 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Estimating Causal Effects using Neural Networks
Aug 23, 2018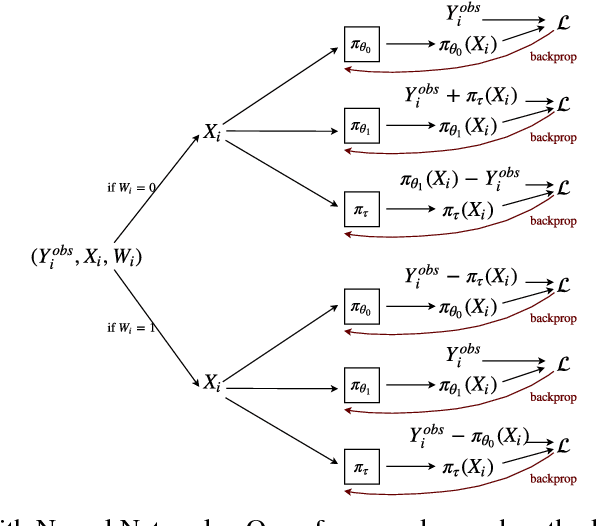
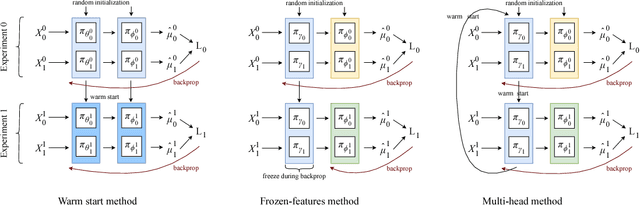
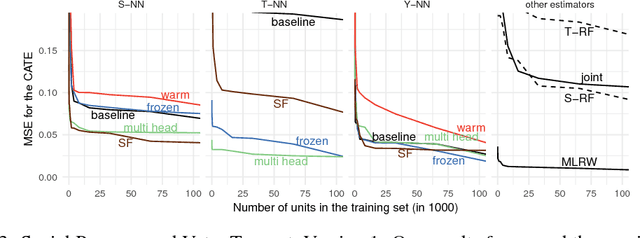
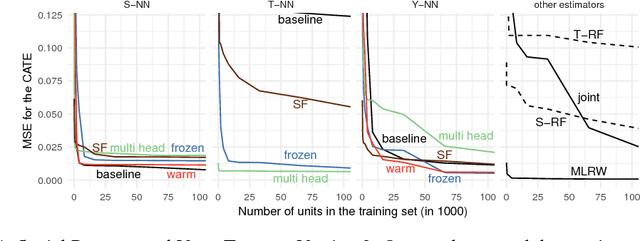
We develop new algorithms for estimating heterogeneous treatment effects, combining recent developments in transfer learning for neural networks with insights from the causal inference literature. By taking advantage of transfer learning, we are able to efficiently use different data sources that are related to the same underlying causal mechanisms. We compare our algorithms with those in the extant literature using extensive simulation studies based on large-scale voter persuasion experiments and the MNIST database. Our methods can perform an order of magnitude better than existing benchmarks while using a fraction of the data.
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Aug 08, 2018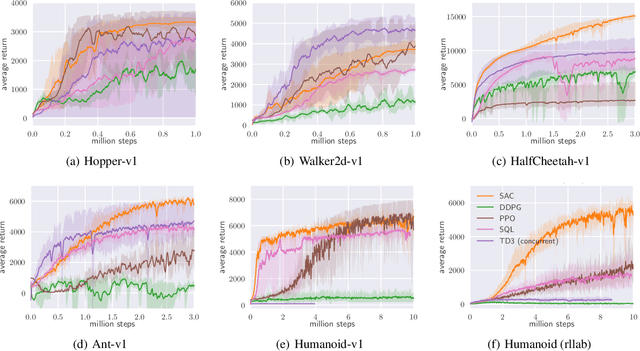

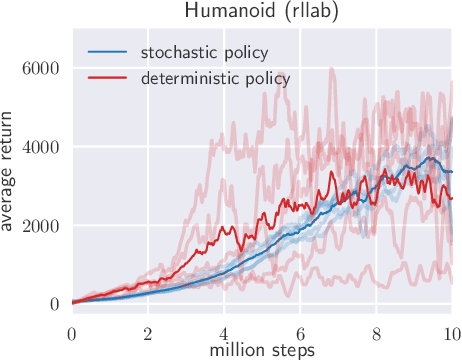

Model-free deep reinforcement learning (RL) algorithms have been demonstrated on a range of challenging decision making and control tasks. However, these methods typically suffer from two major challenges: very high sample complexity and brittle convergence properties, which necessitate meticulous hyperparameter tuning. Both of these challenges severely limit the applicability of such methods to complex, real-world domains. In this paper, we propose soft actor-critic, an off-policy actor-critic deep RL algorithm based on the maximum entropy reinforcement learning framework. In this framework, the actor aims to maximize expected reward while also maximizing entropy. That is, to succeed at the task while acting as randomly as possible. Prior deep RL methods based on this framework have been formulated as Q-learning methods. By combining off-policy updates with a stable stochastic actor-critic formulation, our method achieves state-of-the-art performance on a range of continuous control benchmark tasks, outperforming prior on-policy and off-policy methods. Furthermore, we demonstrate that, in contrast to other off-policy algorithms, our approach is very stable, achieving very similar performance across different random seeds.
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Jul 27, 2018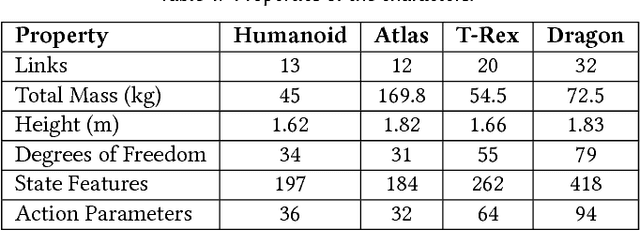
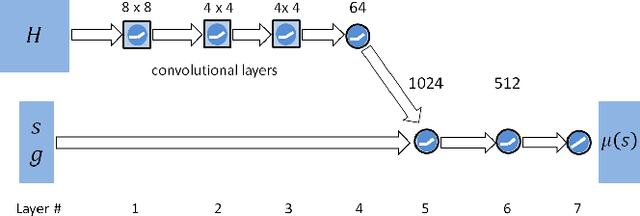
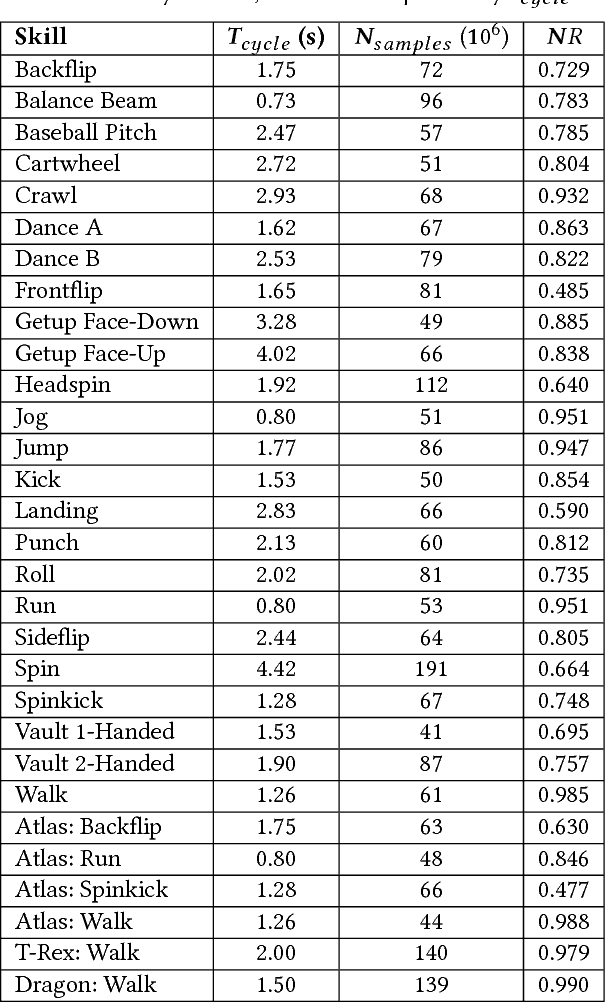
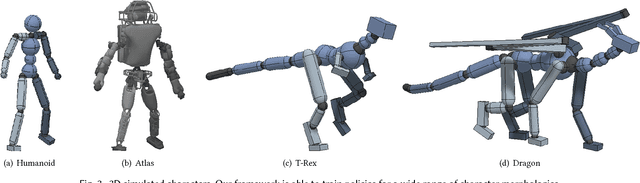
A longstanding goal in character animation is to combine data-driven specification of behavior with a system that can execute a similar behavior in a physical simulation, thus enabling realistic responses to perturbations and environmental variation. We show that well-known reinforcement learning (RL) methods can be adapted to learn robust control policies capable of imitating a broad range of example motion clips, while also learning complex recoveries, adapting to changes in morphology, and accomplishing user-specified goals. Our method handles keyframed motions, highly-dynamic actions such as motion-captured flips and spins, and retargeted motions. By combining a motion-imitation objective with a task objective, we can train characters that react intelligently in interactive settings, e.g., by walking in a desired direction or throwing a ball at a user-specified target. This approach thus combines the convenience and motion quality of using motion clips to define the desired style and appearance, with the flexibility and generality afforded by RL methods and physics-based animation. We further explore a number of methods for integrating multiple clips into the learning process to develop multi-skilled agents capable of performing a rich repertoire of diverse skills. We demonstrate results using multiple characters (human, Atlas robot, bipedal dinosaur, dragon) and a large variety of skills, including locomotion, acrobatics, and martial arts.
Variational Option Discovery Algorithms
Jul 26, 2018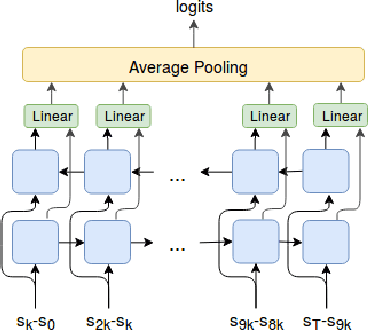
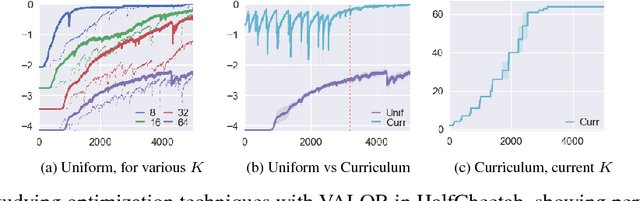
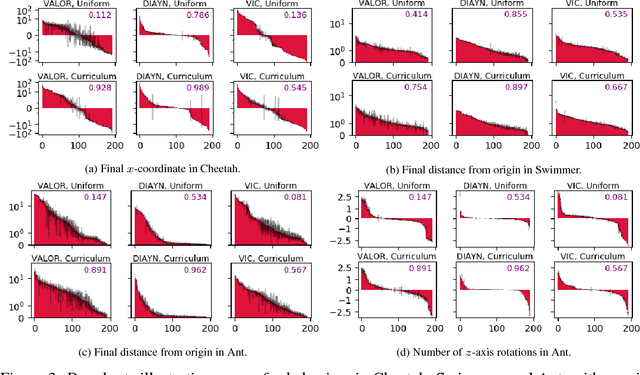
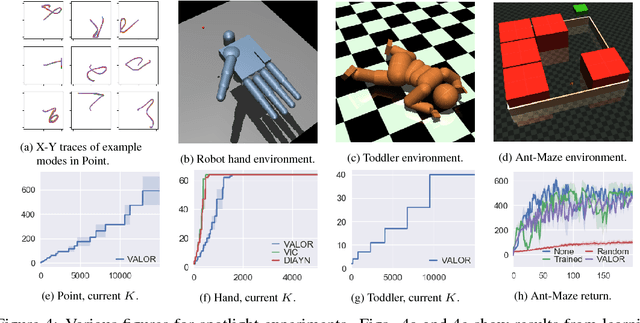
We explore methods for option discovery based on variational inference and make two algorithmic contributions. First: we highlight a tight connection between variational option discovery methods and variational autoencoders, and introduce Variational Autoencoding Learning of Options by Reinforcement (VALOR), a new method derived from the connection. In VALOR, the policy encodes contexts from a noise distribution into trajectories, and the decoder recovers the contexts from the complete trajectories. Second: we propose a curriculum learning approach where the number of contexts seen by the agent increases whenever the agent's performance is strong enough (as measured by the decoder) on the current set of contexts. We show that this simple trick stabilizes training for VALOR and prior variational option discovery methods, allowing a single agent to learn many more modes of behavior than it could with a fixed context distribution. Finally, we investigate other topics related to variational option discovery, including fundamental limitations of the general approach and the applicability of learned options to downstream tasks.
Learning Generalized Reactive Policies using Deep Neural Networks
Jul 25, 2018
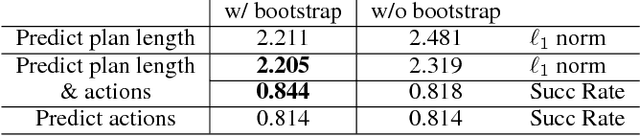
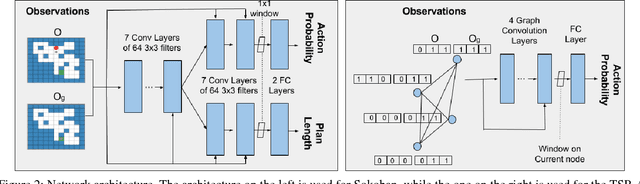

We present a new approach to learning for planning, where knowledge acquired while solving a given set of planning problems is used to plan faster in related, but new problem instances. We show that a deep neural network can be used to learn and represent a \emph{generalized reactive policy} (GRP) that maps a problem instance and a state to an action, and that the learned GRPs efficiently solve large classes of challenging problem instances. In contrast to prior efforts in this direction, our approach significantly reduces the dependence of learning on handcrafted domain knowledge or feature selection. Instead, the GRP is trained from scratch using a set of successful execution traces. We show that our approach can also be used to automatically learn a heuristic function that can be used in directed search algorithms. We evaluate our approach using an extensive suite of experiments on two challenging planning problem domains and show that our approach facilitates learning complex decision making policies and powerful heuristic functions with minimal human input. Videos of our results are available at goo.gl/Hpy4e3.
Learning Robotic Assembly from CAD
Jul 24, 2018
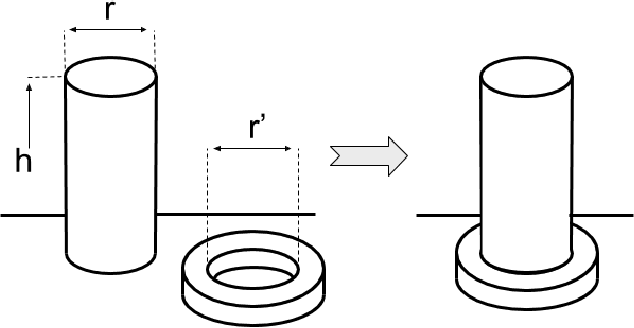
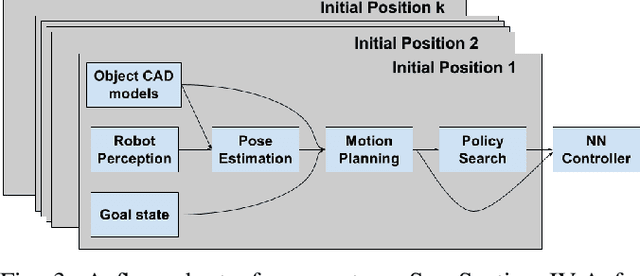
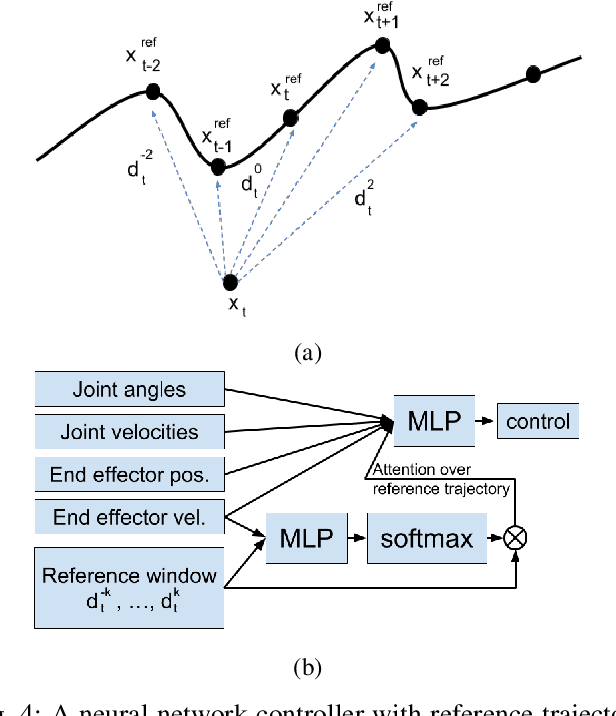
In this work, motivated by recent manufacturing trends, we investigate autonomous robotic assembly. Industrial assembly tasks require contact-rich manipulation skills, which are challenging to acquire using classical control and motion planning approaches. Consequently, robot controllers for assembly domains are presently engineered to solve a particular task, and cannot easily handle variations in the product or environment. Reinforcement learning (RL) is a promising approach for autonomously acquiring robot skills that involve contact-rich dynamics. However, RL relies on random exploration for learning a control policy, which requires many robot executions, and often gets trapped in locally suboptimal solutions. Instead, we posit that prior knowledge, when available, can improve RL performance. We exploit the fact that in modern assembly domains, geometric information about the task is readily available via the CAD design files. We propose to leverage this prior knowledge by guiding RL along a geometric motion plan, calculated using the CAD data. We show that our approach effectively improves over traditional control approaches for tracking the motion plan, and can solve assembly tasks that require high precision, even without accurate state estimation. In addition, we propose a neural network architecture that can learn to track the motion plan, and generalize the assembly controller to changes in the object positions.
Learning Plannable Representations with Causal InfoGAN
Jul 24, 2018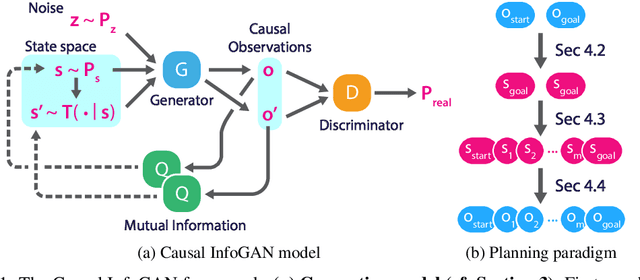

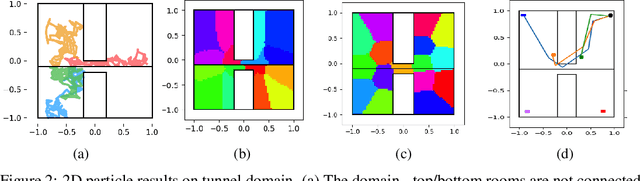
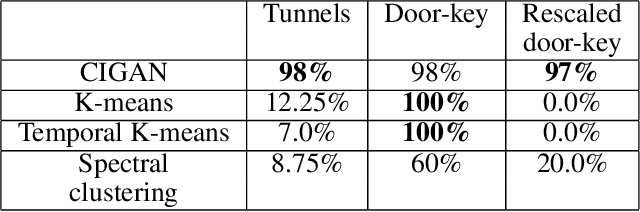
In recent years, deep generative models have been shown to 'imagine' convincing high-dimensional observations such as images, audio, and even video, learning directly from raw data. In this work, we ask how to imagine goal-directed visual plans -- a plausible sequence of observations that transition a dynamical system from its current configuration to a desired goal state, which can later be used as a reference trajectory for control. We focus on systems with high-dimensional observations, such as images, and propose an approach that naturally combines representation learning and planning. Our framework learns a generative model of sequential observations, where the generative process is induced by a transition in a low-dimensional planning model, and an additional noise. By maximizing the mutual information between the generated observations and the transition in the planning model, we obtain a low-dimensional representation that best explains the causal nature of the data. We structure the planning model to be compatible with efficient planning algorithms, and we propose several such models based on either discrete or continuous states. Finally, to generate a visual plan, we project the current and goal observations onto their respective states in the planning model, plan a trajectory, and then use the generative model to transform the trajectory to a sequence of observations. We demonstrate our method on imagining plausible visual plans of rope manipulation.
Emergence of Grounded Compositional Language in Multi-Agent Populations
Jul 24, 2018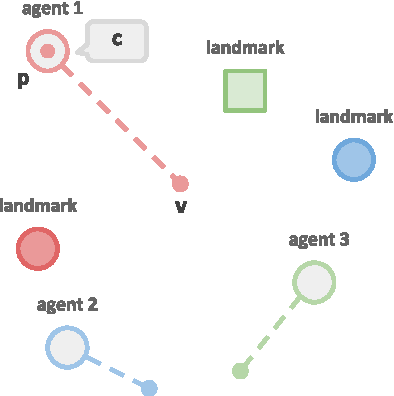
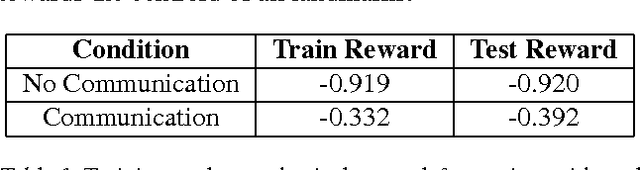
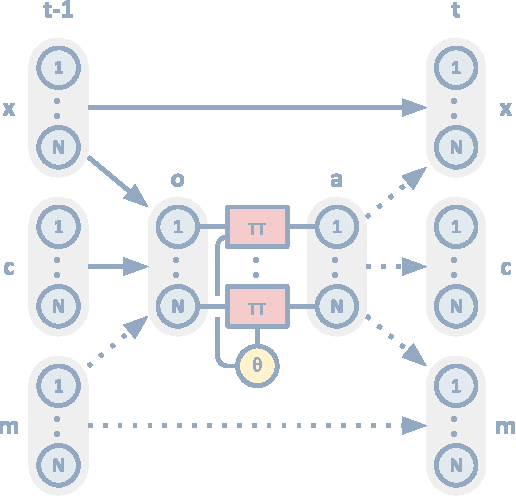
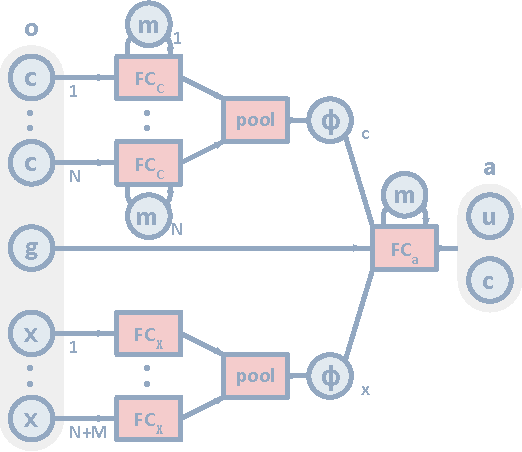
By capturing statistical patterns in large corpora, machine learning has enabled significant advances in natural language processing, including in machine translation, question answering, and sentiment analysis. However, for agents to intelligently interact with humans, simply capturing the statistical patterns is insufficient. In this paper we investigate if, and how, grounded compositional language can emerge as a means to achieve goals in multi-agent populations. Towards this end, we propose a multi-agent learning environment and learning methods that bring about emergence of a basic compositional language. This language is represented as streams of abstract discrete symbols uttered by agents over time, but nonetheless has a coherent structure that possesses a defined vocabulary and syntax. We also observe emergence of non-verbal communication such as pointing and guiding when language communication is unavailable.
Safer Classification by Synthesis
Jul 23, 2018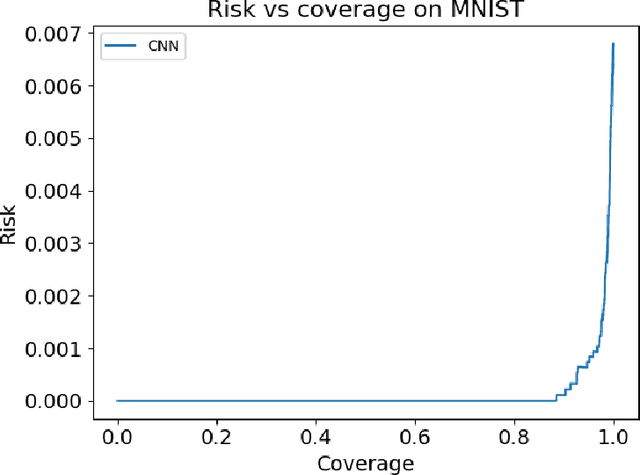
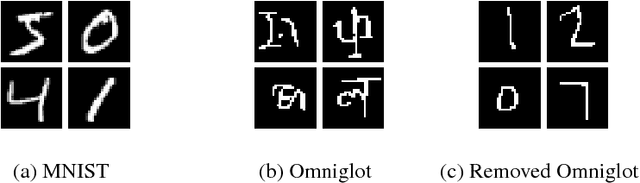
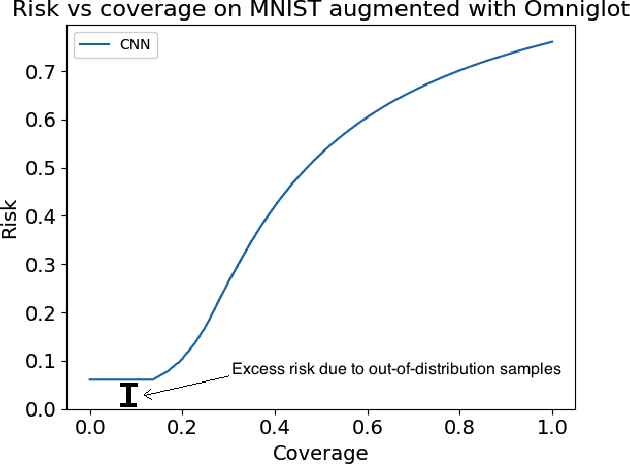
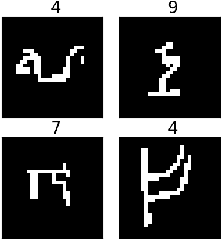
The discriminative approach to classification using deep neural networks has become the de-facto standard in various fields. Complementing recent reservations about safety against adversarial examples, we show that conventional discriminative methods can easily be fooled to provide incorrect labels with very high confidence to out of distribution examples. We posit that a generative approach is the natural remedy for this problem, and propose a method for classification using generative models. At training time, we learn a generative model for each class, while at test time, given an example to classify, we query each generator for its most similar generation, and select the class corresponding to the most similar one. Our approach is general and can be used with expressive models such as GANs and VAEs. At test time, our method accurately "knows when it does not know," and provides resilience to out of distribution examples while maintaining competitive performance for standard examples.
Reverse Curriculum Generation for Reinforcement Learning
Jul 23, 2018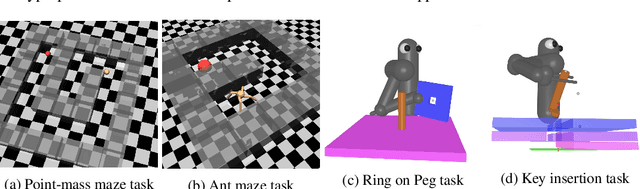
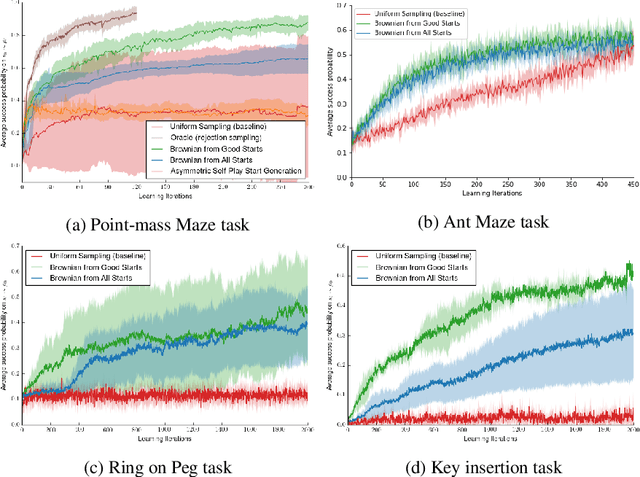
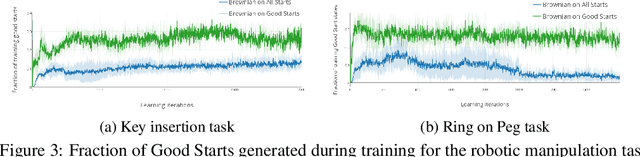
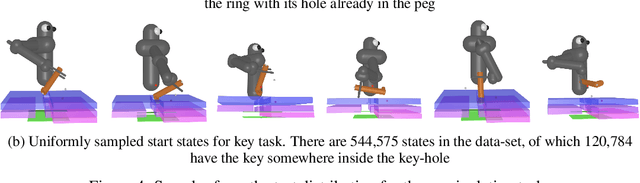
Many relevant tasks require an agent to reach a certain state, or to manipulate objects into a desired configuration. For example, we might want a robot to align and assemble a gear onto an axle or insert and turn a key in a lock. These goal-oriented tasks present a considerable challenge for reinforcement learning, since their natural reward function is sparse and prohibitive amounts of exploration are required to reach the goal and receive some learning signal. Past approaches tackle these problems by exploiting expert demonstrations or by manually designing a task-specific reward shaping function to guide the learning agent. Instead, we propose a method to learn these tasks without requiring any prior knowledge other than obtaining a single state in which the task is achieved. The robot is trained in reverse, gradually learning to reach the goal from a set of start states increasingly far from the goal. Our method automatically generates a curriculum of start states that adapts to the agent's performance, leading to efficient training on goal-oriented tasks. We demonstrate our approach on difficult simulated navigation and fine-grained manipulation problems, not solvable by state-of-the-art reinforcement learning methods.