 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradingAttack: Attacking Large Language Models Towards Short Answer Grading Ability
Feb 01, 2026Large language models (LLMs) have demonstrated remarkable potential for automatic short answer grading (ASAG), significantly boosting student assessment efficiency and scalability in educational scenarios. However, their vulnerability to adversarial manipulation raises critical concerns about automatic grading fairness and reliability. In this paper, we introduce GradingAttack, a fine-grained adversarial attack framework that systematically evaluates the vulnerability of LLM based ASAG models. Specifically, we align general-purpose attack methods with the specific objectives of ASAG by designing token-level and prompt-level strategies that manipulate grading outcomes while maintaining high camouflage. Furthermore, to quantify attack camouflage, we propose a novel evaluation metric that balances attack success and camouflage. Experiments on multiple datasets demonstrate that both attack strategies effectively mislead grading models, with prompt-level attacks achieving higher success rates and token-level attacks exhibiting superior camouflage capability. Our findings underscore the need for robust defenses to ensure fairness and reliability in ASAG. Our code and datasets are available at https://anonymous.4open.science/r/GradingAttack.
GI-SMN: Gradient Inversion Attack against Federated Learning without Prior Knowledge
May 06, 2024



Federated learning (FL) has emerged as a privacy-preserving machine learning approach where multiple parties share gradient information rather than original user data. Recent work has demonstrated that gradient inversion attacks can exploit the gradients of FL to recreate the original user data, posing significant privacy risks. However, these attacks make strong assumptions about the attacker, such as altering the model structure or parameters, gaining batch normalization statistics, or acquiring prior knowledge of the original training set, etc. Consequently, these attacks are not possible in real-world scenarios. To end it, we propose a novel Gradient Inversion attack based on Style Migration Network (GI-SMN), which breaks through the strong assumptions made by previous gradient inversion attacks. The optimization space is reduced by the refinement of the latent code and the use of regular terms to facilitate gradient matching. GI-SMN enables the reconstruction of user data with high similarity in batches. Experimental results have demonstrated that GI-SMN outperforms state-of-the-art gradient inversion attacks in both visual effect and similarity metrics. Additionally, it also can overcome gradient pruning and differential privacy defenses.
Distributional Black-Box Model Inversion Attack with Multi-Agent Reinforcement Learning
Apr 22, 2024A Model Inversion (MI) attack based on Generative Adversarial Networks (GAN) aims to recover the private training data from complex deep learning models by searching codes in the latent space. However, they merely search a deterministic latent space such that the found latent code is usually suboptimal. In addition, the existing distributional MI schemes assume that an attacker can access the structures and parameters of the target model, which is not always viable in practice. To overcome the above shortcomings, this paper proposes a novel Distributional Black-Box Model Inversion (DBB-MI) attack by constructing the probabilistic latent space for searching the target privacy data. Specifically, DBB-MI does not need the target model parameters or specialized GAN training. Instead, it finds the latent probability distribution by combining the output of the target model with multi-agent reinforcement learning techniques. Then, it randomly chooses latent codes from the latent probability distribution for recovering the private data. As the latent probability distribution closely aligns with the target privacy data in latent space, the recovered data will leak the privacy of training samples of the target model significantly. Abundant experiments conducted on diverse datasets and networks show that the present DBB-MI has better performance than state-of-the-art in attack accuracy, K-nearest neighbor feature distance, and Peak Signal-to-Noise Ratio.
Federated Learning for Metaverse: A Survey
Mar 23, 2023The metaverse, which is at the stage of innovation and exploration, faces the dilemma of data collection and the problem of private data leakage in the process of development. This can seriously hinder the widespread deployment of the metaverse. Fortunately, federated learning (FL) is a solution to the above problems. FL is a distributed machine learning paradigm with privacy-preserving features designed for a large number of edge devices. Federated learning for metaverse (FL4M) will be a powerful tool. Because FL allows edge devices to participate in training tasks locally using their own data, computational power, and model-building capabilities. Applying FL to the metaverse not only protects the data privacy of participants but also reduces the need for high computing power and high memory on servers. Until now, there have been many studies about FL and the metaverse, respectively. In this paper, we review some of the early advances of FL4M, which will be a research direction with unlimited development potential. We first introduce the concepts of metaverse and FL, respectively. Besides, we discuss the convergence of key metaverse technologies and FL in detail, such as big data, communication technology, the Internet of Things, edge computing, blockchain, and extended reality. Finally, we discuss some key challenges and promising directions of FL4M in detail. In summary, we hope that our up-to-date brief survey can help people better understand FL4M and build a fair, open, and secure metaverse.
Federated Learning Attacks and Defenses: A Survey
Nov 27, 2022



In terms of artificial intelligence, there are several security and privacy deficiencies in the traditional centralized training methods of machine learning models by a server. To address this limitation, federated learning (FL) has been proposed and is known for breaking down ``data silos" and protecting the privacy of users. However, FL has not yet gained popularity in the industry, mainly due to its security, privacy, and high cost of communication. For the purpose of advancing the research in this field, building a robust FL system, and realizing the wide application of FL, this paper sorts out the possible attacks and corresponding defenses of the current FL system systematically. Firstly, this paper briefly introduces the basic workflow of FL and related knowledge of attacks and defenses. It reviews a great deal of research about privacy theft and malicious attacks that have been studied in recent years. Most importantly, in view of the current three classification criteria, namely the three stages of machine learning, the three different roles in federated learning, and the CIA (Confidentiality, Integrity, and Availability) guidelines on privacy protection, we divide attack approaches into two categories according to the training stage and the prediction stage in machine learning. Furthermore, we also identify the CIA property violated for each attack method and potential attack role. Various defense mechanisms are then analyzed separately from the level of privacy and security. Finally, we summarize the possible challenges in the application of FL from the aspect of attacks and defenses and discuss the future development direction of FL systems. In this way, the designed FL system has the ability to resist different attacks and is more secure and stable.
Contrast Pattern Mining: A Survey
Sep 27, 2022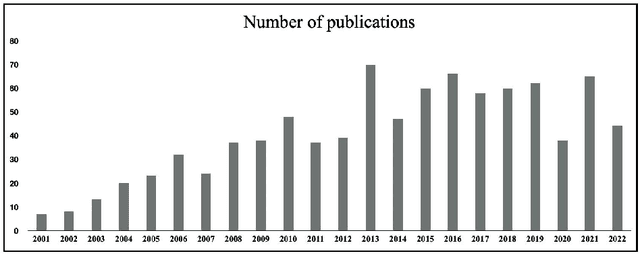
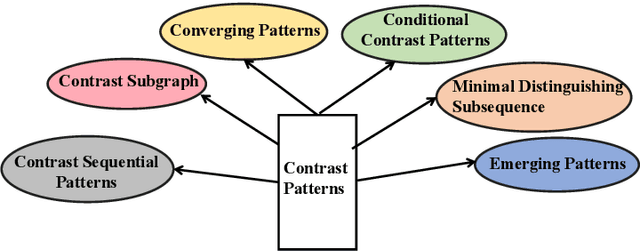
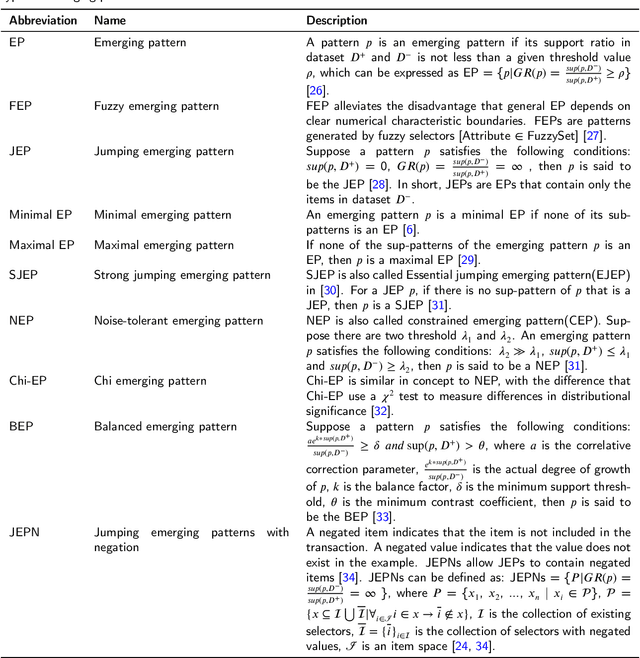
Contrast pattern mining (CPM) is an important and popular subfield of data mining. Traditional sequential patterns cannot describe the contrast information between different classes of data, while contrast patterns involving the concept of contrast can describe the significant differences between datasets under different contrast conditions. Based on the number of papers published in this field, we find that researchers' interest in CPM is still active. Since CPM has many research questions and research methods. It is difficult for new researchers in the field to understand the general situation of the field in a short period of time. Therefore, the purpose of this article is to provide an up-to-date comprehensive and structured overview of the research direction of contrast pattern mining. First, we present an in-depth understanding of CPM, including basic concepts, types, mining strategies, and metrics for assessing discriminative ability. Then we classify CPM methods according to their characteristics into boundary-based algorithms, tree-based algorithms, evolutionary fuzzy system-based algorithms, decision tree-based algorithms, and other algorithms. In addition, we list the classical algorithms of these methods and discuss their advantages and disadvantages. Advanced topics in CPM are presented. Finally, we conclude our survey with a discussion of the challenges and opportunities in this field.
Towards Target High-Utility Itemsets
Jun 09, 2022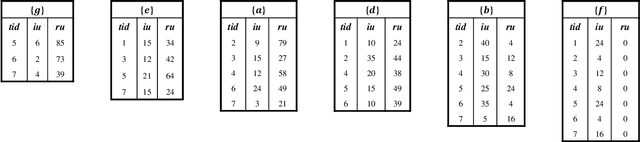

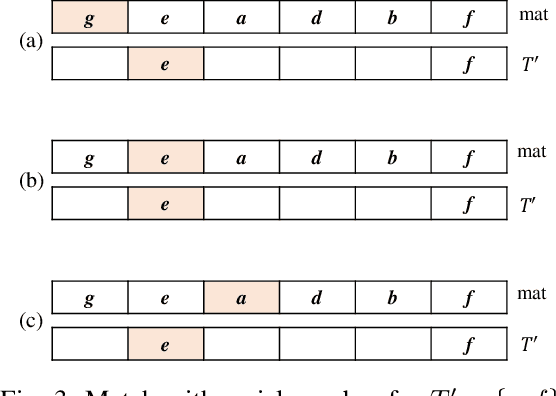
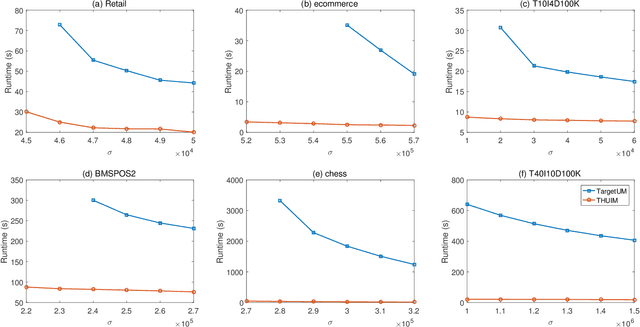
For applied intelligence, utility-driven pattern discovery algorithms can identify insightful and useful patterns in databases. However, in these techniques for pattern discovery, the number of patterns can be huge, and the user is often only interested in a few of those patterns. Hence, targeted high-utility itemset mining has emerged as a key research topic, where the aim is to find a subset of patterns that meet a targeted pattern constraint instead of all patterns. This is a challenging task because efficiently finding tailored patterns in a very large search space requires a targeted mining algorithm. A first algorithm called TargetUM has been proposed, which adopts an approach similar to post-processing using a tree structure, but the running time and memory consumption are unsatisfactory in many situations. In this paper, we address this issue by proposing a novel list-based algorithm with pattern matching mechanism, named THUIM (Targeted High-Utility Itemset Mining), which can quickly match high-utility itemsets during the mining process to select the targeted patterns. Extensive experiments were conducted on different datasets to compare the performance of the proposed algorithm with state-of-the-art algorithms. Results show that THUIM performs very well in terms of runtime and memory consumption, and has good scalability compared to TargetUM.
Smart System: Joint Utility and Frequency for Pattern Classification
Jun 09, 2022


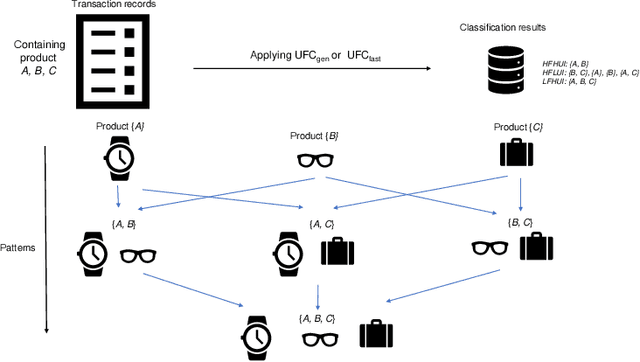
Nowadays, the environments of smart systems for Industry 4.0 and Internet of Things (IoT) are experiencing fast industrial upgrading. Big data technologies such as design making, event detection, and classification are developed to help manufacturing organizations to achieve smart systems. By applying data analysis, the potential values of rich data can be maximized and thus help manufacturing organizations to finish another round of upgrading. In this paper, we propose two new algorithms with respect to big data analysis, namely UFC$_{gen}$ and UFC$_{fast}$. Both algorithms are designed to collect three types of patterns to help people determine the market positions for different product combinations. We compare these algorithms on various types of datasets, both real and synthetic. The experimental results show that both algorithms can successfully achieve pattern classification by utilizing three different types of interesting patterns from all candidate patterns based on user-specified thresholds of utility and frequency. Furthermore, the list-based UFC$_{fast}$ algorithm outperforms the level-wise-based UFC$_{gen}$ algorithm in terms of both execution time and memory consumption.