 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Projection Fusion and Refinement Network for Salient Object Detection in 360° Omnidirectional Image
Dec 23, 2022



Salient object detection (SOD) aims to determine the most visually attractive objects in an image. With the development of virtual reality technology, 360{\deg} omnidirectional image has been widely used, but the SOD task in 360{\deg} omnidirectional image is seldom studied due to its severe distortions and complex scenes. In this paper, we propose a Multi-Projection Fusion and Refinement Network (MPFR-Net) to detect the salient objects in 360{\deg} omnidirectional image. Different from the existing methods, the equirectangular projection image and four corresponding cube-unfolding images are embedded into the network simultaneously as inputs, where the cube-unfolding images not only provide supplementary information for equirectangular projection image, but also ensure the object integrity of the cube-map projection. In order to make full use of these two projection modes, a Dynamic Weighting Fusion (DWF) module is designed to adaptively integrate the features of different projections in a complementary and dynamic manner from the perspective of inter and intra features. Furthermore, in order to fully explore the way of interaction between encoder and decoder features, a Filtration and Refinement (FR) module is designed to suppress the redundant information between the feature itself and the feature. Experimental results on two omnidirectional datasets demonstrate that the proposed approach outperforms the state-of-the-art methods both qualitatively and quantitatively.
Progressive Multi-resolution Loss for Crowd Counting
Dec 08, 2022



Crowd counting is usually handled in a density map regression fashion, which is supervised via a L2 loss between the predicted density map and ground truth. To effectively regulate models, various improved L2 loss functions have been proposed to find a better correspondence between predicted density and annotation positions. In this paper, we propose to predict the density map at one resolution but measure the density map at multiple resolutions. By maximizing the posterior probability in such a setting, we obtain a log-formed multi-resolution L2-difference loss, where the traditional single-resolution L2 loss is its particular case. We mathematically prove it is superior to a single-resolution L2 loss. Without bells and whistles, the proposed loss substantially improves several baselines and performs favorably compared to state-of-the-art methods on four crowd counting datasets, ShanghaiTech A & B, UCF-QNRF, and JHU-Crowd++.
Learning to Dub Movies via Hierarchical Prosody Models
Dec 08, 2022Given a piece of text, a video clip and a reference audio, the movie dubbing (also known as visual voice clone V2C) task aims to generate speeches that match the speaker's emotion presented in the video using the desired speaker voice as reference. V2C is more challenging than conventional text-to-speech tasks as it additionally requires the generated speech to exactly match the varying emotions and speaking speed presented in the video. Unlike previous works, we propose a novel movie dubbing architecture to tackle these problems via hierarchical prosody modelling, which bridges the visual information to corresponding speech prosody from three aspects: lip, face, and scene. Specifically, we align lip movement to the speech duration, and convey facial expression to speech energy and pitch via attention mechanism based on valence and arousal representations inspired by recent psychology findings. Moreover, we design an emotion booster to capture the atmosphere from global video scenes. All these embeddings together are used to generate mel-spectrogram and then convert to speech waves via existing vocoder. Extensive experimental results on the Chem and V2C benchmark datasets demonstrate the favorable performance of the proposed method. The source code and trained models will be released to the public.
Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection
Dec 08, 2022



Weakly supervised video anomaly detection aims to identify abnormal events in videos using only video-level labels. Recently, two-stage self-training methods have achieved significant improvements by self-generating pseudo labels and self-refining anomaly scores with these labels. As the pseudo labels play a crucial role, we propose an enhancement framework by exploiting completeness and uncertainty properties for effective self-training. Specifically, we first design a multi-head classification module (each head serves as a classifier) with a diversity loss to maximize the distribution differences of predicted pseudo labels across heads. This encourages the generated pseudo labels to cover as many abnormal events as possible. We then devise an iterative uncertainty pseudo label refinement strategy, which improves not only the initial pseudo labels but also the updated ones obtained by the desired classifier in the second stage. Extensive experimental results demonstrate the proposed method performs favorably against state-of-the-art approaches on the UCF-Crime, TAD, and XD-Violence benchmark datasets.
Consistency-Aware Anchor Pyramid Network for Crowd Localization
Dec 08, 2022



Crowd localization aims to predict the spatial position of humans in a crowd scenario. We observe that the performance of existing methods is challenged from two aspects: (i) ranking inconsistency between test and training phases; and (ii) fixed anchor resolution may underfit or overfit crowd densities of local regions. To address these problems, we design a supervision target reassignment strategy for training to reduce ranking inconsistency and propose an anchor pyramid scheme to adaptively determine the anchor density in each image region. Extensive experimental results on three widely adopted datasets (ShanghaiTech A\&B, JHU-CROWD++, UCF-QNRF) demonstrate the favorable performance against several state-of-the-art methods.
Dist-PU: Positive-Unlabeled Learning from a Label Distribution Perspective
Dec 06, 2022

Positive-Unlabeled (PU) learning tries to learn binary classifiers from a few labeled positive examples with many unlabeled ones. Compared with ordinary semi-supervised learning, this task is much more challenging due to the absence of any known negative labels. While existing cost-sensitive-based methods have achieved state-of-the-art performances, they explicitly minimize the risk of classifying unlabeled data as negative samples, which might result in a negative-prediction preference of the classifier. To alleviate this issue, we resort to a label distribution perspective for PU learning in this paper. Noticing that the label distribution of unlabeled data is fixed when the class prior is known, it can be naturally used as learning supervision for the model. Motivated by this, we propose to pursue the label distribution consistency between predicted and ground-truth label distributions, which is formulated by aligning their expectations. Moreover, we further adopt the entropy minimization and Mixup regularization to avoid the trivial solution of the label distribution consistency on unlabeled data and mitigate the consequent confirmation bias. Experiments on three benchmark datasets validate the effectiveness of the proposed method.Code available at: https://github.com/Ray-rui/Dist-PU-Positive-Unlabeled-Learning-from-a-Label-Distribution-Perspective.
Asymptotically Unbiased Instance-wise Regularized Partial AUC Optimization: Theory and Algorithm
Oct 11, 2022
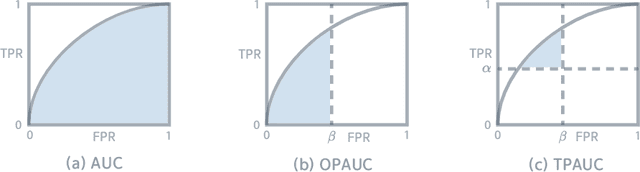
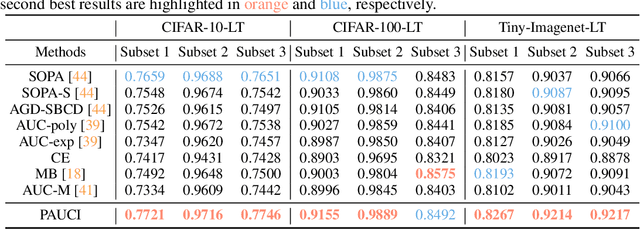
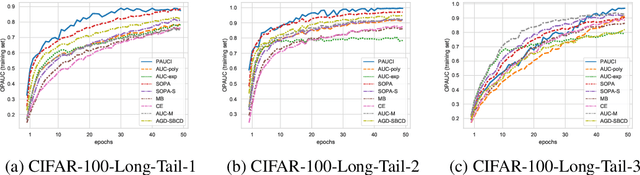
The Partial Area Under the ROC Curve (PAUC), typically including One-way Partial AUC (OPAUC) and Two-way Partial AUC (TPAUC), measures the average performance of a binary classifier within a specific false positive rate and/or true positive rate interval, which is a widely adopted measure when decision constraints must be considered. Consequently, PAUC optimization has naturally attracted increasing attention in the machine learning community within the last few years. Nonetheless, most of the existing methods could only optimize PAUC approximately, leading to inevitable biases that are not controllable. Fortunately, a recent work presents an unbiased formulation of the PAUC optimization problem via distributional robust optimization. However, it is based on the pair-wise formulation of AUC, which suffers from the limited scalability w.r.t. sample size and a slow convergence rate, especially for TPAUC. To address this issue, we present a simpler reformulation of the problem in an asymptotically unbiased and instance-wise manner. For both OPAUC and TPAUC, we come to a nonconvex strongly concave minimax regularized problem of instance-wise functions. On top of this, we employ an efficient solver enjoys a linear per-iteration computational complexity w.r.t. the sample size and a time-complexity of $O(\epsilon^{-1/3})$ to reach a $\epsilon$ stationary point. Furthermore, we find that the minimax reformulation also facilitates the theoretical analysis of generalization error as a byproduct. Compared with the existing results, we present new error bounds that are much easier to prove and could deal with hypotheses with real-valued outputs. Finally, extensive experiments on several benchmark datasets demonstrate the effectiveness of our method.
Does Thermal Really Always Matter for RGB-T Salient Object Detection?
Oct 09, 2022
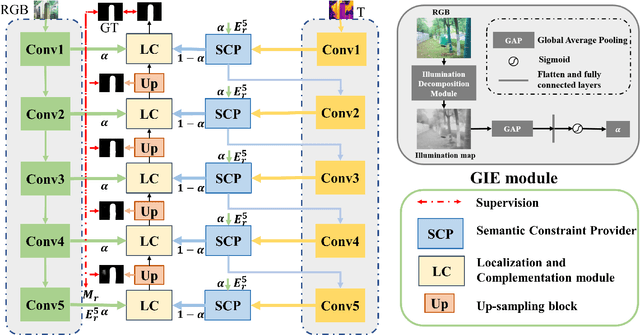
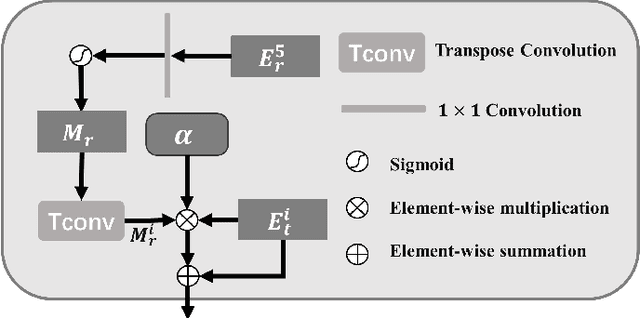

In recent years, RGB-T salient object detection (SOD) has attracted continuous attention, which makes it possible to identify salient objects in environments such as low light by introducing thermal image. However, most of the existing RGB-T SOD models focus on how to perform cross-modality feature fusion, ignoring whether thermal image is really always matter in SOD task. Starting from the definition and nature of this task, this paper rethinks the connotation of thermal modality, and proposes a network named TNet to solve the RGB-T SOD task. In this paper, we introduce a global illumination estimation module to predict the global illuminance score of the image, so as to regulate the role played by the two modalities. In addition, considering the role of thermal modality, we set up different cross-modality interaction mechanisms in the encoding phase and the decoding phase. On the one hand, we introduce a semantic constraint provider to enrich the semantics of thermal images in the encoding phase, which makes thermal modality more suitable for the SOD task. On the other hand, we introduce a two-stage localization and complementation module in the decoding phase to transfer object localization cue and internal integrity cue in thermal features to the RGB modality. Extensive experiments on three datasets show that the proposed TNet achieves competitive performance compared with 20 state-of-the-art methods.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
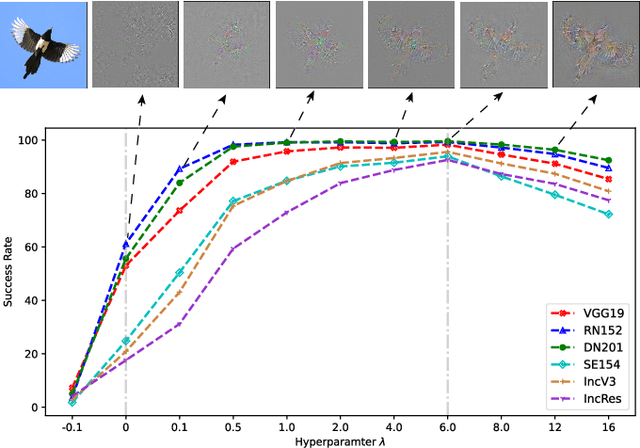
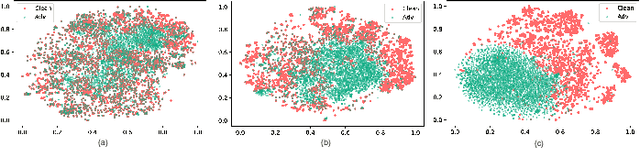
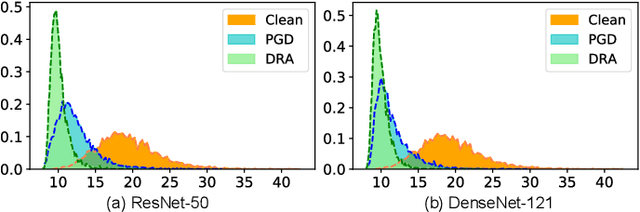
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
CIR-Net: Cross-modality Interaction and Refinement for RGB-D Salient Object Detection
Oct 06, 2022


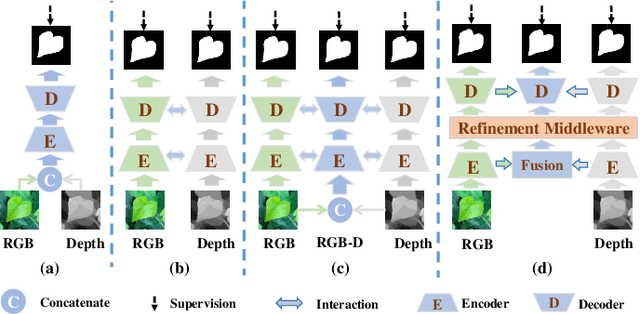
Focusing on the issue of how to effectively capture and utilize cross-modality information in RGB-D salient object detection (SOD) task, we present a convolutional neural network (CNN) model, named CIR-Net, based on the novel cross-modality interaction and refinement. For the cross-modality interaction, 1) a progressive attention guided integration unit is proposed to sufficiently integrate RGB-D feature representations in the encoder stage, and 2) a convergence aggregation structure is proposed, which flows the RGB and depth decoding features into the corresponding RGB-D decoding streams via an importance gated fusion unit in the decoder stage. For the cross-modality refinement, we insert a refinement middleware structure between the encoder and the decoder, in which the RGB, depth, and RGB-D encoder features are further refined by successively using a self-modality attention refinement unit and a cross-modality weighting refinement unit. At last, with the gradually refined features, we predict the saliency map in the decoder stage. Extensive experiments on six popular RGB-D SOD benchmarks demonstrate that our network outperforms the state-of-the-art saliency detectors both qualitatively and quantitatively.