 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Staleness in Asynchronous Pipeline Parallelism via Basis Rotation
Feb 03, 2026Asynchronous pipeline parallelism maximizes hardware utilization by eliminating the pipeline bubbles inherent in synchronous execution, offering a path toward efficient large-scale distributed training. However, this efficiency gain can be compromised by gradient staleness, where the immediate model updates with delayed gradients introduce noise into the optimization process. Crucially, we identify a critical, yet often overlooked, pathology: this delay scales linearly with pipeline depth, fundamentally undermining the very scalability that the method originally intends to provide. In this work, we investigate this inconsistency and bridge the gap by rectifying delayed gradients through basis rotation, restoring scalable asynchronous training while maintaining performance. Specifically, we observe that the deleterious effects of delayed gradients are exacerbated when the Hessian eigenbasis is misaligned with the standard coordinate basis. We demonstrate that this misalignment prevents coordinate-wise adaptive schemes, such as Adam, from effectively leveraging curvature-aware adaptivity. This failure leads to significant oscillations in the optimization trajectory and, consequently, slower convergence. We substantiate these findings through both rigorous theoretical analysis and empirical evaluation. To address this challenge, we propose the use of basis rotation, demonstrating that it effectively mitigates the alignment issue and significantly accelerates convergence in asynchronous settings. For example, our training of a 1B-parameter LLM with basis rotation achieves the same training loss in 76.8% fewer iterations compared to the best-performing asynchronous pipeline parallel training baseline.
The Unseen Frontier: Pushing the Limits of LLM Sparsity with Surrogate-Free ADMM
Oct 02, 2025Neural network pruning is a promising technique to mitigate the excessive computational and memory requirements of large language models (LLMs). Despite its promise, however, progress in this area has diminished, as conventional methods are seemingly unable to surpass moderate sparsity levels (50-60%) without severely degrading model accuracy. This work breaks through the current impasse, presenting a principled and effective method called $\texttt{Elsa}$, which achieves extreme sparsity levels of up to 90% while retaining high model fidelity. This is done by identifying several limitations in current practice, all of which can be traced back to their reliance on a surrogate objective formulation. $\texttt{Elsa}$ tackles this issue directly and effectively via standard and well-established constrained optimization techniques based on ADMM. Our extensive experiments across a wide range of models and scales show that $\texttt{Elsa}$ achieves substantial improvements over existing methods; e.g., it achieves 7.8$\times$ less perplexity than the best existing method on LLaMA-2-7B at 90% sparsity. Furthermore, we present $\texttt{Elsa}_{\text{-L}}$, a quantized variant that scales to extremely large models (27B), and establish its theoretical convergence guarantees. These results highlight meaningful progress in advancing the frontier of LLM sparsity, while promising that significant opportunities for further advancement may remain in directions that have so far attracted limited exploration.
SAFE: Finding Sparse and Flat Minima to Improve Pruning
Jun 07, 2025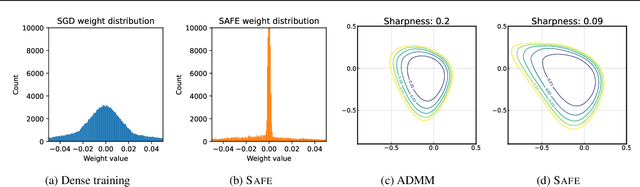
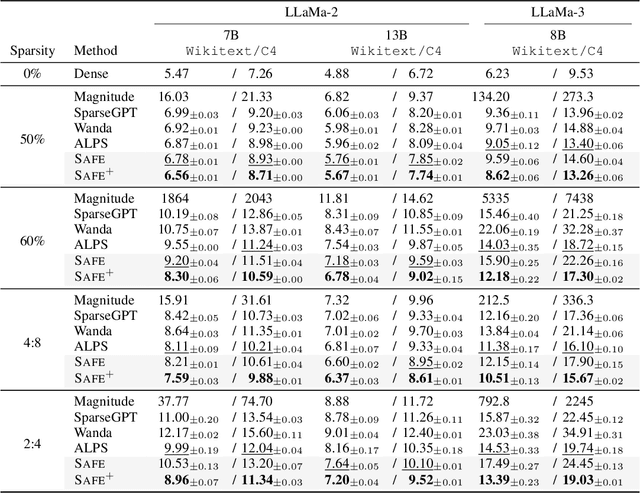
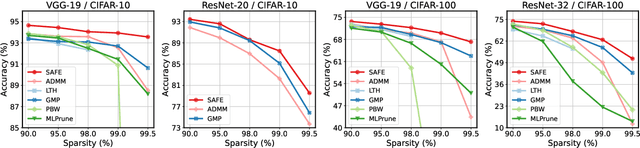
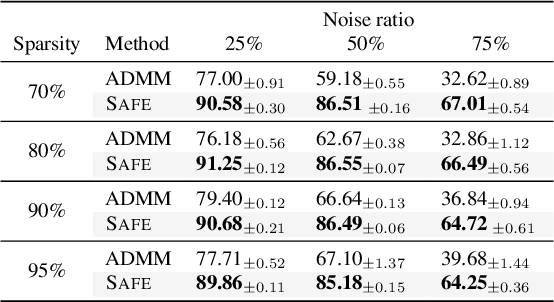
Sparsifying neural networks often suffers from seemingly inevitable performance degradation, and it remains challenging to restore the original performance despite much recent progress. Motivated by recent studies in robust optimization, we aim to tackle this problem by finding subnetworks that are both sparse and flat at the same time. Specifically, we formulate pruning as a sparsity-constrained optimization problem where flatness is encouraged as an objective. We solve it explicitly via an augmented Lagrange dual approach and extend it further by proposing a generalized projection operation, resulting in novel pruning methods called SAFE and its extension, SAFE$^+$. Extensive evaluations on standard image classification and language modeling tasks reveal that SAFE consistently yields sparse networks with improved generalization performance, which compares competitively to well-established baselines. In addition, SAFE demonstrates resilience to noisy data, making it well-suited for real-world conditions.
An Analysis of Concept Bottleneck Models: Measuring, Understanding, and Mitigating the Impact of Noisy Annotations
May 22, 2025



Concept bottleneck models (CBMs) ensure interpretability by decomposing predictions into human interpretable concepts. Yet the annotations used for training CBMs that enable this transparency are often noisy, and the impact of such corruption is not well understood. In this study, we present the first systematic study of noise in CBMs and show that even moderate corruption simultaneously impairs prediction performance, interpretability, and the intervention effectiveness. Our analysis identifies a susceptible subset of concepts whose accuracy declines far more than the average gap between noisy and clean supervision and whose corruption accounts for most performance loss. To mitigate this vulnerability we propose a two-stage framework. During training, sharpness-aware minimization stabilizes the learning of noise-sensitive concepts. During inference, where clean labels are unavailable, we rank concepts by predictive entropy and correct only the most uncertain ones, using uncertainty as a proxy for susceptibility. Theoretical analysis and extensive ablations elucidate why sharpness-aware training confers robustness and why uncertainty reliably identifies susceptible concepts, providing a principled basis that preserves both interpretability and resilience in the presence of noise.
ZIP: An Efficient Zeroth-order Prompt Tuning for Black-box Vision-Language Models
Apr 09, 2025



Recent studies have introduced various approaches for prompt-tuning black-box vision-language models, referred to as black-box prompt-tuning (BBPT). While BBPT has demonstrated considerable potential, it is often found that many existing methods require an excessive number of queries (i.e., function evaluations), which poses a significant challenge in real-world scenarios where the number of allowed queries is limited. To tackle this issue, we propose Zeroth-order Intrinsic-dimensional Prompt-tuning (ZIP), a novel approach that enables efficient and robust prompt optimization in a purely black-box setting. The key idea of ZIP is to reduce the problem dimensionality and the variance of zeroth-order gradient estimates, such that the training is done fast with far less queries. We achieve this by re-parameterizing prompts in low-rank representations and designing intrinsic-dimensional clipping of estimated gradients. We evaluate ZIP on 13+ vision-language tasks in standard benchmarks and show that it achieves an average improvement of approximately 6% in few-shot accuracy and 48% in query efficiency compared to the best-performing alternative BBPT methods, establishing a new state of the art. Our ablation analysis further shows that the proposed clipping mechanism is robust and nearly optimal, without the need to manually select the clipping threshold, matching the result of expensive hyperparameter search.
SASSHA: Sharpness-aware Adaptive Second-order Optimization with Stable Hessian Approximation
Feb 25, 2025



Approximate second-order optimization methods often exhibit poorer generalization compared to first-order approaches. In this work, we look into this issue through the lens of the loss landscape and find that existing second-order methods tend to converge to sharper minima compared to SGD. In response, we propose Sassha, a novel second-order method designed to enhance generalization by explicitly reducing sharpness of the solution, while stabilizing the computation of approximate Hessians along the optimization trajectory. In fact, this sharpness minimization scheme is crafted also to accommodate lazy Hessian updates, so as to secure efficiency besides flatness. To validate its effectiveness, we conduct a wide range of standard deep learning experiments where Sassha demonstrates its outstanding generalization performance that is comparable to, and mostly better than, other methods. We provide a comprehensive set of analyses including convergence, robustness, stability, efficiency, and cost.
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Jun 21, 2024



This work suggests fundamentally rethinking the current practice of pruning large language models (LLMs). The way it is done is by divide and conquer: split the model into submodels, sequentially prune them, and reconstruct predictions of the dense counterparts on small calibration data one at a time; the final model is obtained simply by putting the resulting sparse submodels together. While this approach enables pruning under memory constraints, it generates high reconstruction errors. In this work, we first present an array of reconstruction techniques that can significantly reduce this error by more than $90\%$. Unwittingly, however, we discover that minimizing reconstruction error is not always ideal and can overfit the given calibration data, resulting in rather increased language perplexity and poor performance at downstream tasks. We find out that a strategy of self-generating calibration data can mitigate this trade-off between reconstruction and generalization, suggesting new directions in the presence of both benefits and pitfalls of reconstruction for pruning LLMs.
The Effects of Overparameterization on Sharpness-aware Minimization: An Empirical and Theoretical Analysis
Nov 29, 2023
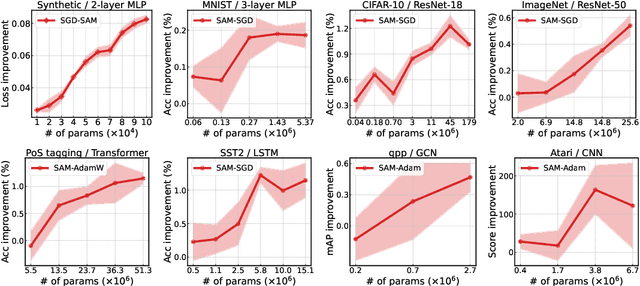
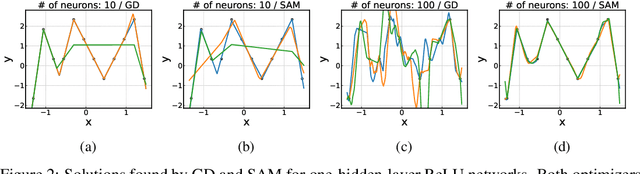

Training an overparameterized neural network can yield minimizers of the same level of training loss and yet different generalization capabilities. With evidence that indicates a correlation between sharpness of minima and their generalization errors, increasing efforts have been made to develop an optimization method to explicitly find flat minima as more generalizable solutions. This sharpness-aware minimization (SAM) strategy, however, has not been studied much yet as to how overparameterization can actually affect its behavior. In this work, we analyze SAM under varying degrees of overparameterization and present both empirical and theoretical results that suggest a critical influence of overparameterization on SAM. Specifically, we first use standard techniques in optimization to prove that SAM can achieve a linear convergence rate under overparameterization in a stochastic setting. We also show that the linearly stable minima found by SAM are indeed flatter and have more uniformly distributed Hessian moments compared to those of SGD. These results are corroborated with our experiments that reveal a consistent trend that the generalization improvement made by SAM continues to increase as the model becomes more overparameterized. We further present that sparsity can open up an avenue for effective overparameterization in practice.
FedFwd: Federated Learning without Backpropagation
Sep 03, 2023



In federated learning (FL), clients with limited resources can disrupt the training efficiency. A potential solution to this problem is to leverage a new learning procedure that does not rely on backpropagation (BP). We present a novel approach to FL called FedFwd that employs a recent BP-free method by Hinton (2022), namely the Forward Forward algorithm, in the local training process. FedFwd can reduce a significant amount of computations for updating parameters by performing layer-wise local updates, and therefore, there is no need to store all intermediate activation values during training. We conduct various experiments to evaluate FedFwd on standard datasets including MNIST and CIFAR-10, and show that it works competitively to other BP-dependent FL methods.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.