 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Neural Machine Translation with Generative Language Models Only
Oct 11, 2021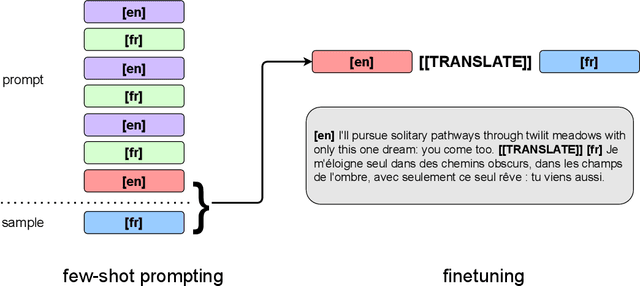
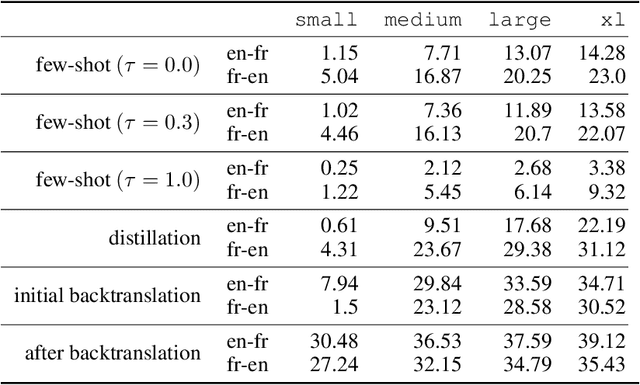
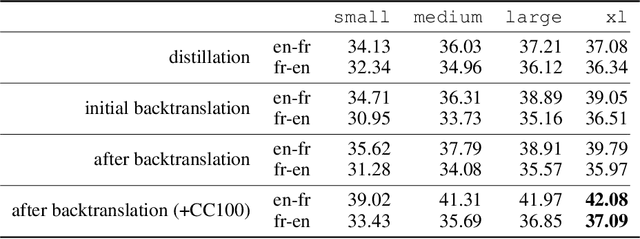

We show how to derive state-of-the-art unsupervised neural machine translation systems from generatively pre-trained language models. Our method consists of three steps: few-shot amplification, distillation, and backtranslation. We first use the zero-shot translation ability of large pre-trained language models to generate translations for a small set of unlabeled sentences. We then amplify these zero-shot translations by using them as few-shot demonstrations for sampling a larger synthetic dataset. This dataset is distilled by discarding the few-shot demonstrations and then fine-tuning. During backtranslation, we repeatedly generate translations for a set of inputs and then fine-tune a single language model on both directions of the translation task at once, ensuring cycle-consistency by swapping the roles of gold monotext and generated translations when fine-tuning. By using our method to leverage GPT-3's zero-shot translation capability, we achieve a new state-of-the-art in unsupervised translation on the WMT14 English-French benchmark, attaining a BLEU score of 42.1.
Autonomous object harvesting using synchronized optoelectronic microrobots
Mar 08, 2021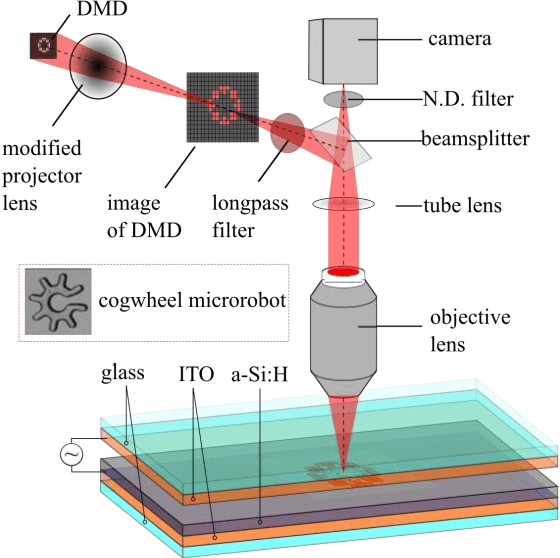

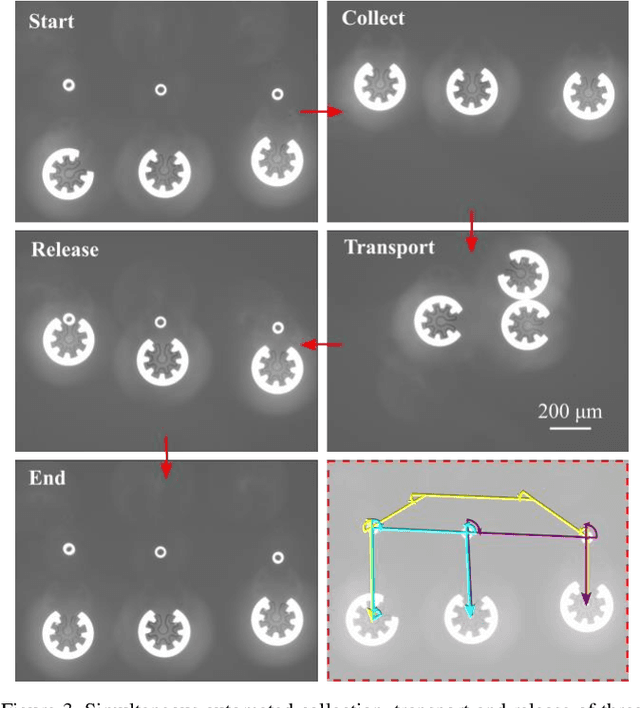
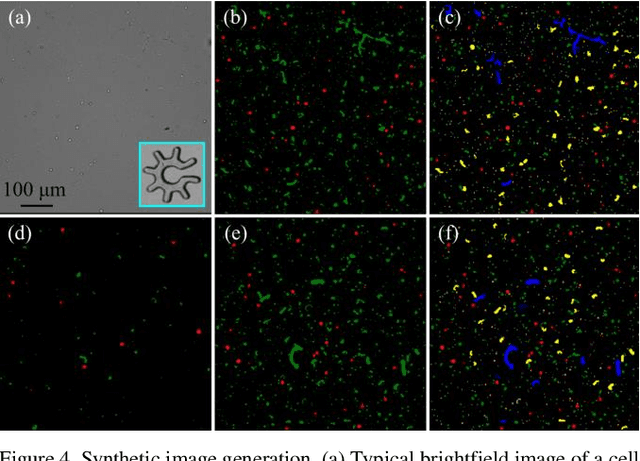
Optoelectronic tweezer-driven microrobots (OETdMs) are a versatile micromanipulation technology based on the use of light induced dielectrophoresis to move small dielectric structures (microrobots) across a photoconductive substrate. The microrobots in turn can be used to exert forces on secondary objects and carry out a wide range of micromanipulation operations, including collecting, transporting and depositing microscopic cargos. In contrast to alternative (direct) micromanipulation techniques, OETdMs are relatively gentle, making them particularly well suited to interacting with sensitive objects such as biological cells. However, at present such systems are used exclusively under manual control by a human operator. This limits the capacity for simultaneous control of multiple microrobots, reducing both experimental throughput and the possibility of cooperative multi-robot operations. In this article, we describe an approach to automated targeting and path planning to enable open-loop control of multiple microrobots. We demonstrate the performance of the method in practice, using microrobots to simultaneously collect, transport and deposit silica microspheres. Using computational simulations based on real microscopic image data, we investigate the capacity of microrobots to collect target cells from within a dissociated tissue culture. Our results indicate the feasibility of using OETdMs to autonomously carry out micromanipulation tasks within complex, unstructured environments.
Exploration by Random Network Distillation
Oct 30, 2018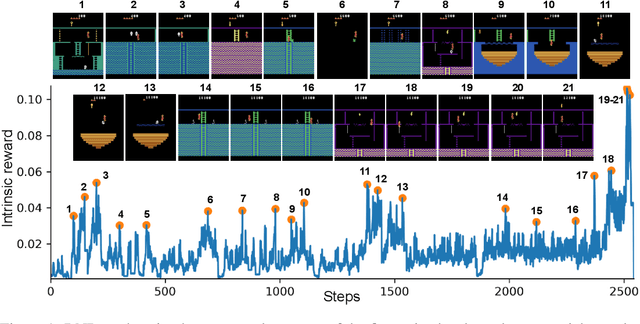


We introduce an exploration bonus for deep reinforcement learning methods that is easy to implement and adds minimal overhead to the computation performed. The bonus is the error of a neural network predicting features of the observations given by a fixed randomly initialized neural network. We also introduce a method to flexibly combine intrinsic and extrinsic rewards. We find that the random network distillation (RND) bonus combined with this increased flexibility enables significant progress on several hard exploration Atari games. In particular we establish state of the art performance on Montezuma's Revenge, a game famously difficult for deep reinforcement learning methods. To the best of our knowledge, this is the first method that achieves better than average human performance on this game without using demonstrations or having access to the underlying state of the game, and occasionally completes the first level.
How to train your MAML
Oct 22, 2018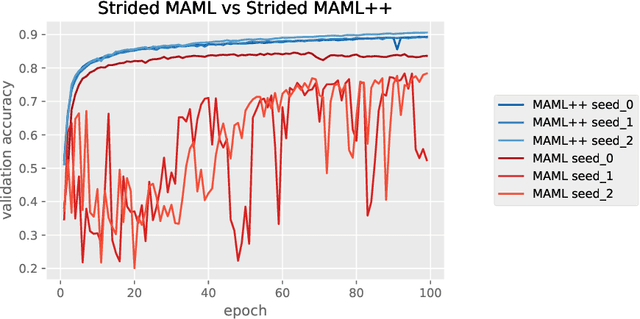
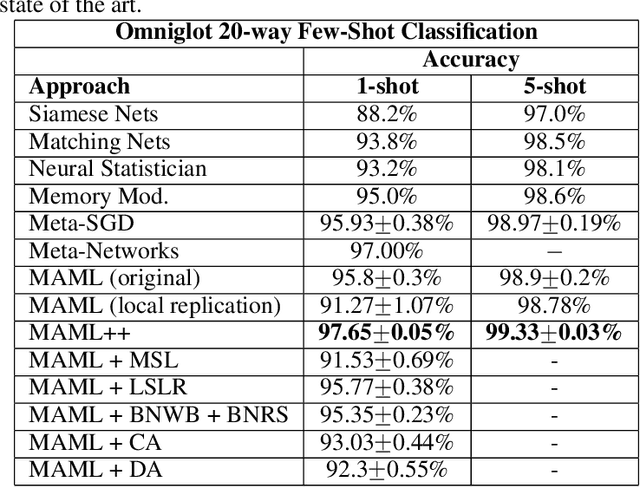

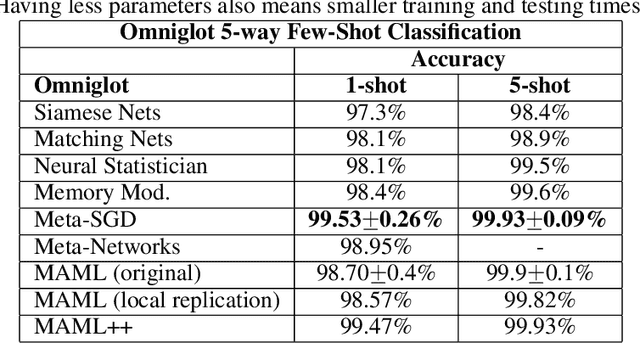
The field of few-shot learning has recently seen substantial advancements. Most of these advancements came from casting few-shot learning as a meta-learning problem. Model Agnostic Meta Learning or MAML is currently one of the best approaches for few-shot learning via meta-learning. MAML is simple, elegant and very powerful, however, it has a variety of issues, such as being very sensitive to neural network architectures, often leading to instability during training, requiring arduous hyperparameter searches to stabilize training and achieve high generalization and being very computationally expensive at both training and inference times. In this paper, we propose various modifications to MAML that not only stabilize the system, but also substantially improve the generalization performance, convergence speed and computational overhead of MAML, which we call MAML++.
Learning Policy Representations in Multiagent Systems
Jul 31, 2018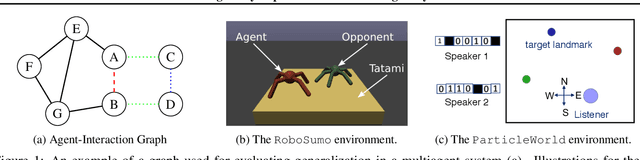
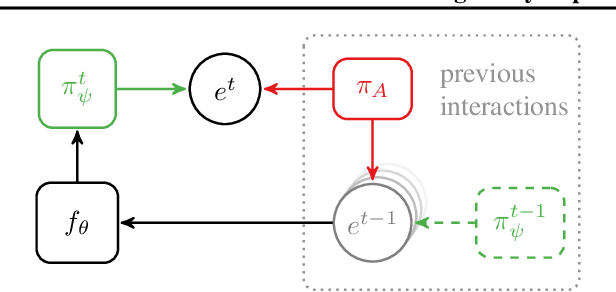
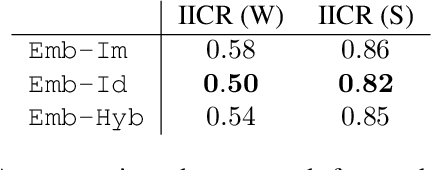
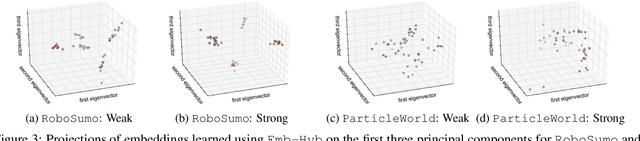
Modeling agent behavior is central to understanding the emergence of complex phenomena in multiagent systems. Prior work in agent modeling has largely been task-specific and driven by hand-engineering domain-specific prior knowledge. We propose a general learning framework for modeling agent behavior in any multiagent system using only a handful of interaction data. Our framework casts agent modeling as a representation learning problem. Consequently, we construct a novel objective inspired by imitation learning and agent identification and design an algorithm for unsupervised learning of representations of agent policies. We demonstrate empirically the utility of the proposed framework in (i) a challenging high-dimensional competitive environment for continuous control and (ii) a cooperative environment for communication, on supervised predictive tasks, unsupervised clustering, and policy optimization using deep reinforcement learning.
Variational Option Discovery Algorithms
Jul 26, 2018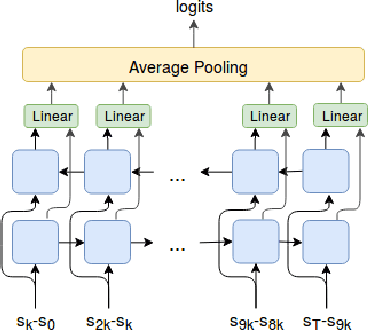
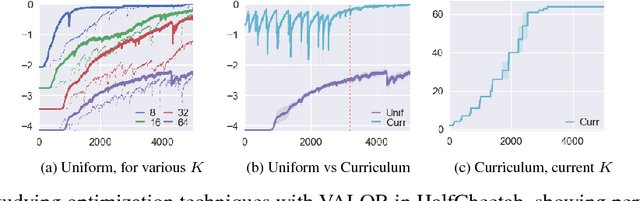
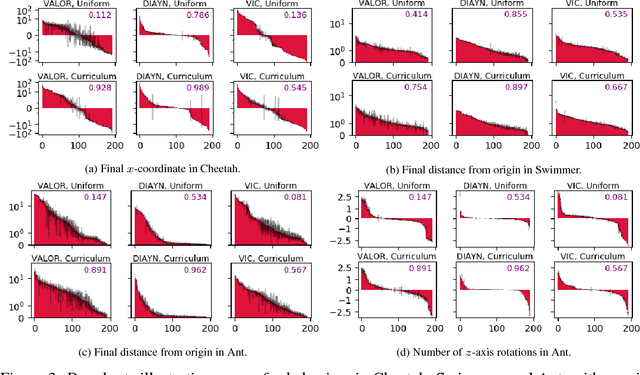
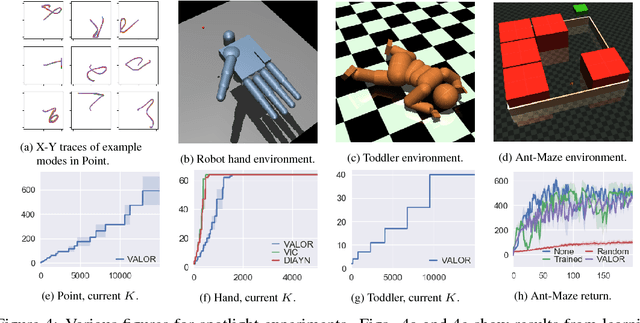
We explore methods for option discovery based on variational inference and make two algorithmic contributions. First: we highlight a tight connection between variational option discovery methods and variational autoencoders, and introduce Variational Autoencoding Learning of Options by Reinforcement (VALOR), a new method derived from the connection. In VALOR, the policy encodes contexts from a noise distribution into trajectories, and the decoder recovers the contexts from the complete trajectories. Second: we propose a curriculum learning approach where the number of contexts seen by the agent increases whenever the agent's performance is strong enough (as measured by the decoder) on the current set of contexts. We show that this simple trick stabilizes training for VALOR and prior variational option discovery methods, allowing a single agent to learn many more modes of behavior than it could with a fixed context distribution. Finally, we investigate other topics related to variational option discovery, including fundamental limitations of the general approach and the applicability of learned options to downstream tasks.
Data Augmentation Generative Adversarial Networks
Mar 21, 2018


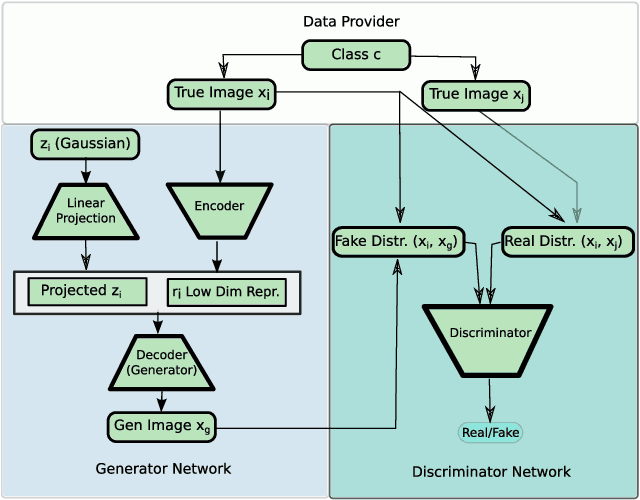
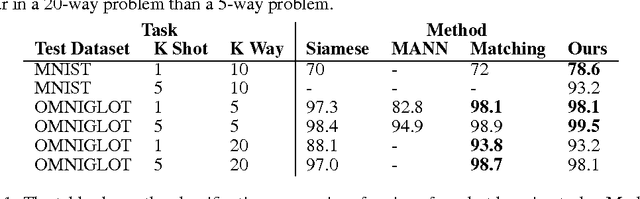
Effective training of neural networks requires much data. In the low-data regime, parameters are underdetermined, and learnt networks generalise poorly. Data Augmentation alleviates this by using existing data more effectively. However standard data augmentation produces only limited plausible alternative data. Given there is potential to generate a much broader set of augmentations, we design and train a generative model to do data augmentation. The model, based on image conditional Generative Adversarial Networks, takes data from a source domain and learns to take any data item and generalise it to generate other within-class data items. As this generative process does not depend on the classes themselves, it can be applied to novel unseen classes of data. We show that a Data Augmentation Generative Adversarial Network (DAGAN) augments standard vanilla classifiers well. We also show a DAGAN can enhance few-shot learning systems such as Matching Networks. We demonstrate these approaches on Omniglot, on EMNIST having learnt the DAGAN on Omniglot, and VGG-Face data. In our experiments we can see over 13% increase in accuracy in the low-data regime experiments in Omniglot (from 69% to 82%), EMNIST (73.9% to 76%) and VGG-Face (4.5% to 12%); in Matching Networks for Omniglot we observe an increase of 0.5% (from 96.9% to 97.4%) and an increase of 1.8% in EMNIST (from 59.5% to 61.3%).
Towards a Neural Statistician
Mar 20, 2017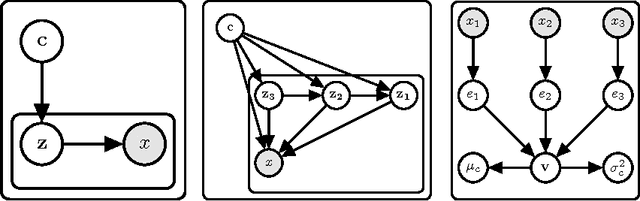
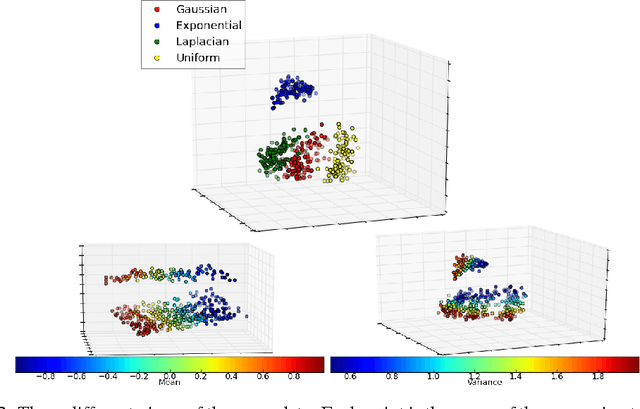

An efficient learner is one who reuses what they already know to tackle a new problem. For a machine learner, this means understanding the similarities amongst datasets. In order to do this, one must take seriously the idea of working with datasets, rather than datapoints, as the key objects to model. Towards this goal, we demonstrate an extension of a variational autoencoder that can learn a method for computing representations, or statistics, of datasets in an unsupervised fashion. The network is trained to produce statistics that encapsulate a generative model for each dataset. Hence the network enables efficient learning from new datasets for both unsupervised and supervised tasks. We show that we are able to learn statistics that can be used for: clustering datasets, transferring generative models to new datasets, selecting representative samples of datasets and classifying previously unseen classes. We refer to our model as a neural statistician, and by this we mean a neural network that can learn to compute summary statistics of datasets without supervision.
Censoring Representations with an Adversary
Mar 04, 2016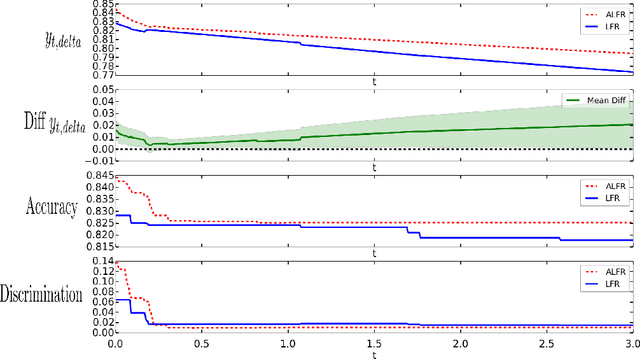
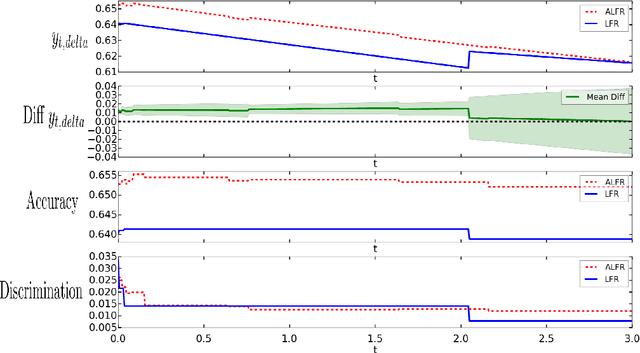
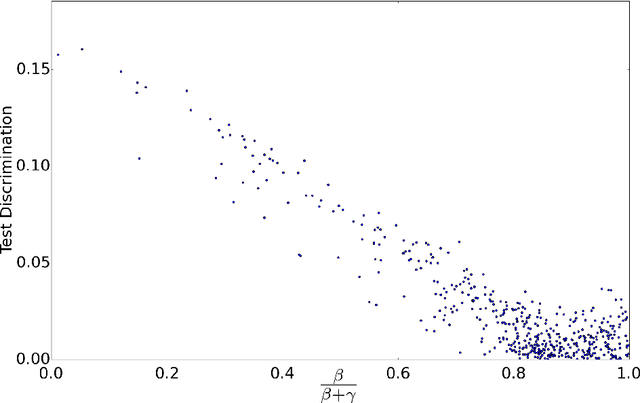

In practice, there are often explicit constraints on what representations or decisions are acceptable in an application of machine learning. For example it may be a legal requirement that a decision must not favour a particular group. Alternatively it can be that that representation of data must not have identifying information. We address these two related issues by learning flexible representations that minimize the capability of an adversarial critic. This adversary is trying to predict the relevant sensitive variable from the representation, and so minimizing the performance of the adversary ensures there is little or no information in the representation about the sensitive variable. We demonstrate this adversarial approach on two problems: making decisions free from discrimination and removing private information from images. We formulate the adversarial model as a minimax problem, and optimize that minimax objective using a stochastic gradient alternate min-max optimizer. We demonstrate the ability to provide discriminant free representations for standard test problems, and compare with previous state of the art methods for fairness, showing statistically significant improvement across most cases. The flexibility of this method is shown via a novel problem: removing annotations from images, from unaligned training examples of annotated and unannotated images, and with no a priori knowledge of the form of annotation provided to the model.