 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo See or To Please: Uncovering Visual Sycophancy and Split Beliefs in VLMs
Mar 19, 2026When VLMs answer correctly, do they genuinely rely on visual information or exploit language shortcuts? We introduce the Tri-Layer Diagnostic Framework, which disentangles hallucination sources via three metrics: Latent Anomaly Detection (perceptual awareness), Visual Necessity Score (visual dependency, measured via KL divergence), and Competition Score (conflict between visual grounding and instruction following). Using counterfactual interventions (blind, noise, and conflict images) across 7 VLMs and 7,000 model-sample pairs, our taxonomy reveals that 69.6% of samples exhibit Visual Sycophancy--models detect visual anomalies but hallucinate to satisfy user expectations--while zero samples show Robust Refusal, indicating alignment training has systematically suppressed truthful uncertainty acknowledgment. A scaling analysis (Qwen2.5-VL 7B to 72B) shows larger models reduce Language Shortcuts but amplify Visual Sycophancy, demonstrating scale alone cannot resolve the grounding problem. Diagnostic scores further enable a post-hoc selective prediction strategy achieving up to +9.5pp accuracy at 50% coverage with no additional training cost.
Motion-Adaptive Temporal Attention for Lightweight Video Generation with Stable Diffusion
Mar 18, 2026We present a motion-adaptive temporal attention mechanism for parameter-efficient video generation built upon frozen Stable Diffusion models. Rather than treating all video content uniformly, our method dynamically adjusts temporal attention receptive fields based on estimated motion content: high-motion sequences attend locally across frames to preserve rapidly changing details, while low-motion sequences attend globally to enforce scene consistency. We inject lightweight temporal attention modules into all UNet transformer blocks via a cascaded strategy -- global attention in down-sampling and middle blocks for semantic stabilization, motion-adaptive attention in up-sampling blocks for fine-grained refinement. Combined with temporally correlated noise initialization and motion-aware gating, the system adds only 25.8M trainable parameters (2.9\% of the base UNet) while achieving competitive results on WebVid validation when trained on 100K videos. We demonstrate that the standard denoising objective alone provides sufficient implicit temporal regularization, outperforming approaches that add explicit temporal consistency losses. Our ablation studies reveal a clear trade-off between noise correlation and motion amplitude, providing a practical inference-time control for diverse generation behaviors.
* 6 pages, 3 figures, 4 tables. Published at IS&T Electronic Imaging 2026, GENAI Track
Vision Backbone Enhancement via Multi-Stage Cross-Scale Attention
Aug 14, 2023



Convolutional neural networks (CNNs) and vision transformers (ViTs) have achieved remarkable success in various vision tasks. However, many architectures do not consider interactions between feature maps from different stages and scales, which may limit their performance. In this work, we propose a simple add-on attention module to overcome these limitations via multi-stage and cross-scale interactions. Specifically, the proposed Multi-Stage Cross-Scale Attention (MSCSA) module takes feature maps from different stages to enable multi-stage interactions and achieves cross-scale interactions by computing self-attention at different scales based on the multi-stage feature maps. Our experiments on several downstream tasks show that MSCSA provides a significant performance boost with modest additional FLOPs and runtime.
SMOF: Squeezing More Out of Filters Yields Hardware-Friendly CNN Pruning
Oct 21, 2021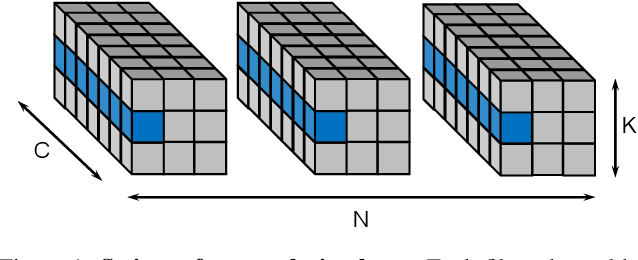
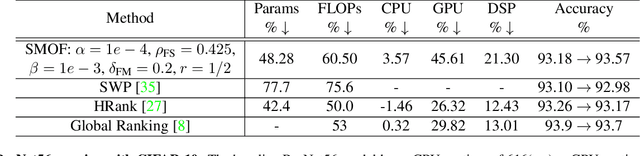
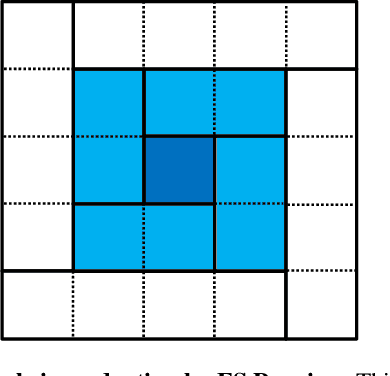
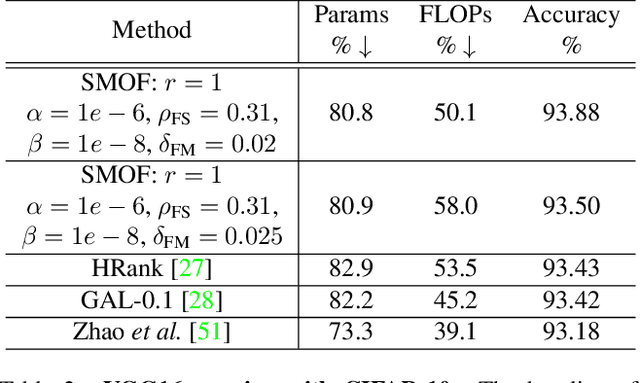
For many years, the family of convolutional neural networks (CNNs) has been a workhorse in deep learning. Recently, many novel CNN structures have been designed to address increasingly challenging tasks. To make them work efficiently on edge devices, researchers have proposed various structured network pruning strategies to reduce their memory and computational cost. However, most of them only focus on reducing the number of filter channels per layer without considering the redundancy within individual filter channels. In this work, we explore pruning from another dimension, the kernel size. We develop a CNN pruning framework called SMOF, which Squeezes More Out of Filters by reducing both kernel size and the number of filter channels. Notably, SMOF is friendly to standard hardware devices without any customized low-level implementations, and the pruning effort by kernel size reduction does not suffer from the fixed-size width constraint in SIMD units of general-purpose processors. The pruned networks can be deployed effortlessly with significant running time reduction. We also support these claims via extensive experiments on various CNN structures and general-purpose processors for mobile devices.
RobustFusion: Robust Volumetric Performance Reconstruction under Human-object Interactions from Monocular RGBD Stream
Apr 30, 2021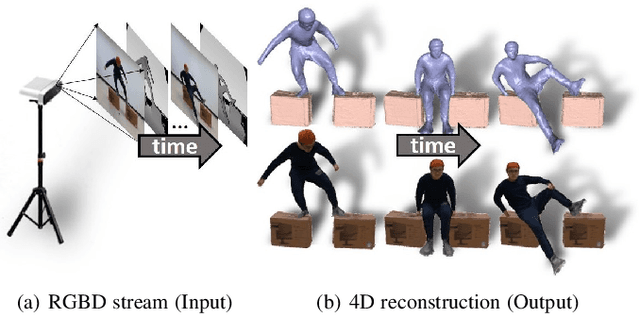
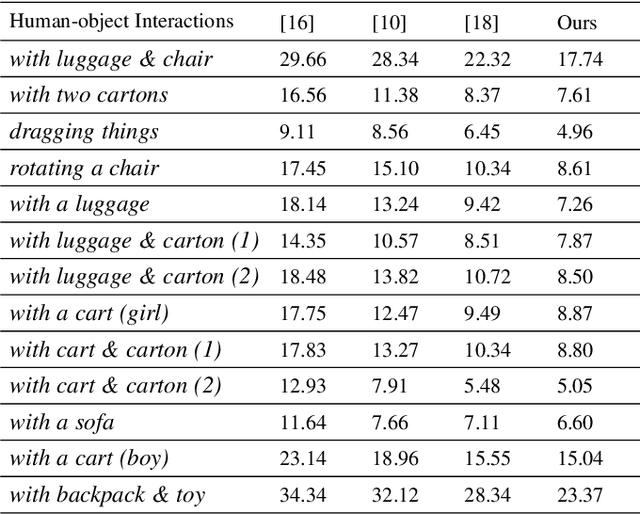
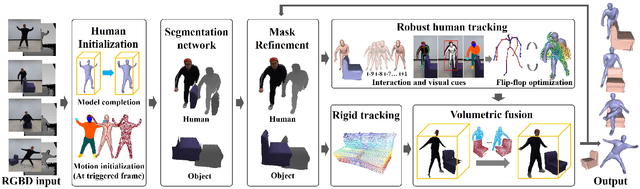

High-quality 4D reconstruction of human performance with complex interactions to various objects is essential in real-world scenarios, which enables numerous immersive VR/AR applications. However, recent advances still fail to provide reliable performance reconstruction, suffering from challenging interaction patterns and severe occlusions, especially for the monocular setting. To fill this gap, in this paper, we propose RobustFusion, a robust volumetric performance reconstruction system for human-object interaction scenarios using only a single RGBD sensor, which combines various data-driven visual and interaction cues to handle the complex interaction patterns and severe occlusions. We propose a semantic-aware scene decoupling scheme to model the occlusions explicitly, with a segmentation refinement and robust object tracking to prevent disentanglement uncertainty and maintain temporal consistency. We further introduce a robust performance capture scheme with the aid of various data-driven cues, which not only enables re-initialization ability, but also models the complex human-object interaction patterns in a data-driven manner. To this end, we introduce a spatial relation prior to prevent implausible intersections, as well as data-driven interaction cues to maintain natural motions, especially for those regions under severe human-object occlusions. We also adopt an adaptive fusion scheme for temporally coherent human-object reconstruction with occlusion analysis and human parsing cue. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality 4D human performance reconstruction under complex human-object interactions whilst still maintaining the lightweight monocular setting.
PoP-Net: Pose over Parts Network for Multi-Person 3D Pose Estimation from a Depth Image
Dec 12, 2020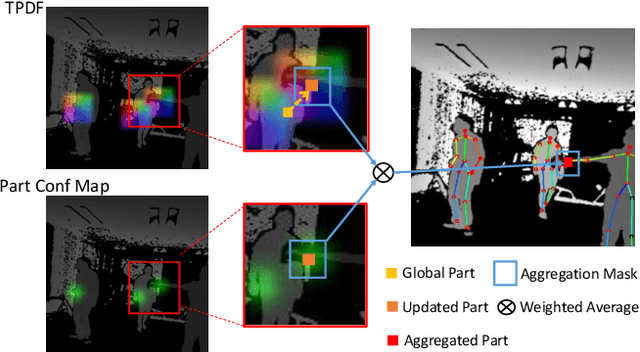
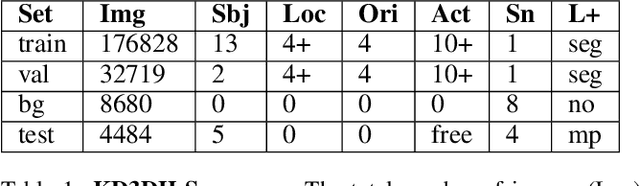

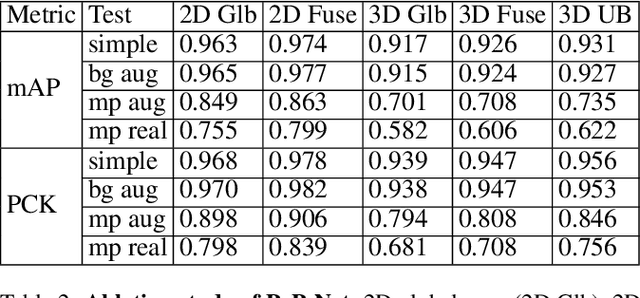
In this paper, a real-time method called PoP-Net is proposed to predict multi-person 3D poses from a depth image. PoP-Net learns to predict bottom-up part detection maps and top-down global poses in a single-shot framework. A simple and effective fusion process is applied to fuse the global poses and part detection. Specifically, a new part-level representation, called Truncated Part Displacement Field (TPDF), is introduced. It drags low-precision global poses towards more accurate part locations while maintaining the advantage of global poses in handling severe occlusion and truncation cases. A mode selection scheme is developed to automatically resolve the conflict between global poses and local detection. Finally, due to the lack of high-quality depth datasets for developing and evaluating multi-person 3D pose estimation methods, a comprehensive depth dataset with 3D pose labels is released. The dataset is designed to enable effective multi-person and background data augmentation such that the developed models are more generalizable towards uncontrolled real-world multi-person scenarios. We show that PoP-Net has significant advantages in efficiency for multi-person processing and achieves the state-of-the-art results both on the released challenging dataset and on the widely used ITOP dataset.
Object Detection in the Context of Mobile Augmented Reality
Aug 15, 2020In the past few years, numerous Deep Neural Network (DNN) models and frameworks have been developed to tackle the problem of real-time object detection from RGB images. Ordinary object detection approaches process information from the images only, and they are oblivious to the camera pose with regard to the environment and the scale of the environment. On the other hand, mobile Augmented Reality (AR) frameworks can continuously track a camera's pose within the scene and can estimate the correct scale of the environment by using Visual-Inertial Odometry (VIO). In this paper, we propose a novel approach that combines the geometric information from VIO with semantic information from object detectors to improve the performance of object detection on mobile devices. Our approach includes three components: (1) an image orientation correction method, (2) a scale-based filtering approach, and (3) an online semantic map. Each component takes advantage of the different characteristics of the VIO-based AR framework. We implemented the AR-enhanced features using ARCore and the SSD Mobilenet model on Android phones. To validate our approach, we manually labeled objects in image sequences taken from 12 room-scale AR sessions. The results show that our approach can improve on the accuracy of generic object detectors by 12% on our dataset.