 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEVEE: Towards Test-time Prompt Learning in the Real World for Self-Improving Agents
Jun 09, 2026In this paper, we propose EEVEE, the first multi-dataset test-time prompt learning framework for LLM agents, enabling test-time prompt learning under real-world task streams. Existing methods are largely designed for single-dataset settings, while real-world applications require models to handle heterogeneous input streams drawn from multiple datasets, domains, and task distributions, limiting their practical applicability. To mitigate cross-dataset interference, EEVEE introduces a router that partitions incoming inputs into task clusters and assigns them to suitable prompt configurations. This design is optimized via a router-prompt co-evolution strategy, which employs interleaved router and prompt learning phases to address their mutual dependency. Experiments across multiple datasets demonstrate that the framework improves robustness under heterogeneous data streams while maintaining single-benchmark learning capability and efficiency. Specifically, EEVEE improves average multi-benchmark scores by 10.38 and 24.32 points over Qwen3-4B-Instruct and DeepSeek-V3.2, surpassing SOTA methods GEPA and ACE by up to 37.2% and 48.2%.
ASI-Evolve: AI Accelerates AI
Mar 31, 2026Can AI accelerate the development of AI itself? While recent agentic systems have shown strong performance on well-scoped tasks with rapid feedback, it remains unclear whether they can tackle the costly, long-horizon, and weakly supervised research loops that drive real AI progress. We present ASI-Evolve, an agentic framework for AI-for-AI research that closes this loop through a learn-design-experiment-analyze cycle. ASI-Evolve augments standard evolutionary agents with two key components: a cognition base that injects accumulated human priors into each round of exploration, and a dedicated analyzer that distills complex experimental outcomes into reusable insights for future iterations. To our knowledge, ASI-Evolve is the first unified framework to demonstrate AI-driven discovery across three central components of AI development: data, architectures, and learning algorithms. In neural architecture design, it discovered 105 SOTA linear attention architectures, with the best discovered model surpassing DeltaNet by +0.97 points, nearly 3x the gain of recent human-designed improvements. In pretraining data curation, the evolved pipeline improves average benchmark performance by +3.96 points, with gains exceeding 18 points on MMLU. In reinforcement learning algorithm design, discovered algorithms outperform GRPO by up to +12.5 points on AMC32, +11.67 points on AIME24, and +5.04 points on OlympiadBench. We further provide initial evidence that this AI-for-AI paradigm can transfer beyond the AI stack through experiments in mathematics and biomedicine. Together, these results suggest that ASI-Evolve represents a promising step toward enabling AI to accelerate AI across the foundational stages of development, offering early evidence for the feasibility of closed-loop AI research.
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
AlphaGo Moment for Model Architecture Discovery
Jul 24, 2025
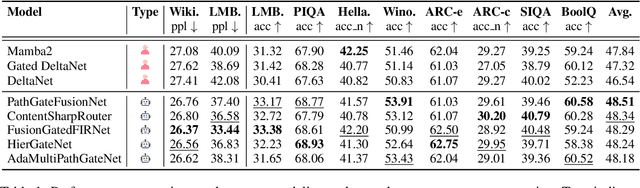
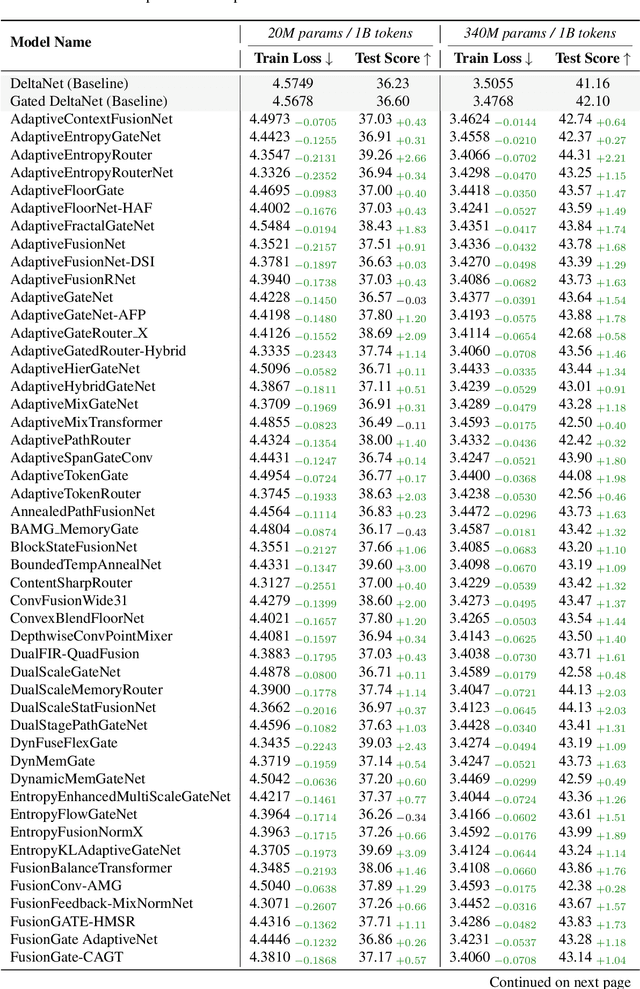

While AI systems demonstrate exponentially improving capabilities, the pace of AI research itself remains linearly bounded by human cognitive capacity, creating an increasingly severe development bottleneck. We present ASI-Arch, the first demonstration of Artificial Superintelligence for AI research (ASI4AI) in the critical domain of neural architecture discovery--a fully autonomous system that shatters this fundamental constraint by enabling AI to conduct its own architectural innovation. Moving beyond traditional Neural Architecture Search (NAS), which is fundamentally limited to exploring human-defined spaces, we introduce a paradigm shift from automated optimization to automated innovation. ASI-Arch can conduct end-to-end scientific research in the domain of architecture discovery, autonomously hypothesizing novel architectural concepts, implementing them as executable code, training and empirically validating their performance through rigorous experimentation and past experience. ASI-Arch conducted 1,773 autonomous experiments over 20,000 GPU hours, culminating in the discovery of 106 innovative, state-of-the-art (SOTA) linear attention architectures. Like AlphaGo's Move 37 that revealed unexpected strategic insights invisible to human players, our AI-discovered architectures demonstrate emergent design principles that systematically surpass human-designed baselines and illuminate previously unknown pathways for architectural innovation. Crucially, we establish the first empirical scaling law for scientific discovery itself--demonstrating that architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process. We provide comprehensive analysis of the emergent design patterns and autonomous research capabilities that enabled these breakthroughs, establishing a blueprint for self-accelerating AI systems.