 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDBL: Communication and Data Efficient Federated Deep-Broad Learning for Histopathological Tissue Classification
Feb 24, 2023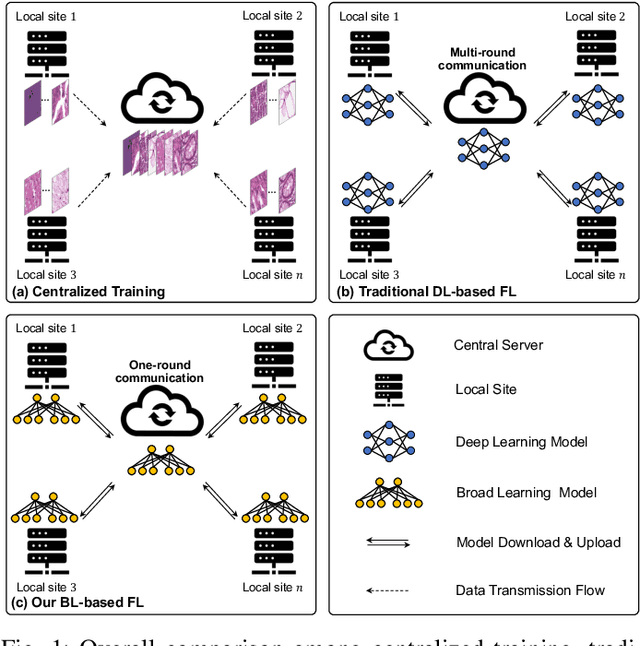
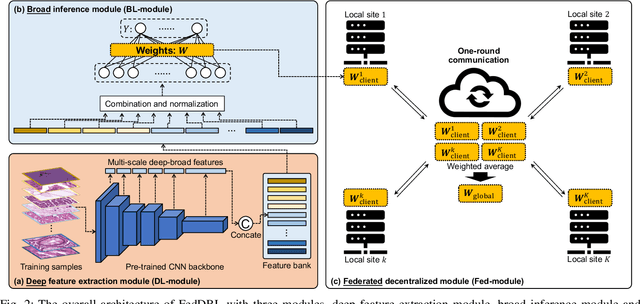
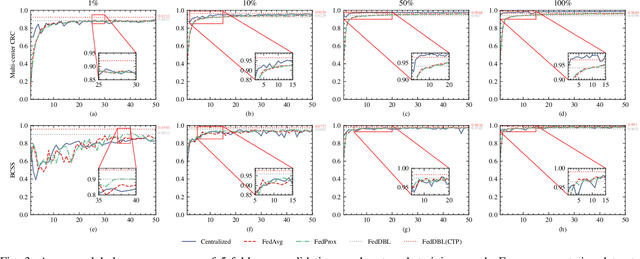

Histopathological tissue classification is a fundamental task in computational pathology. Deep learning-based models have achieved superior performance but centralized training with data centralization suffers from the privacy leakage problem. Federated learning (FL) can safeguard privacy by keeping training samples locally, but existing FL-based frameworks require a large number of well-annotated training samples and numerous rounds of communication which hinder their practicability in the real-world clinical scenario. In this paper, we propose a universal and lightweight federated learning framework, named Federated Deep-Broad Learning (FedDBL), to achieve superior classification performance with limited training samples and only one-round communication. By simply associating a pre-trained deep learning feature extractor, a fast and lightweight broad learning inference system and a classical federated aggregation approach, FedDBL can dramatically reduce data dependency and improve communication efficiency. Five-fold cross-validation demonstrates that FedDBL greatly outperforms the competitors with only one-round communication and limited training samples, while it even achieves comparable performance with the ones under multiple-round communications. Furthermore, due to the lightweight design and one-round communication, FedDBL reduces the communication burden from 4.6GB to only 276.5KB per client using the ResNet-50 backbone at 50-round training. Since no data or deep model sharing across different clients, the privacy issue is well-solved and the model security is guaranteed with no model inversion attack risk. Code is available at https://github.com/tianpeng-deng/FedDBL.
Demonstration-Guided Reinforcement Learning with Efficient Exploration for Task Automation of Surgical Robot
Feb 20, 2023Task automation of surgical robot has the potentials to improve surgical efficiency. Recent reinforcement learning (RL) based approaches provide scalable solutions to surgical automation, but typically require extensive data collection to solve a task if no prior knowledge is given. This issue is known as the exploration challenge, which can be alleviated by providing expert demonstrations to an RL agent. Yet, how to make effective use of demonstration data to improve exploration efficiency still remains an open challenge. In this work, we introduce Demonstration-guided EXploration (DEX), an efficient reinforcement learning algorithm that aims to overcome the exploration problem with expert demonstrations for surgical automation. To effectively exploit demonstrations, our method estimates expert-like behaviors with higher values to facilitate productive interactions, and adopts non-parametric regression to enable such guidance at states unobserved in demonstration data. Extensive experiments on $10$ surgical manipulation tasks from SurRoL, a comprehensive surgical simulation platform, demonstrate significant improvements in the exploration efficiency and task success rates of our method. Moreover, we also deploy the learned policies to the da Vinci Research Kit (dVRK) platform to show the effectiveness on the real robot. Code is available at https://github.com/med-air/DEX.
RecolorNeRF: Layer Decomposed Radiance Field for Efficient Color Editing of 3D Scenes
Jan 19, 2023



Radiance fields have gradually become a main representation of media. Although its appearance editing has been studied, how to achieve view-consistent recoloring in an efficient manner is still under explored. We present RecolorNeRF, a novel user-friendly color editing approach for the neural radiance field. Our key idea is to decompose the scene into a set of pure-colored layers, forming a palette. Thus, color manipulation can be conducted by altering the color components of the palette directly. To support efficient palette-based editing, the color of each layer needs to be as representative as possible. In the end, the problem is formulated as in an optimization formula, where the layers and their blending way are jointly optimized with the NeRF itself. Extensive experiments show that our jointly-optimized layer decomposition can be used against multiple backbones and produce photo-realistic recolored novel-view renderings. We demonstrate that RecolorNeRF outperforms baseline methods both quantitatively and qualitatively for color editing even in complex real-world scenes.
On Fairness of Medical Image Classification with Multiple Sensitive Attributes via Learning Orthogonal Representations
Jan 04, 2023Mitigating the discrimination of machine learning models has gained increasing attention in medical image analysis. However, rare works focus on fair treatments for patients with multiple sensitive demographic ones, which is a crucial yet challenging problem for real-world clinical applications. In this paper, we propose a novel method for fair representation learning with respect to multi-sensitive attributes. We pursue the independence between target and multi-sensitive representations by achieving orthogonality in the representation space. Concretely, we enforce the column space orthogonality by keeping target information on the complement of a low-rank sensitive space. Furthermore, in the row space, we encourage feature dimensions between target and sensitive representations to be orthogonal. The effectiveness of the proposed method is demonstrated with extensive experiments on the CheXpert dataset. To our best knowledge, this is the first work to mitigate unfairness with respect to multiple sensitive attributes in the field of medical imaging.
Human-in-the-loop Embodied Intelligence with Interactive Simulation Environment for Surgical Robot Learning
Jan 01, 2023



Surgical robot automation has attracted increasing research interest over the past decade, expecting its huge potential to benefit surgeons, nurses and patients. Recently, the learning paradigm of embodied AI has demonstrated promising ability to learn good control policies for various complex tasks, where embodied AI simulators play an essential role to facilitate relevant researchers. However, existing open-sourced simulators for surgical robot are still not sufficiently supporting human interactions through physical input devices, which further limits effective investigations on how human demonstrations would affect policy learning. In this paper, we study human-in-the-loop embodied intelligence with a new interactive simulation platform for surgical robot learning. Specifically, we establish our platform based on our previously released SurRoL simulator with several new features co-developed to allow high-quality human interaction via an input device. With these, we further propose to collect human demonstrations and imitate the action patterns to achieve more effective policy learning. We showcase the improvement of our simulation environment with the designed new features and tasks, and validate state-of-the-art reinforcement learning algorithms using the interactive environment. Promising results are obtained, with which we hope to pave the way for future research on surgical embodied intelligence. Our platform is released and will be continuously updated in the website: https://med-air.github.io/SurRoL/
Diffusion Model based Semi-supervised Learning on Brain Hemorrhage Images for Efficient Midline Shift Quantification
Jan 01, 2023



Brain midline shift (MLS) is one of the most critical factors to be considered for clinical diagnosis and treatment decision-making for intracranial hemorrhage. Existing computational methods on MLS quantification not only require intensive labeling in millimeter-level measurement but also suffer from poor performance due to their dependence on specific landmarks or simplified anatomical assumptions. In this paper, we propose a novel semi-supervised framework to accurately measure the scale of MLS from head CT scans. We formulate the MLS measurement task as a deformation estimation problem and solve it using a few MLS slices with sparse labels. Meanwhile, with the help of diffusion models, we are able to use a great number of unlabeled MLS data and 2793 non-MLS cases for representation learning and regularization. The extracted representation reflects how the image is different from a non-MLS image and regularization serves an important role in the sparse-to-dense refinement of the deformation field. Our experiment on a real clinical brain hemorrhage dataset has achieved state-of-the-art performance and can generate interpretable deformation fields.
Distilled Visual and Robot Kinematics Embeddings for Metric Depth Estimation in Monocular Scene Reconstruction
Nov 27, 2022



Estimating precise metric depth and scene reconstruction from monocular endoscopy is a fundamental task for surgical navigation in robotic surgery. However, traditional stereo matching adopts binocular images to perceive the depth information, which is difficult to transfer to the soft robotics-based surgical systems due to the use of monocular endoscopy. In this paper, we present a novel framework that combines robot kinematics and monocular endoscope images with deep unsupervised learning into a single network for metric depth estimation and then achieve 3D reconstruction of complex anatomy. Specifically, we first obtain the relative depth maps of surgical scenes by leveraging a brightness-aware monocular depth estimation method. Then, the corresponding endoscope poses are computed based on non-linear optimization of geometric and photometric reprojection residuals. Afterwards, we develop a Depth-driven Sliding Optimization (DDSO) algorithm to extract the scaling coefficient from kinematics and calculated poses offline. By coupling the metric scale and relative depth data, we form a robust ensemble that represents the metric and consistent depth. Next, we treat the ensemble as supervisory labels to train a metric depth estimation network for surgeries (i.e., MetricDepthS-Net) that distills the embeddings from the robot kinematics, endoscopic videos, and poses. With accurate metric depth estimation, we utilize a dense visual reconstruction method to recover the 3D structure of the whole surgical site. We have extensively evaluated the proposed framework on public SCARED and achieved comparable performance with stereo-based depth estimation methods. Our results demonstrate the feasibility of the proposed approach to recover the metric depth and 3D structure with monocular inputs.
StereoPose: Category-Level 6D Transparent Object Pose Estimation from Stereo Images via Back-View NOCS
Nov 03, 2022



Most existing methods for category-level pose estimation rely on object point clouds. However, when considering transparent objects, depth cameras are usually not able to capture meaningful data, resulting in point clouds with severe artifacts. Without a high-quality point cloud, existing methods are not applicable to challenging transparent objects. To tackle this problem, we present StereoPose, a novel stereo image framework for category-level object pose estimation, ideally suited for transparent objects. For a robust estimation from pure stereo images, we develop a pipeline that decouples category-level pose estimation into object size estimation, initial pose estimation, and pose refinement. StereoPose then estimates object pose based on representation in the normalized object coordinate space~(NOCS). To address the issue of image content aliasing, we further define a back-view NOCS map for the transparent object. The back-view NOCS aims to reduce the network learning ambiguity caused by content aliasing, and leverage informative cues on the back of the transparent object for more accurate pose estimation. To further improve the performance of the stereo framework, StereoPose is equipped with a parallax attention module for stereo feature fusion and an epipolar loss for improving the stereo-view consistency of network predictions. Extensive experiments on the public TOD dataset demonstrate the superiority of the proposed StereoPose framework for category-level 6D transparent object pose estimation.
Learning Deep Nets for Gravitational Dynamics with Unknown Disturbance through Physical Knowledge Distillation: Initial Feasibility Study
Oct 04, 2022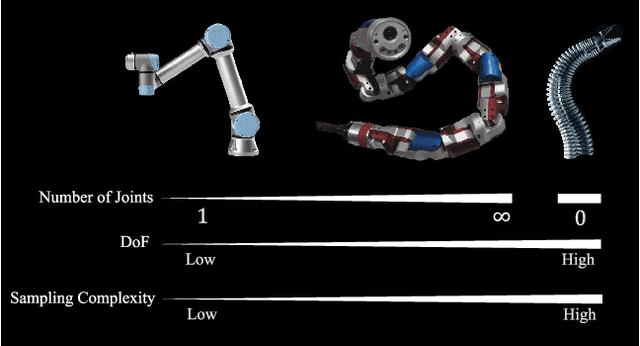
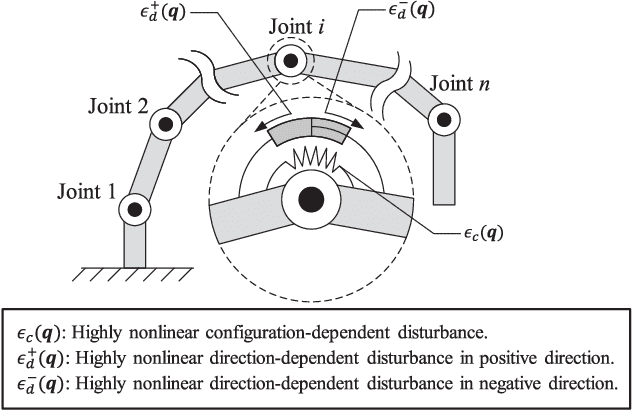
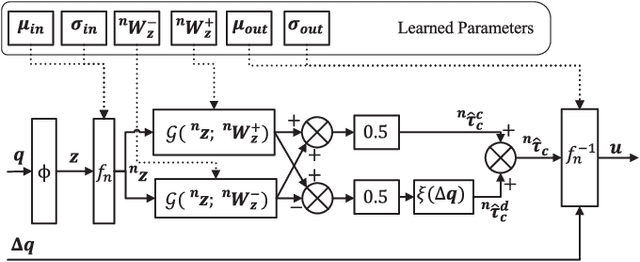

Learning high-performance deep neural networks for dynamic modeling of high Degree-Of-Freedom (DOF) robots remains challenging due to the sampling complexity. Typical unknown system disturbance caused by unmodeled dynamics (such as internal compliance, cables) further exacerbates the problem. In this paper, a novel framework characterized by both high data efficiency and disturbance-adapting capability is proposed to address the problem of modeling gravitational dynamics using deep nets in feedforward gravity compensation control for high-DOF master manipulators with unknown disturbance. In particular, Feedforward Deep Neural Networks (FDNNs) are learned from both prior knowledge of an existing analytical model and observation of the robot system by Knowledge Distillation (KD). Through extensive experiments in high-DOF master manipulators with significant disturbance, we show that our method surpasses a standard Learning-from-Scratch (LfS) approach in terms of data efficiency and disturbance adaptation. Our initial feasibility study has demonstrated the potential of outperforming the analytical teacher model as the training data increases.
Federated Domain Generalization for Image Recognition via Cross-Client Style Transfer
Oct 03, 2022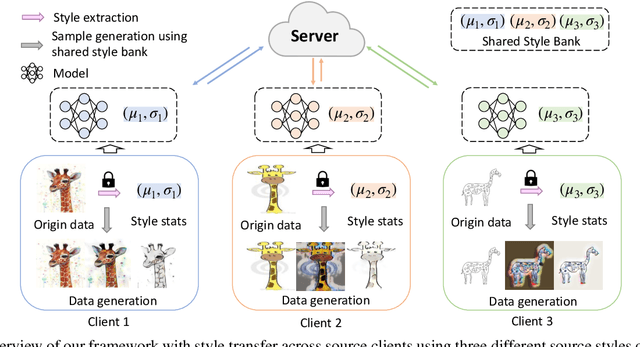
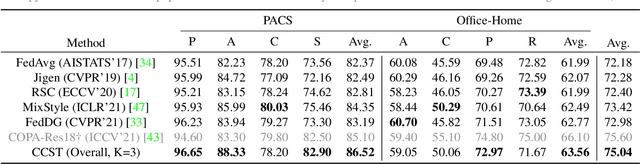
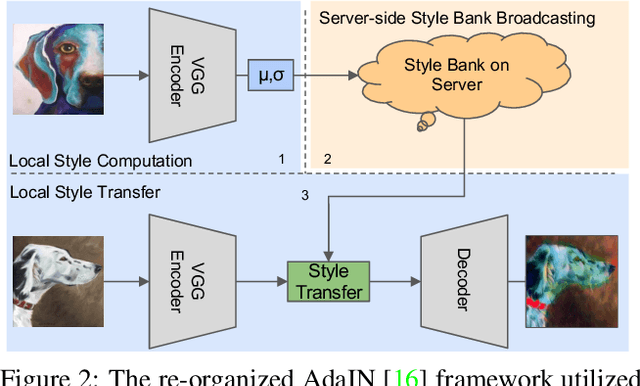
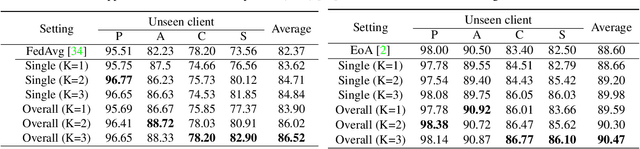
Domain generalization (DG) has been a hot topic in image recognition, with a goal to train a general model that can perform well on unseen domains. Recently, federated learning (FL), an emerging machine learning paradigm to train a global model from multiple decentralized clients without compromising data privacy, brings new challenges, also new possibilities, to DG. In the FL scenario, many existing state-of-the-art (SOTA) DG methods become ineffective, because they require the centralization of data from different domains during training. In this paper, we propose a novel domain generalization method for image recognition under federated learning through cross-client style transfer (CCST) without exchanging data samples. Our CCST method can lead to more uniform distributions of source clients, and thus make each local model learn to fit the image styles of all the clients to avoid the different model biases. Two types of style (single image style and overall domain style) with corresponding mechanisms are proposed to be chosen according to different scenarios. Our style representation is exceptionally lightweight and can hardly be used for the reconstruction of the dataset. The level of diversity is also flexible to be controlled with a hyper-parameter. Our method outperforms recent SOTA DG methods on two DG benchmarks (PACS, OfficeHome) and a large-scale medical image dataset (Camelyon17) in the FL setting. Last but not least, our method is orthogonal to many classic DG methods, achieving additive performance by combined utilization.