 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus on Your Target: A Dual Teacher-Student Framework for Domain-adaptive Semantic Segmentation
Mar 16, 2023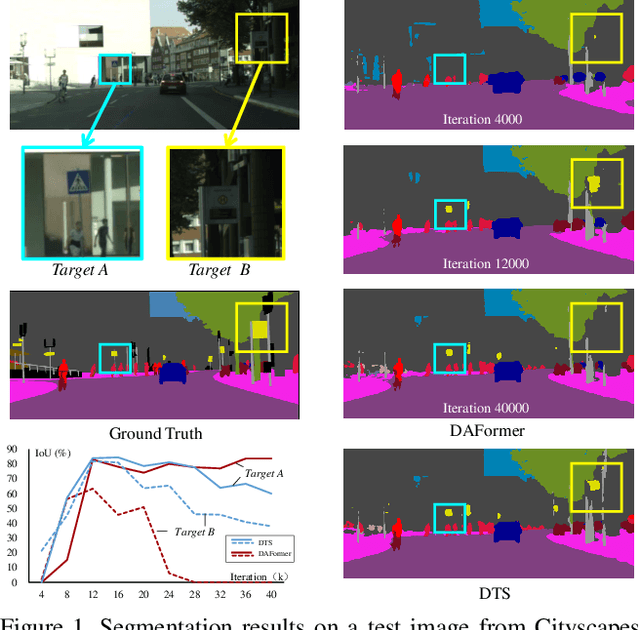
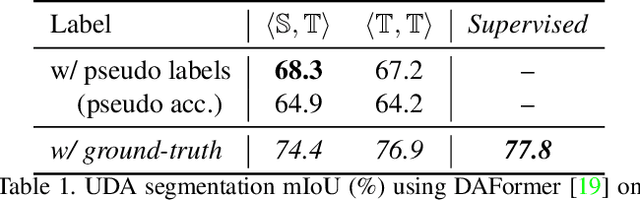
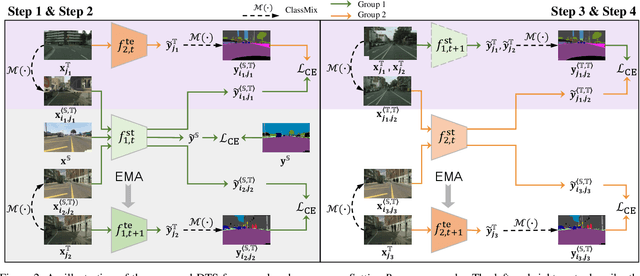
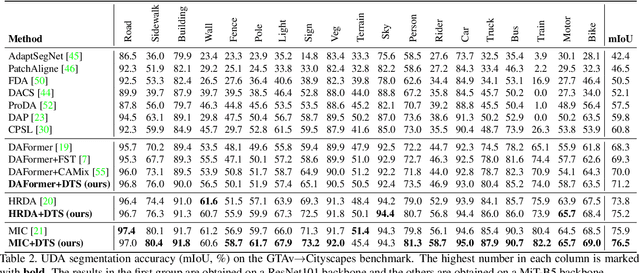
We study unsupervised domain adaptation (UDA) for semantic segmentation. Currently, a popular UDA framework lies in self-training which endows the model with two-fold abilities: (i) learning reliable semantics from the labeled images in the source domain, and (ii) adapting to the target domain via generating pseudo labels on the unlabeled images. We find that, by decreasing/increasing the proportion of training samples from the target domain, the 'learning ability' is strengthened/weakened while the 'adapting ability' goes in the opposite direction, implying a conflict between these two abilities, especially for a single model. To alleviate the issue, we propose a novel dual teacher-student (DTS) framework and equip it with a bidirectional learning strategy. By increasing the proportion of target-domain data, the second teacher-student model learns to 'Focus on Your Target' while the first model is not affected. DTS is easily plugged into existing self-training approaches. In a standard UDA scenario (training on synthetic, labeled data and real, unlabeled data), DTS shows consistent gains over the baselines and sets new state-of-the-art results of 76.5\% and 75.1\% mIoUs on GTAv$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes, respectively.
USAGE: A Unified Seed Area Generation Paradigm for Weakly Supervised Semantic Segmentation
Mar 14, 2023



Seed area generation is usually the starting point of weakly supervised semantic segmentation (WSSS). Computing the Class Activation Map (CAM) from a multi-label classification network is the de facto paradigm for seed area generation, but CAMs generated from Convolutional Neural Networks (CNNs) and Transformers are prone to be under- and over-activated, respectively, which makes the strategies to refine CAMs for CNNs usually inappropriate for Transformers, and vice versa. In this paper, we propose a Unified optimization paradigm for Seed Area GEneration (USAGE) for both types of networks, in which the objective function to be optimized consists of two terms: One is a generation loss, which controls the shape of seed areas by a temperature parameter following a deterministic principle for different types of networks; The other is a regularization loss, which ensures the consistency between the seed areas that are generated by self-adaptive network adjustment from different views, to overturn false activation in seed areas. Experimental results show that USAGE consistently improves seed area generation for both CNNs and Transformers by large margins, e.g., outperforming state-of-the-art methods by a mIoU of 4.1% on PASCAL VOC. Moreover, based on the USAGE-generated seed areas on Transformers, we achieve state-of-the-art WSSS results on both PASCAL VOC and MS COCO.
Gradient-Regulated Meta-Prompt Learning for Generalizable Vision-Language Models
Mar 12, 2023



Prompt tuning, a recently emerging paradigm, enables the powerful vision-language pre-training models to adapt to downstream tasks in a parameter -- and data -- efficient way, by learning the ``soft prompts'' to condition frozen pre-training models. Though effective, it is particularly problematic in the few-shot scenario, where prompt tuning performance is sensitive to the initialization and requires a time-consuming process to find a good initialization, thus restricting the fast adaptation ability of the pre-training models. In addition, prompt tuning could undermine the generalizability of the pre-training models, because the learnable prompt tokens are easy to overfit to the limited training samples. To address these issues, we introduce a novel Gradient-RegulAted Meta-prompt learning (GRAM) framework that jointly meta-learns an efficient soft prompt initialization for better adaptation and a lightweight gradient regulating function for strong cross-domain generalizability in a meta-learning paradigm using only the unlabeled image-text pre-training data. Rather than designing a specific prompt tuning method, our GRAM can be easily incorporated into various prompt tuning methods in a model-agnostic way, and comprehensive experiments show that GRAM brings about consistent improvement for them in several settings (i.e., few-shot learning, cross-domain generalization, cross-dataset generalization, etc.) over 11 datasets. Further, experiments show that GRAM enables the orthogonal methods of textual and visual prompt tuning to work in a mutually-enhanced way, offering better generalizability beyond the uni-modal prompt tuning methods.
Rethinking Visual Prompt Learning as Masked Visual Token Modeling
Mar 09, 2023Prompt learning has achieved great success in efficiently exploiting large-scale pre-trained models in natural language processing (NLP). It reformulates the downstream tasks as the generative pre-training ones, thus narrowing down the gap between them and improving the performance stably. However, when transferring it to the vision area, current visual prompt learning methods are all designed on discriminative pre-trained models, and there is also a lack of careful design to unify the forms of pre-training and downstream tasks. To explore prompt learning on the generative pre-trained visual model as well as keeping the task consistency, we propose Visual Prompt learning as masked visual Token Modeling (VPTM) to transform the downstream visual classification into the pre-trained masked visual token prediction. In addition, we develop the prototypical verbalizer for mapping the predicted visual token with implicit semantics to explicit downstream labels. To our best knowledge, VPTM is the first visual prompt method on the generative pre-trained visual model, and the first to achieve consistency between pre-training and downstream visual classification by task reformulation. Experiments show that VPTM outperforms other visual prompt methods and achieves excellent efficiency. Moreover, the task consistency of VPTM contributes to the robustness against prompt location, prompt length and prototype dimension, and could be deployed uniformly.
R-Tuning: Regularized Prompt Tuning in Open-Set Scenarios
Mar 09, 2023



In realistic open-set scenarios where labels of a part of testing data are totally unknown, current prompt methods on vision-language (VL) models always predict the unknown classes as the downstream training classes. The exhibited label bias causes difficulty in the open set recognition (OSR), by which an image should be correctly predicted as one of the known classes or the unknown one. To learn prompts in open-set scenarios, we propose the Regularized prompt Tuning (R-Tuning) to mitigate the label bias. It introduces open words from the WordNet to extend the range of words forming the prompt texts from only closed-set label words to more. Thus, prompts are tuned in a simulated open-set scenario. Besides, inspired by the observation that classifying directly on large datasets causes a much higher false positive rate than on small datasets, we propose the Combinatorial Tuning and Testing (CTT) strategy for improving performance. CTT decomposes R-Tuning on large datasets as multiple independent group-wise tuning on fewer classes, then makes comprehensive predictions by selecting the optimal sub-prompt. For fair comparisons, we construct new baselines for OSR based on VL models, especially for prompt methods. Our method achieves the best results on datasets with various scales. Extensive ablation studies validate the effectiveness of our method.
Lformer: Text-to-Image Generation with L-shape Block Parallel Decoding
Mar 07, 2023Generative transformers have shown their superiority in synthesizing high-fidelity and high-resolution images, such as good diversity and training stability. However, they suffer from the problem of slow generation since they need to generate a long token sequence autoregressively. To better accelerate the generative transformers while keeping good generation quality, we propose Lformer, a semi-autoregressive text-to-image generation model. Lformer firstly encodes an image into $h{\times}h$ discrete tokens, then divides these tokens into $h$ mirrored L-shape blocks from the top left to the bottom right and decodes the tokens in a block parallelly in each step. Lformer predicts the area adjacent to the previous context like autoregressive models thus it is more stable while accelerating. By leveraging the 2D structure of image tokens, Lformer achieves faster speed than the existing transformer-based methods while keeping good generation quality. Moreover, the pretrained Lformer can edit images without the requirement for finetuning. We can roll back to the early steps for regeneration or edit the image with a bounding box and a text prompt.
Constraint and Union for Partially-Supervised Temporal Sentence Grounding
Feb 20, 2023



Temporal sentence grounding aims to detect the event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great performance but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation cost, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip or even single-frame labels are available during training. To take full advantage of partial labels, we propose a novel quadruple constraint pipeline to comprehensively shape event-query aligned representations, covering intra- and inter-samples, uni- and multi-modalities. The former raises intra-cluster compactness and inter-cluster separability; while the latter enables event-background separation and event-query gather. To achieve more powerful performance with explicit grounding optimization, we further introduce a partial-full union framework, i.e., bridging with an additional fully-supervised branch, to enjoy its impressive grounding bonus, and be robust to partial annotations. Extensive experiments and ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision and our superior performance.
ShiftDDPMs: Exploring Conditional Diffusion Models by Shifting Diffusion Trajectories
Feb 18, 2023Diffusion models have recently exhibited remarkable abilities to synthesize striking image samples since the introduction of denoising diffusion probabilistic models (DDPMs). Their key idea is to disrupt images into noise through a fixed forward process and learn its reverse process to generate samples from noise in a denoising way. For conditional DDPMs, most existing practices relate conditions only to the reverse process and fit it to the reversal of unconditional forward process. We find this will limit the condition modeling and generation in a small time window. In this paper, we propose a novel and flexible conditional diffusion model by introducing conditions into the forward process. We utilize extra latent space to allocate an exclusive diffusion trajectory for each condition based on some shifting rules, which will disperse condition modeling to all timesteps and improve the learning capacity of model. We formulate our method, which we call \textbf{ShiftDDPMs}, and provide a unified point of view on existing related methods. Extensive qualitative and quantitative experiments on image synthesis demonstrate the feasibility and effectiveness of ShiftDDPMs.
Prototype-guided Cross-task Knowledge Distillation for Large-scale Models
Dec 26, 2022



Recently, large-scale pre-trained models have shown their advantages in many tasks. However, due to the huge computational complexity and storage requirements, it is challenging to apply the large-scale model to real scenes. A common solution is knowledge distillation which regards the large-scale model as a teacher model and helps to train a small student model to obtain a competitive performance. Cross-task Knowledge distillation expands the application scenarios of the large-scale pre-trained model. Existing knowledge distillation works focus on directly mimicking the final prediction or the intermediate layers of the teacher model, which represent the global-level characteristics and are task-specific. To alleviate the constraint of different label spaces, capturing invariant intrinsic local object characteristics (such as the shape characteristics of the leg and tail of the cattle and horse) plays a key role. Considering the complexity and variability of real scene tasks, we propose a Prototype-guided Cross-task Knowledge Distillation (ProC-KD) approach to transfer the intrinsic local-level object knowledge of a large-scale teacher network to various task scenarios. First, to better transfer the generalized knowledge in the teacher model in cross-task scenarios, we propose a prototype learning module to learn from the essential feature representation of objects in the teacher model. Secondly, for diverse downstream tasks, we propose a task-adaptive feature augmentation module to enhance the features of the student model with the learned generalization prototype features and guide the training of the student model to improve its generalization ability. The experimental results on various visual tasks demonstrate the effectiveness of our approach for large-scale model cross-task knowledge distillation scenes.
Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization
Dec 19, 2022



Weakly-supervised temporal action localization (WTAL) learns to detect and classify action instances with only category labels. Most methods widely adopt the off-the-shelf Classification-Based Pre-training (CBP) to generate video features for action localization. However, the different optimization objectives between classification and localization, make temporally localized results suffer from the serious incomplete issue. To tackle this issue without additional annotations, this paper considers to distill free action knowledge from Vision-Language Pre-training (VLP), since we surprisingly observe that the localization results of vanilla VLP have an over-complete issue, which is just complementary to the CBP results. To fuse such complementarity, we propose a novel distillation-collaboration framework with two branches acting as CBP and VLP respectively. The framework is optimized through a dual-branch alternate training strategy. Specifically, during the B step, we distill the confident background pseudo-labels from the CBP branch; while during the F step, the confident foreground pseudo-labels are distilled from the VLP branch. And as a result, the dual-branch complementarity is effectively fused to promote a strong alliance. Extensive experiments and ablation studies on THUMOS14 and ActivityNet1.2 reveal that our method significantly outperforms state-of-the-art methods.