 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking-based Group Identification via Factorized Attention on Social Tripartite Graph
Nov 16, 2022Due to the proliferation of social media, a growing number of users search for and join group activities in their daily life. This develops a need for the study on the ranking-based group identification (RGI) task, i.e., recommending groups to users. The major challenge in this task is how to effectively and efficiently leverage both the item interaction and group participation of users' online behaviors. Though recent developments of Graph Neural Networks (GNNs) succeed in simultaneously aggregating both social and user-item interaction, they however fail to comprehensively resolve this RGI task. In this paper, we propose a novel GNN-based framework named Contextualized Factorized Attention for Group identification (CFAG). We devise tripartite graph convolution layers to aggregate information from different types of neighborhoods among users, groups, and items. To cope with the data sparsity issue, we devise a novel propagation augmentation (PA) layer, which is based on our proposed factorized attention mechanism. PA layers efficiently learn the relatedness of non-neighbor nodes to improve the information propagation to users. Experimental results on three benchmark datasets verify the superiority of CFAG. Additional detailed investigations are conducted to demonstrate the effectiveness of the proposed framework.
Gradient Imitation Reinforcement Learning for General Low-Resource Information Extraction
Nov 14, 2022



Information Extraction (IE) aims to extract structured information from heterogeneous sources. IE from natural language texts include sub-tasks such as Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE). Most IE systems require comprehensive understandings of sentence structure, implied semantics, and domain knowledge to perform well; thus, IE tasks always need adequate external resources and annotations. However, it takes time and effort to obtain more human annotations. Low-Resource Information Extraction (LRIE) strives to use unsupervised data, reducing the required resources and human annotation. In practice, existing systems either utilize self-training schemes to generate pseudo labels that will cause the gradual drift problem, or leverage consistency regularization methods which inevitably possess confirmation bias. To alleviate confirmation bias due to the lack of feedback loops in existing LRIE learning paradigms, we develop a Gradient Imitation Reinforcement Learning (GIRL) method to encourage pseudo-labeled data to imitate the gradient descent direction on labeled data, which can force pseudo-labeled data to achieve better optimization capabilities similar to labeled data. Based on how well the pseudo-labeled data imitates the instructive gradient descent direction obtained from labeled data, we design a reward to quantify the imitation process and bootstrap the optimization capability of pseudo-labeled data through trial and error. In addition to learning paradigms, GIRL is not limited to specific sub-tasks, and we leverage GIRL to solve all IE sub-tasks (named entity recognition, relation extraction, and event extraction) in low-resource settings (semi-supervised IE and few-shot IE).
MetaKRec: Collaborative Meta-Knowledge Enhanced Recommender System
Nov 14, 2022Knowledge graph (KG) enhanced recommendation has demonstrated improved performance in the recommendation system (RecSys) and attracted considerable research interest. Recently the literature has adopted neural graph networks (GNNs) on the collaborative knowledge graph and built an end-to-end KG-enhanced RecSys. However, the majority of these approaches have three limitations: (1) treat the collaborative knowledge graph as a homogeneous graph and overlook the highly heterogeneous relationships among items, (2) lack of design to explicitly leverage the rich side information, and (3) overlook the rich knowledge in user preference. To fill this gap, in this paper, we explore the rich, heterogeneous relationship among items and propose a new KG-enhanced recommendation model called Collaborative Meta-Knowledge Enhanced Recommender System (MetaKRec). In particular, we focus on modeling the rich, heterogeneous semantic relationships among items and construct several collaborative Meta-KGs to explicitly depict the relatedness of the items under the guidance of meta-knowledge. In addition to the knowledge obtained from KG, we leverage user knowledge that extracts from user preference to construct the Meta-KGs. The constructed Meta-KGs can capture the knowledge from both the knowledge graph and user preference. Furthermore. we utilize a light convolution encoder to recursively integrate the item relationship in each collaborative Meta-KGs. This scheme allows us to explicitly gather the heterogeneous semantic relationships among items and encode them into the representations of items. In addition, we propose channel attention to fuse the item and user representations from different Meta-KGs. Extensive experiments are conducted on four real-world benchmark datasets, demonstrating significant gains over the state-of-the-art baselines on both regular and cold-start recommendation settings.
Can Current Explainability Help Provide References in Clinical Notes to Support Humans Annotate Medical Codes?
Oct 28, 2022


The medical codes prediction problem from clinical notes has received substantial interest in the NLP community, and several recent studies have shown the state-of-the-art (SOTA) code prediction results of full-fledged deep learning-based methods. However, most previous SOTA works based on deep learning are still in early stages in terms of providing textual references and explanations of the predicted codes, despite the fact that this level of explainability of the prediction outcomes is critical to gaining trust from professional medical coders. This raises the important question of how well current explainability methods apply to advanced neural network models such as transformers to predict correct codes and present references in clinical notes that support code prediction. First, we present an explainable Read, Attend, and Code (xRAC) framework and assess two approaches, attention score-based xRAC-ATTN and model-agnostic knowledge-distillation-based xRAC-KD, through simplified but thorough human-grounded evaluations with SOTA transformer-based model, RAC. We find that the supporting evidence text highlighted by xRAC-ATTN is of higher quality than xRAC-KD whereas xRAC-KD has potential advantages in production deployment scenarios. More importantly, we show for the first time that, given the current state of explainability methodologies, using the SOTA medical codes prediction system still requires the expertise and competencies of professional coders, even though its prediction accuracy is superior to that of human coders. This, we believe, is a very meaningful step toward developing explainable and accurate machine learning systems for fully autonomous medical code prediction from clinical notes.
Sequential Recommendation with Auxiliary Item Relationships via Multi-Relational Transformer
Oct 28, 2022Sequential Recommendation (SR) models user dynamics and predicts the next preferred items based on the user history. Existing SR methods model the 'was interacted before' item-item transitions observed in sequences, which can be viewed as an item relationship. However, there are multiple auxiliary item relationships, e.g., items from similar brands and with similar contents in real-world scenarios. Auxiliary item relationships describe item-item affinities in multiple different semantics and alleviate the long-lasting cold start problem in the recommendation. However, it remains a significant challenge to model auxiliary item relationships in SR. To simultaneously model high-order item-item transitions in sequences and auxiliary item relationships, we propose a Multi-relational Transformer capable of modeling auxiliary item relationships for SR (MT4SR). Specifically, we propose a novel self-attention module, which incorporates arbitrary item relationships and weights item relationships accordingly. Second, we regularize intra-sequence item relationships with a novel regularization module to supervise attentions computations. Third, for inter-sequence item relationship pairs, we introduce a novel inter-sequence related items modeling module. Finally, we conduct experiments on four benchmark datasets and demonstrate the effectiveness of MT4SR over state-of-the-art methods and the improvements on the cold start problem. The code is available at https://github.com/zfan20/MT4SR.
EnTDA: Entity-to-Text based Data Augmentation Approach for Named Entity Recognition Tasks
Oct 19, 2022
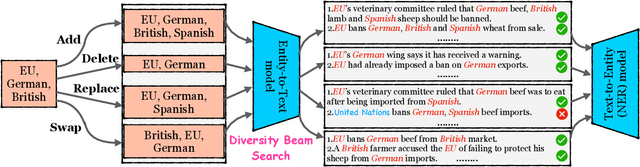
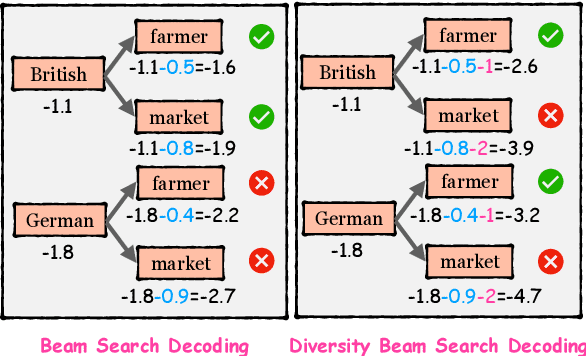
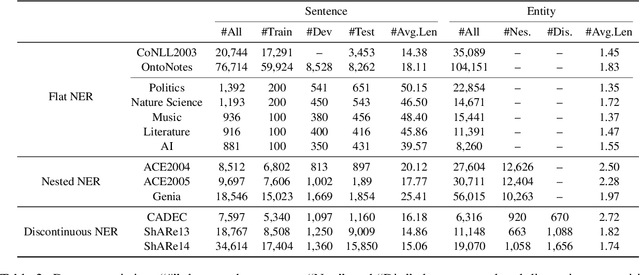
Data augmentation techniques have been used to improve the generalization capability of models in the named entity recognition (NER) tasks. Existing augmentation methods either manipulate the words in the original text that require hand-crafted in-domain knowledge, or leverage generative models which solicit dependency order among entities. To alleviate the excessive reliance on the dependency order among entities in existing augmentation paradigms, we develop an entity-to-text instead of text-to-entity based data augmentation method named: EnTDA to decouple the dependencies between entities by adding, deleting, replacing and swapping entities, and adopt these augmented data to bootstrap the generalization ability of the NER model. Furthermore, we introduce a diversity beam search to increase the diversity of the augmented data. Experiments on thirteen NER datasets across three tasks (flat NER, nested NER, and discontinuous NER) and two settings (full data NER and low resource NER) show that EnTDA could consistently outperform the baselines.
Deep Clustering: A Comprehensive Survey
Oct 09, 2022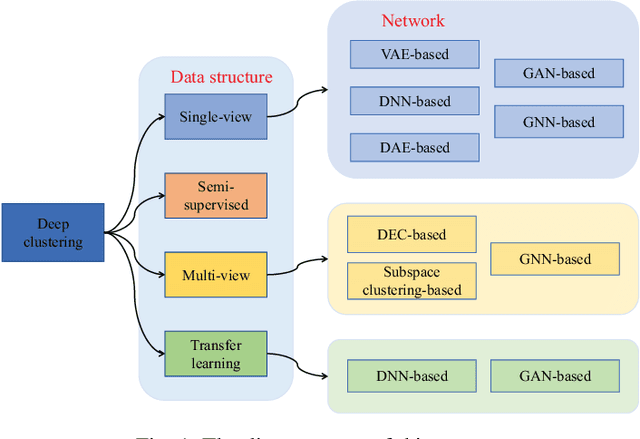
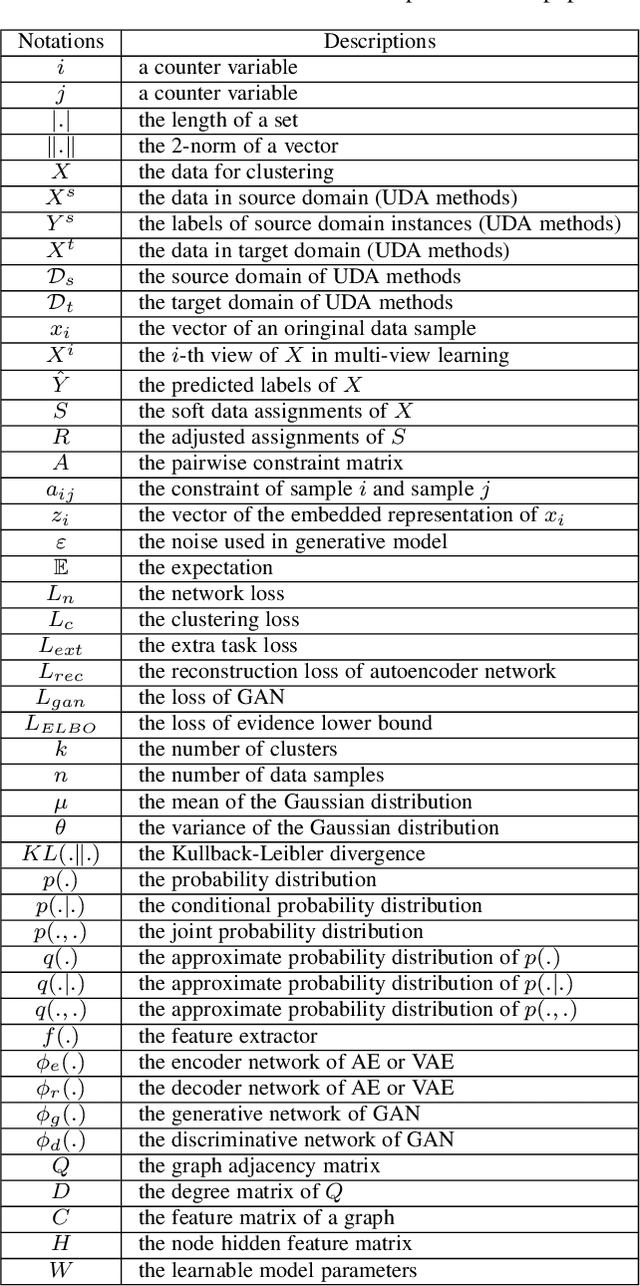
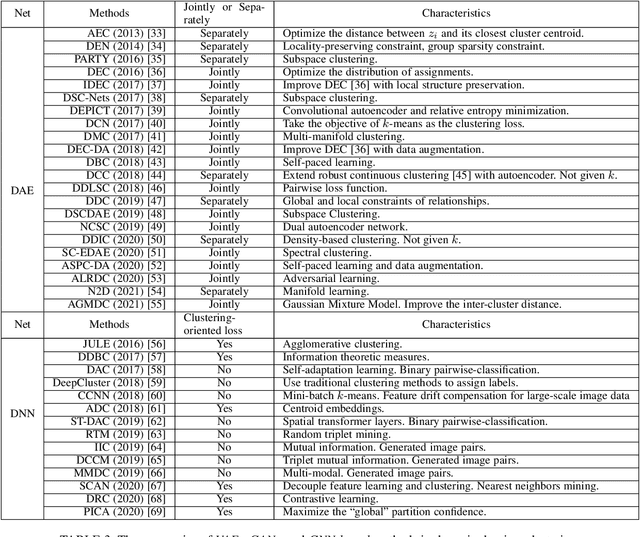
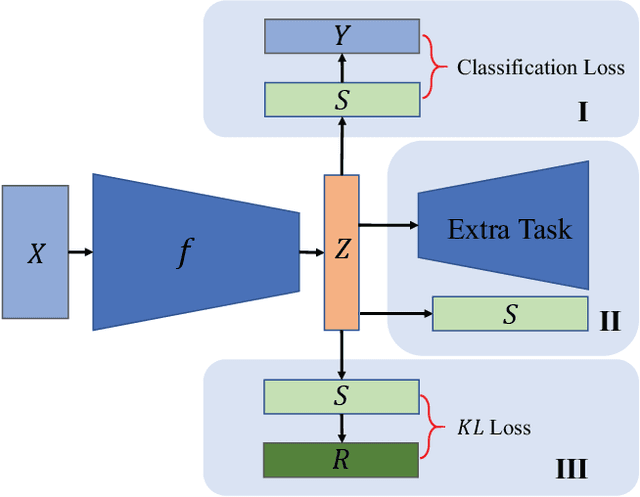
Cluster analysis plays an indispensable role in machine learning and data mining. Learning a good data representation is crucial for clustering algorithms. Recently, deep clustering, which can learn clustering-friendly representations using deep neural networks, has been broadly applied in a wide range of clustering tasks. Existing surveys for deep clustering mainly focus on the single-view fields and the network architectures, ignoring the complex application scenarios of clustering. To address this issue, in this paper we provide a comprehensive survey for deep clustering in views of data sources. With different data sources and initial conditions, we systematically distinguish the clustering methods in terms of methodology, prior knowledge, and architecture. Concretely, deep clustering methods are introduced according to four categories, i.e., traditional single-view deep clustering, semi-supervised deep clustering, deep multi-view clustering, and deep transfer clustering. Finally, we discuss the open challenges and potential future opportunities in different fields of deep clustering.
Contrast Pattern Mining: A Survey
Sep 27, 2022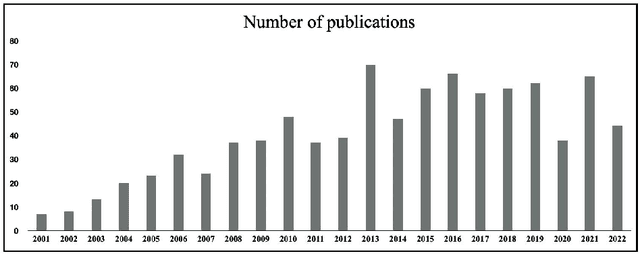
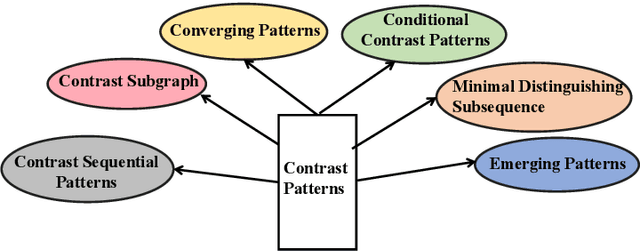
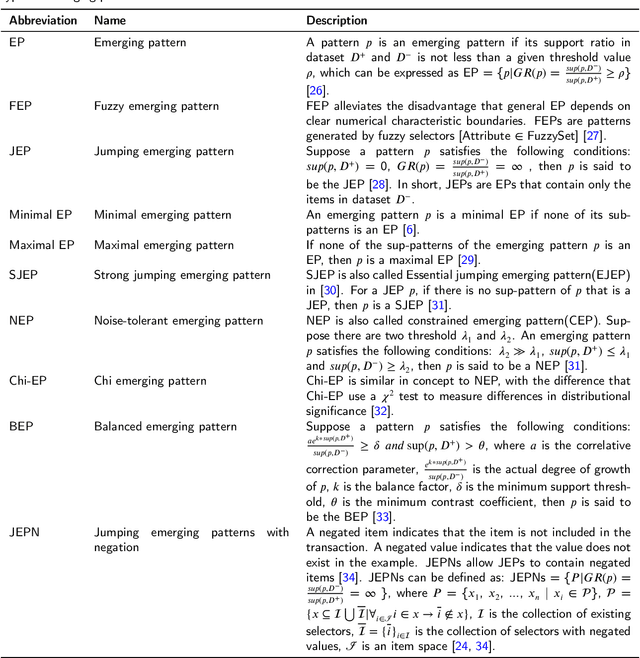
Contrast pattern mining (CPM) is an important and popular subfield of data mining. Traditional sequential patterns cannot describe the contrast information between different classes of data, while contrast patterns involving the concept of contrast can describe the significant differences between datasets under different contrast conditions. Based on the number of papers published in this field, we find that researchers' interest in CPM is still active. Since CPM has many research questions and research methods. It is difficult for new researchers in the field to understand the general situation of the field in a short period of time. Therefore, the purpose of this article is to provide an up-to-date comprehensive and structured overview of the research direction of contrast pattern mining. First, we present an in-depth understanding of CPM, including basic concepts, types, mining strategies, and metrics for assessing discriminative ability. Then we classify CPM methods according to their characteristics into boundary-based algorithms, tree-based algorithms, evolutionary fuzzy system-based algorithms, decision tree-based algorithms, and other algorithms. In addition, we list the classical algorithms of these methods and discuss their advantages and disadvantages. Advanced topics in CPM are presented. Finally, we conclude our survey with a discussion of the challenges and opportunities in this field.
Totally-ordered Sequential Rules for Utility Maximization
Sep 27, 2022
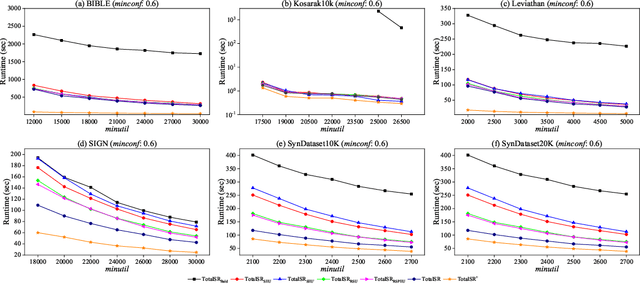

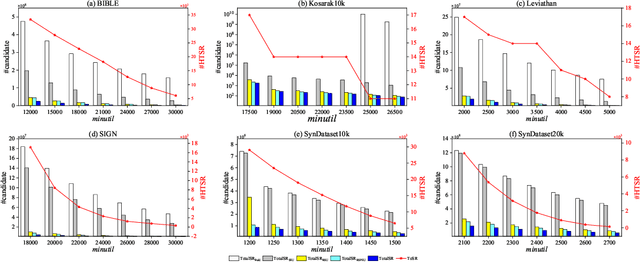
High utility sequential pattern mining (HUSPM) is a significant and valuable activity in knowledge discovery and data analytics with many real-world applications. In some cases, HUSPM can not provide an excellent measure to predict what will happen. High utility sequential rule mining (HUSRM) discovers high utility and high confidence sequential rules, allowing it to solve the problem in HUSPM. All existing HUSRM algorithms aim to find high-utility partially-ordered sequential rules (HUSRs), which are not consistent with reality and may generate fake HUSRs. Therefore, in this paper, we formulate the problem of high utility totally-ordered sequential rule mining and propose two novel algorithms, called TotalSR and TotalSR+, which aim to identify all high utility totally-ordered sequential rules (HTSRs). TotalSR creates a utility table that can efficiently calculate antecedent support and a utility prefix sum list that can compute the remaining utility in O(1) time for a sequence. We also introduce a left-first expansion strategy that can utilize the anti-monotonic property to use a confidence pruning strategy. TotalSR can also drastically reduce the search space with the help of utility upper bounds pruning strategies, avoiding much more meaningless computation. In addition, TotalSR+ uses an auxiliary antecedent record table to more efficiently discover HTSRs. Finally, there are numerous experimental results on both real and synthetic datasets demonstrating that TotalSR is significantly more efficient than algorithms with fewer pruning strategies, and TotalSR+ is significantly more efficient than TotalSR in terms of running time and scalability.
Scene Graph Modification as Incremental Structure Expanding
Sep 15, 2022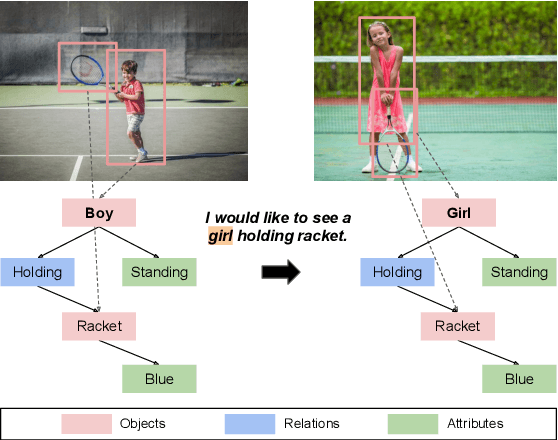
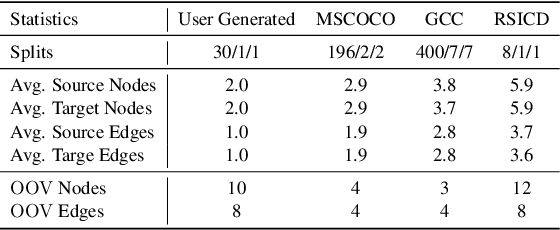
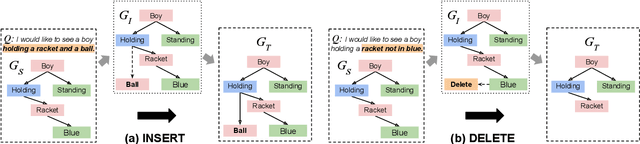
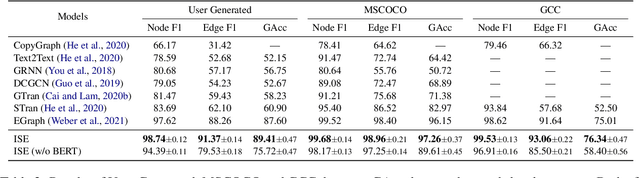
A scene graph is a semantic representation that expresses the objects, attributes, and relationships between objects in a scene. Scene graphs play an important role in many cross modality tasks, as they are able to capture the interactions between images and texts. In this paper, we focus on scene graph modification (SGM), where the system is required to learn how to update an existing scene graph based on a natural language query. Unlike previous approaches that rebuilt the entire scene graph, we frame SGM as a graph expansion task by introducing the incremental structure expanding (ISE). ISE constructs the target graph by incrementally expanding the source graph without changing the unmodified structure. Based on ISE, we further propose a model that iterates between nodes prediction and edges prediction, inferring more accurate and harmonious expansion decisions progressively. In addition, we construct a challenging dataset that contains more complicated queries and larger scene graphs than existing datasets. Experiments on four benchmarks demonstrate the effectiveness of our approach, which surpasses the previous state-of-the-art model by large margins.