 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule Based Rewards for Language Model Safety
Nov 02, 2024Reinforcement learning based fine-tuning of large language models (LLMs) on human preferences has been shown to enhance both their capabilities and safety behavior. However, in cases related to safety, without precise instructions to human annotators, the data collected may cause the model to become overly cautious, or to respond in an undesirable style, such as being judgmental. Additionally, as model capabilities and usage patterns evolve, there may be a costly need to add or relabel data to modify safety behavior. We propose a novel preference modeling approach that utilizes AI feedback and only requires a small amount of human data. Our method, Rule Based Rewards (RBR), uses a collection of rules for desired or undesired behaviors (e.g. refusals should not be judgmental) along with a LLM grader. In contrast to prior methods using AI feedback, our method uses fine-grained, composable, LLM-graded few-shot prompts as reward directly in RL training, resulting in greater control, accuracy and ease of updating. We show that RBRs are an effective training method, achieving an F1 score of 97.1, compared to a human-feedback baseline of 91.7, resulting in much higher safety-behavior accuracy through better balancing usefulness and safety.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
A Hazard Analysis Framework for Code Synthesis Large Language Models
Jul 25, 2022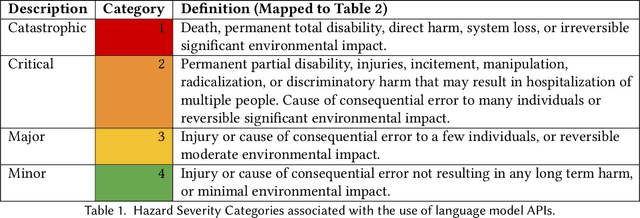
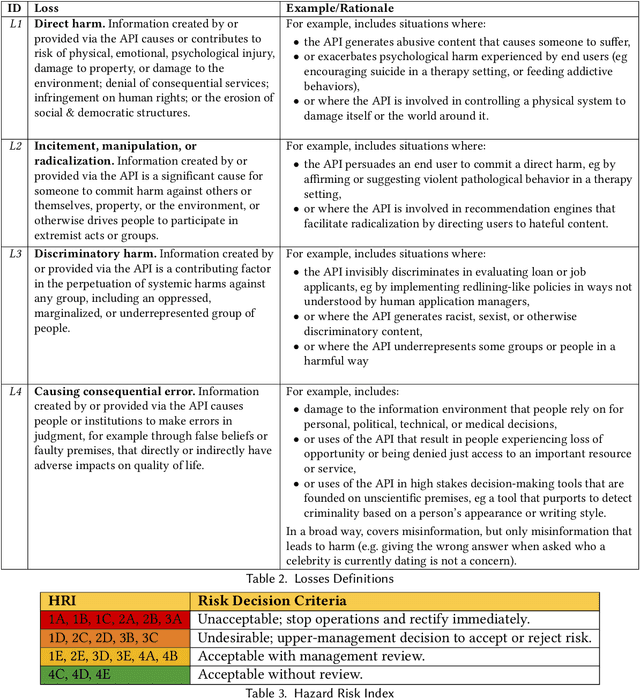
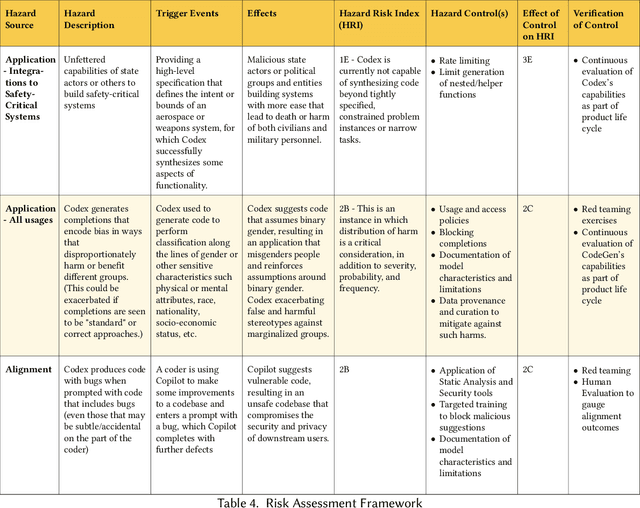
Codex, a large language model (LLM) trained on a variety of codebases, exceeds the previous state of the art in its capacity to synthesize and generate code. Although Codex provides a plethora of benefits, models that may generate code on such scale have significant limitations, alignment problems, the potential to be misused, and the possibility to increase the rate of progress in technical fields that may themselves have destabilizing impacts or have misuse potential. Yet such safety impacts are not yet known or remain to be explored. In this paper, we outline a hazard analysis framework constructed at OpenAI to uncover hazards or safety risks that the deployment of models like Codex may impose technically, socially, politically, and economically. The analysis is informed by a novel evaluation framework that determines the capacity of advanced code generation techniques against the complexity and expressivity of specification prompts, and their capability to understand and execute them relative to human ability.
Responsive Safety in Reinforcement Learning by PID Lagrangian Methods
Jul 08, 2020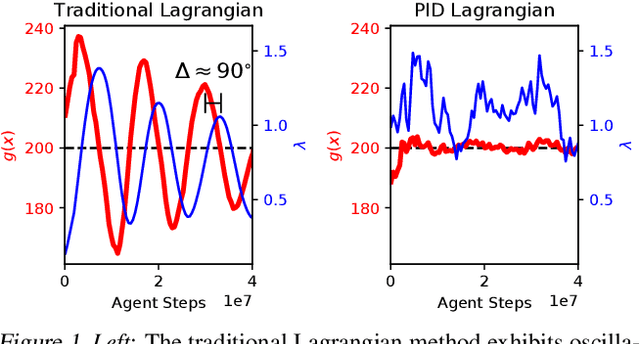
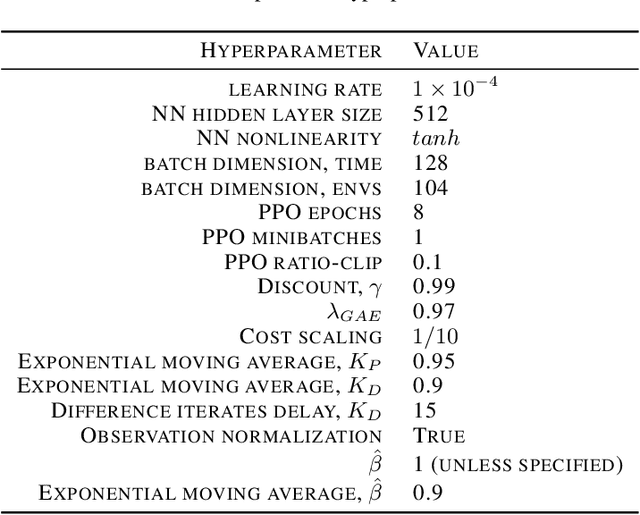
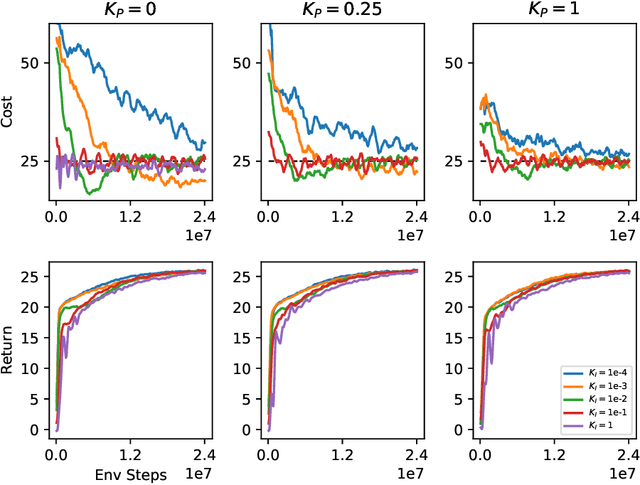

Lagrangian methods are widely used algorithms for constrained optimization problems, but their learning dynamics exhibit oscillations and overshoot which, when applied to safe reinforcement learning, leads to constraint-violating behavior during agent training. We address this shortcoming by proposing a novel Lagrange multiplier update method that utilizes derivatives of the constraint function. We take a controls perspective, wherein the traditional Lagrange multiplier update behaves as \emph{integral} control; our terms introduce \emph{proportional} and \emph{derivative} control, achieving favorable learning dynamics through damping and predictive measures. We apply our PID Lagrangian methods in deep RL, setting a new state of the art in Safety Gym, a safe RL benchmark. Lastly, we introduce a new method to ease controller tuning by providing invariance to the relative numerical scales of reward and cost. Our extensive experiments demonstrate improved performance and hyperparameter robustness, while our algorithms remain nearly as simple to derive and implement as the traditional Lagrangian approach.
Towards Characterizing Divergence in Deep Q-Learning
Mar 21, 2019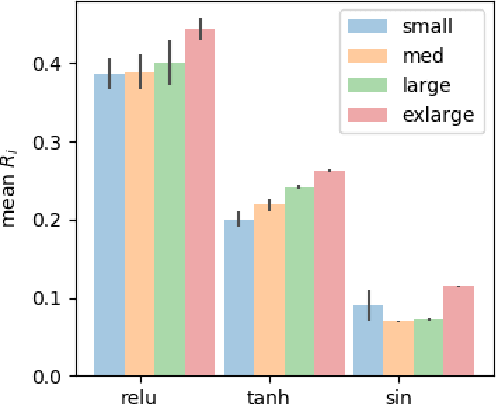
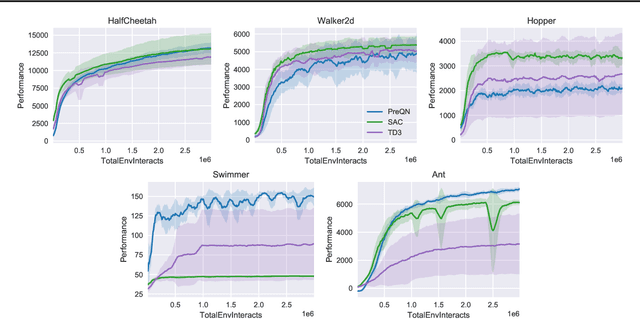
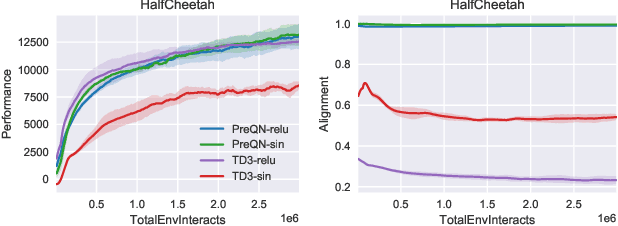
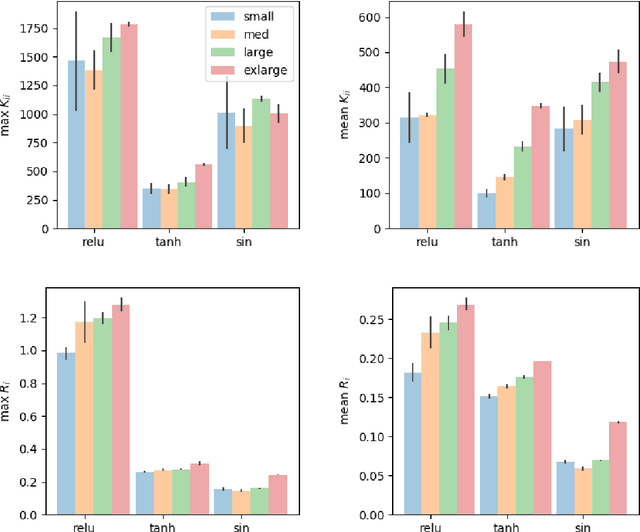
Deep Q-Learning (DQL), a family of temporal difference algorithms for control, employs three techniques collectively known as the `deadly triad' in reinforcement learning: bootstrapping, off-policy learning, and function approximation. Prior work has demonstrated that together these can lead to divergence in Q-learning algorithms, but the conditions under which divergence occurs are not well-understood. In this note, we give a simple analysis based on a linear approximation to the Q-value updates, which we believe provides insight into divergence under the deadly triad. The central point in our analysis is to consider when the leading order approximation to the deep-Q update is or is not a contraction in the sup norm. Based on this analysis, we develop an algorithm which permits stable deep Q-learning for continuous control without any of the tricks conventionally used (such as target networks, adaptive gradient optimizers, or using multiple Q functions). We demonstrate that our algorithm performs above or near state-of-the-art on standard MuJoCo benchmarks from the OpenAI Gym.
On First-Order Meta-Learning Algorithms
Oct 22, 2018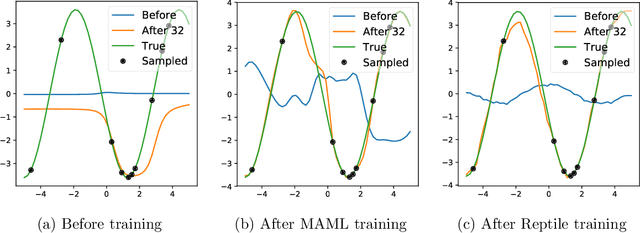
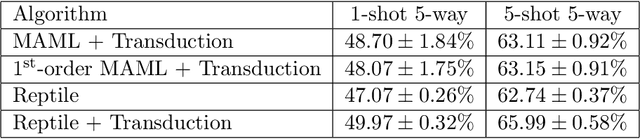

This paper considers meta-learning problems, where there is a distribution of tasks, and we would like to obtain an agent that performs well (i.e., learns quickly) when presented with a previously unseen task sampled from this distribution. We analyze a family of algorithms for learning a parameter initialization that can be fine-tuned quickly on a new task, using only first-order derivatives for the meta-learning updates. This family includes and generalizes first-order MAML, an approximation to MAML obtained by ignoring second-order derivatives. It also includes Reptile, a new algorithm that we introduce here, which works by repeatedly sampling a task, training on it, and moving the initialization towards the trained weights on that task. We expand on the results from Finn et al. showing that first-order meta-learning algorithms perform well on some well-established benchmarks for few-shot classification, and we provide theoretical analysis aimed at understanding why these algorithms work.
Variational Option Discovery Algorithms
Jul 26, 2018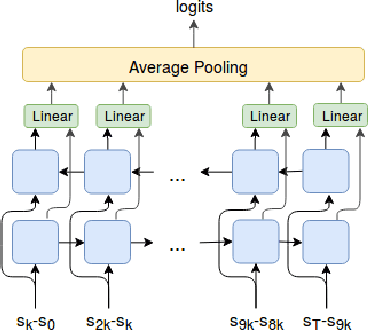
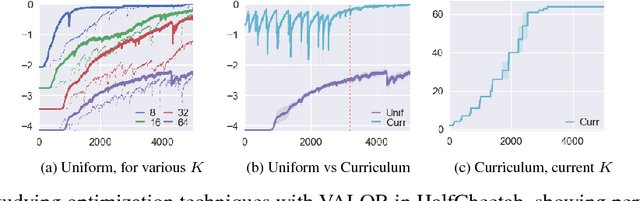
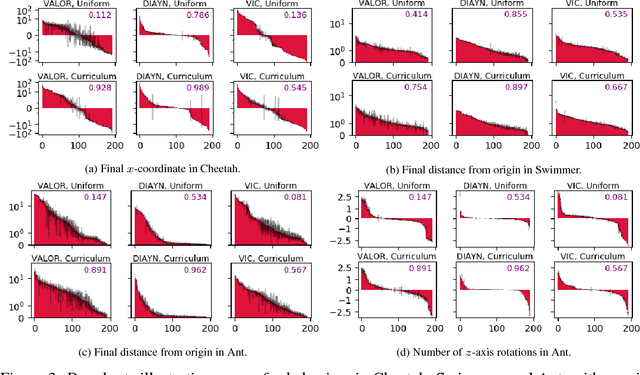
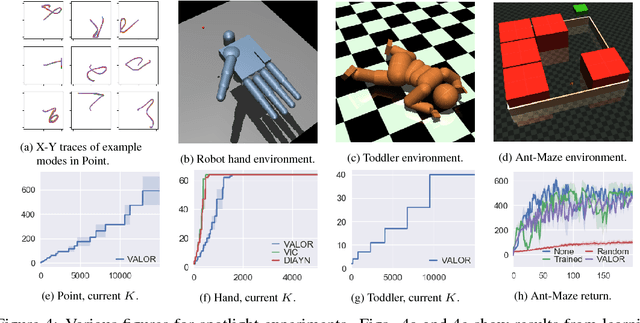
We explore methods for option discovery based on variational inference and make two algorithmic contributions. First: we highlight a tight connection between variational option discovery methods and variational autoencoders, and introduce Variational Autoencoding Learning of Options by Reinforcement (VALOR), a new method derived from the connection. In VALOR, the policy encodes contexts from a noise distribution into trajectories, and the decoder recovers the contexts from the complete trajectories. Second: we propose a curriculum learning approach where the number of contexts seen by the agent increases whenever the agent's performance is strong enough (as measured by the decoder) on the current set of contexts. We show that this simple trick stabilizes training for VALOR and prior variational option discovery methods, allowing a single agent to learn many more modes of behavior than it could with a fixed context distribution. Finally, we investigate other topics related to variational option discovery, including fundamental limitations of the general approach and the applicability of learned options to downstream tasks.
Constrained Policy Optimization
May 30, 2017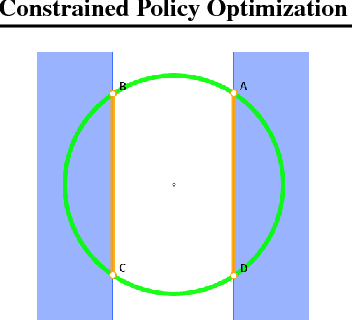
For many applications of reinforcement learning it can be more convenient to specify both a reward function and constraints, rather than trying to design behavior through the reward function. For example, systems that physically interact with or around humans should satisfy safety constraints. Recent advances in policy search algorithms (Mnih et al., 2016, Schulman et al., 2015, Lillicrap et al., 2016, Levine et al., 2016) have enabled new capabilities in high-dimensional control, but do not consider the constrained setting. We propose Constrained Policy Optimization (CPO), the first general-purpose policy search algorithm for constrained reinforcement learning with guarantees for near-constraint satisfaction at each iteration. Our method allows us to train neural network policies for high-dimensional control while making guarantees about policy behavior all throughout training. Our guarantees are based on a new theoretical result, which is of independent interest: we prove a bound relating the expected returns of two policies to an average divergence between them. We demonstrate the effectiveness of our approach on simulated robot locomotion tasks where the agent must satisfy constraints motivated by safety.
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
Mar 06, 2017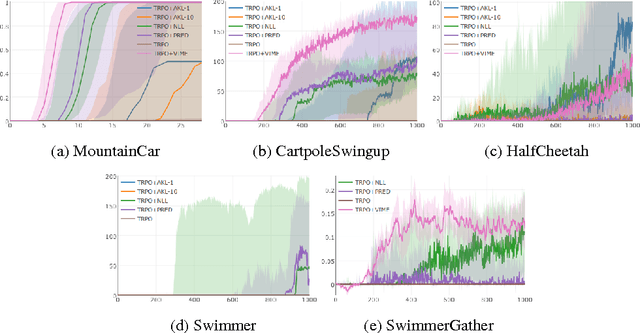


Exploration in complex domains is a key challenge in reinforcement learning, especially for tasks with very sparse rewards. Recent successes in deep reinforcement learning have been achieved mostly using simple heuristic exploration strategies such as $\epsilon$-greedy action selection or Gaussian control noise, but there are many tasks where these methods are insufficient to make any learning progress. Here, we consider more complex heuristics: efficient and scalable exploration strategies that maximize a notion of an agent's surprise about its experiences via intrinsic motivation. We propose to learn a model of the MDP transition probabilities concurrently with the policy, and to form intrinsic rewards that approximate the KL-divergence of the true transition probabilities from the learned model. One of our approximations results in using surprisal as intrinsic motivation, while the other gives the $k$-step learning progress. We show that our incentives enable agents to succeed in a wide range of environments with high-dimensional state spaces and very sparse rewards, including continuous control tasks and games in the Atari RAM domain, outperforming several other heuristic exploration techniques.
Easy Monotonic Policy Iteration
Feb 29, 2016A key problem in reinforcement learning for control with general function approximators (such as deep neural networks and other nonlinear functions) is that, for many algorithms employed in practice, updates to the policy or $Q$-function may fail to improve performance---or worse, actually cause the policy performance to degrade. Prior work has addressed this for policy iteration by deriving tight policy improvement bounds; by optimizing the lower bound on policy improvement, a better policy is guaranteed. However, existing approaches suffer from bounds that are hard to optimize in practice because they include sup norm terms which cannot be efficiently estimated or differentiated. In this work, we derive a better policy improvement bound where the sup norm of the policy divergence has been replaced with an average divergence; this leads to an algorithm, Easy Monotonic Policy Iteration, that generates sequences of policies with guaranteed non-decreasing returns and is easy to implement in a sample-based framework.