 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Utility-driven Interval Rules
Sep 28, 2023



For artificial intelligence, high-utility sequential rule mining (HUSRM) is a knowledge discovery method that can reveal the associations between events in the sequences. Recently, abundant methods have been proposed to discover high-utility sequence rules. However, the existing methods are all related to point-based sequences. Interval events that persist for some time are common. Traditional interval-event sequence knowledge discovery tasks mainly focus on pattern discovery, but patterns cannot reveal the correlation between interval events well. Moreover, the existing HUSRM algorithms cannot be directly applied to interval-event sequences since the relation in interval-event sequences is much more intricate than those in point-based sequences. In this work, we propose a utility-driven interval rule mining (UIRMiner) algorithm that can extract all utility-driven interval rules (UIRs) from the interval-event sequence database to solve the problem. In UIRMiner, we first introduce a numeric encoding relation representation, which can save much time on relation computation and storage on relation representation. Furthermore, to shrink the search space, we also propose a complement pruning strategy, which incorporates the utility upper bound with the relation. Finally, plentiful experiments implemented on both real-world and synthetic datasets verify that UIRMiner is an effective and efficient algorithm.
Totally-ordered Sequential Rules for Utility Maximization
Sep 27, 2022
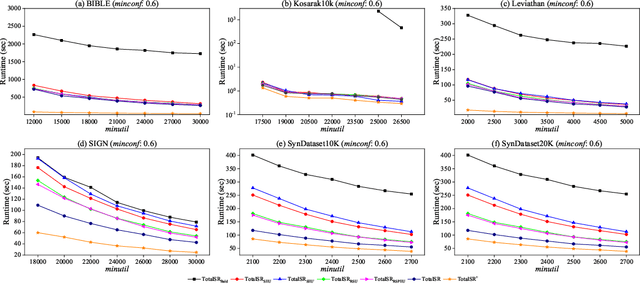

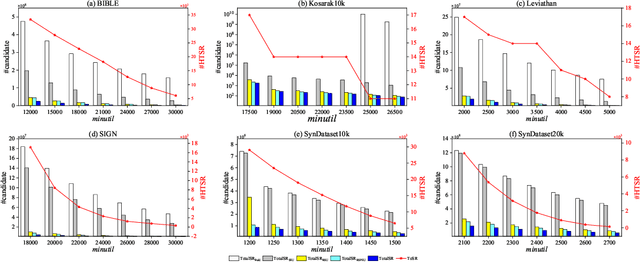
High utility sequential pattern mining (HUSPM) is a significant and valuable activity in knowledge discovery and data analytics with many real-world applications. In some cases, HUSPM can not provide an excellent measure to predict what will happen. High utility sequential rule mining (HUSRM) discovers high utility and high confidence sequential rules, allowing it to solve the problem in HUSPM. All existing HUSRM algorithms aim to find high-utility partially-ordered sequential rules (HUSRs), which are not consistent with reality and may generate fake HUSRs. Therefore, in this paper, we formulate the problem of high utility totally-ordered sequential rule mining and propose two novel algorithms, called TotalSR and TotalSR+, which aim to identify all high utility totally-ordered sequential rules (HTSRs). TotalSR creates a utility table that can efficiently calculate antecedent support and a utility prefix sum list that can compute the remaining utility in O(1) time for a sequence. We also introduce a left-first expansion strategy that can utilize the anti-monotonic property to use a confidence pruning strategy. TotalSR can also drastically reduce the search space with the help of utility upper bounds pruning strategies, avoiding much more meaningless computation. In addition, TotalSR+ uses an auxiliary antecedent record table to more efficiently discover HTSRs. Finally, there are numerous experimental results on both real and synthetic datasets demonstrating that TotalSR is significantly more efficient than algorithms with fewer pruning strategies, and TotalSR+ is significantly more efficient than TotalSR in terms of running time and scalability.