 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research
Nov 03, 2025
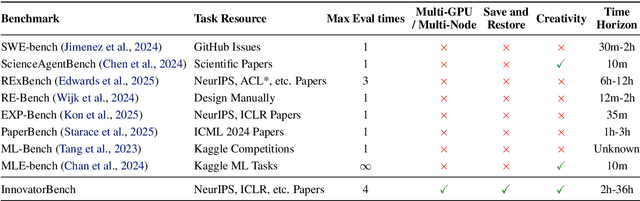


AI agents could accelerate scientific discovery by automating hypothesis formation, experiment design, coding, execution, and analysis, yet existing benchmarks probe narrow skills in simplified settings. To address this gap, we introduce InnovatorBench, a benchmark-platform pair for realistic, end-to-end assessment of agents performing Large Language Model (LLM) research. It comprises 20 tasks spanning Data Construction, Filtering, Augmentation, Loss Design, Reward Design, and Scaffold Construction, which require runnable artifacts and assessment of correctness, performance, output quality, and uncertainty. To support agent operation, we develop ResearchGym, a research environment offering rich action spaces, distributed and long-horizon execution, asynchronous monitoring, and snapshot saving. We also implement a lightweight ReAct agent that couples explicit reasoning with executable planning using frontier models such as Claude-4, GPT-5, GLM-4.5, and Kimi-K2. Our experiments demonstrate that while frontier models show promise in code-driven research tasks, they struggle with fragile algorithm-related tasks and long-horizon decision making, such as impatience, poor resource management, and overreliance on template-based reasoning. Furthermore, agents require over 11 hours to achieve their best performance on InnovatorBench, underscoring the benchmark's difficulty and showing the potential of InnovatorBench to be the next generation of code-based research benchmark.
Context Engineering 2.0: The Context of Context Engineering
Oct 30, 2025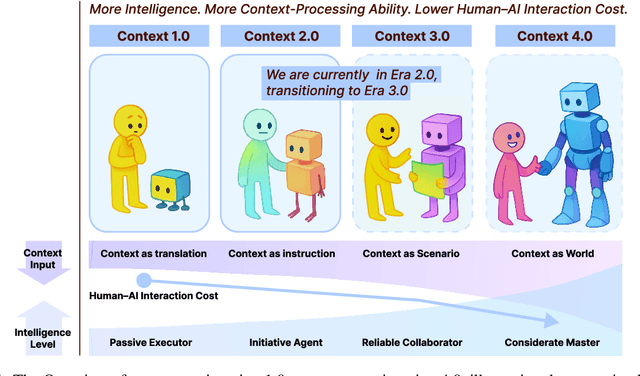
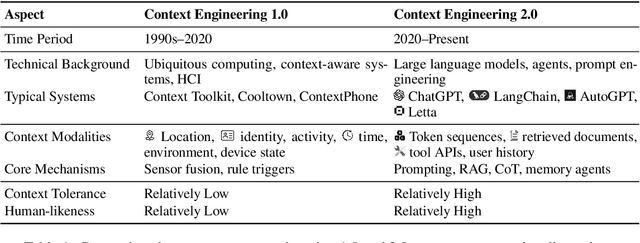
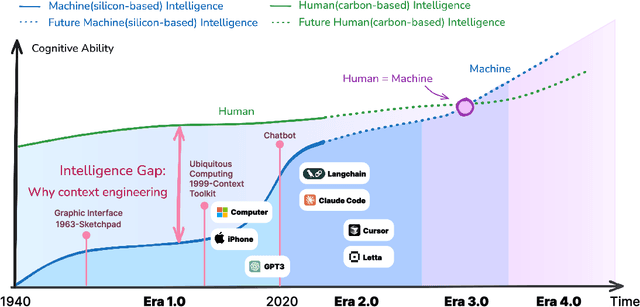
Karl Marx once wrote that ``the human essence is the ensemble of social relations'', suggesting that individuals are not isolated entities but are fundamentally shaped by their interactions with other entities, within which contexts play a constitutive and essential role. With the advent of computers and artificial intelligence, these contexts are no longer limited to purely human--human interactions: human--machine interactions are included as well. Then a central question emerges: How can machines better understand our situations and purposes? To address this challenge, researchers have recently introduced the concept of context engineering. Although it is often regarded as a recent innovation of the agent era, we argue that related practices can be traced back more than twenty years. Since the early 1990s, the field has evolved through distinct historical phases, each shaped by the intelligence level of machines: from early human--computer interaction frameworks built around primitive computers, to today's human--agent interaction paradigms driven by intelligent agents, and potentially to human--level or superhuman intelligence in the future. In this paper, we situate context engineering, provide a systematic definition, outline its historical and conceptual landscape, and examine key design considerations for practice. By addressing these questions, we aim to offer a conceptual foundation for context engineering and sketch its promising future. This paper is a stepping stone for a broader community effort toward systematic context engineering in AI systems.
Visual Programmability: A Guide for Code-as-Thought in Chart Understanding
Sep 11, 2025Chart understanding presents a critical test to the reasoning capabilities of Vision-Language Models (VLMs). Prior approaches face critical limitations: some rely on external tools, making them brittle and constrained by a predefined toolkit, while others fine-tune specialist models that often adopt a single reasoning strategy, such as text-based chain-of-thought (CoT). The intermediate steps of text-based reasoning are difficult to verify, which complicates the use of reinforcement-learning signals that reward factual accuracy. To address this, we propose a Code-as-Thought (CaT) approach to represent the visual information of a chart in a verifiable, symbolic format. Our key insight is that this strategy must be adaptive: a fixed, code-only implementation consistently fails on complex charts where symbolic representation is unsuitable. This finding leads us to introduce Visual Programmability: a learnable property that determines if a chart-question pair is better solved with code or direct visual analysis. We implement this concept in an adaptive framework where a VLM learns to choose between the CaT pathway and a direct visual reasoning pathway. The selection policy of the model is trained with reinforcement learning using a novel dual-reward system. This system combines a data-accuracy reward to ground the model in facts and prevent numerical hallucination, with a decision reward that teaches the model when to use each strategy, preventing it from defaulting to a single reasoning mode. Experiments demonstrate strong and robust performance across diverse chart-understanding benchmarks. Our work shows that VLMs can be taught not only to reason but also how to reason, dynamically selecting the optimal reasoning pathway for each task.
Proximal Supervised Fine-Tuning
Aug 25, 2025



Supervised fine-tuning (SFT) of foundation models often leads to poor generalization, where prior capabilities deteriorate after tuning on new tasks or domains. Inspired by trust-region policy optimization (TRPO) and proximal policy optimization (PPO) in reinforcement learning (RL), we propose Proximal SFT (PSFT). This fine-tuning objective incorporates the benefits of trust-region, effectively constraining policy drift during SFT while maintaining competitive tuning. By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains show that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
DatasetResearch: Benchmarking Agent Systems for Demand-Driven Dataset Discovery
Aug 09, 2025The rapid advancement of large language models has fundamentally shifted the bottleneck in AI development from computational power to data availability-with countless valuable datasets remaining hidden across specialized repositories, research appendices, and domain platforms. As reasoning capabilities and deep research methodologies continue to evolve, a critical question emerges: can AI agents transcend conventional search to systematically discover any dataset that meets specific user requirements, enabling truly autonomous demand-driven data curation? We introduce DatasetResearch, the first comprehensive benchmark evaluating AI agents' ability to discover and synthesize datasets from 208 real-world demands across knowledge-intensive and reasoning-intensive tasks. Our tri-dimensional evaluation framework reveals a stark reality: even advanced deep research systems achieve only 22% score on our challenging DatasetResearch-pro subset, exposing the vast gap between current capabilities and perfect dataset discovery. Our analysis uncovers a fundamental dichotomy-search agents excel at knowledge tasks through retrieval breadth, while synthesis agents dominate reasoning challenges via structured generation-yet both catastrophically fail on "corner cases" outside existing distributions. These findings establish the first rigorous baseline for dataset discovery agents and illuminate the path toward AI systems capable of finding any dataset in the digital universe. Our benchmark and comprehensive analysis provide the foundation for the next generation of self-improving AI systems and are publicly available at https://github.com/GAIR-NLP/DatasetResearch.
AlphaGo Moment for Model Architecture Discovery
Jul 24, 2025
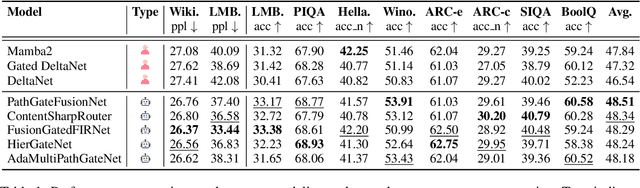
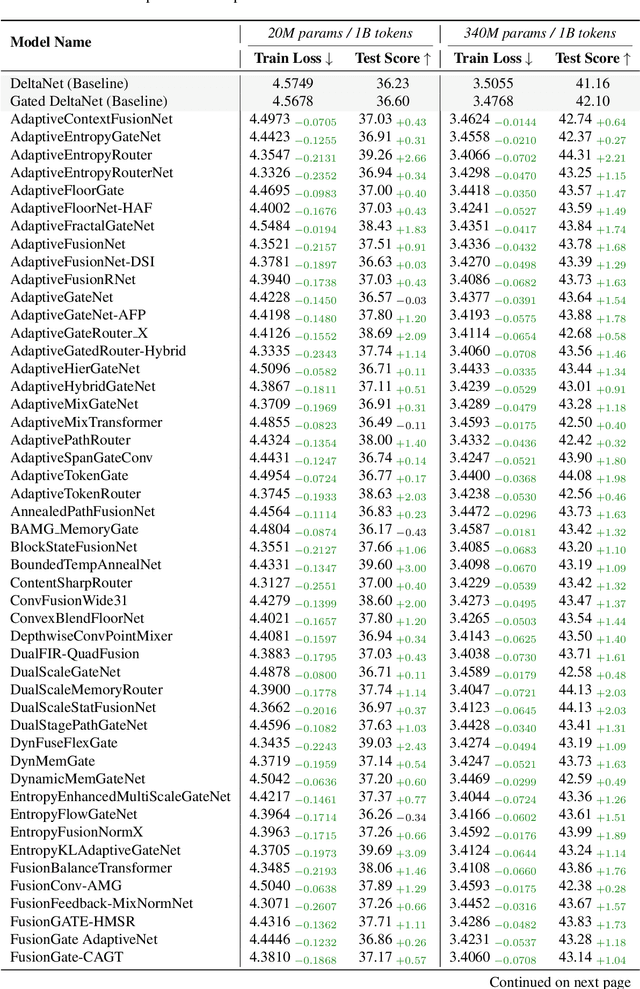

While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bottleneck. We present ASI-Arch, the first demonstration of Artificial Superintelligence for AI research (ASI4AI) in the critical domain of neural architecture discovery--a fully autonomous system that shatters this fundamental constraint by enabling AI to conduct its own architectural innovation. Moving beyond traditional Neural Architecture Search (NAS), which is fundamentally limited to exploring human-defined spaces, we introduce a paradigm shift from automated optimization to automated innovation. ASI-Arch can conduct end-to-end scientific research in the domain of architecture discovery, autonomously hypothesizing novel architectural concepts, implementing them as executable code, training and empirically validating their performance through rigorous experimentation and past experience. ASI-Arch conducted 1,773 autonomous experiments over 20,000 GPU hours, culminating in the discovery of 106 innovative, state-of-the-art (SOTA) linear attention architectures. Like AlphaGo's Move 37 that revealed unexpected strategic insights invisible to human players, our AI-discovered architectures demonstrate emergent design principles that systematically surpass human-designed baselines and illuminate previously unknown pathways for architectural innovation. Crucially, we establish the first empirical scaling law for scientific discovery itself--demonstrating that architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process. We provide comprehensive analysis of the emergent design patterns and autonomous research capabilities that enabled these breakthroughs, establishing a blueprint for self-accelerating AI systems.
MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning
Jul 22, 2025



Scientific reasoning is critical for developing AI scientists and supporting human researchers in advancing the frontiers of natural science discovery. However, the open-source community has primarily focused on mathematics and coding while neglecting the scientific domain, largely due to the absence of open, large-scale, high-quality, verifiable scientific reasoning datasets. To bridge this gap, we first present TextbookReasoning, an open dataset featuring truthful reference answers extracted from 12k university-level scientific textbooks, comprising 650k reasoning questions spanning 7 scientific disciplines. We further introduce MegaScience, a large-scale mixture of high-quality open-source datasets totaling 1.25 million instances, developed through systematic ablation studies that evaluate various data selection methodologies to identify the optimal subset for each publicly available scientific dataset. Meanwhile, we build a comprehensive evaluation system covering diverse subjects and question types across 15 benchmarks, incorporating comprehensive answer extraction strategies to ensure accurate evaluation metrics. Our experiments demonstrate that our datasets achieve superior performance and training efficiency with more concise response lengths compared to existing open-source scientific datasets. Furthermore, we train Llama3.1, Qwen2.5, and Qwen3 series base models on MegaScience, which significantly outperform the corresponding official instruct models in average performance. In addition, MegaScience exhibits greater effectiveness for larger and stronger models, suggesting a scaling benefit for scientific tuning. We release our data curation pipeline, evaluation system, datasets, and seven trained models to the community to advance scientific reasoning research.
Thinking with Generated Images
May 28, 2025We present Thinking with Generated Images, a novel paradigm that fundamentally transforms how large multimodal models (LMMs) engage with visual reasoning by enabling them to natively think across text and vision modalities through spontaneous generation of intermediate visual thinking steps. Current visual reasoning with LMMs is constrained to either processing fixed user-provided images or reasoning solely through text-based chain-of-thought (CoT). Thinking with Generated Images unlocks a new dimension of cognitive capability where models can actively construct intermediate visual thoughts, critique their own visual hypotheses, and refine them as integral components of their reasoning process. We demonstrate the effectiveness of our approach through two complementary mechanisms: (1) vision generation with intermediate visual subgoals, where models decompose complex visual tasks into manageable components that are generated and integrated progressively, and (2) vision generation with self-critique, where models generate an initial visual hypothesis, analyze its shortcomings through textual reasoning, and produce refined outputs based on their own critiques. Our experiments on vision generation benchmarks show substantial improvements over baseline approaches, with our models achieving up to 50% (from 38% to 57%) relative improvement in handling complex multi-object scenarios. From biochemists exploring novel protein structures, and architects iterating on spatial designs, to forensic analysts reconstructing crime scenes, and basketball players envisioning strategic plays, our approach enables AI models to engage in the kind of visual imagination and iterative refinement that characterizes human creative, analytical, and strategic thinking. We release our open-source suite at https://github.com/GAIR-NLP/thinking-with-generated-images.
LIMOPro: Reasoning Refinement for Efficient and Effective Test-time Scaling
May 25, 2025Large language models (LLMs) have demonstrated remarkable reasoning capabilities through test-time scaling approaches, particularly when fine-tuned with chain-of-thought (CoT) data distilled from more powerful large reasoning models (LRMs). However, these reasoning chains often contain verbose elements that mirror human problem-solving, categorized as progressive reasoning (the essential solution development path) and functional elements (verification processes, alternative solution approaches, and error corrections). While progressive reasoning is crucial, the functional elements significantly increase computational demands during test-time inference. We introduce PIR (Perplexity-based Importance Refinement), a principled framework that quantitatively evaluates the importance of each reasoning step based on its impact on answer prediction confidence. PIR systematically identifies and selectively prunes only low-importance functional steps while preserving progressive reasoning components, creating optimized training data that maintains the integrity of the core solution path while reducing verbosity. Models fine-tuned on PIR-optimized data exhibit superior test-time scaling properties, generating more concise reasoning chains while achieving improved accuracy (+0.9\% to +6.6\%) with significantly reduced token usage (-3\% to -41\%) across challenging reasoning benchmarks (AIME, AMC, and GPQA Diamond). Our approach demonstrates strong generalizability across different model sizes, data sources, and token budgets, offering a practical solution for deploying reasoning-capable LLMs in scenarios where efficient test-time scaling, response time, and computational efficiency are valuable constraints.
One RL to See Them All: Visual Triple Unified Reinforcement Learning
May 23, 2025



Reinforcement learning (RL) has significantly advanced the reasoning capabilities of vision-language models (VLMs). However, the use of RL beyond reasoning tasks remains largely unexplored, especially for perceptionintensive tasks like object detection and grounding. We propose V-Triune, a Visual Triple Unified Reinforcement Learning system that enables VLMs to jointly learn visual reasoning and perception tasks within a single training pipeline. V-Triune comprises triple complementary components: Sample-Level Data Formatting (to unify diverse task inputs), Verifier-Level Reward Computation (to deliver custom rewards via specialized verifiers) , and Source-Level Metric Monitoring (to diagnose problems at the data-source level). We further introduce a novel Dynamic IoU reward, which provides adaptive, progressive, and definite feedback for perception tasks handled by V-Triune. Our approach is instantiated within off-the-shelf RL training framework using open-source 7B and 32B backbone models. The resulting model, dubbed Orsta (One RL to See Them All), demonstrates consistent improvements across both reasoning and perception tasks. This broad capability is significantly shaped by its training on a diverse dataset, constructed around four representative visual reasoning tasks (Math, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and OCR). Subsequently, Orsta achieves substantial gains on MEGA-Bench Core, with improvements ranging from +2.1 to an impressive +14.1 across its various 7B and 32B model variants, with performance benefits extending to a wide range of downstream tasks. These results highlight the effectiveness and scalability of our unified RL approach for VLMs. The V-Triune system, along with the Orsta models, is publicly available at https://github.com/MiniMax-AI.