 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRay3D: ray-based 3D human pose estimation for monocular absolute 3D localization
Mar 30, 2022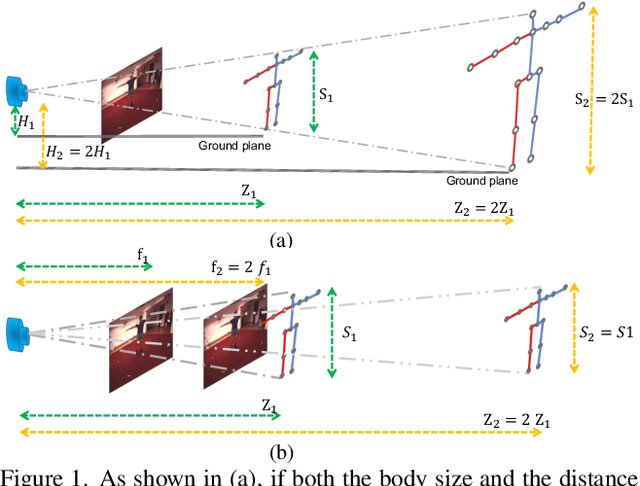

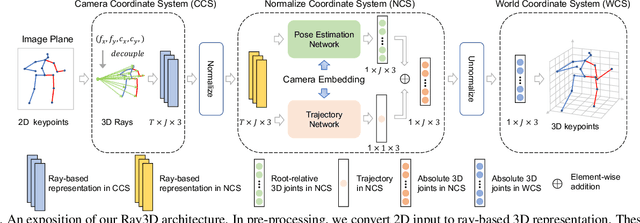
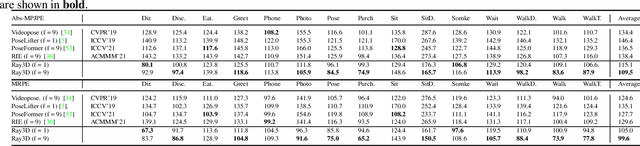
In this paper, we propose a novel monocular ray-based 3D (Ray3D) absolute human pose estimation with calibrated camera. Accurate and generalizable absolute 3D human pose estimation from monocular 2D pose input is an ill-posed problem. To address this challenge, we convert the input from pixel space to 3D normalized rays. This conversion makes our approach robust to camera intrinsic parameter changes. To deal with the in-the-wild camera extrinsic parameter variations, Ray3D explicitly takes the camera extrinsic parameters as an input and jointly models the distribution between the 3D pose rays and camera extrinsic parameters. This novel network design is the key to the outstanding generalizability of Ray3D approach. To have a comprehensive understanding of how the camera intrinsic and extrinsic parameter variations affect the accuracy of absolute 3D key-point localization, we conduct in-depth systematic experiments on three single person 3D benchmarks as well as one synthetic benchmark. These experiments demonstrate that our method significantly outperforms existing state-of-the-art models. Our code and the synthetic dataset are available at https://github.com/YxZhxn/Ray3D .
3SD: Self-Supervised Saliency Detection With No Labels
Mar 09, 2022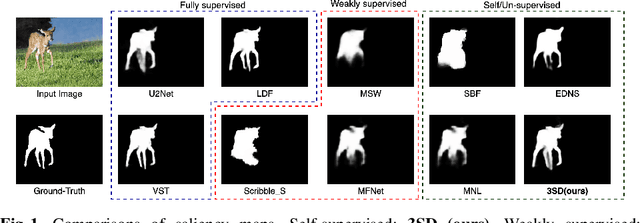
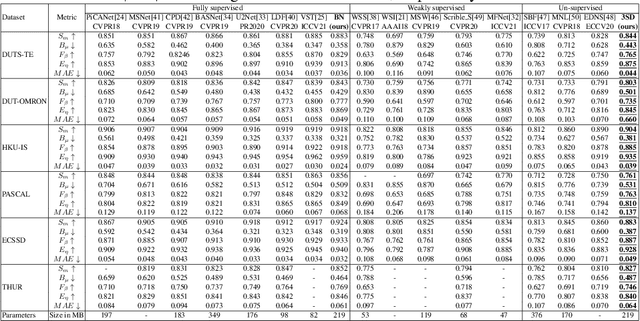

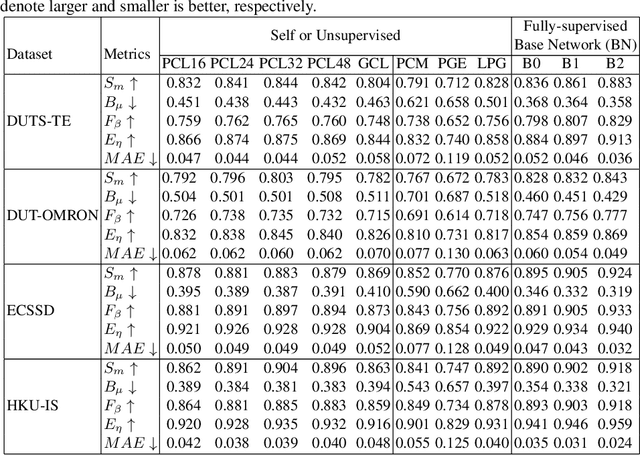
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don't require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD
Learning a Proposal Classifier for Multiple Object Tracking
Mar 26, 2021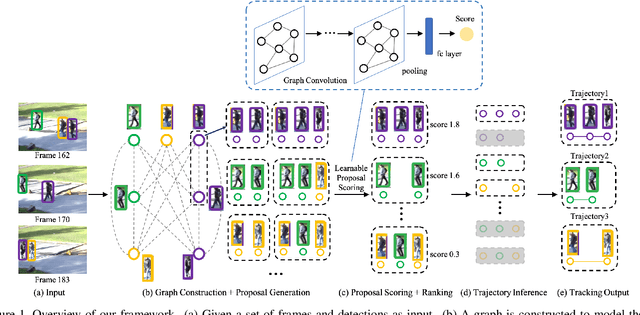
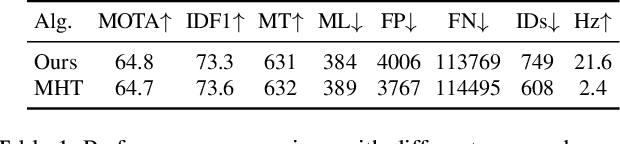
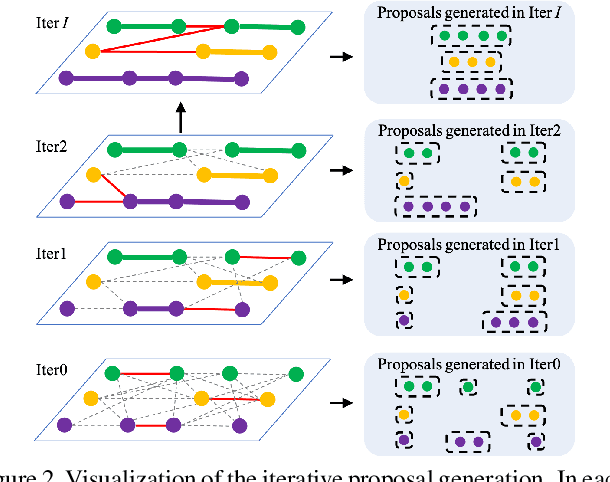
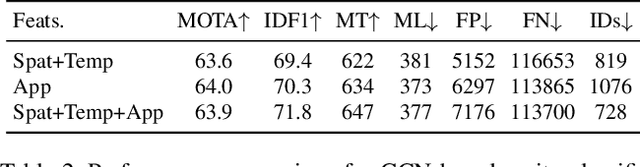
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. However, it is not trivial to solve the data-association problem in an end-to-end fashion. In this paper, we propose a novel proposal-based learnable framework, which models MOT as a proposal generation, proposal scoring and trajectory inference paradigm on an affinity graph. This framework is similar to the two-stage object detector Faster RCNN, and can solve the MOT problem in a data-driven way. For proposal generation, we propose an iterative graph clustering method to reduce the computational cost while maintaining the quality of the generated proposals. For proposal scoring, we deploy a trainable graph-convolutional-network (GCN) to learn the structural patterns of the generated proposals and rank them according to the estimated quality scores. For trajectory inference, a simple deoverlapping strategy is adopted to generate tracking output while complying with the constraints that no detection can be assigned to more than one track. We experimentally demonstrate that the proposed method achieves a clear performance improvement in both MOTA and IDF1 with respect to previous state-of-the-art on two public benchmarks. Our code is available at https://github.com/daip13/LPC_MOT.git.
Multi-Agent Tensor Fusion for Contextual Trajectory Prediction
Apr 09, 2019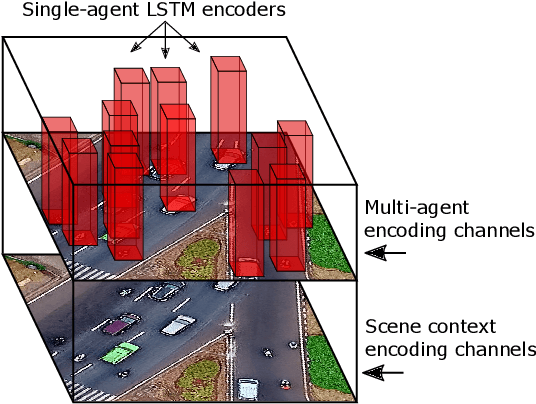
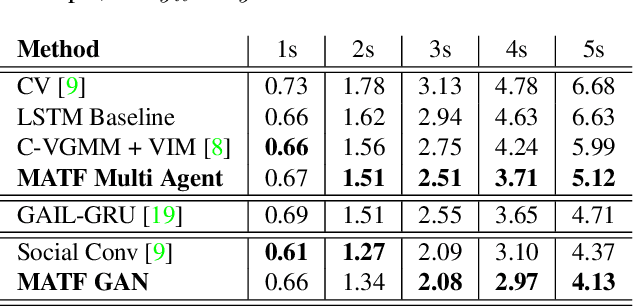
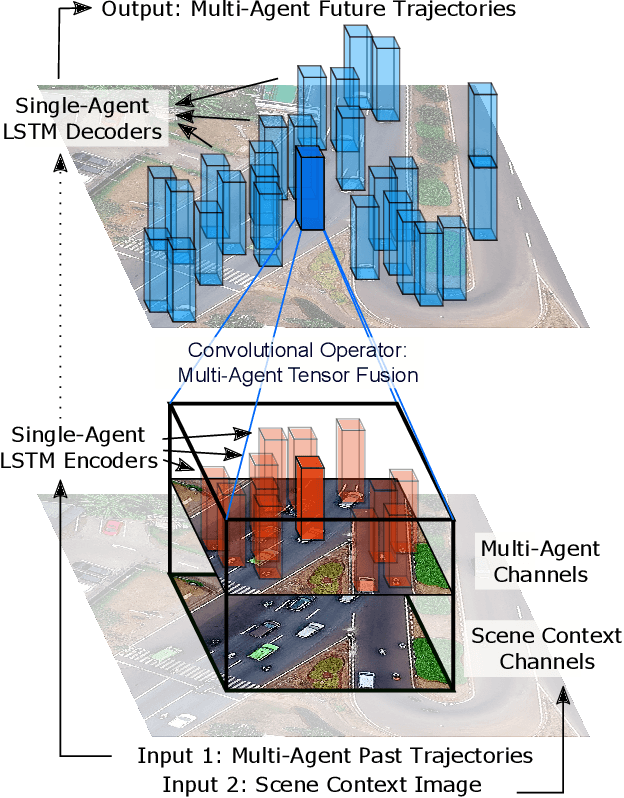
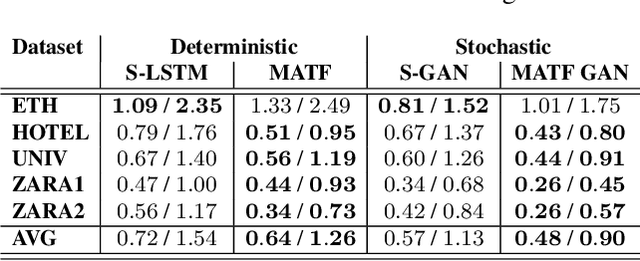
Accurate prediction of others' trajectories is essential for autonomous driving. Trajectory prediction is challenging because it requires reasoning about agents' past movements, social interactions among varying numbers and kinds of agents, constraints from the scene context, and the stochasticity of human behavior. Our approach models these interactions and constraints jointly within a novel Multi-Agent Tensor Fusion (MATF) network. Specifically, the model encodes multiple agents' past trajectories and the scene context into a Multi-Agent Tensor, then applies convolutional fusion to capture multiagent interactions while retaining the spatial structure of agents and the scene context. The model decodes recurrently to multiple agents' future trajectories, using adversarial loss to learn stochastic predictions. Experiments on both highway driving and pedestrian crowd datasets show that the model achieves state-of-the-art prediction accuracy.
Memory Warps for Learning Long-Term Online Video Representations
Mar 28, 2018
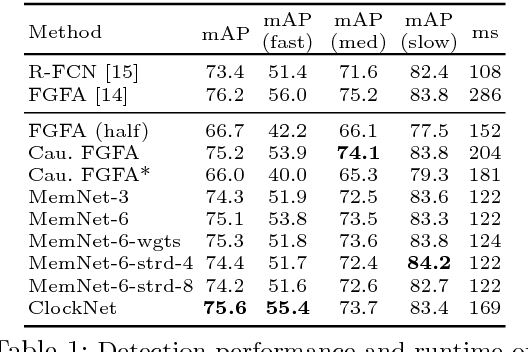
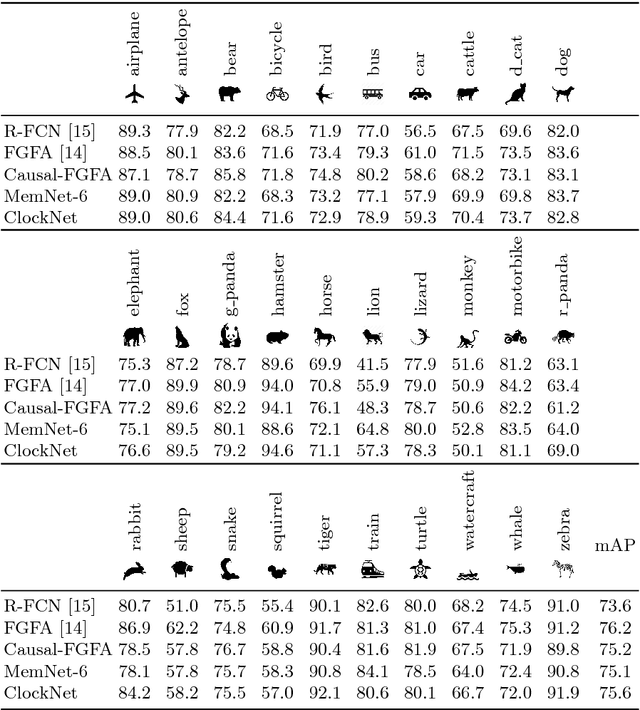
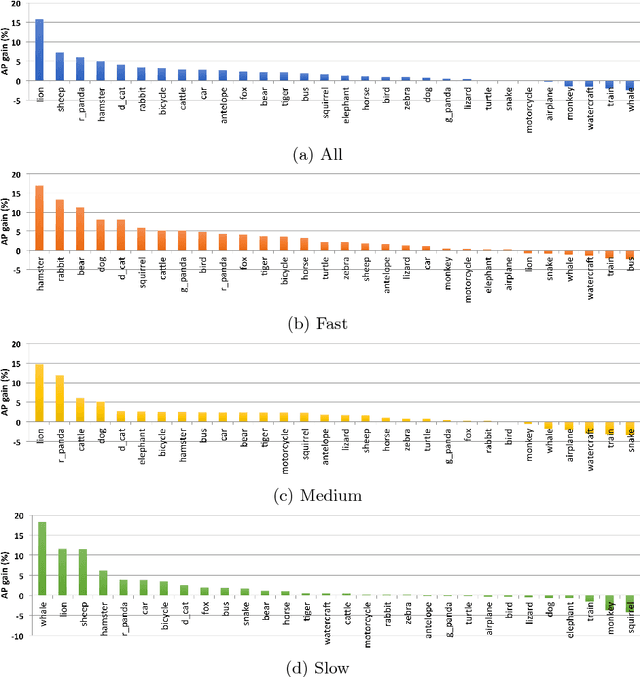
This paper proposes a novel memory-based online video representation that is efficient, accurate and predictive. This is in contrast to prior works that often rely on computationally heavy 3D convolutions, ignore actual motion when aligning features over time, or operate in an off-line mode to utilize future frames. In particular, our memory (i) holds the feature representation, (ii) is spatially warped over time to compensate for observer and scene motions, (iii) can carry long-term information, and (iv) enables predicting feature representations in future frames. By exploring a variant that operates at multiple temporal scales, we efficiently learn across even longer time horizons. We apply our online framework to object detection in videos, obtaining a large 2.3 times speed-up and losing only 0.9% mAP on ImageNet-VID dataset, compared to prior works that even use future frames. Finally, we demonstrate the predictive property of our representation in two novel detection setups, where features are propagated over time to (i) significantly enhance a real-time detector by more than 10% mAP in a multi-threaded online setup and to (ii) anticipate objects in future frames.
Deep Network Flow for Multi-Object Tracking
Jun 26, 2017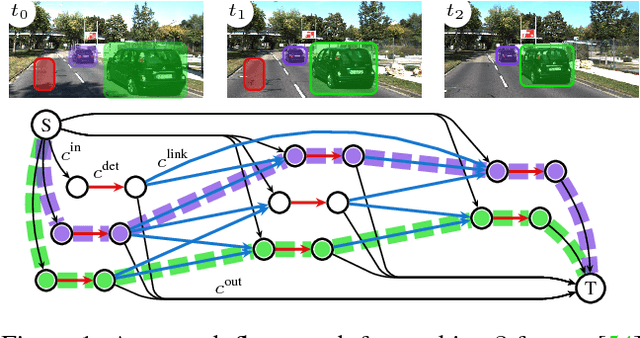
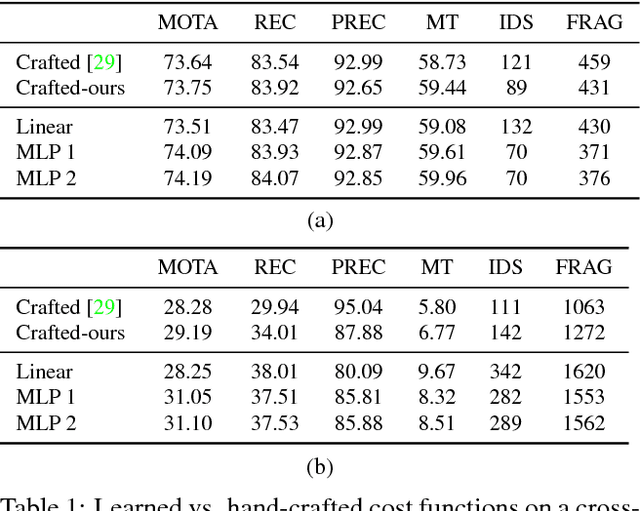
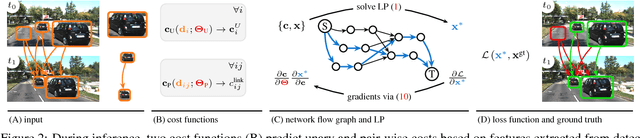
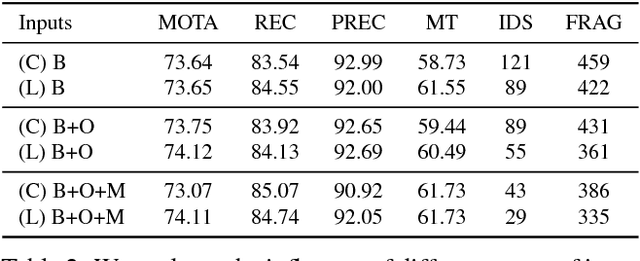
Data association problems are an important component of many computer vision applications, with multi-object tracking being one of the most prominent examples. A typical approach to data association involves finding a graph matching or network flow that minimizes a sum of pairwise association costs, which are often either hand-crafted or learned as linear functions of fixed features. In this work, we demonstrate that it is possible to learn features for network-flow-based data association via backpropagation, by expressing the optimum of a smoothed network flow problem as a differentiable function of the pairwise association costs. We apply this approach to multi-object tracking with a network flow formulation. Our experiments demonstrate that we are able to successfully learn all cost functions for the association problem in an end-to-end fashion, which outperform hand-crafted costs in all settings. The integration and combination of various sources of inputs becomes easy and the cost functions can be learned entirely from data, alleviating tedious hand-designing of costs.
DESIRE: Distant Future Prediction in Dynamic Scenes with Interacting Agents
Apr 14, 2017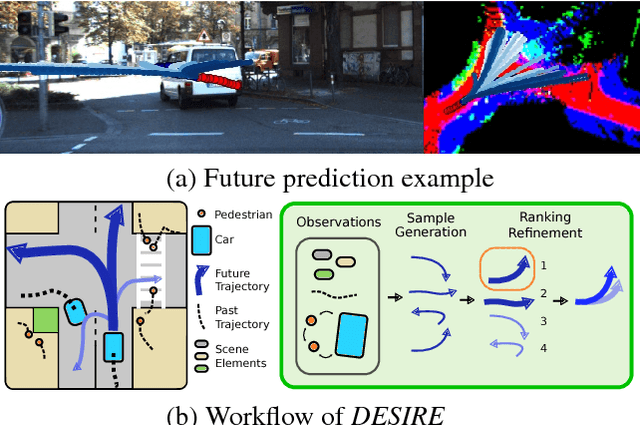
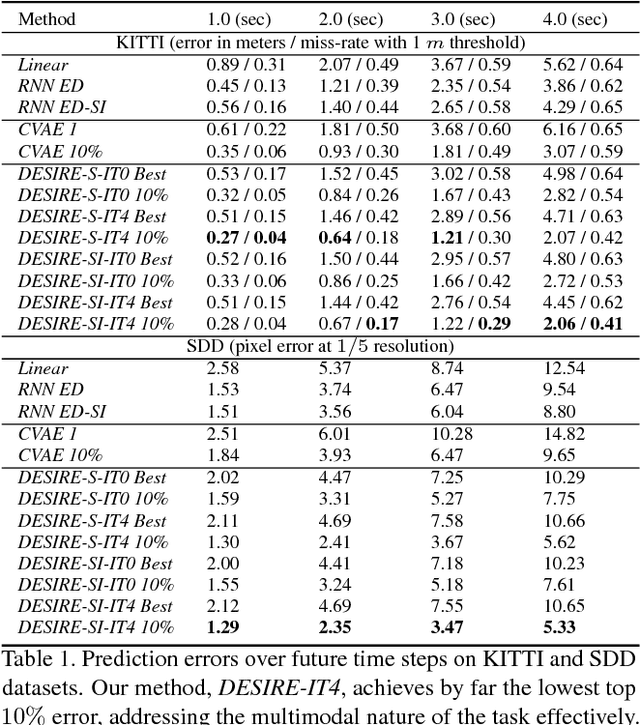
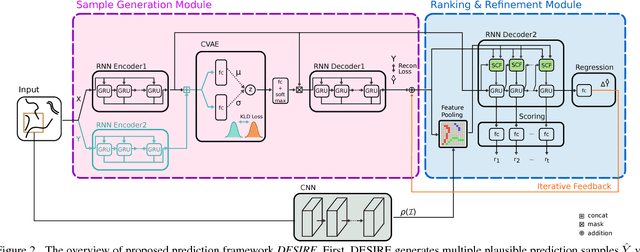
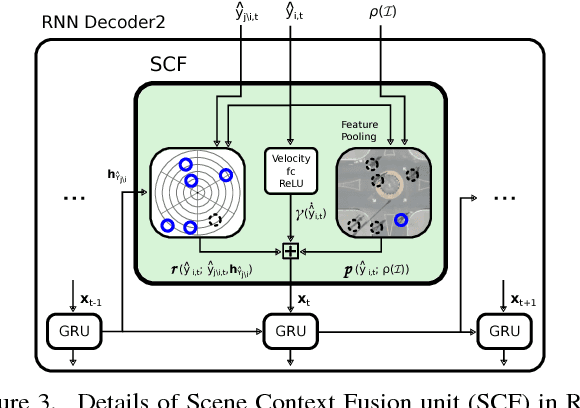
We introduce a Deep Stochastic IOC RNN Encoderdecoder framework, DESIRE, for the task of future predictions of multiple interacting agents in dynamic scenes. DESIRE effectively predicts future locations of objects in multiple scenes by 1) accounting for the multi-modal nature of the future prediction (i.e., given the same context, future may vary), 2) foreseeing the potential future outcomes and make a strategic prediction based on that, and 3) reasoning not only from the past motion history, but also from the scene context as well as the interactions among the agents. DESIRE achieves these in a single end-to-end trainable neural network model, while being computationally efficient. The model first obtains a diverse set of hypothetical future prediction samples employing a conditional variational autoencoder, which are ranked and refined by the following RNN scoring-regression module. Samples are scored by accounting for accumulated future rewards, which enables better long-term strategic decisions similar to IOC frameworks. An RNN scene context fusion module jointly captures past motion histories, the semantic scene context and interactions among multiple agents. A feedback mechanism iterates over the ranking and refinement to further boost the prediction accuracy. We evaluate our model on two publicly available datasets: KITTI and Stanford Drone Dataset. Our experiments show that the proposed model significantly improves the prediction accuracy compared to other baseline methods.
Subcategory-aware Convolutional Neural Networks for Object Proposals and Detection
Mar 09, 2017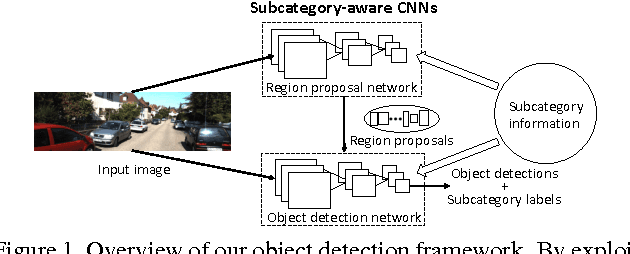
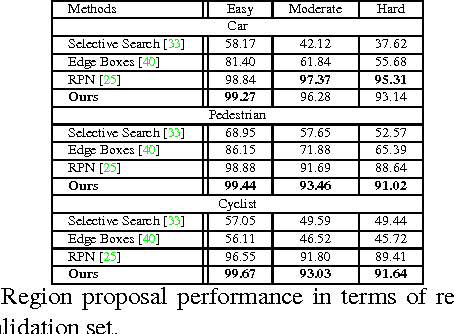
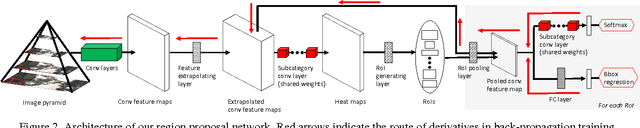
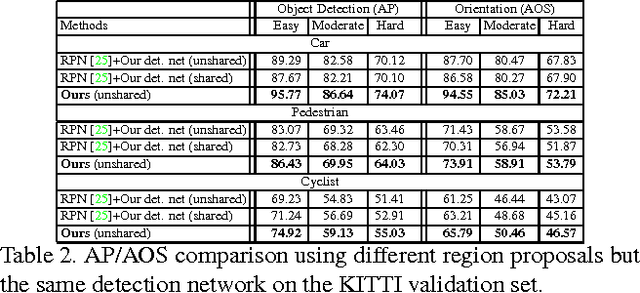
In CNN-based object detection methods, region proposal becomes a bottleneck when objects exhibit significant scale variation, occlusion or truncation. In addition, these methods mainly focus on 2D object detection and cannot estimate detailed properties of objects. In this paper, we propose subcategory-aware CNNs for object detection. We introduce a novel region proposal network that uses subcategory information to guide the proposal generating process, and a new detection network for joint detection and subcategory classification. By using subcategories related to object pose, we achieve state-of-the-art performance on both detection and pose estimation on commonly used benchmarks.
Near-Online Multi-target Tracking with Aggregated Local Flow Descriptor
Apr 09, 2015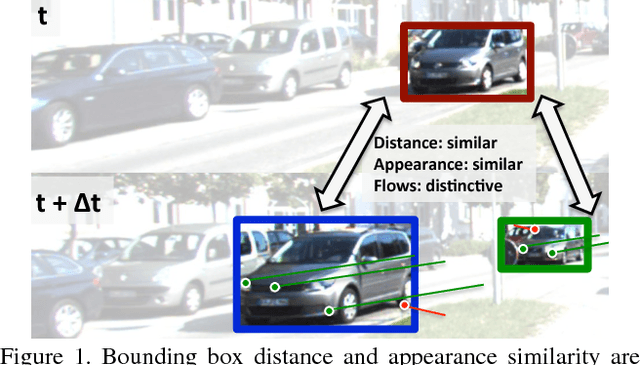
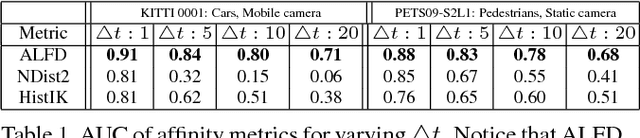
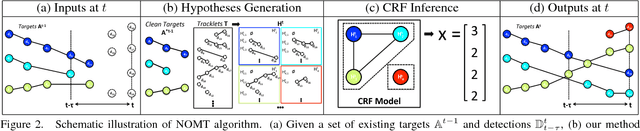
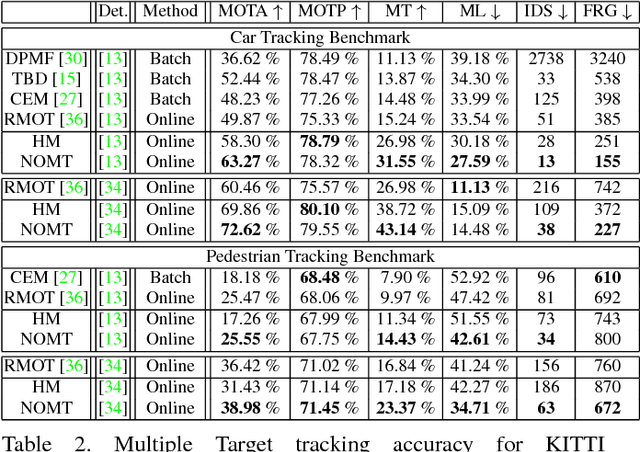
In this paper, we focus on the two key aspects of multiple target tracking problem: 1) designing an accurate affinity measure to associate detections and 2) implementing an efficient and accurate (near) online multiple target tracking algorithm. As the first contribution, we introduce a novel Aggregated Local Flow Descriptor (ALFD) that encodes the relative motion pattern between a pair of temporally distant detections using long term interest point trajectories (IPTs). Leveraging on the IPTs, the ALFD provides a robust affinity measure for estimating the likelihood of matching detections regardless of the application scenarios. As another contribution, we present a Near-Online Multi-target Tracking (NOMT) algorithm. The tracking problem is formulated as a data-association between targets and detections in a temporal window, that is performed repeatedly at every frame. While being efficient, NOMT achieves robustness via integrating multiple cues including ALFD metric, target dynamics, appearance similarity, and long term trajectory regularization into the model. Our ablative analysis verifies the superiority of the ALFD metric over the other conventional affinity metrics. We run a comprehensive experimental evaluation on two challenging tracking datasets, KITTI and MOT datasets. The NOMT method combined with ALFD metric achieves the best accuracy in both datasets with significant margins (about 10% higher MOTA) over the state-of-the-arts.