 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal Human Action Localisation and Instance Segmentation in Temporally Untrimmed Videos
Aug 06, 2017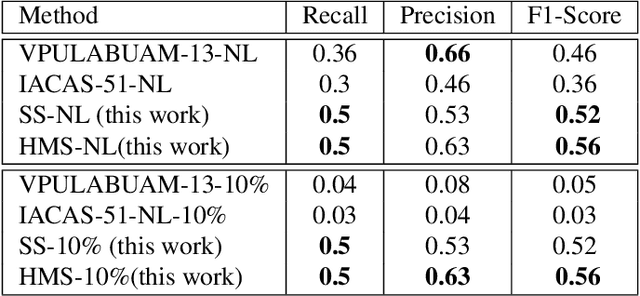


Current state-of-the-art human action recognition is focused on the classification of temporally trimmed videos in which only one action occurs per frame. In this work we address the problem of action localisation and instance segmentation in which multiple concurrent actions of the same class may be segmented out of an image sequence. We cast the action tube extraction as an energy maximisation problem in which configurations of region proposals in each frame are assigned a cost and the best action tubes are selected via two passes of dynamic programming. One pass associates region proposals in space and time for each action category, and another pass is used to solve for the tube's temporal extent and to enforce a smooth label sequence through the video. In addition, by taking advantage of recent work on action foreground-background segmentation, we are able to associate each tube with class-specific segmentations. We demonstrate the performance of our algorithm on the challenging LIRIS-HARL dataset and achieve a new state-of-the-art result which is 14.3 times better than previous methods.
Discovering Class-Specific Pixels for Weakly-Supervised Semantic Segmentation
Jul 18, 2017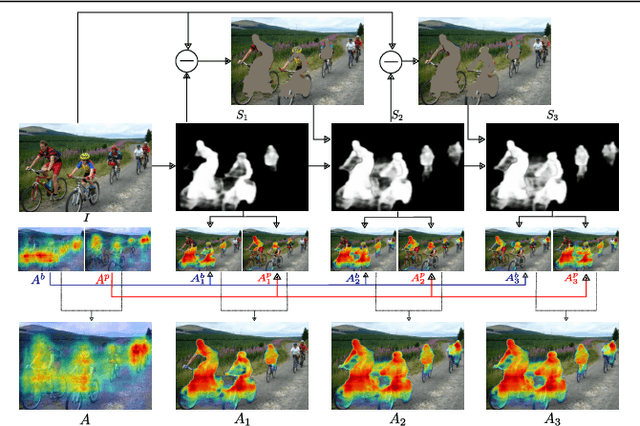
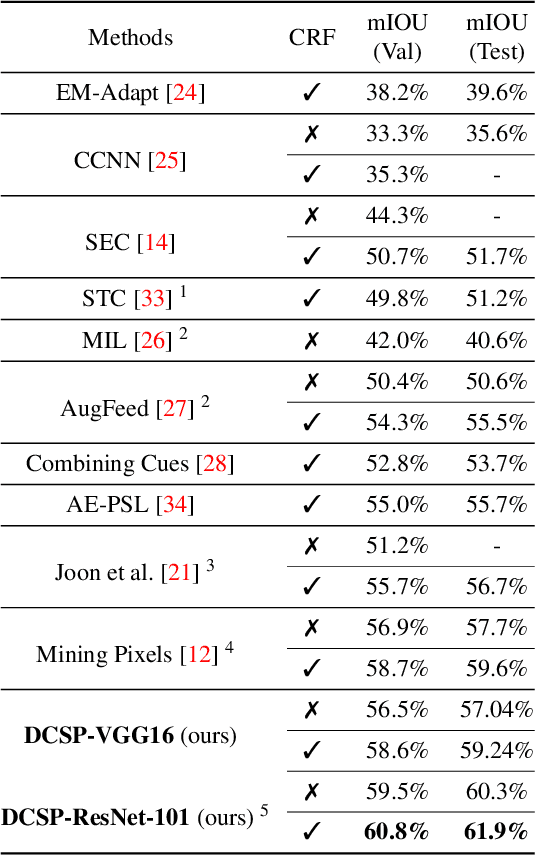
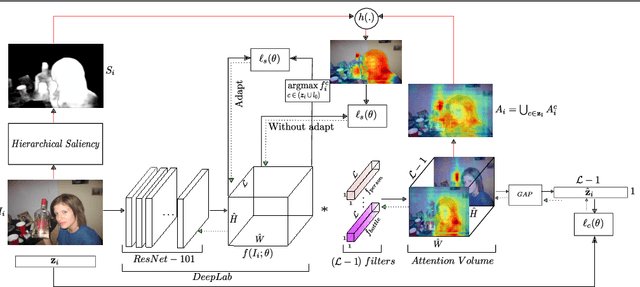

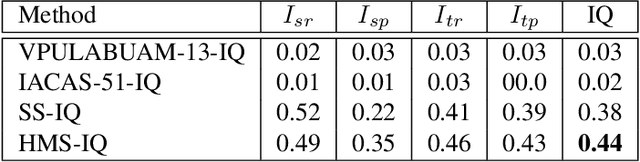
We propose an approach to discover class-specific pixels for the weakly-supervised semantic segmentation task. We show that properly combining saliency and attention maps allows us to obtain reliable cues capable of significantly boosting the performance. First, we propose a simple yet powerful hierarchical approach to discover the class-agnostic salient regions, obtained using a salient object detector, which otherwise would be ignored. Second, we use fully convolutional attention maps to reliably localize the class-specific regions in a given image. We combine these two cues to discover class-specific pixels which are then used as an approximate ground truth for training a CNN. While solving the weakly supervised semantic segmentation task, we ensure that the image-level classification task is also solved in order to enforce the CNN to assign at least one pixel to each object present in the image. Experimentally, on the PASCAL VOC12 val and test sets, we obtain the mIoU of 60.8% and 61.9%, achieving the performance gains of 5.1% and 5.2% compared to the published state-of-the-art results. The code is made publicly available.
Random Forests versus Neural Networks - What's Best for Camera Localization?
Jul 13, 2017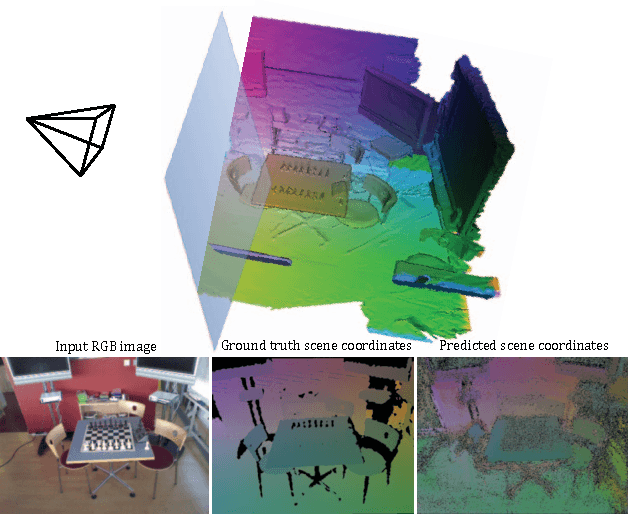
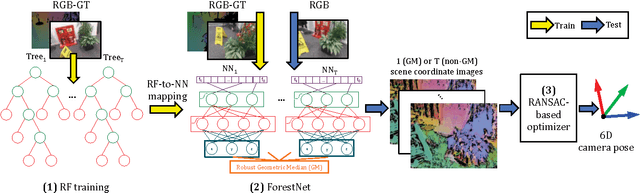
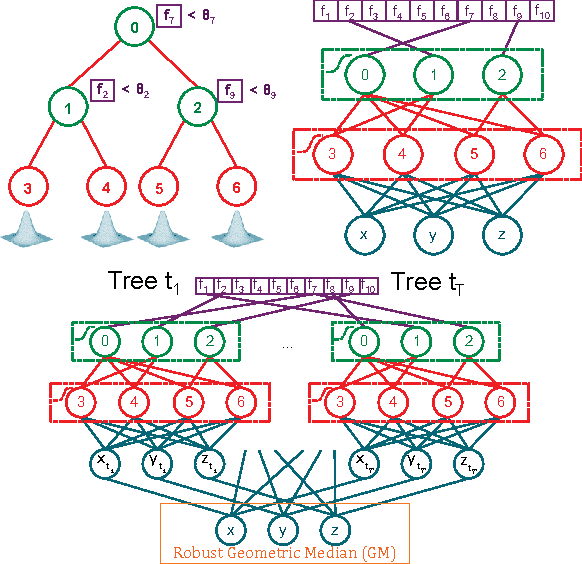
This work addresses the task of camera localization in a known 3D scene given a single input RGB image. State-of-the-art approaches accomplish this in two steps: firstly, regressing for every pixel in the image its 3D scene coordinate and subsequently, using these coordinates to estimate the final 6D camera pose via RANSAC. To solve the first step, Random Forests (RFs) are typically used. On the other hand, Neural Networks (NNs) reign in many dense regression tasks, but are not test-time efficient. We ask the question: which of the two is best for camera localization? To address this, we make two method contributions: (1) a test-time efficient NN architecture which we term a ForestNet that is derived and initialized from a RF, and (2) a new fully-differentiable robust averaging technique for regression ensembles which can be trained end-to-end with a NN. Our experimental findings show that for scene coordinate regression, traditional NN architectures are superior to test-time efficient RFs and ForestNets, however, this does not translate to final 6D camera pose accuracy where RFs and ForestNets perform slightly better. To summarize, our best method, a ForestNet with a robust average, which has an equivalent fast and lightweight RF, improves over the state-of-the-art for camera localization on the 7-Scenes dataset. While this work focuses on scene coordinate regression for camera localization, our innovations may also be applied to other continuous regression tasks.
Straight to Shapes: Real-time Detection of Encoded Shapes
Jul 05, 2017
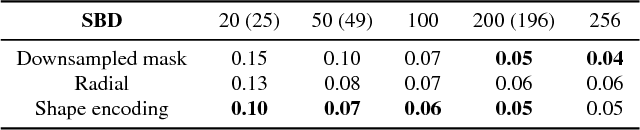

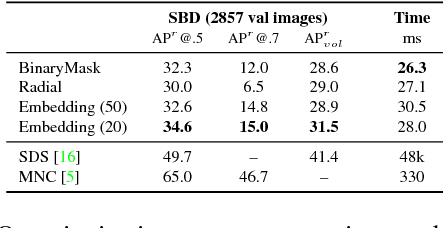
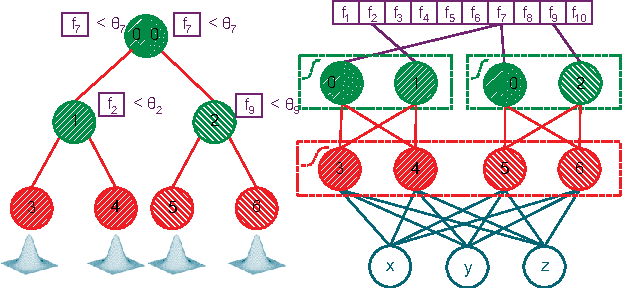
Current object detection approaches predict bounding boxes, but these provide little instance-specific information beyond location, scale and aspect ratio. In this work, we propose to directly regress to objects' shapes in addition to their bounding boxes and categories. It is crucial to find an appropriate shape representation that is compact and decodable, and in which objects can be compared for higher-order concepts such as view similarity, pose variation and occlusion. To achieve this, we use a denoising convolutional auto-encoder to establish an embedding space, and place the decoder after a fast end-to-end network trained to regress directly to the encoded shape vectors. This yields what to the best of our knowledge is the first real-time shape prediction network, running at ~35 FPS on a high-end desktop. With higher-order shape reasoning well-integrated into the network pipeline, the network shows the useful practical quality of generalising to unseen categories similar to the ones in the training set, something that most existing approaches fail to handle.
Learning to superoptimize programs
Jun 28, 2017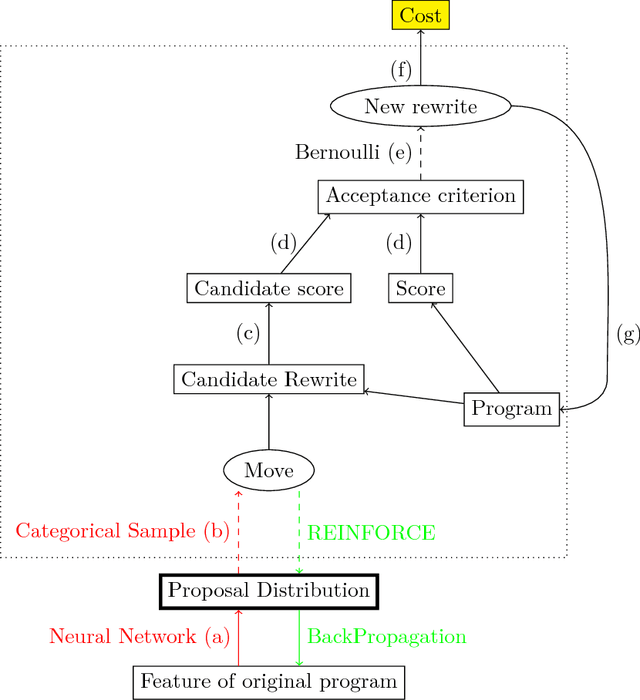
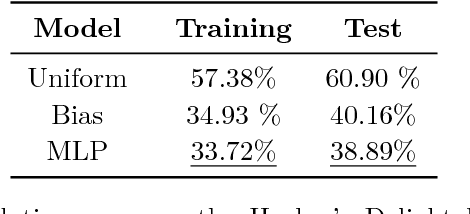
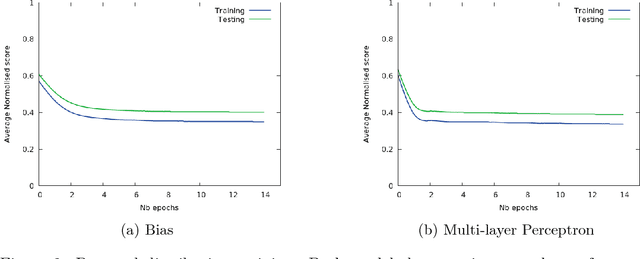
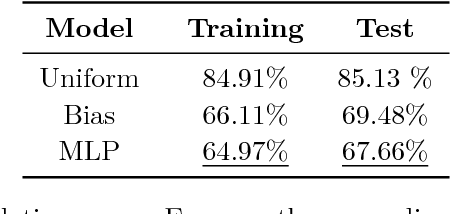
Code super-optimization is the task of transforming any given program to a more efficient version while preserving its input-output behaviour. In some sense, it is similar to the paraphrase problem from natural language processing where the intention is to change the syntax of an utterance without changing its semantics. Code-optimization has been the subject of years of research that has resulted in the development of rule-based transformation strategies that are used by compilers. More recently, however, a class of stochastic search based methods have been shown to outperform these strategies. This approach involves repeated sampling of modifications to the program from a proposal distribution, which are accepted or rejected based on whether they preserve correctness, and the improvement they achieve. These methods, however, neither learn from past behaviour nor do they try to leverage the semantics of the program under consideration. Motivated by this observation, we present a novel learning based approach for code super-optimization. Intuitively, our method works by learning the proposal distribution using unbiased estimators of the gradient of the expected improvement. Experiments on benchmarks comprising of automatically generated as well as existing ("Hacker's Delight") programs show that the proposed method is able to significantly outperform state of the art approaches for code super-optimization.
On-the-Fly Adaptation of Regression Forests for Online Camera Relocalisation
Jun 26, 2017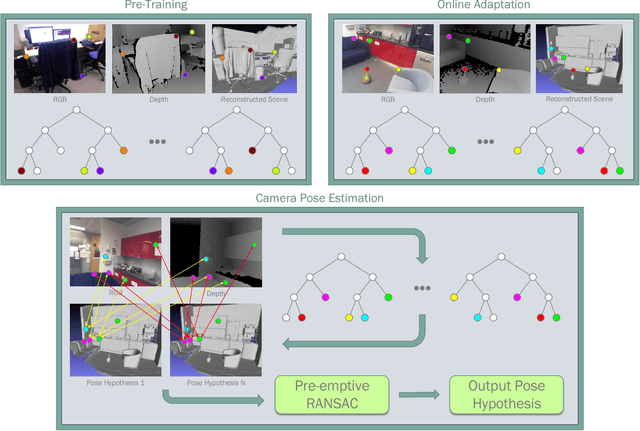
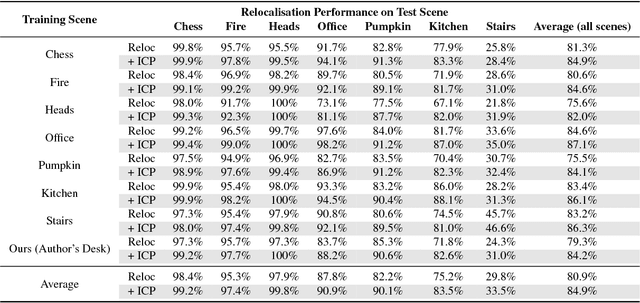

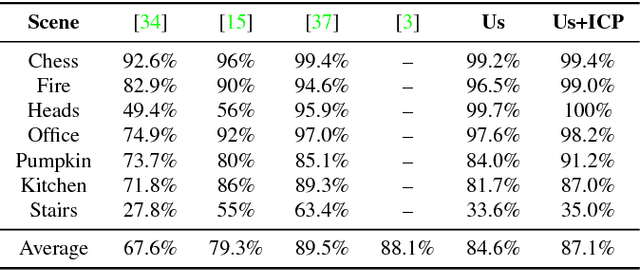
Camera relocalisation is an important problem in computer vision, with applications in simultaneous localisation and mapping, virtual/augmented reality and navigation. Common techniques either match the current image against keyframes with known poses coming from a tracker, or establish 2D-to-3D correspondences between keypoints in the current image and points in the scene in order to estimate the camera pose. Recently, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but must be trained offline on the target scene, preventing relocalisation in new environments. In this paper, we show how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. Our adapted forests achieve relocalisation performance that is on par with that of offline forests, and our approach runs in under 150ms, making it desirable for real-time systems that require online relocalisation.
Sequential Optimization for Efficient High-Quality Object Proposal Generation
May 22, 2017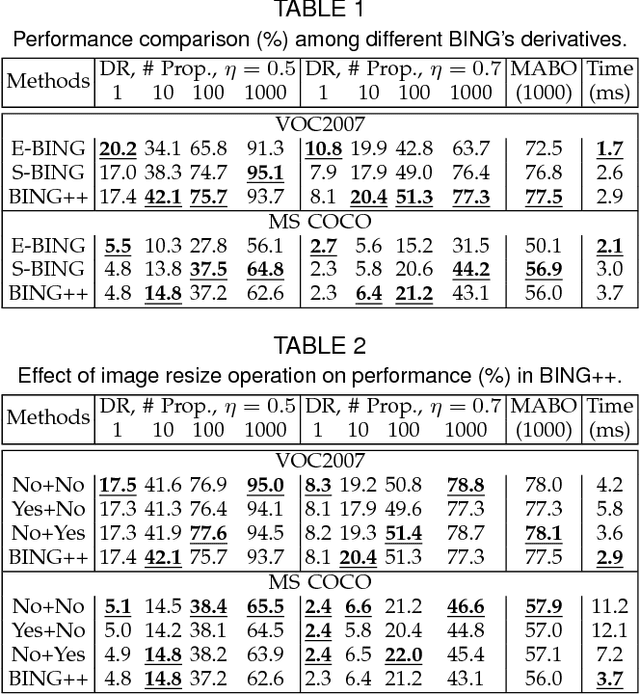
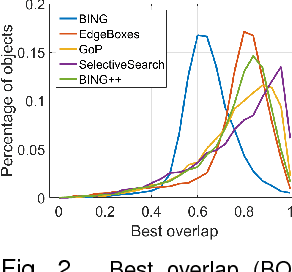


We are motivated by the need for a generic object proposal generation algorithm which achieves good balance between object detection recall, proposal localization quality and computational efficiency. We propose a novel object proposal algorithm, BING++, which inherits the virtue of good computational efficiency of BING but significantly improves its proposal localization quality. At high level we formulate the problem of object proposal generation from a novel probabilistic perspective, based on which our BING++ manages to improve the localization quality by employing edges and segments to estimate object boundaries and update the proposals sequentially. We propose learning the parameters efficiently by searching for approximate solutions in a quantized parameter space for complexity reduction. We demonstrate the generalization of BING++ with the same fixed parameters across different object classes and datasets. Empirically our BING++ can run at half speed of BING on CPU, but significantly improve the localization quality by 18.5% and 16.7% on both VOC2007 and Microhsoft COCO datasets, respectively. Compared with other state-of-the-art approaches, BING++ can achieve comparable performance, but run significantly faster.
End-to-end representation learning for Correlation Filter based tracking
Apr 20, 2017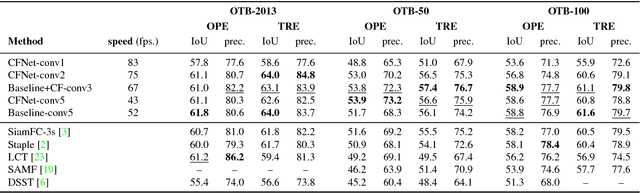

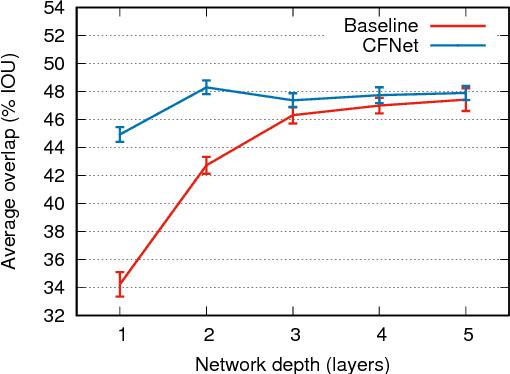
The Correlation Filter is an algorithm that trains a linear template to discriminate between images and their translations. It is well suited to object tracking because its formulation in the Fourier domain provides a fast solution, enabling the detector to be re-trained once per frame. Previous works that use the Correlation Filter, however, have adopted features that were either manually designed or trained for a different task. This work is the first to overcome this limitation by interpreting the Correlation Filter learner, which has a closed-form solution, as a differentiable layer in a deep neural network. This enables learning deep features that are tightly coupled to the Correlation Filter. Experiments illustrate that our method has the important practical benefit of allowing lightweight architectures to achieve state-of-the-art performance at high framerates.
DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents
Apr 14, 2017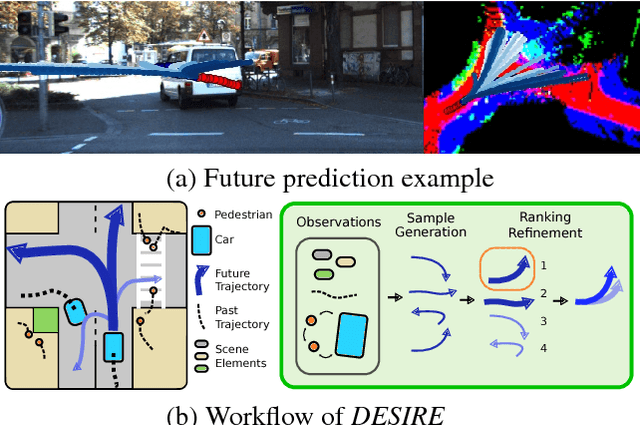
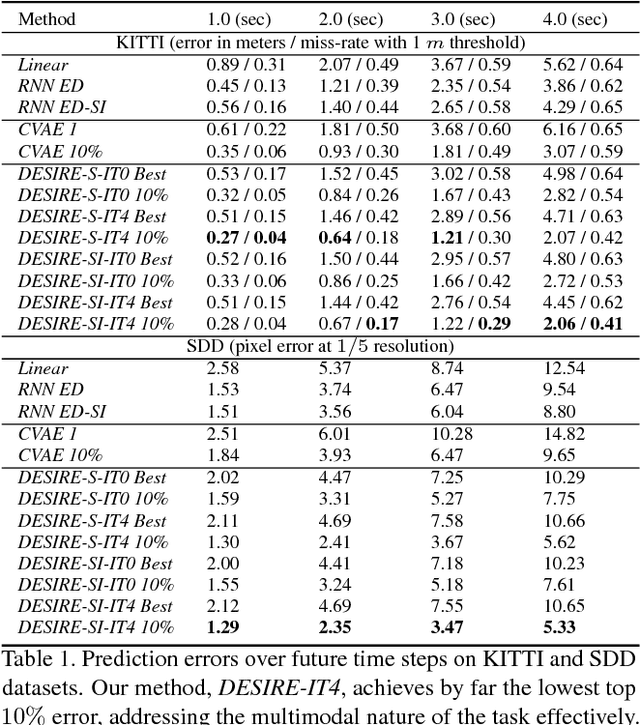
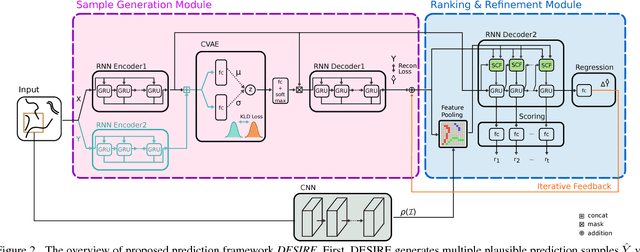
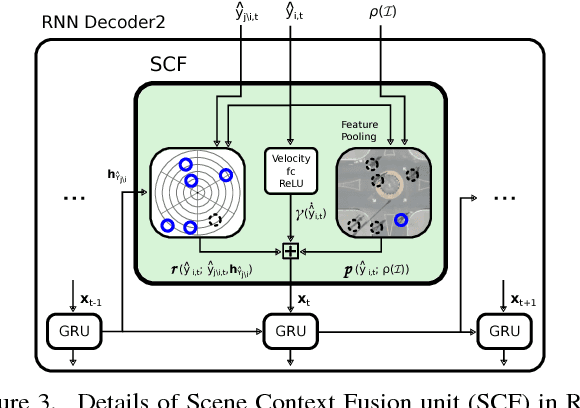
We introduce a Deep Stochastic IOC RNN Encoderdecoder framework, DESIRE, for the task of future predictions of multiple interacting agents in dynamic scenes. DESIRE effectively predicts future locations of objects in multiple scenes by 1) accounting for the multi-modal nature of the future prediction (i.e., given the same context, future may vary), 2) foreseeing the potential future outcomes and make a strategic prediction based on that, and 3) reasoning not only from the past motion history, but also from the scene context as well as the interactions among the agents. DESIRE achieves these in a single end-to-end trainable neural network model, while being computationally efficient. The model first obtains a diverse set of hypothetical future prediction samples employing a conditional variational autoencoder, which are ranked and refined by the following RNN scoring-regression module. Samples are scored by accounting for accumulated future rewards, which enables better long-term strategic decisions similar to IOC frameworks. An RNN scene context fusion module jointly captures past motion histories, the semantic scene context and interactions among multiple agents. A feedback mechanism iterates over the ranking and refinement to further boost the prediction accuracy. We evaluate our model on two publicly available datasets: KITTI and Stanford Drone Dataset. Our experiments show that the proposed model significantly improves the prediction accuracy compared to other baseline methods.
Efficient Linear Programming for Dense CRFs
Feb 14, 2017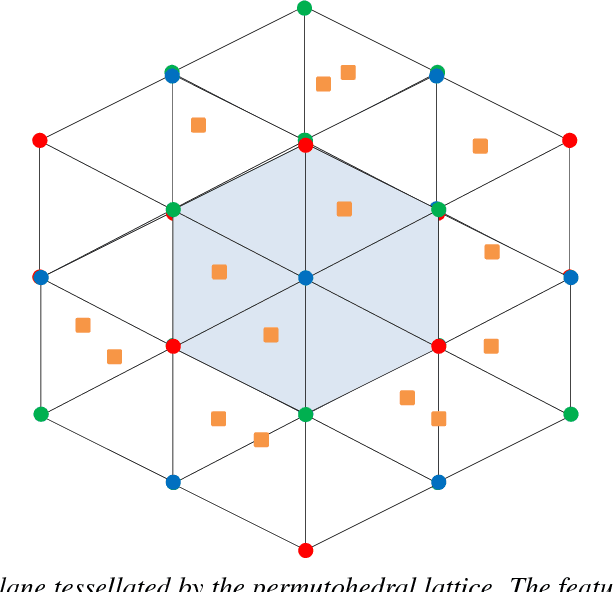
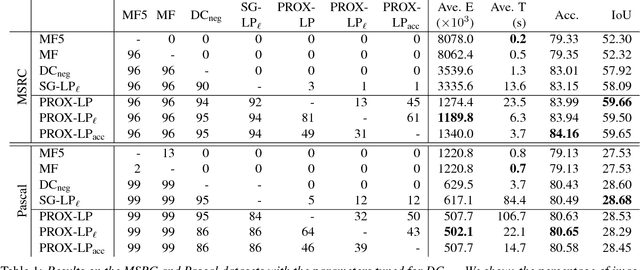
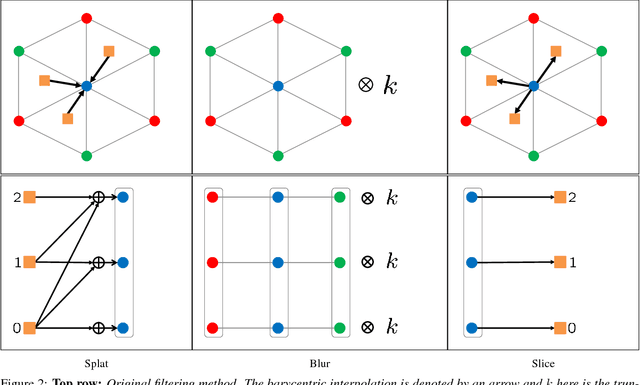

The fully connected conditional random field (CRF) with Gaussian pairwise potentials has proven popular and effective for multi-class semantic segmentation. While the energy of a dense CRF can be minimized accurately using a linear programming (LP) relaxation, the state-of-the-art algorithm is too slow to be useful in practice. To alleviate this deficiency, we introduce an efficient LP minimization algorithm for dense CRFs. To this end, we develop a proximal minimization framework, where the dual of each proximal problem is optimized via block coordinate descent. We show that each block of variables can be efficiently optimized. Specifically, for one block, the problem decomposes into significantly smaller subproblems, each of which is defined over a single pixel. For the other block, the problem is optimized via conditional gradient descent. This has two advantages: 1) the conditional gradient can be computed in a time linear in the number of pixels and labels; and 2) the optimal step size can be computed analytically. Our experiments on standard datasets provide compelling evidence that our approach outperforms all existing baselines including the previous LP based approach for dense CRFs.