 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircuit-Aware SAT Solving: Guiding CDCL via Conditional Probabilities
Aug 06, 2025



Circuit Satisfiability (CSAT) plays a pivotal role in Electronic Design Automation. The standard workflow for solving CSAT problems converts circuits into Conjunctive Normal Form (CNF) and employs generic SAT solvers powered by Conflict-Driven Clause Learning (CDCL). However, this process inherently discards rich structural and functional information, leading to suboptimal solver performance. To address this limitation, we introduce CASCAD, a novel circuit-aware SAT solving framework that directly leverages circuit-level conditional probabilities computed via Graph Neural Networks (GNNs). By explicitly modeling gate-level conditional probabilities, CASCAD dynamically guides two critical CDCL heuristics -- variable phase selection and clause managementto significantly enhance solver efficiency. Extensive evaluations on challenging real-world Logical Equivalence Checking (LEC) benchmarks demonstrate that CASCAD reduces solving times by up to 10x compared to state-of-the-art CNF-based approaches, achieving an additional 23.5% runtime reduction via our probability-guided clause filtering strategy. Our results underscore the importance of preserving circuit-level structural insights within SAT solvers, providing a robust foundation for future improvements in SAT-solving efficiency and EDA tool design.
AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
Dissecting the Impact of Mobile DVFS Governors on LLM Inference Performance and Energy Efficiency
Jul 02, 2025Large Language Models (LLMs) are increasingly being integrated into various applications and services running on billions of mobile devices. However, deploying LLMs on resource-limited mobile devices faces a significant challenge due to their high demand for computation, memory, and ultimately energy. While current LLM frameworks for mobile use three power-hungry components-CPU, GPU, and Memory-even when running primarily-GPU LLM models, optimized DVFS governors for CPU, GPU, and memory featured in modern mobile devices operate independently and are oblivious of each other. Motivated by the above observation, in this work, we first measure the energy-efficiency of a SOTA LLM framework consisting of various LLM models on mobile phones which showed the triplet mobile governors result in up to 40.4% longer prefilling and decoding latency compared to optimal combinations of CPU, GPU, and memory frequencies with the same energy consumption for sampled prefill and decode lengths. Second, we conduct an in-depth measurement study to uncover how the intricate interplay (or lack of) among the mobile governors cause the above inefficiency in LLM inference. Finally, based on these insights, we design FUSE - a unified energy-aware governor for optimizing the energy efficiency of LLM inference on mobile devices. Our evaluation using a ShareGPT dataset shows FUSE reduces the time-to-first-token and time-per-output-token latencies by 7.0%-16.9% and 25.4%-36.8% on average with the same energy-per-token for various mobile LLM models.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025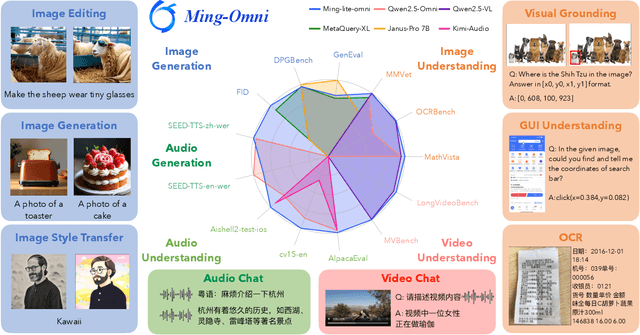
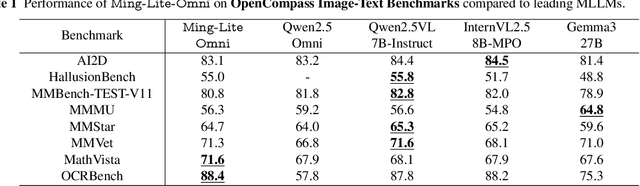
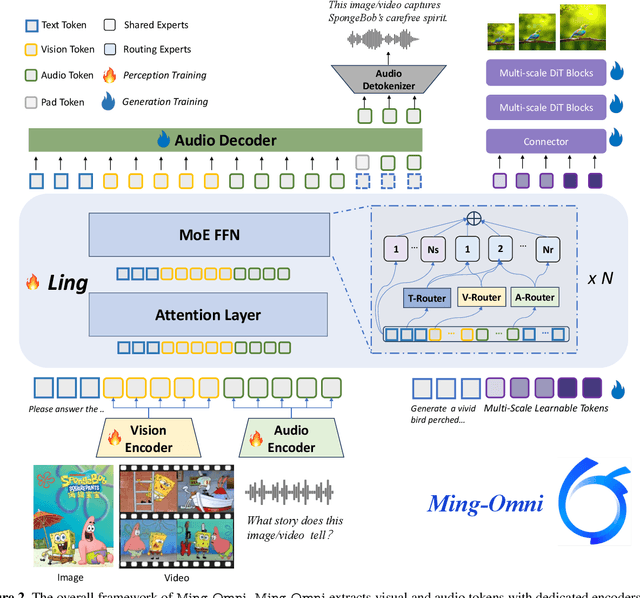
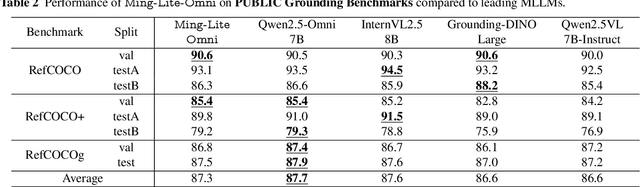
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Mathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
Functional Matching of Logic Subgraphs: Beyond Structural Isomorphism
May 28, 2025Subgraph matching in logic circuits is foundational for numerous Electronic Design Automation (EDA) applications, including datapath optimization, arithmetic verification, and hardware trojan detection. However, existing techniques rely primarily on structural graph isomorphism and thus fail to identify function-related subgraphs when synthesis transformations substantially alter circuit topology. To overcome this critical limitation, we introduce the concept of functional subgraph matching, a novel approach that identifies whether a given logic function is implicitly present within a larger circuit, irrespective of structural variations induced by synthesis or technology mapping. Specifically, we propose a two-stage multi-modal framework: (1) learning robust functional embeddings across AIG and post-mapping netlists for functional subgraph detection, and (2) identifying fuzzy boundaries using a graph segmentation approach. Evaluations on standard benchmarks (ITC99, OpenABCD, ForgeEDA) demonstrate significant performance improvements over existing structural methods, with average $93.8\%$ accuracy in functional subgraph detection and a dice score of $91.3\%$ in fuzzy boundary identification.
Solve-Detect-Verify: Inference-Time Scaling with Flexible Generative Verifier
May 17, 2025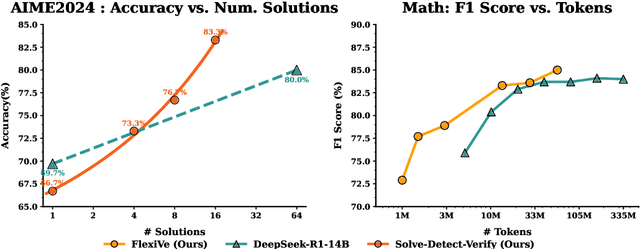
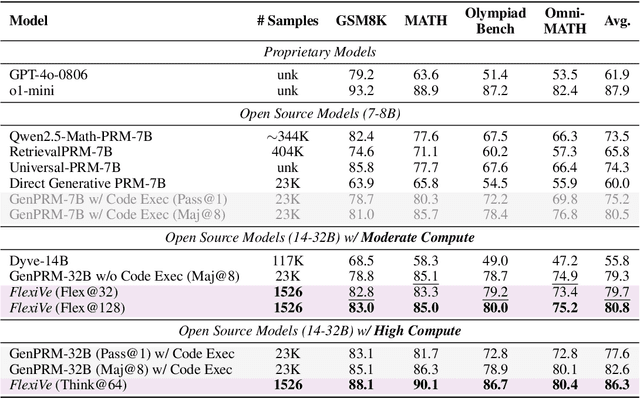
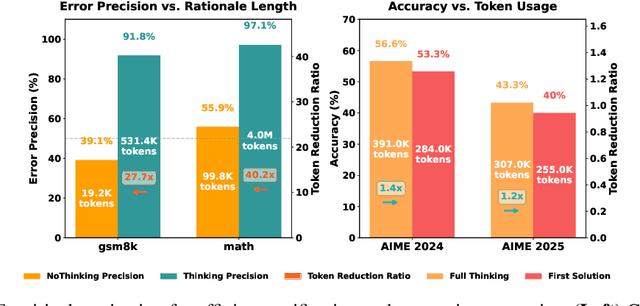
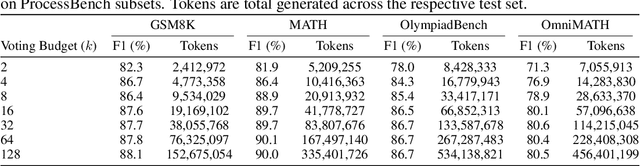
Large Language Model (LLM) reasoning for complex tasks inherently involves a trade-off between solution accuracy and computational efficiency. The subsequent step of verification, while intended to improve performance, further complicates this landscape by introducing its own challenging trade-off: sophisticated Generative Reward Models (GenRMs) can be computationally prohibitive if naively integrated with LLMs at test-time, while simpler, faster methods may lack reliability. To overcome these challenges, we introduce FlexiVe, a novel generative verifier that flexibly balances computational resources between rapid, reliable fast thinking and meticulous slow thinking using a Flexible Allocation of Verification Budget strategy. We further propose the Solve-Detect-Verify pipeline, an efficient inference-time scaling framework that intelligently integrates FlexiVe, proactively identifying solution completion points to trigger targeted verification and provide focused solver feedback. Experiments show FlexiVe achieves superior accuracy in pinpointing errors within reasoning traces on ProcessBench. Furthermore, on challenging mathematical reasoning benchmarks (AIME 2024, AIME 2025, and CNMO), our full approach outperforms baselines like self-consistency in reasoning accuracy and inference efficiency. Our system offers a scalable and effective solution to enhance LLM reasoning at test time.
FullDiT: Multi-Task Video Generative Foundation Model with Full Attention
Mar 25, 2025Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.
Speculative Decoding for Verilog: Speed and Quality, All in One
Mar 18, 2025



The rapid advancement of large language models (LLMs) has revolutionized code generation tasks across various programming languages. However, the unique characteristics of programming languages, particularly those like Verilog with specific syntax and lower representation in training datasets, pose significant challenges for conventional tokenization and decoding approaches. In this paper, we introduce a novel application of speculative decoding for Verilog code generation, showing that it can improve both inference speed and output quality, effectively achieving speed and quality all in one. Unlike standard LLM tokenization schemes, which often fragment meaningful code structures, our approach aligns decoding stops with syntactically significant tokens, making it easier for models to learn the token distribution. This refinement addresses inherent tokenization issues and enhances the model's ability to capture Verilog's logical constructs more effectively. Our experimental results show that our method achieves up to a 5.05x speedup in Verilog code generation and increases pass@10 functional accuracy on RTLLM by up to 17.19% compared to conventional training strategies. These findings highlight speculative decoding as a promising approach to bridge the quality gap in code generation for specialized programming languages.