 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjDevBench: Benchmarking AI Coding Agents on End-to-End Project Development
Feb 02, 2026Recent coding agents can generate complete codebases from simple prompts, yet existing evaluations focus on issue-level bug fixing and lag behind end-to-end development. We introduce ProjDevBench, an end-to-end benchmark that provides project requirements to coding agents and evaluates the resulting repositories. Combining Online Judge (OJ) testing with LLM-assisted code review, the benchmark evaluates agents on (1) system architecture design, (2) functional correctness, and (3) iterative solution refinement. We curate 20 programming problems across 8 categories, covering both concept-oriented tasks and real-world application scenarios, and evaluate six coding agents built on different LLM backends. Our evaluation reports an overall acceptance rate of 27.38%: agents handle basic functionality and data structures but struggle with complex system design, time complexity optimization, and resource management. Our benchmark is available at https://github.com/zsworld6/projdevbench.
daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently
Feb 02, 2026While Large Language Models (LLMs) excel at short-term tasks, scaling them to long-horizon agentic workflows remains challenging. The core bottleneck lies in the scarcity of training data that captures authentic long-dependency structures and cross-stage evolutionary dynamics--existing synthesis methods either confine to single-feature scenarios constrained by model distribution, or incur prohibitive human annotation costs, failing to provide scalable, high-quality supervision. We address this by reconceptualizing data synthesis through the lens of real-world software evolution. Our key insight: Pull Request (PR) sequences naturally embody the supervision signals for long-horizon learning. They decompose complex objectives into verifiable submission units, maintain functional coherence across iterations, and encode authentic refinement patterns through bug-fix histories. Building on this, we propose daVinci-Agency, which systematically mines structured supervision from chain-of-PRs through three interlocking mechanisms: (1) progressive task decomposition via continuous commits, (2) long-term consistency enforcement through unified functional objectives, and (3) verifiable refinement from authentic bug-fix trajectories. Unlike synthetic trajectories that treat each step independently, daVinci-Agency's PR-grounded structure inherently preserves the causal dependencies and iterative refinements essential for teaching persistent goal-directed behavior and enables natural alignment with project-level, full-cycle task modeling. The resulting trajectories are substantial--averaging 85k tokens and 116 tool calls--yet remarkably data-efficient: fine-tuning GLM-4.6 on 239 daVinci-Agency samples yields broad improvements across benchmarks, notably achieving a 47% relative gain on Toolathlon. Beyond benchmark performance, our analysis confirms...
What Does Vision Tool-Use Reinforcement Learning Really Learn? Disentangling Tool-Induced and Intrinsic Effects for Crop-and-Zoom
Feb 01, 2026Vision tool-use reinforcement learning (RL) can equip vision-language models with visual operators such as crop-and-zoom and achieves strong performance gains, yet it remains unclear whether these gains are driven by improvements in tool use or evolving intrinsic capabilities.We introduce MED (Measure-Explain-Diagnose), a coarse-to-fine framework that disentangles intrinsic capability changes from tool-induced effects, decomposes the tool-induced performance difference into gain and harm terms, and probes the mechanisms driving their evolution. Across checkpoint-level analyses on two VLMs with different tool priors and six benchmarks, we find that improvements are dominated by intrinsic learning, while tool-use RL mainly reduces tool-induced harm (e.g., fewer call-induced errors and weaker tool schema interference) and yields limited progress in tool-based correction of intrinsic failures. Overall, current vision tool-use RL learns to coexist safely with tools rather than master them.
daVinci-Dev: Agent-native Mid-training for Software Engineering
Jan 27, 2026Recently, the frontier of Large Language Model (LLM) capabilities has shifted from single-turn code generation to agentic software engineering-a paradigm where models autonomously navigate, edit, and test complex repositories. While post-training methods have become the de facto approach for code agents, **agentic mid-training**-mid-training (MT) on large-scale data that mirrors authentic agentic workflows-remains critically underexplored due to substantial resource requirements, despite offering a more scalable path to instilling foundational agentic behaviors than relying solely on expensive reinforcement learning. A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development. To address this, we present a systematic study of agentic mid-training, establishing both the data synthesis principles and training methodology for effective agent development at scale. Central to our approach is **agent-native data**-supervision comprising two complementary types of trajectories: **contextually-native trajectories** that preserve the complete information flow an agent experiences, offering broad coverage and diversity; and **environmentally-native trajectories** collected from executable repositories where observations stem from actual tool invocations and test executions, providing depth and interaction authenticity. We verify the model's agentic capabilities on `SWE-Bench Verified`. We demonstrate our superiority over the previous open software engineering mid-training recipe `Kimi-Dev` under two post-training settings with an aligned base model and agentic scaffold, while using less than half mid-training tokens (73.1B). Besides relative advantage, our best performing 32B and 72B models achieve **56.1%** and **58.5%** resolution rates, respectively, which are ...
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Jan 16, 2026Large Language Models (LLMs) based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.
One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling
Jan 06, 2026The reasoning ability of large language models (LLMs) can be unleashed with reinforcement learning (RL) (OpenAI, 2024; DeepSeek-AI et al., 2025a; Zeng et al., 2025). The success of existing RL attempts in LLMs usually relies on high-quality samples of thousands or beyond. In this paper, we challenge fundamental assumptions about data requirements in RL for LLMs by demonstrating the remarkable effectiveness of one-shot learning. Specifically, we introduce polymath learning, a framework for designing one training sample that elicits multidisciplinary impact. We present three key findings: (1) A single, strategically selected math reasoning sample can produce significant performance improvements across multiple domains, including physics, chemistry, and biology with RL; (2) The math skills salient to reasoning suggest the characteristics of the optimal polymath sample; and (3) An engineered synthetic sample that integrates multidiscipline elements outperforms training with individual samples that naturally occur. Our approach achieves superior performance to training with larger datasets across various reasoning benchmarks, demonstrating that sample quality and design, rather than quantity, may be the key to unlock enhanced reasoning capabilities in language models. Our results suggest a shift, dubbed as sample engineering, toward precision engineering of training samples rather than simply increasing data volume.
LiveTalk: Real-Time Multimodal Interactive Video Diffusion via Improved On-Policy Distillation
Dec 29, 2025Real-time video generation via diffusion is essential for building general-purpose multimodal interactive AI systems. However, the simultaneous denoising of all video frames with bidirectional attention via an iterative process in diffusion models prevents real-time interaction. While existing distillation methods can make the model autoregressive and reduce sampling steps to mitigate this, they focus primarily on text-to-video generation, leaving the human-AI interaction unnatural and less efficient. This paper targets real-time interactive video diffusion conditioned on a multimodal context, including text, image, and audio, to bridge the gap. Given the observation that the leading on-policy distillation approach Self Forcing encounters challenges (visual artifacts like flickering, black frames, and quality degradation) with multimodal conditioning, we investigate an improved distillation recipe with emphasis on the quality of condition inputs as well as the initialization and schedule for the on-policy optimization. On benchmarks for multimodal-conditioned (audio, image, and text) avatar video generation including HDTF, AVSpeech, and CelebV-HQ, our distilled model matches the visual quality of the full-step, bidirectional baselines of similar or larger size with 20x less inference cost and latency. Further, we integrate our model with audio language models and long-form video inference technique Anchor-Heavy Identity Sinks to build LiveTalk, a real-time multimodal interactive avatar system. System-level evaluation on our curated multi-turn interaction benchmark shows LiveTalk outperforms state-of-the-art models (Sora2, Veo3) in multi-turn video coherence and content quality, while reducing response latency from 1 to 2 minutes to real-time generation, enabling seamless human-AI multimodal interaction.
GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
Nov 19, 2025Current research on agentic visual reasoning enables deep multimodal understanding but primarily focuses on image manipulation tools, leaving a gap toward more general-purpose agentic models. In this work, we revisit the geolocalization task, which requires not only nuanced visual grounding but also web search to confirm or refine hypotheses during reasoning. Since existing geolocalization benchmarks fail to meet the need for high-resolution imagery and the localization challenge for deep agentic reasoning, we curate GeoBench, a benchmark that includes photos and panoramas from around the world, along with a subset of satellite images of different cities to rigorously evaluate the geolocalization ability of agentic models. We also propose GeoVista, an agentic model that seamlessly integrates tool invocation within the reasoning loop, including an image-zoom-in tool to magnify regions of interest and a web-search tool to retrieve related web information. We develop a complete training pipeline for it, including a cold-start supervised fine-tuning (SFT) stage to learn reasoning patterns and tool-use priors, followed by a reinforcement learning (RL) stage to further enhance reasoning ability. We adopt a hierarchical reward to leverage multi-level geographical information and improve overall geolocalization performance. Experimental results show that GeoVista surpasses other open-source agentic models on the geolocalization task greatly and achieves performance comparable to closed-source models such as Gemini-2.5-flash and GPT-5 on most metrics.
InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research
Nov 03, 2025
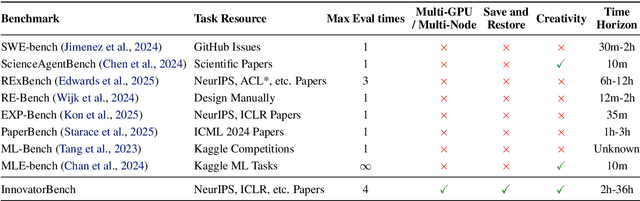


AI agents could accelerate scientific discovery by automating hypothesis formation, experiment design, coding, execution, and analysis, yet existing benchmarks probe narrow skills in simplified settings. To address this gap, we introduce InnovatorBench, a benchmark-platform pair for realistic, end-to-end assessment of agents performing Large Language Model (LLM) research. It comprises 20 tasks spanning Data Construction, Filtering, Augmentation, Loss Design, Reward Design, and Scaffold Construction, which require runnable artifacts and assessment of correctness, performance, output quality, and uncertainty. To support agent operation, we develop ResearchGym, a research environment offering rich action spaces, distributed and long-horizon execution, asynchronous monitoring, and snapshot saving. We also implement a lightweight ReAct agent that couples explicit reasoning with executable planning using frontier models such as Claude-4, GPT-5, GLM-4.5, and Kimi-K2. Our experiments demonstrate that while frontier models show promise in code-driven research tasks, they struggle with fragile algorithm-related tasks and long-horizon decision making, such as impatience, poor resource management, and overreliance on template-based reasoning. Furthermore, agents require over 11 hours to achieve their best performance on InnovatorBench, underscoring the benchmark's difficulty and showing the potential of InnovatorBench to be the next generation of code-based research benchmark.
Interaction as Intelligence Part II: Asynchronous Human-Agent Rollout for Long-Horizon Task Training
Nov 03, 2025Large Language Model (LLM) agents have recently shown strong potential in domains such as automated coding, deep research, and graphical user interface manipulation. However, training them to succeed on long-horizon, domain-specialized tasks remains challenging. Current methods primarily fall into two categories. The first relies on dense human annotations through behavior cloning, which is prohibitively expensive for long-horizon tasks that can take days or months. The second depends on outcome-driven sampling, which often collapses due to the rarity of valid positive trajectories on domain-specialized tasks. We introduce Apollo, a sampling framework that integrates asynchronous human guidance with action-level data filtering. Instead of requiring annotators to shadow every step, Apollo allows them to intervene only when the agent drifts from a promising trajectory, by providing prior knowledge, strategic advice, etc. This lightweight design makes it possible to sustain interactions for over 30 hours and produces valuable trajectories at a lower cost. Apollo then applies supervision control to filter out sub-optimal actions and prevent error propagation. Together, these components enable reliable and effective data collection in long-horizon environments. To demonstrate the effectiveness of Apollo, we evaluate it using InnovatorBench. Our experiments show that when applied to train the GLM-4.5 model on InnovatorBench, Apollo achieves more than a 50% improvement over the untrained baseline and a 28% improvement over a variant trained without human interaction. These results highlight the critical role of human-in-the-loop sampling and the robustness of Apollo's design in handling long-horizon, domain-specialized tasks.