 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolvingGrasp: Evolutionary Grasp Generation via Efficient Preference Alignment
Mar 19, 2025



Dexterous robotic hands often struggle to generalize effectively in complex environments due to the limitations of models trained on low-diversity data. However, the real world presents an inherently unbounded range of scenarios, making it impractical to account for every possible variation. A natural solution is to enable robots learning from experience in complex environments, an approach akin to evolution, where systems improve through continuous feedback, learning from both failures and successes, and iterating toward optimal performance. Motivated by this, we propose EvolvingGrasp, an evolutionary grasp generation method that continuously enhances grasping performance through efficient preference alignment. Specifically, we introduce Handpose wise Preference Optimization (HPO), which allows the model to continuously align with preferences from both positive and negative feedback while progressively refining its grasping strategies. To further enhance efficiency and reliability during online adjustments, we incorporate a Physics-aware Consistency Model within HPO, which accelerates inference, reduces the number of timesteps needed for preference finetuning, and ensures physical plausibility throughout the process. Extensive experiments across four benchmark datasets demonstrate state of the art performance of our method in grasp success rate and sampling efficiency. Our results validate that EvolvingGrasp enables evolutionary grasp generation, ensuring robust, physically feasible, and preference-aligned grasping in both simulation and real scenarios.
SemGeoMo: Dynamic Contextual Human Motion Generation with Semantic and Geometric Guidance
Mar 03, 2025



Generating reasonable and high-quality human interactive motions in a given dynamic environment is crucial for understanding, modeling, transferring, and applying human behaviors to both virtual and physical robots. In this paper, we introduce an effective method, SemGeoMo, for dynamic contextual human motion generation, which fully leverages the text-affordance-joint multi-level semantic and geometric guidance in the generation process, improving the semantic rationality and geometric correctness of generative motions. Our method achieves state-of-the-art performance on three datasets and demonstrates superior generalization capability for diverse interaction scenarios. The project page and code can be found at https://4dvlab.github.io/project_page/semgeomo/.
SymbioSim: Human-in-the-loop Simulation Platform for Bidirectional Continuing Learning in Human-Robot Interaction
Feb 11, 2025The development of intelligent robots seeks to seamlessly integrate them into the human world, providing assistance and companionship in daily life and work, with the ultimate goal of achieving human-robot symbiosis. To realize this vision, robots must continuously learn and evolve through consistent interaction and collaboration with humans, while humans need to gradually develop an understanding of and trust in robots through shared experiences. However, training and testing algorithms directly on physical robots involve substantial costs and safety risks. Moreover, current robotic simulators fail to support real human participation, limiting their ability to provide authentic interaction experiences and gather valuable human feedback. In this paper, we introduce SymbioSim, a novel human-in-the-loop robotic simulation platform designed to enable the safe and efficient development, evaluation, and optimization of human-robot interactions. By leveraging a carefully designed system architecture and modules, SymbioSim delivers a natural and realistic interaction experience, facilitating bidirectional continuous learning and adaptation for both humans and robots. Extensive experiments and user studies demonstrate the platform's promising performance and highlight its potential to significantly advance research on human-robot symbiosis.
LaserHuman: Language-guided Scene-aware Human Motion Generation in Free Environment
Mar 21, 2024Language-guided scene-aware human motion generation has great significance for entertainment and robotics. In response to the limitations of existing datasets, we introduce LaserHuman, a pioneering dataset engineered to revolutionize Scene-Text-to-Motion research. LaserHuman stands out with its inclusion of genuine human motions within 3D environments, unbounded free-form natural language descriptions, a blend of indoor and outdoor scenarios, and dynamic, ever-changing scenes. Diverse modalities of capture data and rich annotations present great opportunities for the research of conditional motion generation, and can also facilitate the development of real-life applications. Moreover, to generate semantically consistent and physically plausible human motions, we propose a multi-conditional diffusion model, which is simple but effective, achieving state-of-the-art performance on existing datasets.
Human-centric Scene Understanding for 3D Large-scale Scenarios
Jul 26, 2023



Human-centric scene understanding is significant for real-world applications, but it is extremely challenging due to the existence of diverse human poses and actions, complex human-environment interactions, severe occlusions in crowds, etc. In this paper, we present a large-scale multi-modal dataset for human-centric scene understanding, dubbed HuCenLife, which is collected in diverse daily-life scenarios with rich and fine-grained annotations. Our HuCenLife can benefit many 3D perception tasks, such as segmentation, detection, action recognition, etc., and we also provide benchmarks for these tasks to facilitate related research. In addition, we design novel modules for LiDAR-based segmentation and action recognition, which are more applicable for large-scale human-centric scenarios and achieve state-of-the-art performance.
WildRefer: 3D Object Localization in Large-scale Dynamic Scenes with Multi-modal Visual Data and Natural Language
Apr 12, 2023We introduce the task of 3D visual grounding in large-scale dynamic scenes based on natural linguistic descriptions and online captured multi-modal visual data, including 2D images and 3D LiDAR point clouds. We present a novel method, WildRefer, for this task by fully utilizing the appearance features in images, the location and geometry features in point clouds, and the dynamic features in consecutive input frames to match the semantic features in language. In particular, we propose two novel datasets, STRefer and LifeRefer, which focus on large-scale human-centric daily-life scenarios with abundant 3D object and natural language annotations. Our datasets are significant for the research of 3D visual grounding in the wild and has huge potential to boost the development of autonomous driving and service robots. Extensive comparisons and ablation studies illustrate that our method achieves state-of-the-art performance on two proposed datasets. Code and dataset will be released when the paper is published.
Weakly Supervised 3D Multi-person Pose Estimation for Large-scale Scenes based on Monocular Camera and Single LiDAR
Nov 30, 2022



Depth estimation is usually ill-posed and ambiguous for monocular camera-based 3D multi-person pose estimation. Since LiDAR can capture accurate depth information in long-range scenes, it can benefit both the global localization of individuals and the 3D pose estimation by providing rich geometry features. Motivated by this, we propose a monocular camera and single LiDAR-based method for 3D multi-person pose estimation in large-scale scenes, which is easy to deploy and insensitive to light. Specifically, we design an effective fusion strategy to take advantage of multi-modal input data, including images and point cloud, and make full use of temporal information to guide the network to learn natural and coherent human motions. Without relying on any 3D pose annotations, our method exploits the inherent geometry constraints of point cloud for self-supervision and utilizes 2D keypoints on images for weak supervision. Extensive experiments on public datasets and our newly collected dataset demonstrate the superiority and generalization capability of our proposed method.
LiCamGait: Gait Recognition in the Wild by Using LiDAR and Camera Multi-modal Visual Sensors
Nov 22, 2022



LiDAR can capture accurate depth information in large-scale scenarios without the effect of light conditions, and the captured point cloud contains gait-related 3D geometric properties and dynamic motion characteristics. We make the first attempt to leverage LiDAR to remedy the limitation of view-dependent and light-sensitive camera for more robust and accurate gait recognition. In this paper, we propose a LiDAR-camera-based gait recognition method with an effective multi-modal feature fusion strategy, which fully exploits advantages of both point clouds and images. In particular, we propose a new in-the-wild gait dataset, LiCamGait, involving multi-modal visual data and diverse 2D/3D representations. Our method achieves state-of-the-art performance on the new dataset. Code and dataset will be released when this paper is published.
LiDAR-aid Inertial Poser: Large-scale Human Motion Capture by Sparse Inertial and LiDAR Sensors
May 30, 2022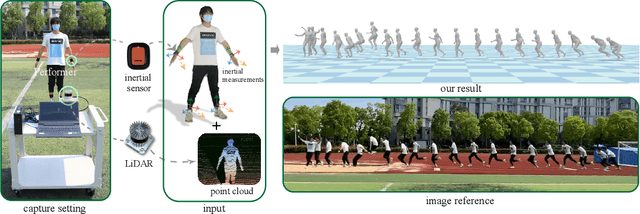

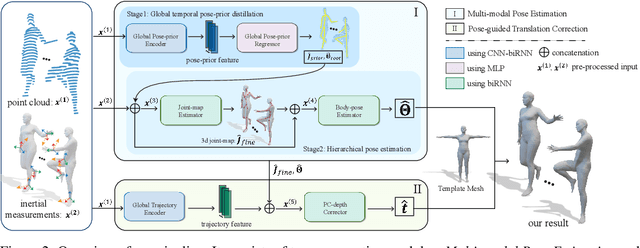
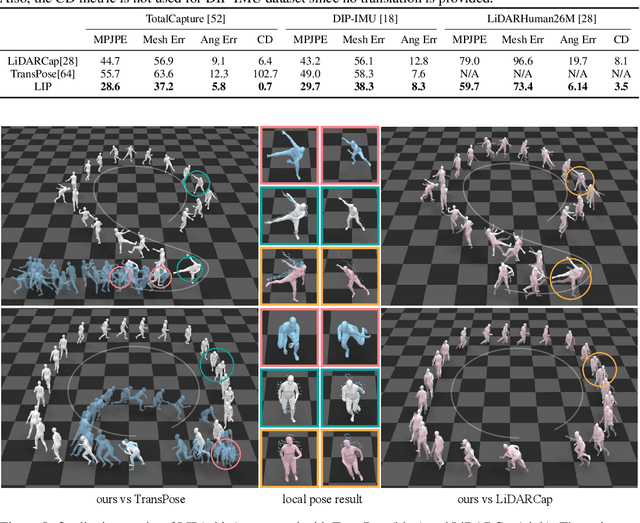
We propose a multi-sensor fusion method for capturing challenging 3D human motions with accurate consecutive local poses and global trajectories in large-scale scenarios, only using a single LiDAR and 4 IMUs. Specifically, to fully utilize the global geometry information captured by LiDAR and local dynamic motions captured by IMUs, we design a two-stage pose estimator in a coarse-to-fine manner, where point clouds provide the coarse body shape and IMU measurements optimize the local actions. Furthermore, considering the translation deviation caused by the view-dependent partial point cloud, we propose a pose-guided translation corrector. It predicts the offset between captured points and the real root locations, which makes the consecutive movements and trajectories more precise and natural. Extensive quantitative and qualitative experiments demonstrate the capability of our approach for compelling motion capture in large-scale scenarios, which outperforms other methods by an obvious margin. We will release our code and captured dataset to stimulate future research.
STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes
Apr 03, 2022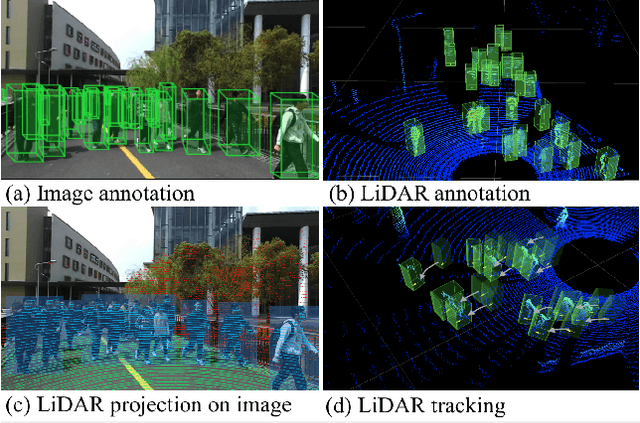
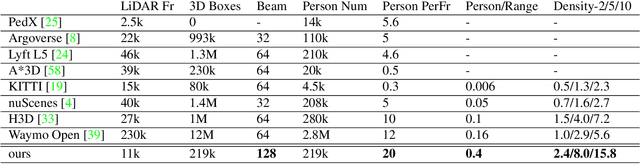

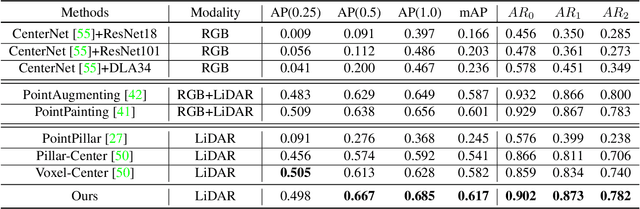
Accurately detecting and tracking pedestrians in 3D space is challenging due to large variations in rotations, poses and scales. The situation becomes even worse for dense crowds with severe occlusions. However, existing benchmarks either only provide 2D annotations, or have limited 3D annotations with low-density pedestrian distribution, making it difficult to build a reliable pedestrian perception system especially in crowded scenes. To better evaluate pedestrian perception algorithms in crowded scenarios, we introduce a large-scale multimodal dataset,STCrowd. Specifically, in STCrowd, there are a total of 219 K pedestrian instances and 20 persons per frame on average, with various levels of occlusion. We provide synchronized LiDAR point clouds and camera images as well as their corresponding 3D labels and joint IDs. STCrowd can be used for various tasks, including LiDAR-only, image-only, and sensor-fusion based pedestrian detection and tracking. We provide baselines for most of the tasks. In addition, considering the property of sparse global distribution and density-varying local distribution of pedestrians, we further propose a novel method, Density-aware Hierarchical heatmap Aggregation (DHA), to enhance pedestrian perception in crowded scenes. Extensive experiments show that our new method achieves state-of-the-art performance for pedestrian detection on various datasets.