 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Mix: Semantic Data Augmentation for Fine Grained Recognition
Apr 06, 2020

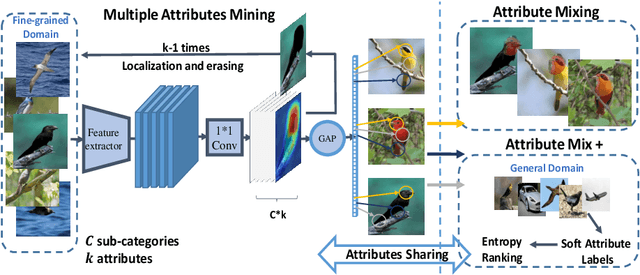

Collecting fine-grained labels usually requires expert-level domain knowledge and is prohibitive to scale up. In this paper, we propose Attribute Mix, a data augmentation strategy at attribute level to expand the fine-grained samples. The principle lies in that attribute features are shared among fine-grained sub-categories, and can be seamlessly transferred among images. Toward this goal, we propose an automatic attribute mining approach to discover attributes that belong to the same super-category, and Attribute Mix is operated by mixing semantically meaningful attribute features from two images. Attribute Mix is a simple but effective data augmentation strategy that can significantly improve the recognition performance without increasing the inference budgets. Furthermore, since attributes can be shared among images from the same super-category, we further enrich the training samples with attribute level labels using images from the generic domain. Experiments on widely used fine-grained benchmarks demonstrate the effectiveness of our proposed method. Specifically, without any bells and whistles, we achieve accuracies of $90.2\%$, $93.1\%$ and $94.9\%$ on CUB-200-2011, FGVC-Aircraft and Standford Cars, respectively.
Learning to Select Base Classes for Few-shot Classification
Apr 01, 2020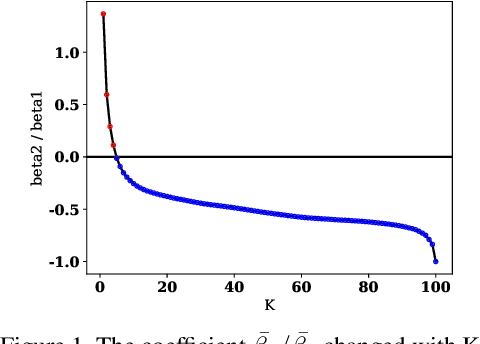

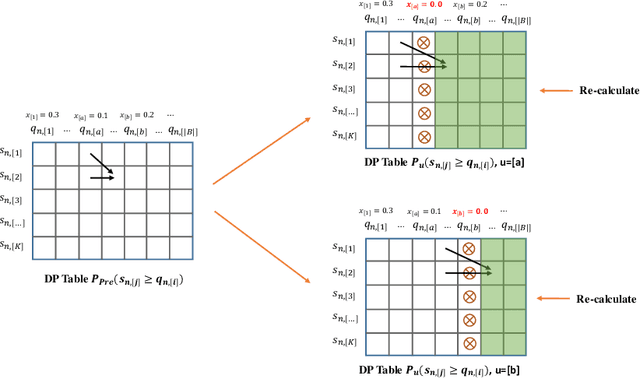
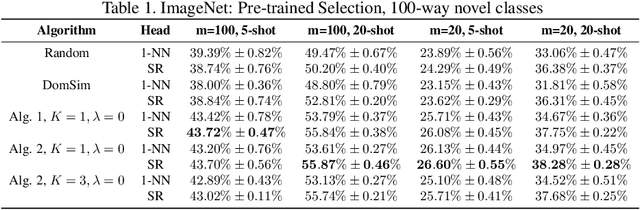
Few-shot learning has attracted intensive research attention in recent years. Many methods have been proposed to generalize a model learned from provided base classes to novel classes, but no previous work studies how to select base classes, or even whether different base classes will result in different generalization performance of the learned model. In this paper, we utilize a simple yet effective measure, the Similarity Ratio, as an indicator for the generalization performance of a few-shot model. We then formulate the base class selection problem as a submodular optimization problem over Similarity Ratio. We further provide theoretical analysis on the optimization lower bound of different optimization methods, which could be used to identify the most appropriate algorithm for different experimental settings. The extensive experiments on ImageNet, Caltech256 and CUB-200-2011 demonstrate that our proposed method is effective in selecting a better base dataset.
Creating Something from Nothing: Unsupervised Knowledge Distillation for Cross-Modal Hashing
Apr 01, 2020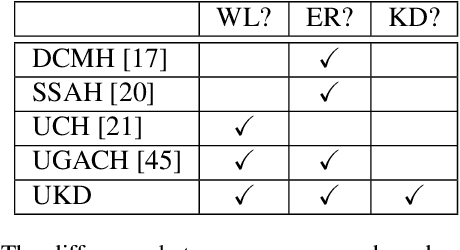
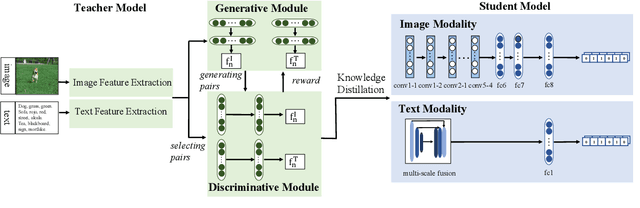
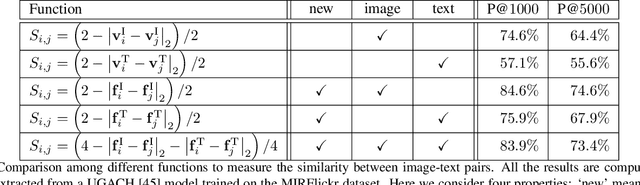

In recent years, cross-modal hashing (CMH) has attracted increasing attentions, mainly because its potential ability of mapping contents from different modalities, especially in vision and language, into the same space, so that it becomes efficient in cross-modal data retrieval. There are two main frameworks for CMH, differing from each other in whether semantic supervision is required. Compared to the unsupervised methods, the supervised methods often enjoy more accurate results, but require much heavier labors in data annotation. In this paper, we propose a novel approach that enables guiding a supervised method using outputs produced by an unsupervised method. Specifically, we make use of teacher-student optimization for propagating knowledge. Experiments are performed on two popular CMH benchmarks, i.e., the MIRFlickr and NUS-WIDE datasets. Our approach outperforms all existing unsupervised methods by a large margin.
TapLab: A Fast Framework for Semantic Video Segmentation Tapping into Compressed-Domain Knowledge
Mar 30, 2020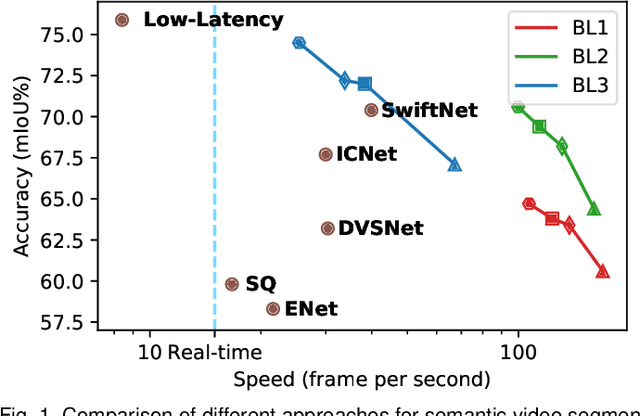
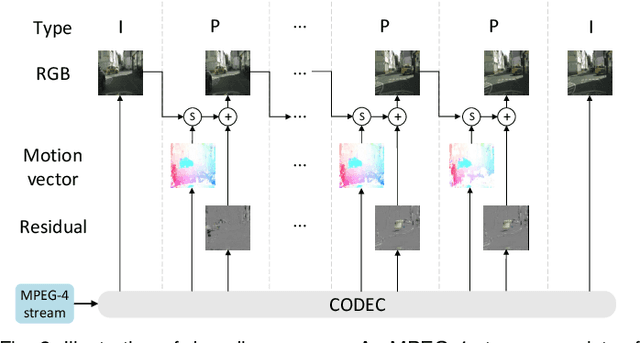

Real-time semantic video segmentation is a challenging task due to the strict requirements of inference speed. Recent approaches mainly devote great efforts to reducing the model size for high efficiency. In this paper, we rethink this problem from a different viewpoint: using knowledge contained in compressed videos. We propose a simple and effective framework, dubbed TapLab, to tap into resources from the compressed domain. Specifically, we design a fast feature warping module using motion vectors for acceleration. To reduce the noise introduced by motion vectors, we design a residual-guided correction module and a residual-guided frame selection module using residuals. Compared with the state-of-the-art fast semantic image segmentation models, our proposed TapLab significantly reduces redundant computations, running around 3 times faster with comparable accuracy for 1024x2048 video. The experimental results show that TapLab achieves 70.6% mIoU on the Cityscapes dataset at 99.8 FPS with a single GPU card. A high-speed version even reaches the speed of 160+ FPS.
Gradually Vanishing Bridge for Adversarial Domain Adaptation
Mar 30, 2020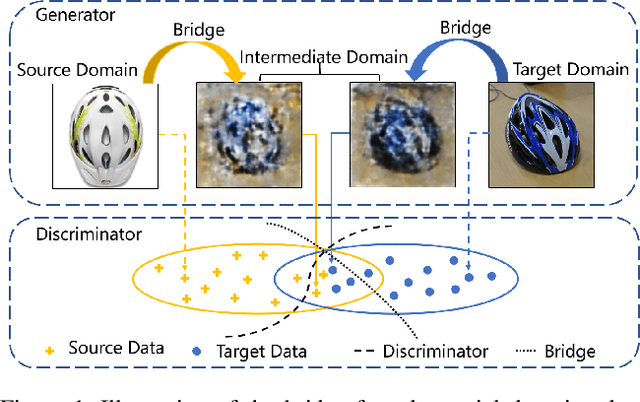
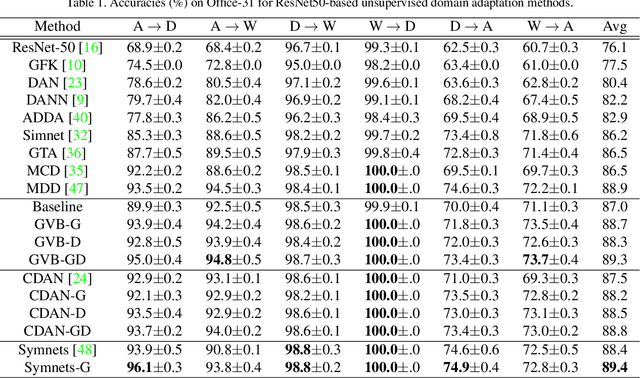
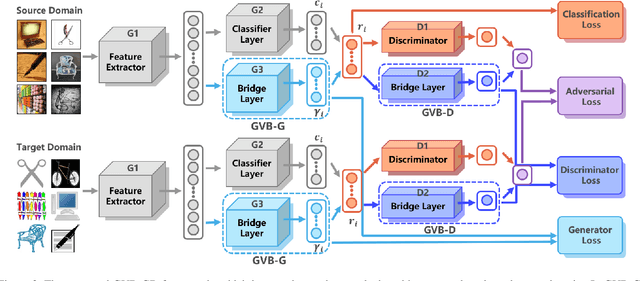
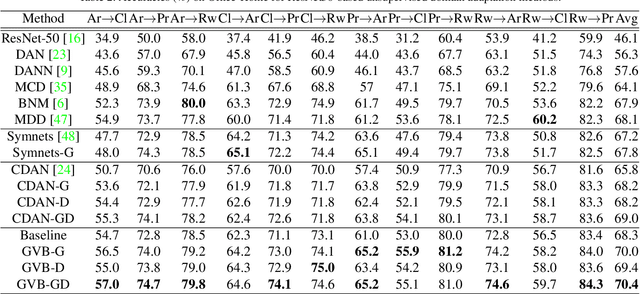
In unsupervised domain adaptation, rich domain-specific characteristics bring great challenge to learn domain-invariant representations. However, domain discrepancy is considered to be directly minimized in existing solutions, which is difficult to achieve in practice. Some methods alleviate the difficulty by explicitly modeling domain-invariant and domain-specific parts in the representations, but the adverse influence of the explicit construction lies in the residual domain-specific characteristics in the constructed domain-invariant representations. In this paper, we equip adversarial domain adaptation with Gradually Vanishing Bridge (GVB) mechanism on both generator and discriminator. On the generator, GVB could not only reduce the overall transfer difficulty, but also reduce the influence of the residual domain-specific characteristics in domain-invariant representations. On the discriminator, GVB contributes to enhance the discriminating ability, and balance the adversarial training process. Experiments on three challenging datasets show that our GVB methods outperform strong competitors, and cooperate well with other adversarial methods. The code is available at https://github.com/cuishuhao/GVB.
Cross-domain Detection via Graph-induced Prototype Alignment
Mar 28, 2020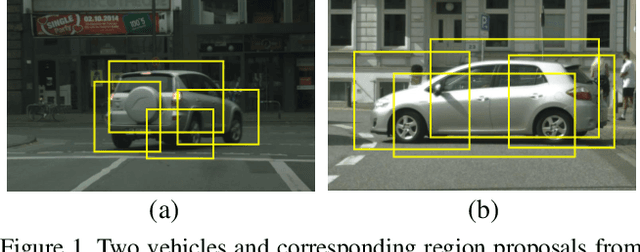
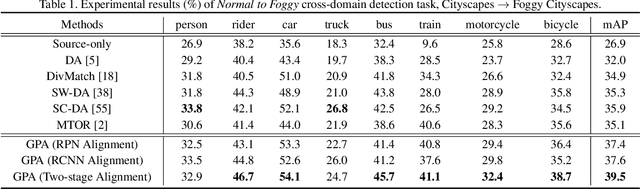
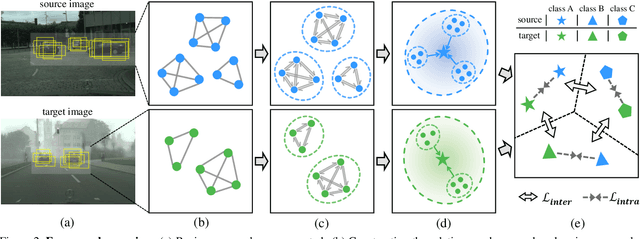
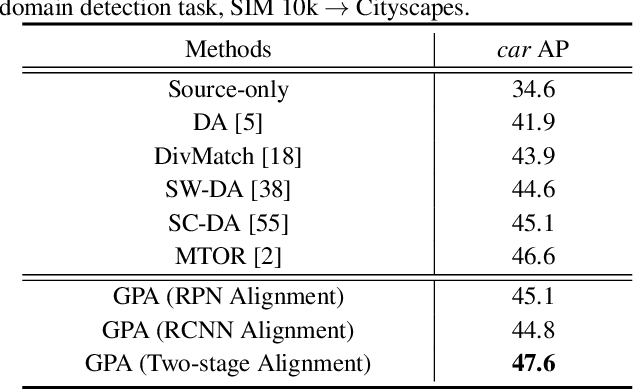
Applying the knowledge of an object detector trained on a specific domain directly onto a new domain is risky, as the gap between two domains can severely degrade model's performance. Furthermore, since different instances commonly embody distinct modal information in object detection scenario, the feature alignment of source and target domain is hard to be realized. To mitigate these problems, we propose a Graph-induced Prototype Alignment (GPA) framework to seek for category-level domain alignment via elaborate prototype representations. In the nutshell, more precise instance-level features are obtained through graph-based information propagation among region proposals, and, on such basis, the prototype representation of each class is derived for category-level domain alignment. In addition, in order to alleviate the negative effect of class-imbalance on domain adaptation, we design a Class-reweighted Contrastive Loss to harmonize the adaptation training process. Combining with Faster R-CNN, the proposed framework conducts feature alignment in a two-stage manner. Comprehensive results on various cross-domain detection tasks demonstrate that our approach outperforms existing methods with a remarkable margin. Our code is available at https://github.com/ChrisAllenMing/GPA-detection.
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations
Mar 27, 2020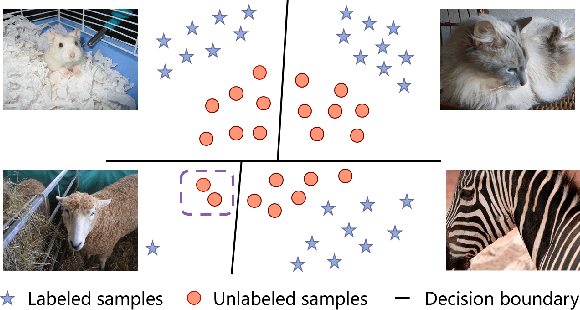
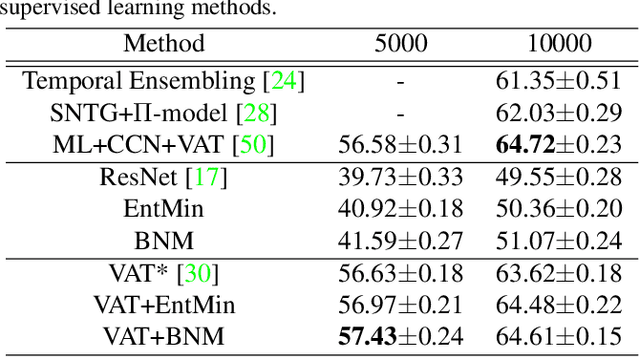
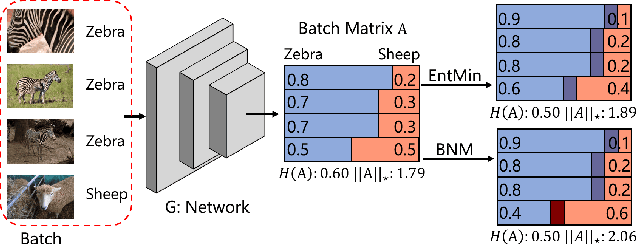
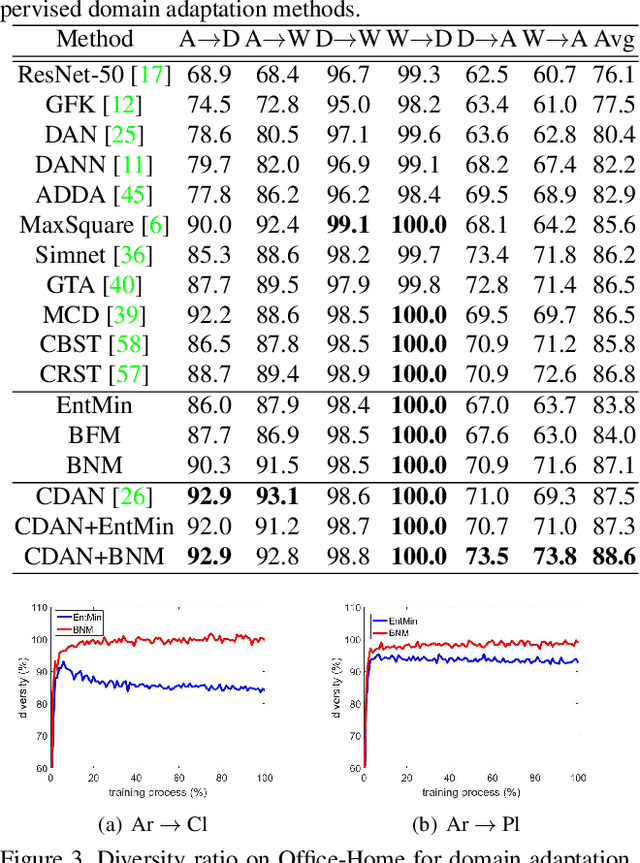
The learning of the deep networks largely relies on the data with human-annotated labels. In some label insufficient situations, the performance degrades on the decision boundary with high data density. A common solution is to directly minimize the Shannon Entropy, but the side effect caused by entropy minimization, i.e., reduction of the prediction diversity, is mostly ignored. To address this issue, we reinvestigate the structure of classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. Besides, the nuclear-norm is an upperbound of the Frobenius-norm, and a convex approximation of the matrix rank. Accordingly, to improve both discriminability and diversity, we propose Batch Nuclear-norm Maximization (BNM) on the output matrix. BNM could boost the learning under typical label insufficient learning scenarios, such as semi-supervised learning, domain adaptation and open domain recognition. On these tasks, extensive experimental results show that BNM outperforms competitors and works well with existing well-known methods. The code is available at https://github.com/cuishuhao/BNM.
Circumventing Outliers of AutoAugment with Knowledge Distillation
Mar 25, 2020
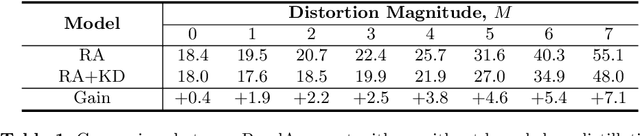
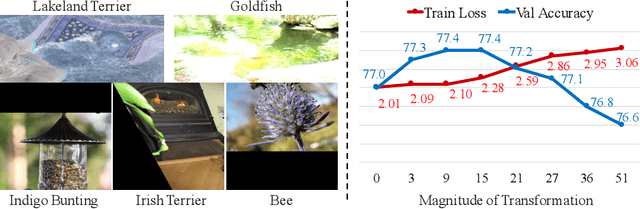

AutoAugment has been a powerful algorithm that improves the accuracy of many vision tasks, yet it is sensitive to the operator space as well as hyper-parameters, and an improper setting may degenerate network optimization. This paper delves deep into the working mechanism, and reveals that AutoAugment may remove part of discriminative information from the training image and so insisting on the ground-truth label is no longer the best option. To relieve the inaccuracy of supervision, we make use of knowledge distillation that refers to the output of a teacher model to guide network training. Experiments are performed in standard image classification benchmarks, and demonstrate the effectiveness of our approach in suppressing noise of data augmentation and stabilizing training. Upon the cooperation of knowledge distillation and AutoAugment, we claim the new state-of-the-art on ImageNet classification with a top-1 accuracy of 85.8%.
Dynamic Multiscale Graph Neural Networks for 3D Skeleton-Based Human Motion Prediction
Mar 17, 2020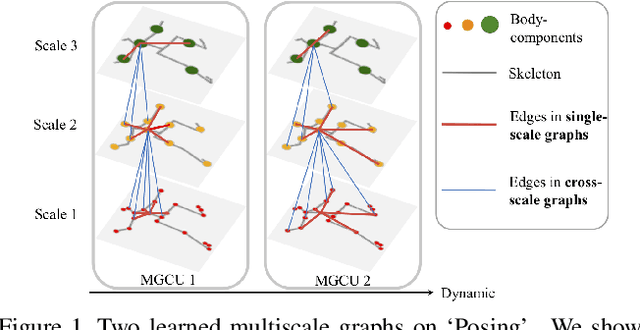
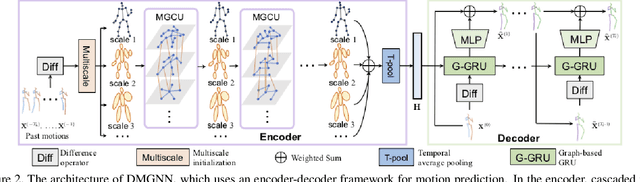
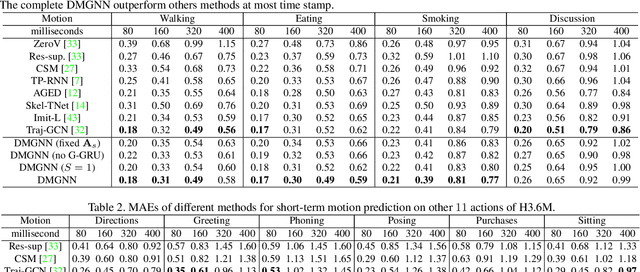
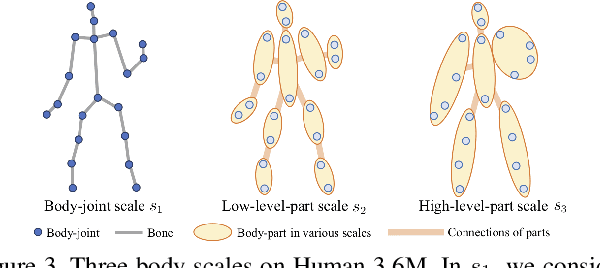
We propose novel dynamic multiscale graph neural networks (DMGNN) to predict 3D skeleton-based human motions. The core idea of DMGNN is to use a multiscale graph to comprehensively model the internal relations of a human body for motion feature learning. This multiscale graph is adaptive during training and dynamic across network layers. Based on this graph, we propose a multiscale graph computational unit (MGCU) to extract features at individual scales and fuse features across scales. The entire model is action-category-agnostic and follows an encoder-decoder framework. The encoder consists of a sequence of MGCUs to learn motion features. The decoder uses a proposed graph-based gate recurrent unit to generate future poses. Extensive experiments show that the proposed DMGNN outperforms state-of-the-art methods in both short and long-term predictions on the datasets of Human 3.6M and CMU Mocap. We further investigate the learned multiscale graphs for the interpretability. The codes could be downloaded from https://github.com/limaosen0/DMGNN.
Constraining Temporal Relationship for Action Localization
Feb 18, 2020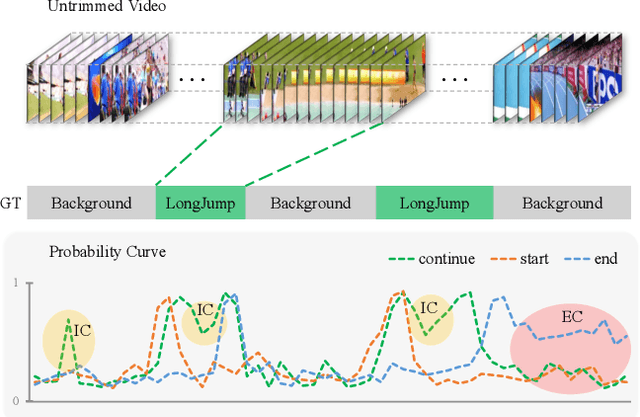
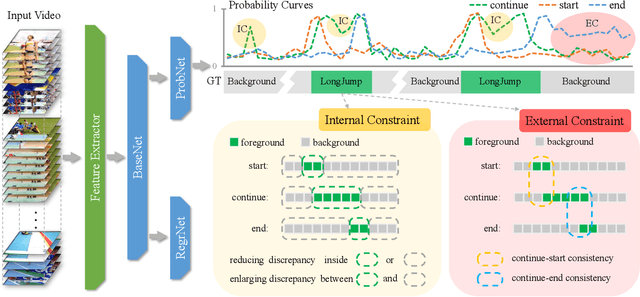
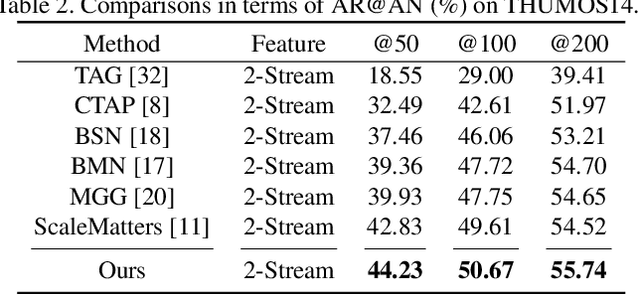
Recently, temporal action localization (TAL), i.e., finding specific action segments in untrimmed videos, has attracted increasing attentions of the computer vision community. State-of-the-art solutions for TAL involves predicting three values at each time point, corresponding to the probabilities that the action starts, continues and ends, and post-processing these curves for the final localization. This paper delves deep into this mechanism, and argues that existing approaches mostly ignored the potential relationship of these curves, and results in low quality of action proposals. To alleviate this problem, we add extra constraints to these curves, e.g., the probability of ''action continues'' should be relatively high between probability peaks of ''action starts'' and ''action ends'', so that the entire framework is aware of these latent constraints during an end-to-end optimization process. Experiments are performed on two popular TAL datasets, THUMOS14 and ActivityNet1.3. Our approach clearly outperforms the baseline both quantitatively (in terms of the AR@AN and mAP) and qualitatively (the curves in the testing stage become much smoother). In particular, when we build our constraints beyond TSA-Net and PGCN, we achieve the state-of-the-art performance especially at strict high IoU settings. The code will be available.