 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic-MM-Embedding: Towards Visual-Token-Efficient Universal Multimodal Embedding with MLLMs
Feb 05, 2026Multimodal Large Language Models (MLLMs) have shown immense promise in universal multimodal retrieval, which aims to find relevant items of various modalities for a given query. But their practical application is often hindered by the substantial computational cost incurred from processing a large number of tokens from visual inputs. In this paper, we propose Magic-MM-Embedding, a series of novel models that achieve both high efficiency and state-of-the-art performance in universal multimodal embedding. Our approach is built on two synergistic pillars: (1) a highly efficient MLLM architecture incorporating visual token compression to drastically reduce inference latency and memory footprint, and (2) a multi-stage progressive training strategy designed to not only recover but significantly boost performance. This coarse-to-fine training paradigm begins with extensive continue pretraining to restore multimodal understanding and generation capabilities, progresses to large-scale contrastive pretraining and hard negative mining to enhance discriminative power, and culminates in a task-aware fine-tuning stage guided by an MLLM-as-a-Judge for precise data curation. Comprehensive experiments show that our model outperforms existing methods by a large margin while being more inference-efficient.
DENOISER: Rethinking the Robustness for Open-Vocabulary Action Recognition
Apr 23, 2024



As one of the fundamental video tasks in computer vision, Open-Vocabulary Action Recognition (OVAR) recently gains increasing attention, with the development of vision-language pre-trainings. To enable generalization of arbitrary classes, existing methods treat class labels as text descriptions, then formulate OVAR as evaluating embedding similarity between visual samples and textual classes. However, one crucial issue is completely ignored: the class descriptions given by users may be noisy, e.g., misspellings and typos, limiting the real-world practicality of vanilla OVAR. To fill the research gap, this paper pioneers to evaluate existing methods by simulating multi-level noises of various types, and reveals their poor robustness. To tackle the noisy OVAR task, we further propose one novel DENOISER framework, covering two parts: generation and discrimination. Concretely, the generative part denoises noisy class-text names via one decoding process, i.e., propose text candidates, then utilize inter-modal and intra-modal information to vote for the best. At the discriminative part, we use vanilla OVAR models to assign visual samples to class-text names, thus obtaining more semantics. For optimization, we alternately iterate between generative and discriminative parts for progressive refinements. The denoised text classes help OVAR models classify visual samples more accurately; in return, classified visual samples help better denoising. On three datasets, we carry out extensive experiments to show our superior robustness, and thorough ablations to dissect the effectiveness of each component.
Audio-Visual Segmentation via Unlabeled Frame Exploitation
Mar 17, 2024



Audio-visual segmentation (AVS) aims to segment the sounding objects in video frames. Although great progress has been witnessed, we experimentally reveal that current methods reach marginal performance gain within the use of the unlabeled frames, leading to the underutilization issue. To fully explore the potential of the unlabeled frames for AVS, we explicitly divide them into two categories based on their temporal characteristics, i.e., neighboring frame (NF) and distant frame (DF). NFs, temporally adjacent to the labeled frame, often contain rich motion information that assists in the accurate localization of sounding objects. Contrary to NFs, DFs have long temporal distances from the labeled frame, which share semantic-similar objects with appearance variations. Considering their unique characteristics, we propose a versatile framework that effectively leverages them to tackle AVS. Specifically, for NFs, we exploit the motion cues as the dynamic guidance to improve the objectness localization. Besides, we exploit the semantic cues in DFs by treating them as valid augmentations to the labeled frames, which are then used to enrich data diversity in a self-training manner. Extensive experimental results demonstrate the versatility and superiority of our method, unleashing the power of the abundant unlabeled frames.
Audio-aware Query-enhanced Transformer for Audio-Visual Segmentation
Jul 25, 2023The goal of the audio-visual segmentation (AVS) task is to segment the sounding objects in the video frames using audio cues. However, current fusion-based methods have the performance limitations due to the small receptive field of convolution and inadequate fusion of audio-visual features. To overcome these issues, we propose a novel \textbf{Au}dio-aware query-enhanced \textbf{TR}ansformer (AuTR) to tackle the task. Unlike existing methods, our approach introduces a multimodal transformer architecture that enables deep fusion and aggregation of audio-visual features. Furthermore, we devise an audio-aware query-enhanced transformer decoder that explicitly helps the model focus on the segmentation of the pinpointed sounding objects based on audio signals, while disregarding silent yet salient objects. Experimental results show that our method outperforms previous methods and demonstrates better generalization ability in multi-sound and open-set scenarios.
Annotation-free Audio-Visual Segmentation
May 19, 2023



The objective of Audio-Visual Segmentation (AVS) is to locate sounding objects within visual scenes by accurately predicting pixelwise segmentation masks. In this paper, we present the following contributions: (i), we propose a scalable and annotation-free pipeline for generating artificial data for the AVS task. We leverage existing image segmentation and audio datasets to draw links between category labels, image-mask pairs, and audio samples, which allows us to easily compose (image, audio, mask) triplets for training AVS models; (ii), we introduce a novel Audio-Aware Transformer (AuTR) architecture that features an audio-aware query-based transformer decoder. This architecture enables the model to search for sounding objects with the guidance of audio signals, resulting in more accurate segmentation; (iii), we present extensive experiments conducted on both synthetic and real datasets, which demonstrate the effectiveness of training AVS models with synthetic data generated by our proposed pipeline. Additionally, our proposed AuTR architecture exhibits superior performance and strong generalization ability on public benchmarks. The project page is https://jinxiang-liu.github.io/anno-free-AVS/.
DiffusionSeg: Adapting Diffusion Towards Unsupervised Object Discovery
Mar 17, 2023



Learning from a large corpus of data, pre-trained models have achieved impressive progress nowadays. As popular generative pre-training, diffusion models capture both low-level visual knowledge and high-level semantic relations. In this paper, we propose to exploit such knowledgeable diffusion models for mainstream discriminative tasks, i.e., unsupervised object discovery: saliency segmentation and object localization. However, the challenges exist as there is one structural difference between generative and discriminative models, which limits the direct use. Besides, the lack of explicitly labeled data significantly limits performance in unsupervised settings. To tackle these issues, we introduce DiffusionSeg, one novel synthesis-exploitation framework containing two-stage strategies. To alleviate data insufficiency, we synthesize abundant images, and propose a novel training-free AttentionCut to obtain masks in the first synthesis stage. In the second exploitation stage, to bridge the structural gap, we use the inversion technique, to map the given image back to diffusion features. These features can be directly used by downstream architectures. Extensive experiments and ablation studies demonstrate the superiority of adapting diffusion for unsupervised object discovery.
Constraint and Union for Partially-Supervised Temporal Sentence Grounding
Feb 20, 2023



Temporal sentence grounding aims to detect the event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great performance but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation cost, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip or even single-frame labels are available during training. To take full advantage of partial labels, we propose a novel quadruple constraint pipeline to comprehensively shape event-query aligned representations, covering intra- and inter-samples, uni- and multi-modalities. The former raises intra-cluster compactness and inter-cluster separability; while the latter enables event-background separation and event-query gather. To achieve more powerful performance with explicit grounding optimization, we further introduce a partial-full union framework, i.e., bridging with an additional fully-supervised branch, to enjoy its impressive grounding bonus, and be robust to partial annotations. Extensive experiments and ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision and our superior performance.
Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization
Dec 19, 2022



Weakly-supervised temporal action localization (WTAL) learns to detect and classify action instances with only category labels. Most methods widely adopt the off-the-shelf Classification-Based Pre-training (CBP) to generate video features for action localization. However, the different optimization objectives between classification and localization, make temporally localized results suffer from the serious incomplete issue. To tackle this issue without additional annotations, this paper considers to distill free action knowledge from Vision-Language Pre-training (VLP), since we surprisingly observe that the localization results of vanilla VLP have an over-complete issue, which is just complementary to the CBP results. To fuse such complementarity, we propose a novel distillation-collaboration framework with two branches acting as CBP and VLP respectively. The framework is optimized through a dual-branch alternate training strategy. Specifically, during the B step, we distill the confident background pseudo-labels from the CBP branch; while during the F step, the confident foreground pseudo-labels are distilled from the VLP branch. And as a result, the dual-branch complementarity is effectively fused to promote a strong alliance. Extensive experiments and ablation studies on THUMOS14 and ActivityNet1.2 reveal that our method significantly outperforms state-of-the-art methods.
Exploiting Transformation Invariance and Equivariance for Self-supervised Sound Localisation
Jun 26, 2022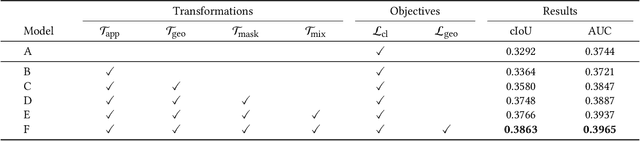
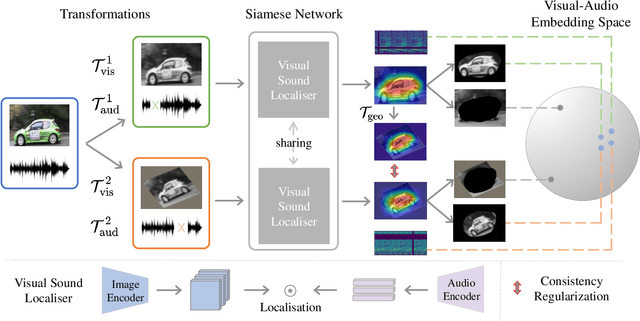
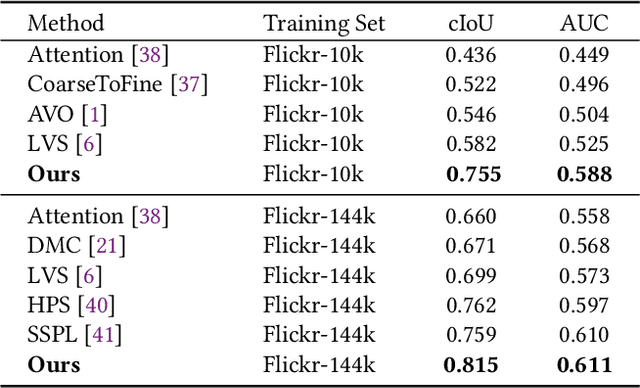
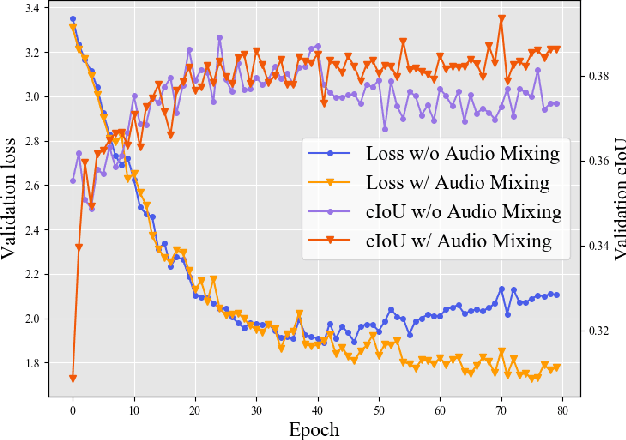
We present a simple yet effective self-supervised framework for audio-visual representation learning, to localize the sound source in videos. To understand what enables to learn useful representations, we systematically investigate the effects of data augmentations, and reveal that (1) composition of data augmentations plays a critical role, {\em i.e.}~explicitly encouraging the audio-visual representations to be invariant to various transformations~({\em transformation invariance}); (2) enforcing geometric consistency substantially improves the quality of learned representations, {\em i.e.}~the detected sound source should follow the same transformation applied on input video frames~({\em transformation equivariance}). Extensive experiments demonstrate that our model significantly outperforms previous methods on two sound localization benchmarks, namely, Flickr-SoundNet and VGG-Sound. Additionally, we also evaluate audio retrieval and cross-modal retrieval tasks. In both cases, our self-supervised models demonstrate superior retrieval performances, even competitive with the supervised approach in audio retrieval. This reveals the proposed framework learns strong multi-modal representations that are beneficial to sound localisation and generalization to further applications. \textit{All codes will be available}.
A 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer
Sep 24, 2021
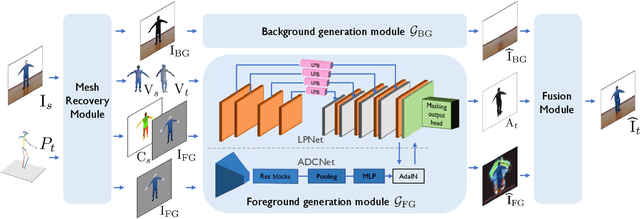
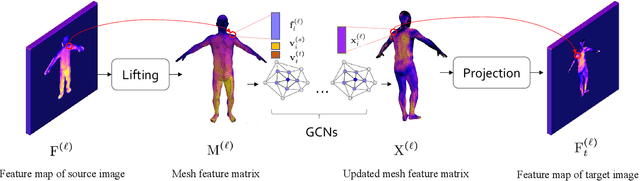

Human pose transfer has typically been modeled as a 2D image-to-image translation problem. This formulation ignores the human body shape prior in 3D space and inevitably causes implausible artifacts, especially when facing occlusion. To address this issue, we propose a lifting-and-projection framework to perform pose transfer in the 3D mesh space. The core of our framework is a foreground generation module, that consists of two novel networks: a lifting-and-projection network (LPNet) and an appearance detail compensating network (ADCNet). To leverage the human body shape prior, LPNet exploits the topological information of the body mesh to learn an expressive visual representation for the target person in the 3D mesh space. To preserve texture details, ADCNet is further introduced to enhance the feature produced by LPNet with the source foreground image. Such design of the foreground generation module enables the model to better handle difficult cases such as those with occlusions. Experiments on the iPER and Fashion datasets empirically demonstrate that the proposed lifting-and-projection framework is effective and outperforms the existing image-to-image-based and mesh-based methods on human pose transfer task in both self-transfer and cross-transfer settings.