 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBP-Triplet Net for Unsupervised Domain Adaptation: A Bayesian Perspective
Feb 19, 2022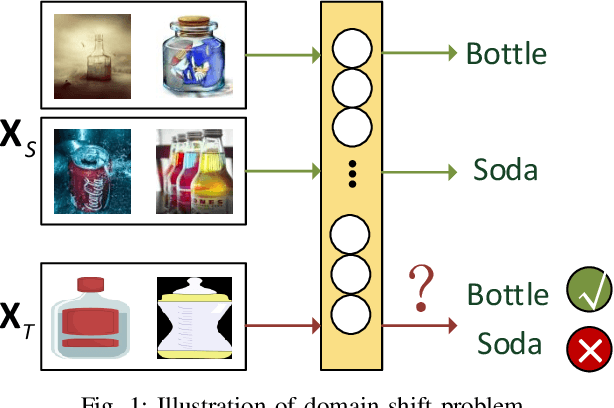
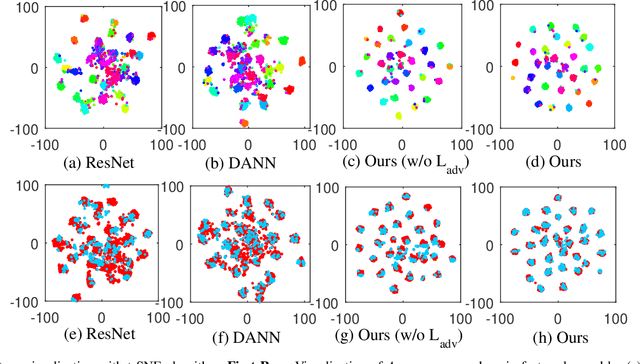
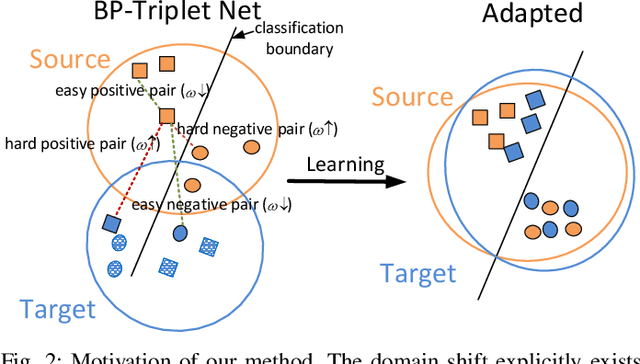
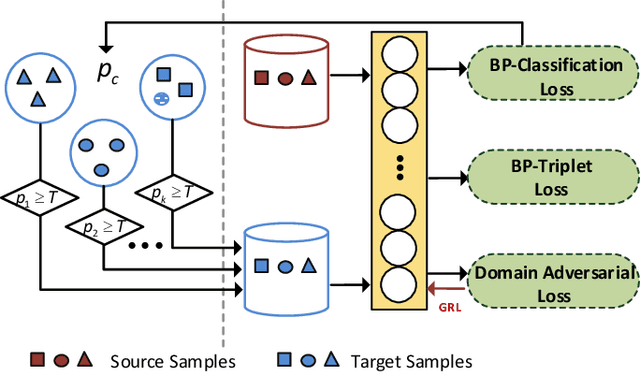
Triplet loss, one of the deep metric learning (DML) methods, is to learn the embeddings where examples from the same class are closer than examples from different classes. Motivated by DML, we propose an effective BP-Triplet Loss for unsupervised domain adaption (UDA) from the perspective of Bayesian learning and we name the model as BP-Triplet Net. In previous metric learning based methods for UDA, sample pairs across domains are treated equally, which is not appropriate due to the domain bias. In our work, considering the different importance of pair-wise samples for both feature learning and domain alignment, we deduce our BP-Triplet loss for effective UDA from the perspective of Bayesian learning. Our BP-Triplet loss adjusts the weights of pair-wise samples in intra domain and inter domain. Especially, it can self attend to the hard pairs (including hard positive pair and hard negative pair). Together with the commonly used adversarial loss for domain alignment, the quality of target pseudo labels is progressively improved. Our method achieved low joint error of the ideal source and target hypothesis. The expected target error can then be upper bounded following Ben-David s theorem. Comprehensive evaluations on five benchmark datasets, handwritten digits, Office31, ImageCLEF-DA, Office-Home and VisDA-2017 demonstrate the effectiveness of the proposed approach for UDA.
Image-to-Video Re-Identification via Mutual Discriminative Knowledge Transfer
Jan 21, 2022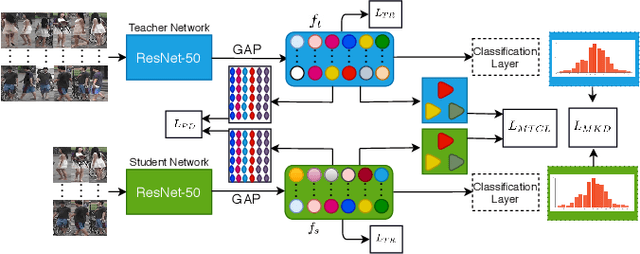
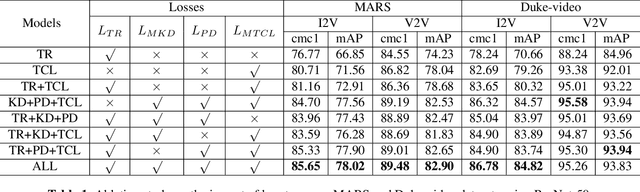
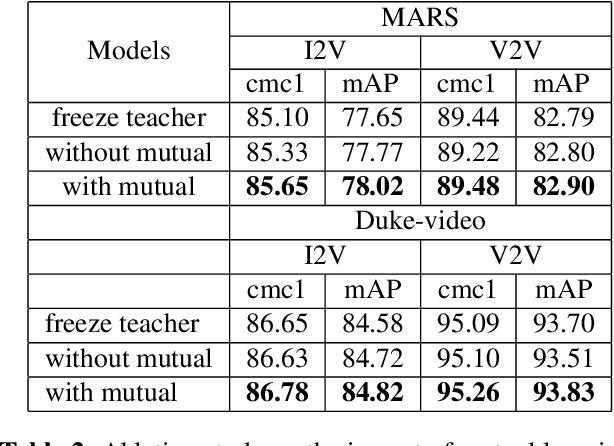
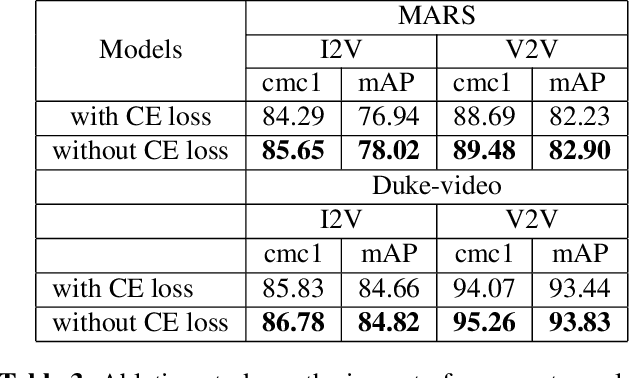
The gap in representations between image and video makes Image-to-Video Re-identification (I2V Re-ID) challenging, and recent works formulate this problem as a knowledge distillation (KD) process. In this paper, we propose a mutual discriminative knowledge distillation framework to transfer a video-based richer representation to an image based representation more effectively. Specifically, we propose the triplet contrast loss (TCL), a novel loss designed for KD. During the KD process, the TCL loss transfers the local structure, exploits the higher order information, and mitigates the misalignment of the heterogeneous output of teacher and student networks. Compared with other losses for KD, the proposed TCL loss selectively transfers the local discriminative features from teacher to student, making it effective in the ReID. Besides the TCL loss, we adopt mutual learning to regularize both the teacher and student networks training. Extensive experiments demonstrate the effectiveness of our method on the MARS, DukeMTMC-VideoReID and VeRi-776 benchmarks.
ELSA: Enhanced Local Self-Attention for Vision Transformer
Dec 23, 2021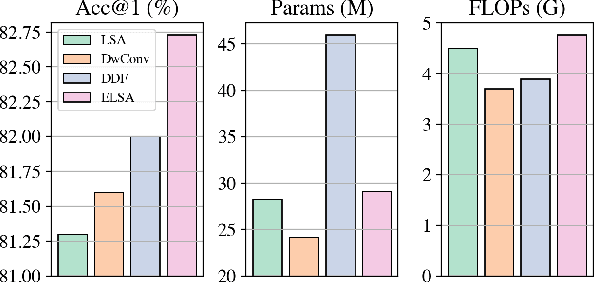
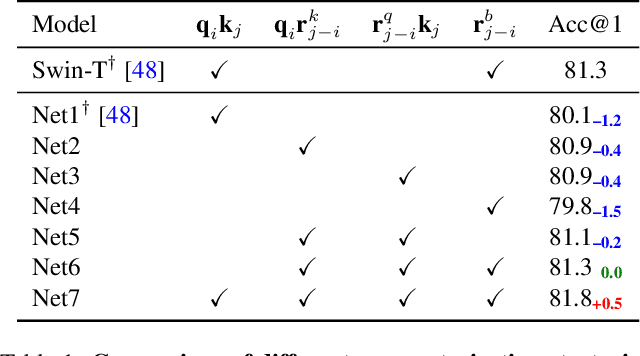
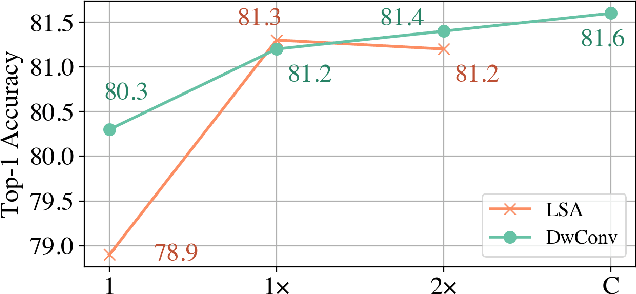

Self-attention is powerful in modeling long-range dependencies, but it is weak in local finer-level feature learning. The performance of local self-attention (LSA) is just on par with convolution and inferior to dynamic filters, which puzzles researchers on whether to use LSA or its counterparts, which one is better, and what makes LSA mediocre. To clarify these, we comprehensively investigate LSA and its counterparts from two sides: \emph{channel setting} and \emph{spatial processing}. We find that the devil lies in the generation and application of spatial attention, where relative position embeddings and the neighboring filter application are key factors. Based on these findings, we propose the enhanced local self-attention (ELSA) with Hadamard attention and the ghost head. Hadamard attention introduces the Hadamard product to efficiently generate attention in the neighboring case, while maintaining the high-order mapping. The ghost head combines attention maps with static matrices to increase channel capacity. Experiments demonstrate the effectiveness of ELSA. Without architecture / hyperparameter modification, drop-in replacing LSA with ELSA boosts Swin Transformer \cite{swin} by up to +1.4 on top-1 accuracy. ELSA also consistently benefits VOLO \cite{volo} from D1 to D5, where ELSA-VOLO-D5 achieves 87.2 on the ImageNet-1K without extra training images. In addition, we evaluate ELSA in downstream tasks. ELSA significantly improves the baseline by up to +1.9 box Ap / +1.3 mask Ap on the COCO, and by up to +1.9 mIoU on the ADE20K. Code is available at \url{https://github.com/damo-cv/ELSA}.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Dec 16, 2021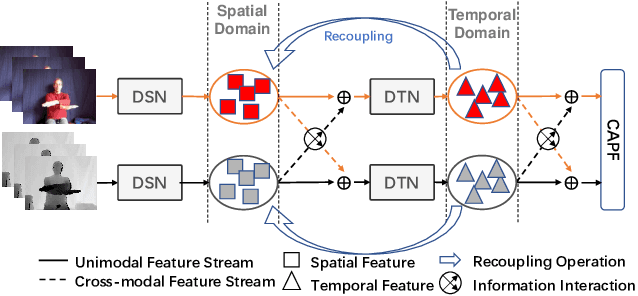
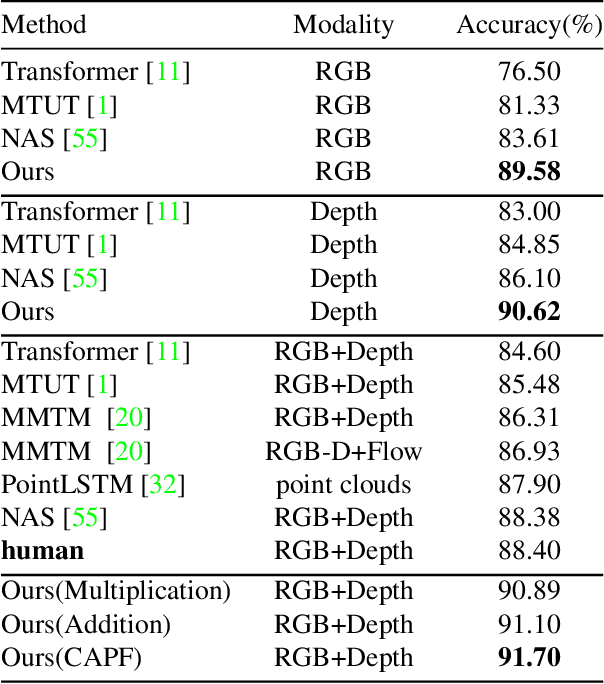
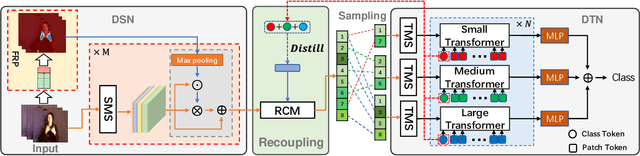
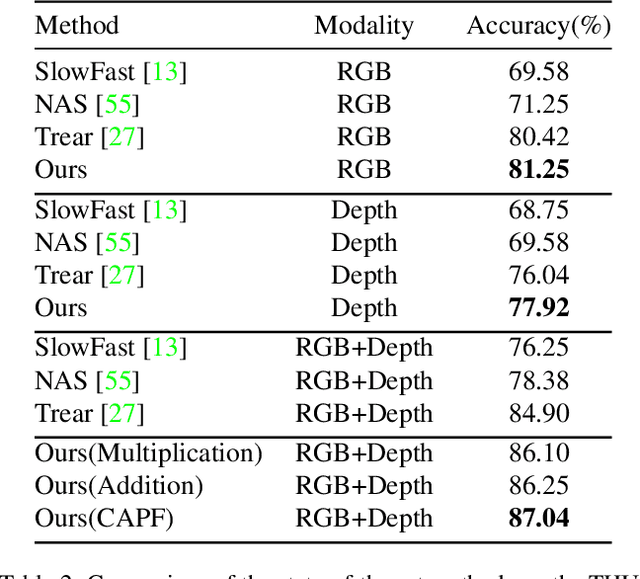
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors. Although previous RGB-D-based motion recognition methods have achieved promising performance through the tightly coupled multi-modal spatiotemporal representation, they still suffer from (i) optimization difficulty under small data setting due to the tightly spatiotemporal-entangled modeling;(ii) information redundancy as it usually contains lots of marginal information that is weakly relevant to classification; and (iii) low interaction between multi-modal spatiotemporal information caused by insufficient late fusion. To alleviate these drawbacks, we propose to decouple and recouple spatiotemporal representation for RGB-D-based motion recognition. Specifically, we disentangle the task of learning spatiotemporal representation into 3 sub-tasks: (1) Learning high-quality and dimension independent features through a decoupled spatial and temporal modeling network. (2) Recoupling the decoupled representation to establish stronger space-time dependency. (3) Introducing a Cross-modal Adaptive Posterior Fusion (CAPF) mechanism to capture cross-modal spatiotemporal information from RGB-D data. Seamless combination of these novel designs forms a robust spatialtemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Our code is available at https://github.com/damo-cv/MotionRGBD.
TransFGU: A Top-down Approach to Fine-Grained Unsupervised Semantic Segmentation
Dec 02, 2021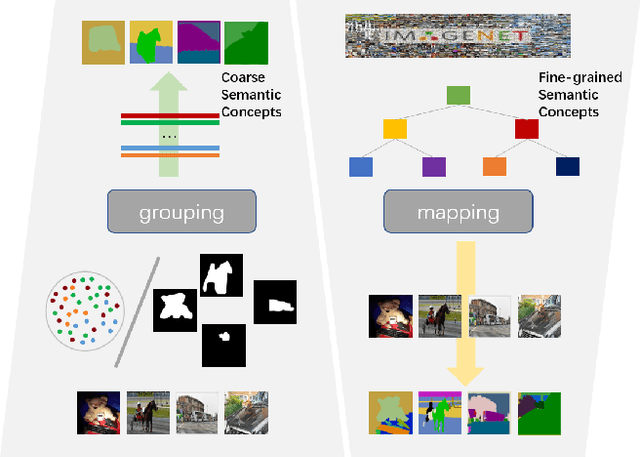
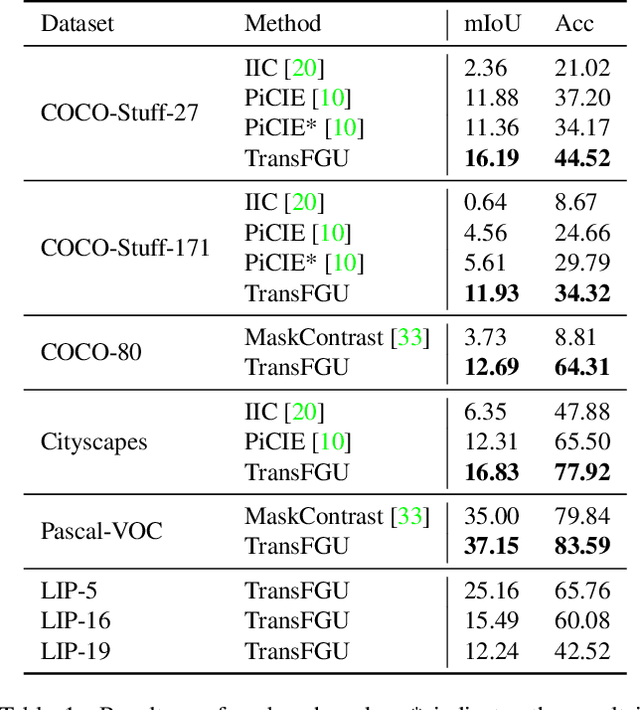
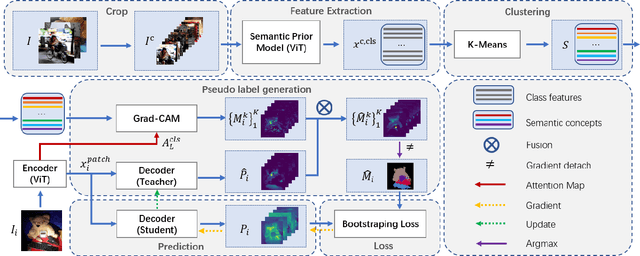
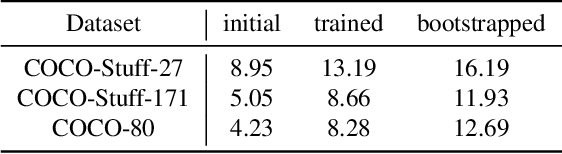
Unsupervised semantic segmentation aims to obtain high-level semantic representation on low-level visual features without manual annotations. Most existing methods are bottom-up approaches that try to group pixels into regions based on their visual cues or certain predefined rules. As a result, it is difficult for these bottom-up approaches to generate fine-grained semantic segmentation when coming to complicated scenes with multiple objects and some objects sharing similar visual appearance. In contrast, we propose the first top-down unsupervised semantic segmentation framework for fine-grained segmentation in extremely complicated scenarios. Specifically, we first obtain rich high-level structured semantic concept information from large-scale vision data in a self-supervised learning manner, and use such information as a prior to discover potential semantic categories presented in target datasets. Secondly, the discovered high-level semantic categories are mapped to low-level pixel features by calculating the class activate map (CAM) with respect to certain discovered semantic representation. Lastly, the obtained CAMs serve as pseudo labels to train the segmentation module and produce final semantic segmentation. Experimental results on multiple semantic segmentation benchmarks show that our top-down unsupervised segmentation is robust to both object-centric and scene-centric datasets under different semantic granularity levels, and outperforms all the current state-of-the-art bottom-up methods. Our code is available at \url{https://github.com/damo-cv/TransFGU}.
MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation
Nov 24, 2021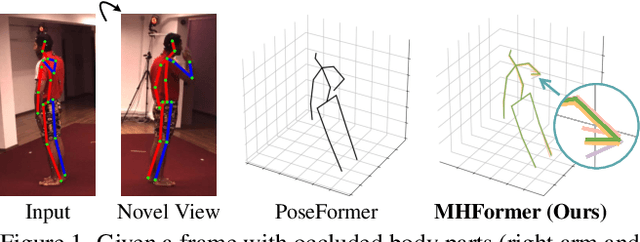
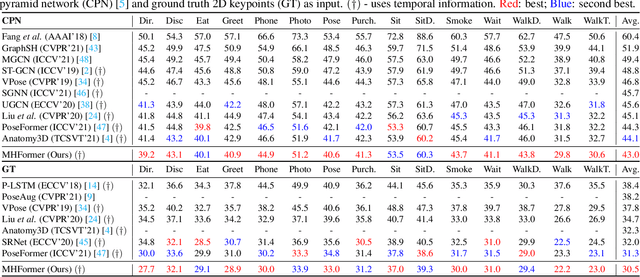
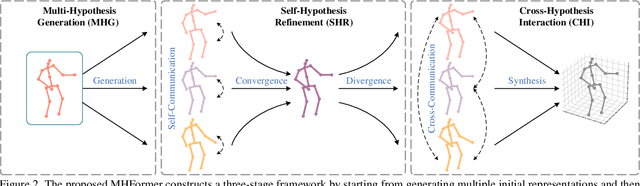

Estimating 3D human poses from monocular videos is a challenging task due to depth ambiguity and self-occlusion. Most existing works attempt to solve both issues by exploiting spatial and temporal relationships. However, those works ignore the fact that it is an inverse problem where multiple feasible solutions (i.e., hypotheses) exist. To relieve this limitation, we propose a Multi-Hypothesis Transformer (MHFormer) that learns spatio-temporal representations of multiple plausible pose hypotheses. In order to effectively model multi-hypothesis dependencies and build strong relationships across hypothesis features, the task is decomposed into three stages: (i) Generate multiple initial hypothesis representations; (ii) Model self-hypothesis communication, merge multiple hypotheses into a single converged representation and then partition it into several diverged hypotheses; (iii) Learn cross-hypothesis communication and aggregate the multi-hypothesis features to synthesize the final 3D pose. Through the above processes, the final representation is enhanced and the synthesized pose is much more accurate. Extensive experiments show that MHFormer achieves state-of-the-art results on two challenging datasets: Human3.6M and MPI-INF-3DHP. Without bells and whistles, its performance surpasses the previous best result by a large margin of 3% on Human3.6M. Code and models are available at https://github.com/Vegetebird/MHFormer.
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Nov 23, 2021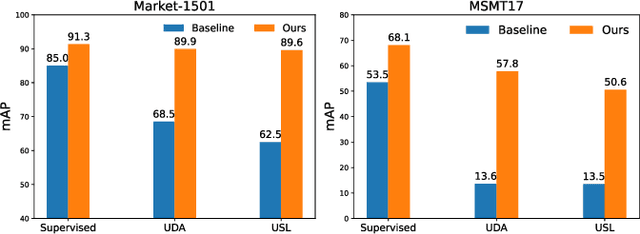
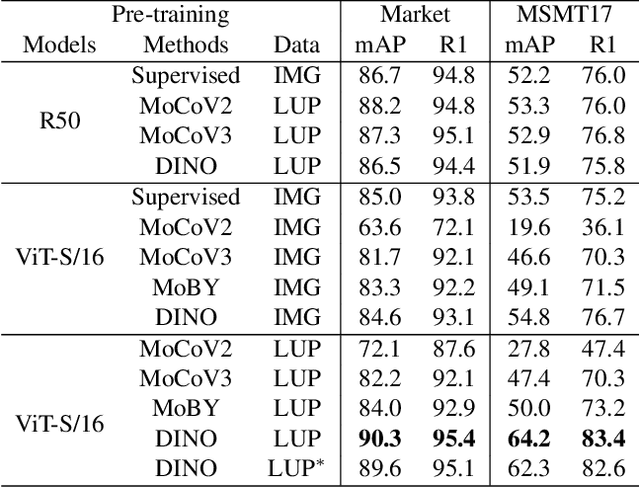
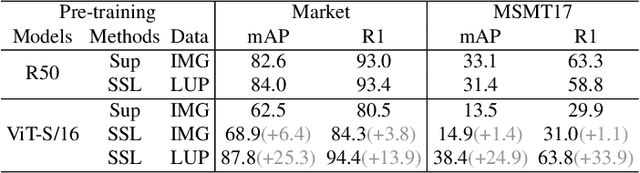
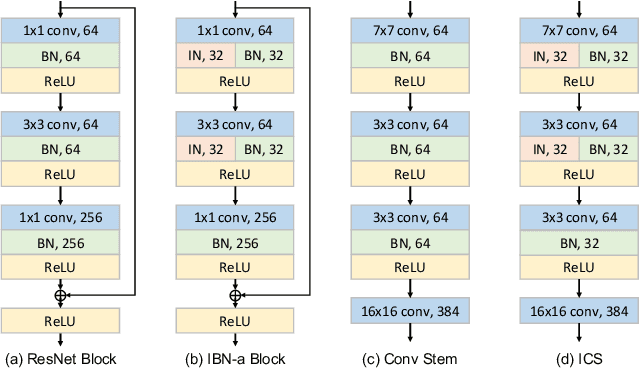
Transformer-based supervised pre-training achieves great performance in person re-identification (ReID). However, due to the domain gap between ImageNet and ReID datasets, it usually needs a larger pre-training dataset (e.g. ImageNet-21K) to boost the performance because of the strong data fitting ability of the transformer. To address this challenge, this work targets to mitigate the gap between the pre-training and ReID datasets from the perspective of data and model structure, respectively. We first investigate self-supervised learning (SSL) methods with Vision Transformer (ViT) pretrained on unlabelled person images (the LUPerson dataset), and empirically find it significantly surpasses ImageNet supervised pre-training models on ReID tasks. To further reduce the domain gap and accelerate the pre-training, the Catastrophic Forgetting Score (CFS) is proposed to evaluate the gap between pre-training and fine-tuning data. Based on CFS, a subset is selected via sampling relevant data close to the down-stream ReID data and filtering irrelevant data from the pre-training dataset. For the model structure, a ReID-specific module named IBN-based convolution stem (ICS) is proposed to bridge the domain gap by learning more invariant features. Extensive experiments have been conducted to fine-tune the pre-training models under supervised learning, unsupervised domain adaptation (UDA), and unsupervised learning (USL) settings. We successfully downscale the LUPerson dataset to 50% with no performance degradation. Finally, we achieve state-of-the-art performance on Market-1501 and MSMT17. For example, our ViT-S/16 achieves 91.3%/89.9%/89.6% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Codes and models will be released to https://github.com/michuanhaohao/TransReID-SSL.
CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
Sep 13, 2021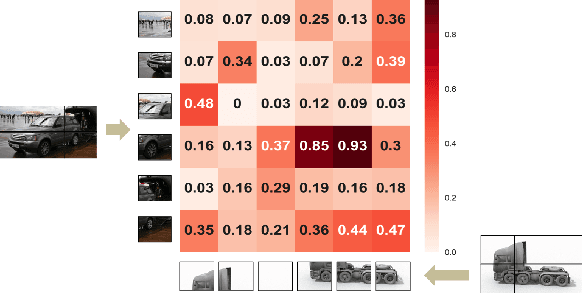
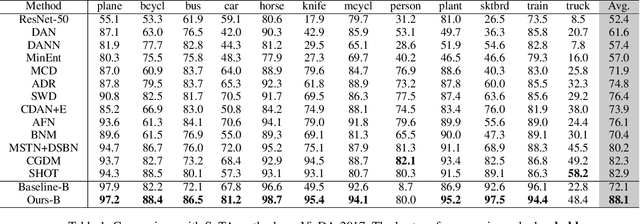
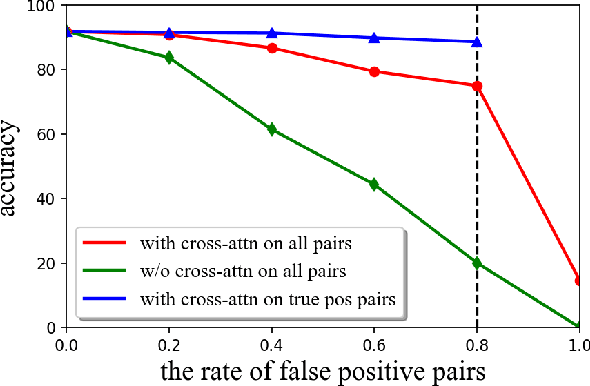
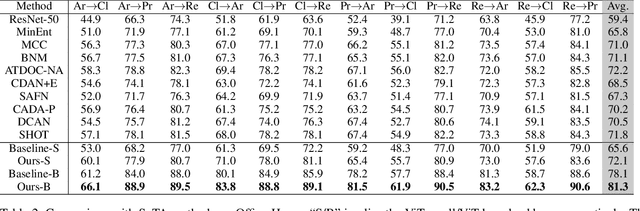
Unsupervised domain adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to a different unlabeled target domain. Most existing UDA methods focus on learning domain-invariant feature representation, either from the domain level or category level, using convolution neural networks (CNNs)-based frameworks. One fundamental problem for the category level based UDA is the production of pseudo labels for samples in target domain, which are usually too noisy for accurate domain alignment, inevitably compromising the UDA performance. With the success of Transformer in various tasks, we find that the cross-attention in Transformer is robust to the noisy input pairs for better feature alignment, thus in this paper Transformer is adopted for the challenging UDA task. Specifically, to generate accurate input pairs, we design a two-way center-aware labeling algorithm to produce pseudo labels for target samples. Along with the pseudo labels, a weight-sharing triple-branch transformer framework is proposed to apply self-attention and cross-attention for source/target feature learning and source-target domain alignment, respectively. Such design explicitly enforces the framework to learn discriminative domain-specific and domain-invariant representations simultaneously. The proposed method is dubbed CDTrans (cross-domain transformer), and it provides one of the first attempts to solve UDA tasks with a pure transformer solution. Extensive experiments show that our proposed method achieves the best performance on Office-Home, VisDA-2017, and DomainNet datasets.
Scaled ReLU Matters for Training Vision Transformers
Sep 08, 2021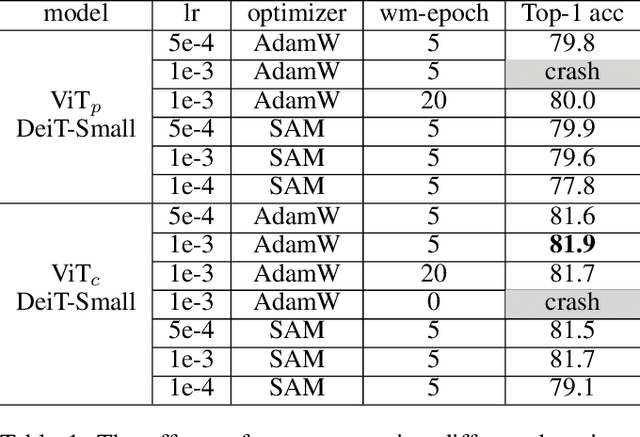
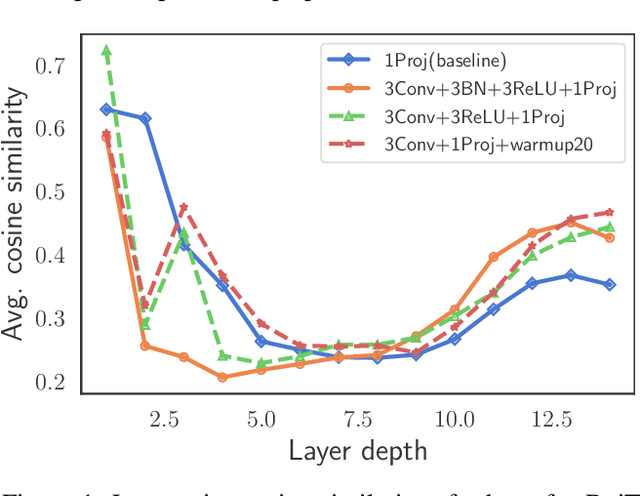
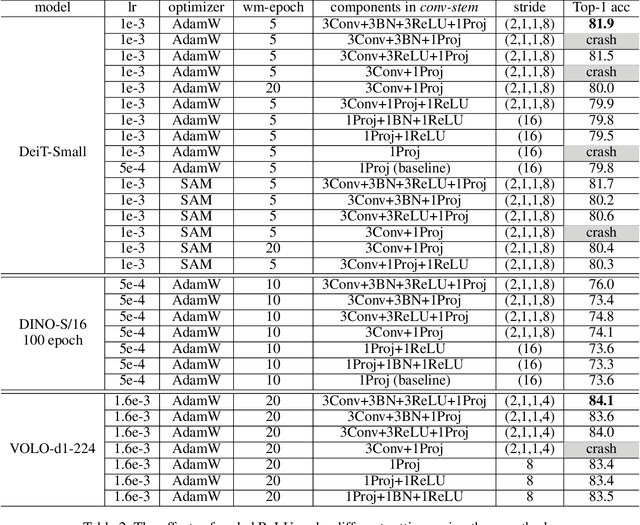
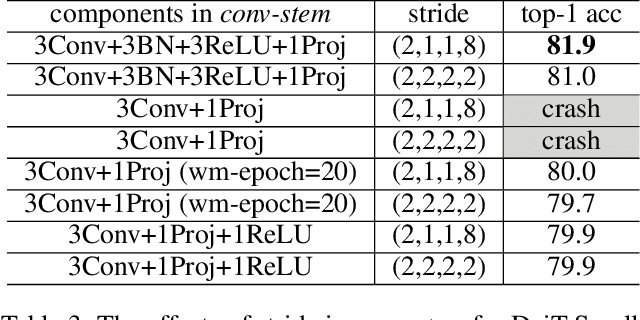
Vision transformers (ViTs) have been an alternative design paradigm to convolutional neural networks (CNNs). However, the training of ViTs is much harder than CNNs, as it is sensitive to the training parameters, such as learning rate, optimizer and warmup epoch. The reasons for training difficulty are empirically analysed in ~\cite{xiao2021early}, and the authors conjecture that the issue lies with the \textit{patchify-stem} of ViT models and propose that early convolutions help transformers see better. In this paper, we further investigate this problem and extend the above conclusion: only early convolutions do not help for stable training, but the scaled ReLU operation in the \textit{convolutional stem} (\textit{conv-stem}) matters. We verify, both theoretically and empirically, that scaled ReLU in \textit{conv-stem} not only improves training stabilization, but also increases the diversity of patch tokens, thus boosting peak performance with a large margin via adding few parameters and flops. In addition, extensive experiments are conducted to demonstrate that previous ViTs are far from being well trained, further showing that ViTs have great potential to be a better substitute of CNNs.
KVT: k-NN Attention for Boosting Vision Transformers
May 28, 2021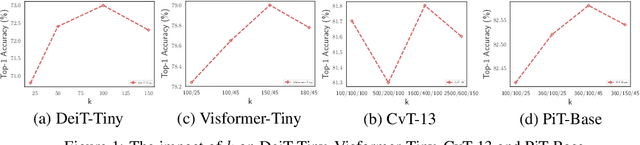
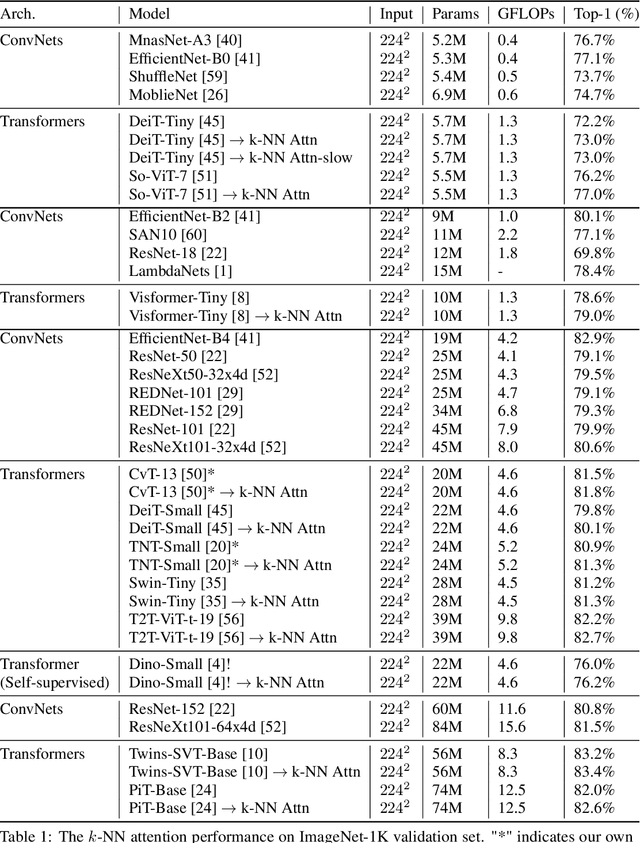
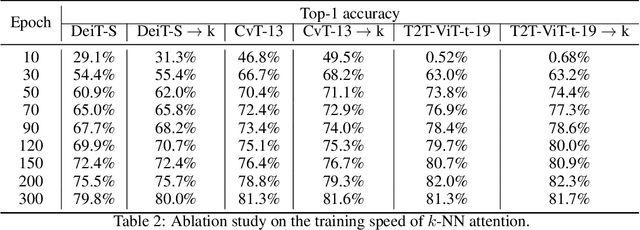
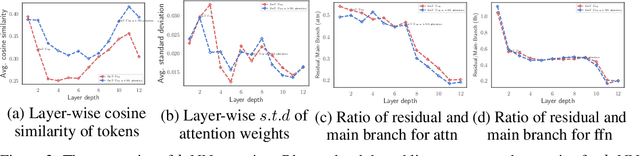
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.