 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubrics to Tokens: Bridging Response-level Rubrics and Token-level Rewards in Instruction Following Tasks
Apr 03, 2026Rubric-based Reinforcement Learning (RL) has emerged as a promising approach for aligning Large Language Models (LLMs) with complex, open-domain instruction following tasks. However, existing methods predominantly rely on response-level rewards, introducing severe reward sparsity and reward ambiguity problems. To address these issues, we propose Rubrics to Tokens (RTT), a novel rubric-based RL framework that bridges coarse response-level scores and fine-grained token-level credit assignment. RTT introduces a Token-Level Relevance Discriminator to predict which tokens in the response are responsible for a specific constraint, and optimizes the policy model via RTT-GRPO, which integrates response-level and token-level advantages within a unified framework. Furthermore, when transitioning from one-dimensional, outcome-level reward to three-dimensional reward space in the token-level rubric-based RL, we propose a novel group normalization method, called Intra-sample Token Group Normalization, to accommodate this shift. Extensive experiments and benchmarks demonstrate that RTT consistently outperforms other baselines in both instruction- and rubric-level accuracy across different models.
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Jan 16, 2026Large Language Models (LLMs) based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.
Interaction as Intelligence Part II: Asynchronous Human-Agent Rollout for Long-Horizon Task Training
Nov 03, 2025Large Language Model (LLM) agents have recently shown strong potential in domains such as automated coding, deep research, and graphical user interface manipulation. However, training them to succeed on long-horizon, domain-specialized tasks remains challenging. Current methods primarily fall into two categories. The first relies on dense human annotations through behavior cloning, which is prohibitively expensive for long-horizon tasks that can take days or months. The second depends on outcome-driven sampling, which often collapses due to the rarity of valid positive trajectories on domain-specialized tasks. We introduce Apollo, a sampling framework that integrates asynchronous human guidance with action-level data filtering. Instead of requiring annotators to shadow every step, Apollo allows them to intervene only when the agent drifts from a promising trajectory, by providing prior knowledge, strategic advice, etc. This lightweight design makes it possible to sustain interactions for over 30 hours and produces valuable trajectories at a lower cost. Apollo then applies supervision control to filter out sub-optimal actions and prevent error propagation. Together, these components enable reliable and effective data collection in long-horizon environments. To demonstrate the effectiveness of Apollo, we evaluate it using InnovatorBench. Our experiments show that when applied to train the GLM-4.5 model on InnovatorBench, Apollo achieves more than a 50% improvement over the untrained baseline and a 28% improvement over a variant trained without human interaction. These results highlight the critical role of human-in-the-loop sampling and the robustness of Apollo's design in handling long-horizon, domain-specialized tasks.
InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research
Nov 03, 2025
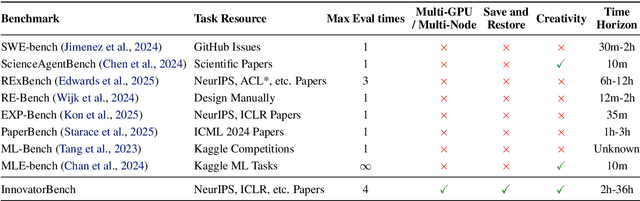


AI agents could accelerate scientific discovery by automating hypothesis formation, experiment design, coding, execution, and analysis, yet existing benchmarks probe narrow skills in simplified settings. To address this gap, we introduce InnovatorBench, a benchmark-platform pair for realistic, end-to-end assessment of agents performing Large Language Model (LLM) research. It comprises 20 tasks spanning Data Construction, Filtering, Augmentation, Loss Design, Reward Design, and Scaffold Construction, which require runnable artifacts and assessment of correctness, performance, output quality, and uncertainty. To support agent operation, we develop ResearchGym, a research environment offering rich action spaces, distributed and long-horizon execution, asynchronous monitoring, and snapshot saving. We also implement a lightweight ReAct agent that couples explicit reasoning with executable planning using frontier models such as Claude-4, GPT-5, GLM-4.5, and Kimi-K2. Our experiments demonstrate that while frontier models show promise in code-driven research tasks, they struggle with fragile algorithm-related tasks and long-horizon decision making, such as impatience, poor resource management, and overreliance on template-based reasoning. Furthermore, agents require over 11 hours to achieve their best performance on InnovatorBench, underscoring the benchmark's difficulty and showing the potential of InnovatorBench to be the next generation of code-based research benchmark.
Mozart's Touch: A Lightweight Multi-modal Music Generation Framework Based on Pre-Trained Large Models
May 07, 2024



In recent years, AI-Generated Content (AIGC) has witnessed rapid advancements, facilitating the generation of music, images, and other forms of artistic expression across various industries. However, researches on general multi-modal music generation model remain scarce. To fill this gap, we propose a multi-modal music generation framework Mozart's Touch. It could generate aligned music with the cross-modality inputs, such as images, videos and text. Mozart's Touch is composed of three main components: Multi-modal Captioning Module, Large Language Model (LLM) Understanding & Bridging Module, and Music Generation Module. Unlike traditional approaches, Mozart's Touch requires no training or fine-tuning pre-trained models, offering efficiency and transparency through clear, interpretable prompts. We also introduce "LLM-Bridge" method to resolve the heterogeneous representation problems between descriptive texts of different modalities. We conduct a series of objective and subjective evaluations on the proposed model, and results indicate that our model surpasses the performance of current state-of-the-art models. Our codes and examples is availble at: https://github.com/WangTooNaive/MozartsTouch