasts multiple link events and their timestamps on communities over a CTDG. Moreover, to scale our model to large graphs, we factorize the jointly event prediction problem into three easier conditional probability modeling problems.To evaluate the effectiveness of our model and the rationale behind such a decomposition, we establish a set of benchmarks and evaluation metrics for this event forecasting task. Our experiments demonstrate the superior performance of our model in terms of both model accuracy and training efficiency.