 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Enhancing Robustness of Deep Recommendation Systems Against Hardware Errors
Jul 17, 2023



Deep recommendation systems (DRS) heavily depend on specialized HPC hardware and accelerators to optimize energy, efficiency, and recommendation quality. Despite the growing number of hardware errors observed in large-scale fleet systems where DRS are deployed, the robustness of DRS has been largely overlooked. This paper presents the first systematic study of DRS robustness against hardware errors. We develop Terrorch, a user-friendly, efficient and flexible error injection framework on top of the widely-used PyTorch. We evaluate a wide range of models and datasets and observe that the DRS robustness against hardware errors is influenced by various factors from model parameters to input characteristics. We also explore 3 error mitigation methods including algorithm based fault tolerance (ABFT), activation clipping and selective bit protection (SBP). We find that applying activation clipping can recover up to 30% of the degraded AUC-ROC score, making it a promising mitigation method.
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Apr 21, 2023It is widely acknowledged that large models have the potential to deliver superior performance across a broad range of domains. Despite the remarkable progress made in the field of machine learning systems research, which has enabled the development and exploration of large models, such abilities remain confined to a small group of advanced users and industry leaders, resulting in an implicit technical barrier for the wider community to access and leverage these technologies. In this paper, we introduce PyTorch Fully Sharded Data Parallel (FSDP) as an industry-grade solution for large model training. FSDP has been closely co-designed with several key PyTorch core components including Tensor implementation, dispatcher system, and CUDA memory caching allocator, to provide non-intrusive user experiences and high training efficiency. Additionally, FSDP natively incorporates a range of techniques and settings to optimize resource utilization across a variety of hardware configurations. The experimental results demonstrate that FSDP is capable of achieving comparable performance to Distributed Data Parallel while providing support for significantly larger models with near-linear scalability in terms of TFLOPS.
Improved Branch and Bound for Neural Network Verification via Lagrangian Decomposition
Apr 14, 2021
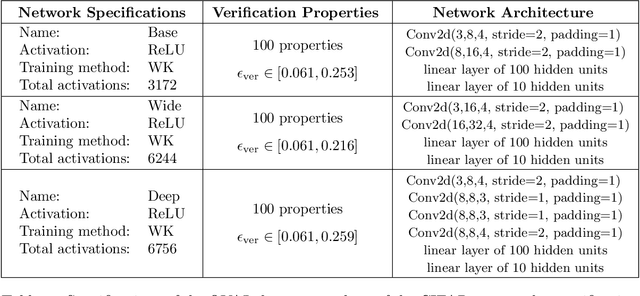
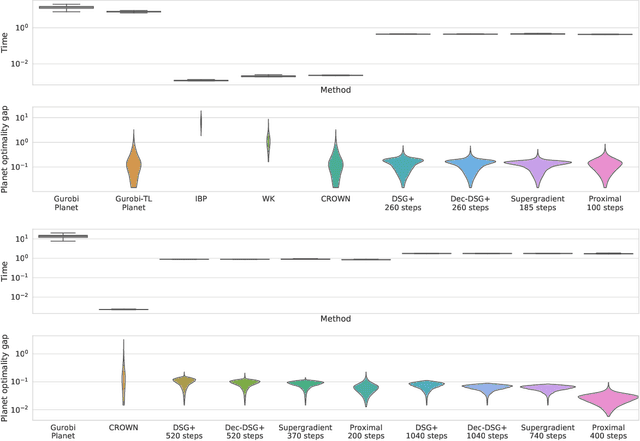
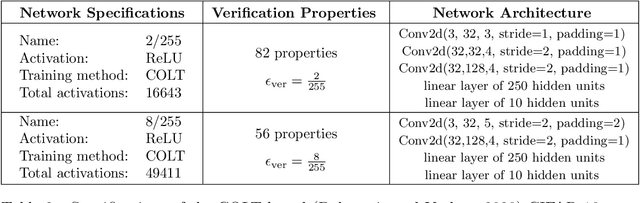
We improve the scalability of Branch and Bound (BaB) algorithms for formally proving input-output properties of neural networks. First, we propose novel bounding algorithms based on Lagrangian Decomposition. Previous works have used off-the-shelf solvers to solve relaxations at each node of the BaB tree, or constructed weaker relaxations that can be solved efficiently, but lead to unnecessarily weak bounds. Our formulation restricts the optimization to a subspace of the dual domain that is guaranteed to contain the optimum, resulting in accelerated convergence. Furthermore, it allows for a massively parallel implementation, which is amenable to GPU acceleration via modern deep learning frameworks. Second, we present a novel activation-based branching strategy. By coupling an inexpensive heuristic with fast dual bounding, our branching scheme greatly reduces the size of the BaB tree compared to previous heuristic methods. Moreover, it performs competitively with a recent strategy based on learning algorithms, without its large offline training cost. Finally, we design a BaB framework, named Branch and Dual Network Bound (BaDNB), based on our novel bounding and branching algorithms. We show that BaDNB outperforms previous complete verification systems by a large margin, cutting average verification times by factors up to 50 on adversarial robustness properties.
Lagrangian Decomposition for Neural Network Verification
Feb 24, 2020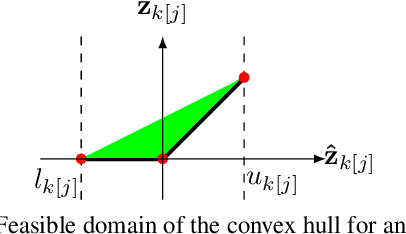

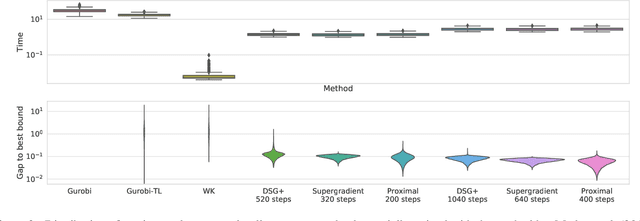

A fundamental component of neural network verification is the computation of bounds on the values their outputs can take. Previous methods have either used off-the-shelf solvers, discarding the problem structure, or relaxed the problem even further, making the bounds unnecessarily loose. We propose a novel approach based on Lagrangian Decomposition. Our formulation admits an efficient supergradient ascent algorithm, as well as an improved proximal algorithm. Both the algorithms offer three advantages: (i) they yield bounds that are provably at least as tight as previous dual algorithms relying on Lagrangian relaxations; (ii) they are based on operations analogous to forward/backward pass of neural networks layers and are therefore easily parallelizable, amenable to GPU implementation and able to take advantage of the convolutional structure of problems; and (iii) they allow for anytime stopping while still providing valid bounds. Empirically, we show that we obtain bounds comparable with off-the-shelf solvers in a fraction of their running time, and obtain tighter bounds in the same time as previous dual algorithms. This results in an overall speed-up when employing the bounds for formal verification.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019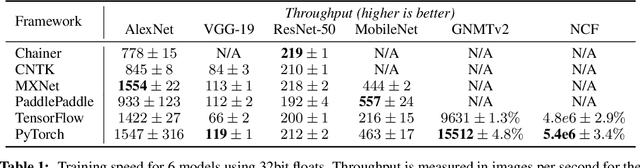

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
Efficient Relaxations for Dense CRFs with Sparse Higher Order Potentials
Oct 26, 2018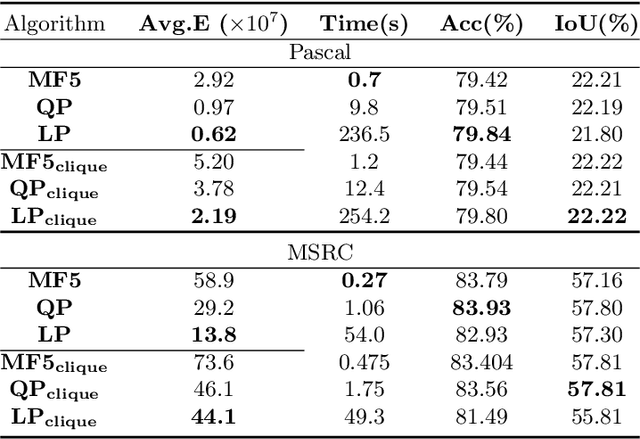
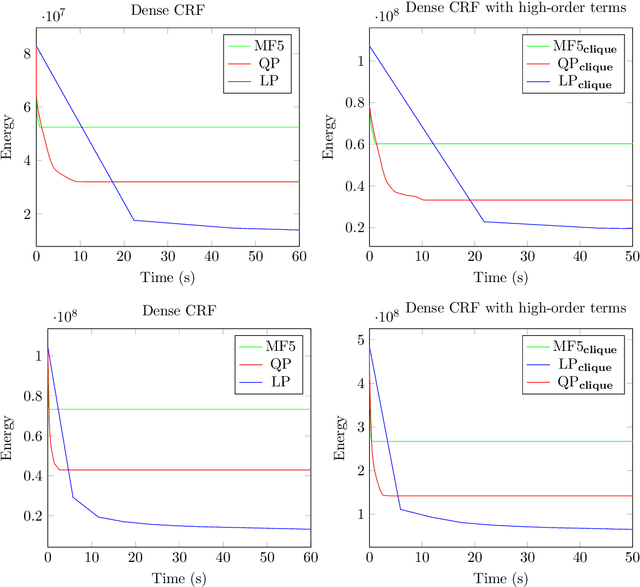
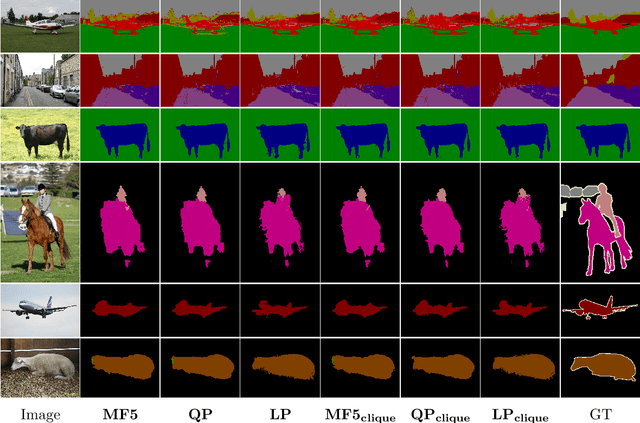
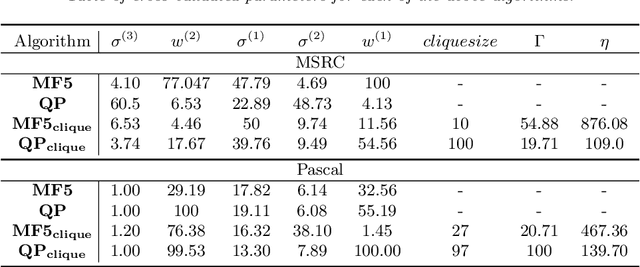
Dense conditional random fields (CRFs) have become a popular framework for modelling several problems in computer vision such as stereo correspondence and multi-class semantic segmentation. By modelling long-range interactions, dense CRFs provide a labelling that captures finer detail than their sparse counterparts. Currently, the state-of-the-art algorithm performs mean-field inference using a filter-based method but fails to provide a strong theoretical guarantee on the quality of the solution. A question naturally arises as to whether it is possible to obtain a maximum a posteriori (MAP) estimate of a dense CRF using a principled method. Within this paper, we show that this is indeed possible. We will show that, by using a filter-based method, continuous relaxations of the MAP problem can be optimised efficiently using state-of-the-art algorithms. Specifically, we will solve a quadratic programming (QP) relaxation using the Frank-Wolfe algorithm and a linear programming (LP) relaxation by developing a proximal minimisation framework. By exploiting labelling consistency in the higher-order potentials and utilising the filter-based method, we are able to formulate the above algorithms such that each iteration has a complexity linear in the number of classes and random variables. The presented algorithms can be applied to any labelling problem using a dense CRF with sparse higher-order potentials. In this paper, we use semantic segmentation as an example application as it demonstrates the ability of the algorithm to scale to dense CRFs with large dimensions. We perform experiments on the Pascal dataset to indicate that the presented algorithms are able to attain lower energies than the mean-field inference method.
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017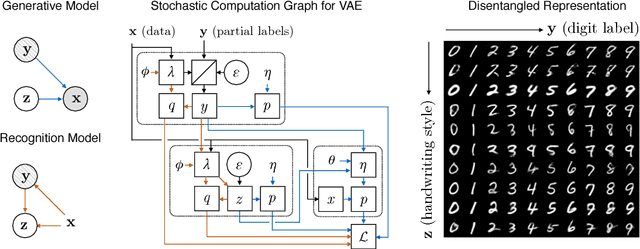

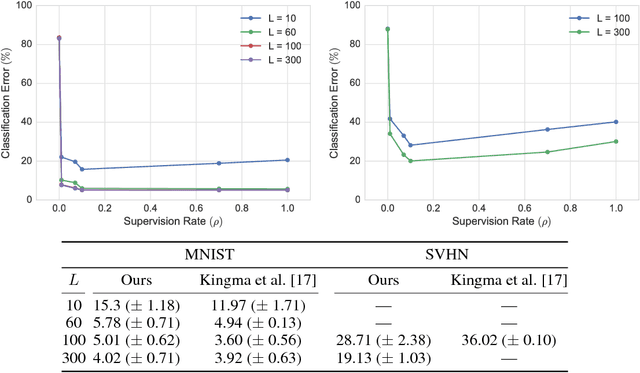
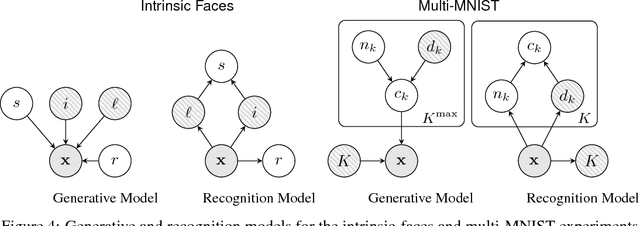
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.
Learning to superoptimize programs
Jun 28, 2017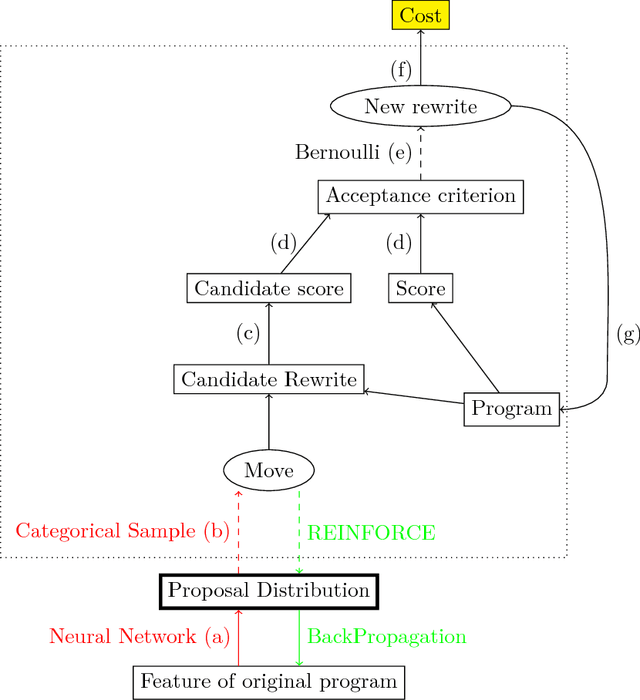
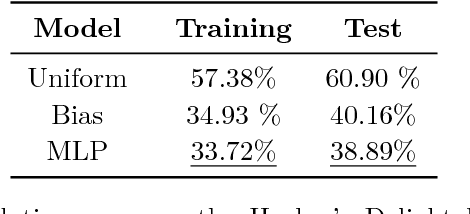
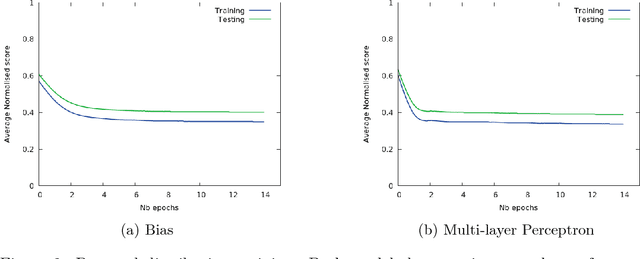
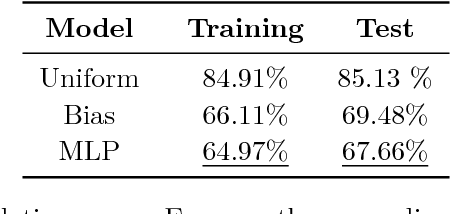
Code super-optimization is the task of transforming any given program to a more efficient version while preserving its input-output behaviour. In some sense, it is similar to the paraphrase problem from natural language processing where the intention is to change the syntax of an utterance without changing its semantics. Code-optimization has been the subject of years of research that has resulted in the development of rule-based transformation strategies that are used by compilers. More recently, however, a class of stochastic search based methods have been shown to outperform these strategies. This approach involves repeated sampling of modifications to the program from a proposal distribution, which are accepted or rejected based on whether they preserve correctness, and the improvement they achieve. These methods, however, neither learn from past behaviour nor do they try to leverage the semantics of the program under consideration. Motivated by this observation, we present a novel learning based approach for code super-optimization. Intuitively, our method works by learning the proposal distribution using unbiased estimators of the gradient of the expected improvement. Experiments on benchmarks comprising of automatically generated as well as existing ("Hacker's Delight") programs show that the proposed method is able to significantly outperform state of the art approaches for code super-optimization.
Efficient Linear Programming for Dense CRFs
Feb 14, 2017
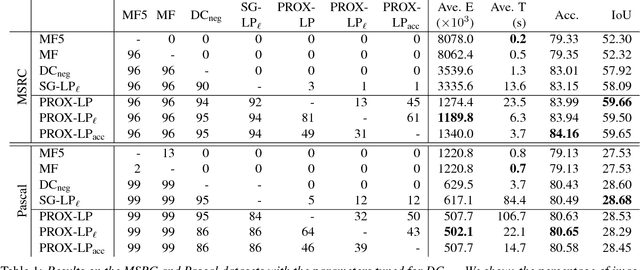
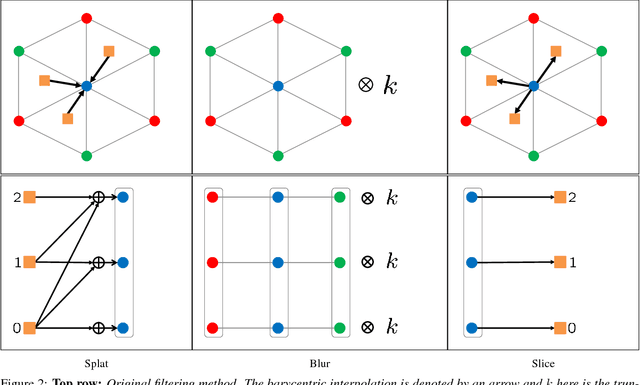

The fully connected conditional random field (CRF) with Gaussian pairwise potentials has proven popular and effective for multi-class semantic segmentation. While the energy of a dense CRF can be minimized accurately using a linear programming (LP) relaxation, the state-of-the-art algorithm is too slow to be useful in practice. To alleviate this deficiency, we introduce an efficient LP minimization algorithm for dense CRFs. To this end, we develop a proximal minimization framework, where the dual of each proximal problem is optimized via block coordinate descent. We show that each block of variables can be efficiently optimized. Specifically, for one block, the problem decomposes into significantly smaller subproblems, each of which is defined over a single pixel. For the other block, the problem is optimized via conditional gradient descent. This has two advantages: 1) the conditional gradient can be computed in a time linear in the number of pixels and labels; and 2) the optimal step size can be computed analytically. Our experiments on standard datasets provide compelling evidence that our approach outperforms all existing baselines including the previous LP based approach for dense CRFs.
Learning to superoptimize programs - Workshop Version
Dec 04, 2016Superoptimization requires the estimation of the best program for a given computational task. In order to deal with large programs, superoptimization techniques perform a stochastic search. This involves proposing a modification of the current program, which is accepted or rejected based on the improvement achieved. The state of the art method uses uniform proposal distributions, which fails to exploit the problem structure to the fullest. To alleviate this deficiency, we learn a proposal distribution over possible modifications using Reinforcement Learning. We provide convincing results on the superoptimization of "Hacker's Delight" programs.