 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolative Weight Averaging Reveals Correctness-Efficiency Frontiers in Code RL
May 27, 2026Linear interpolation between fine-tuned checkpoints has been shown to trace the Pareto front between competing objectives, but whether extrapolative weight averaging can extend such frontiers to new checkpoints useful at inference time, without additional RL training, remains unclear. We study this question in RL for competitive programming, where hidden unit tests under time and memory limits enforce both functional correctness and computational efficiency. Starting from a shared initialization, we train checkpoints under nested unit-test coverage: low-coverage rewards require passing smaller-input tests, while high-coverage rewards require passing progressively larger tests up to the full suite. This sweep reveals the emergence of a correctness-efficiency frontier: on hard problems, higher-coverage reward reduces optimization failures but increases correctness failures, leaving solve rate nearly unchanged. Interpolation between low- and high-coverage checkpoints recovers this frontier, while extrapolation extends it beyond the trained endpoints. Both the frontier and its extrapolative continuation appear across three inference settings, pure reasoning, tool use, and agentic coding, and across two model scales, 32B and 7B. At the problem level, moving along the frontier changes which problems are solved, making extrapolated checkpoints complementary policies in inference-time scaling. Ensembles with extrapolative weight averaging broaden coverage and improve pass@250 on LCB/hard by 3.3% over the best single checkpoint at matched sample budget. These results show that nested unit-test coverage in code RL induces a frontier that extrapolative weight averaging can navigate, extend, and exploit.
WybeCoder: Verified Imperative Code Generation
Mar 31, 2026Recent progress in large language models (LLMs) has advanced automatic code generation and formal theorem proving, yet software verification has not seen the same improvement. To address this gap, we propose WybeCoder, an agentic code verification framework that enables prove-as-you-generate development where code, invariants, and proofs co-evolve. It builds on a recent framework that combines automatic verification condition generation and SMT solvers with interactive proofs in Lean. To enable systematic evaluation, we translate two benchmarks for functional verification in Lean, Verina and Clever, to equivalent imperative code specifications. On complex algorithms such as Heapsort, we observe consistent performance improvements by scaling our approach, synthesizing dozens of valid invariants and dispatching of dozens of subgoals, resulting in hundreds of lines of verified code, overcoming plateaus reported in previous works. Our best system solves 74% of Verina tasks and 62% of Clever tasks at moderate compute budgets, significantly surpassing previous evaluations and paving a path to automated construction of large-scale datasets of verified imperative code.
Optimizing Language Models for Inference Time Objectives using Reinforcement Learning
Mar 25, 2025In this work, we investigate the merits of explicitly optimizing for inference time algorithmic performance during model training. We show how optimizing for inference time performance can improve overall model efficacy. We consider generic inference time objectives with $k$ samples, with a focus on pass@$k$ and majority voting as two main applications. With language model training on reasoning datasets, we showcase the performance trade-off enabled by training with such objectives. When training on code generation tasks, we show that the approach significantly improves pass@$k$ objectives compared to the baseline method.
The KoLMogorov Test: Compression by Code Generation
Mar 18, 2025Compression is at the heart of intelligence. A theoretically optimal way to compress any sequence of data is to find the shortest program that outputs that sequence and then halts. However, such 'Kolmogorov compression' is uncomputable, and code generating LLMs struggle to approximate this theoretical ideal, as it requires reasoning, planning and search capabilities beyond those of current models. In this work, we introduce the KoLMogorov-Test (KT), a compression-as-intelligence test for code generating LLMs. In KT a model is presented with a sequence of data at inference time, and asked to generate the shortest program that produces the sequence. We identify several benefits of KT for both evaluation and training: an essentially infinite number of problem instances of varying difficulty is readily available, strong baselines already exist, the evaluation metric (compression) cannot be gamed, and pretraining data contamination is highly unlikely. To evaluate current models, we use audio, text, and DNA data, as well as sequences produced by random synthetic programs. Current flagship models perform poorly - both GPT4-o and Llama-3.1-405B struggle on our natural and synthetic sequences. On our synthetic distribution, we are able to train code generation models with lower compression rates than previous approaches. Moreover, we show that gains on synthetic data generalize poorly to real data, suggesting that new innovations are necessary for additional gains on KT.
Soft Policy Optimization: Online Off-Policy RL for Sequence Models
Mar 07, 2025

RL-based post-training of language models is almost exclusively done using on-policy methods such as PPO. These methods cannot learn from arbitrary sequences such as those produced earlier in training, in earlier runs, by human experts or other policies, or by decoding and exploration methods. This results in severe sample inefficiency and exploration difficulties, as well as a potential loss of diversity in the policy responses. Moreover, asynchronous PPO implementations require frequent and costly model transfers, and typically use value models which require a large amount of memory. In this paper we introduce Soft Policy Optimization (SPO), a simple, scalable and principled Soft RL method for sequence model policies that can learn from arbitrary online and offline trajectories and does not require a separate value model. In experiments on code contests, we shows that SPO outperforms PPO on pass@10, is significantly faster and more memory efficient, is able to benefit from off-policy data, enjoys improved stability, and learns more diverse (i.e. soft) policies.
PILAF: Optimal Human Preference Sampling for Reward Modeling
Feb 06, 2025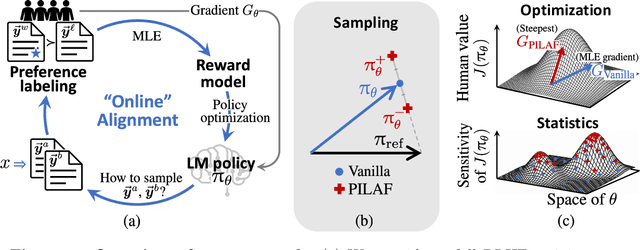

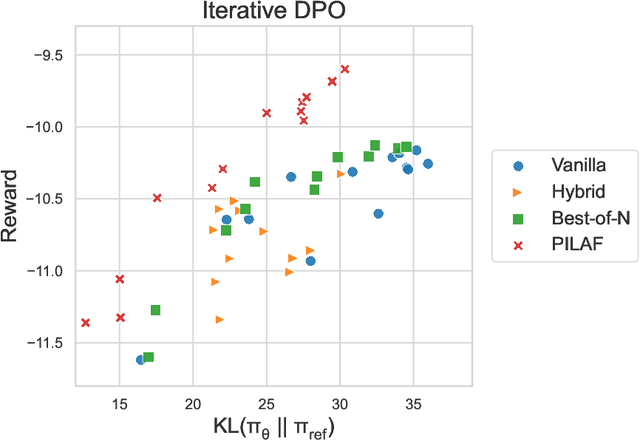
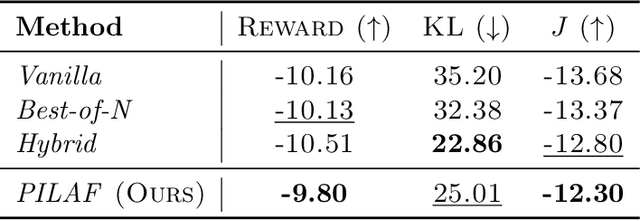
As large language models increasingly drive real-world applications, aligning them with human values becomes paramount. Reinforcement Learning from Human Feedback (RLHF) has emerged as a key technique, translating preference data into reward models when oracle human values remain inaccessible. In practice, RLHF mostly relies on approximate reward models, which may not consistently guide the policy toward maximizing the underlying human values. We propose Policy-Interpolated Learning for Aligned Feedback (PILAF), a novel response sampling strategy for preference labeling that explicitly aligns preference learning with maximizing the underlying oracle reward. PILAF is theoretically grounded, demonstrating optimality from both an optimization and a statistical perspective. The method is straightforward to implement and demonstrates strong performance in iterative and online RLHF settings where feedback curation is critical.
What Makes Large Language Models Reason in (Multi-Turn) Code Generation?
Oct 10, 2024



Prompting techniques such as chain-of-thought have established themselves as a popular vehicle for improving the outputs of large language models (LLMs). For code generation, however, their exact mechanics and efficacy are under-explored. We thus investigate the effects of a wide range of prompting strategies with a focus on automatic re-prompting over multiple turns and computational requirements. After systematically decomposing reasoning, instruction, and execution feedback prompts, we conduct an extensive grid search on the competitive programming benchmarks CodeContests and TACO for multiple LLM families and sizes (Llama 3.0 and 3.1, 8B, 70B, 405B, and GPT-4o). Our study reveals strategies that consistently improve performance across all models with small and large sampling budgets. We then show how finetuning with such an optimal configuration allows models to internalize the induced reasoning process and obtain improvements in performance and scalability for multi-turn code generation.
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
Oct 02, 2024



Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new start-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
D4FT: A Deep Learning Approach to Kohn-Sham Density Functional Theory
Mar 01, 2023



Kohn-Sham Density Functional Theory (KS-DFT) has been traditionally solved by the Self-Consistent Field (SCF) method. Behind the SCF loop is the physics intuition of solving a system of non-interactive single-electron wave functions under an effective potential. In this work, we propose a deep learning approach to KS-DFT. First, in contrast to the conventional SCF loop, we propose to directly minimize the total energy by reparameterizing the orthogonal constraint as a feed-forward computation. We prove that such an approach has the same expressivity as the SCF method, yet reduces the computational complexity from O(N^4) to O(N^3). Second, the numerical integration which involves a summation over the quadrature grids can be amortized to the optimization steps. At each step, stochastic gradient descent (SGD) is performed with a sampled minibatch of the grids. Extensive experiments are carried out to demonstrate the advantage of our approach in terms of efficiency and stability. In addition, we show that our approach enables us to explore more complex neural-based wave functions.
Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization
Dec 19, 2022



Weakly-supervised temporal action localization (WTAL) learns to detect and classify action instances with only category labels. Most methods widely adopt the off-the-shelf Classification-Based Pre-training (CBP) to generate video features for action localization. However, the different optimization objectives between classification and localization, make temporally localized results suffer from the serious incomplete issue. To tackle this issue without additional annotations, this paper considers to distill free action knowledge from Vision-Language Pre-training (VLP), since we surprisingly observe that the localization results of vanilla VLP have an over-complete issue, which is just complementary to the CBP results. To fuse such complementarity, we propose a novel distillation-collaboration framework with two branches acting as CBP and VLP respectively. The framework is optimized through a dual-branch alternate training strategy. Specifically, during the B step, we distill the confident background pseudo-labels from the CBP branch; while during the F step, the confident foreground pseudo-labels are distilled from the VLP branch. And as a result, the dual-branch complementarity is effectively fused to promote a strong alliance. Extensive experiments and ablation studies on THUMOS14 and ActivityNet1.2 reveal that our method significantly outperforms state-of-the-art methods.