 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Self-Distillation via Previous Mini-batches for Fine-tuning Small Language Models
Nov 25, 2024



Knowledge distillation (KD) has become a widely adopted approach for compressing large language models (LLMs) to reduce computational costs and memory footprints. However, the availability of complex teacher models is a prerequisite for running most KD pipelines. Thus, the traditional KD procedure can be unachievable or budget-unfriendly, particularly when relying on commercial LLMs like GPT4. In this regard, Self-distillation (SelfD) emerges as an advisable alternative, enabling student models to learn without teachers' guidance. Nonetheless, existing SelfD approaches for LMs often involve architectural modifications, assuming the models are open-source, which may not always be practical. In this work, we introduce a model-agnostic and task-agnostic method named dynamic SelfD from the previous minibatch (DynSDPB), which realizes current iterations' distillation from the last ones' generated logits. Additionally, to address prediction inaccuracies during the early iterations, we dynamically adjust the distillation influence and temperature values to enhance the adaptability of fine-tuning. Furthermore, DynSDPB is a novel fine-tuning policy that facilitates the seamless integration of existing self-correction and self-training techniques for small language models (SLMs) because they all require updating SLMs' parameters. We demonstrate the superior performance of DynSDPB on both encoder-only LMs (e.g., BERT model families) and decoder-only LMs (e.g., LLaMA model families), validating its effectiveness across natural language understanding (NLU) and natural language generation (NLG) benchmarks.
Training Compute-Optimal Protein Language Models
Nov 04, 2024We explore optimally training protein language models, an area of significant interest in biological research where guidance on best practices is limited. Most models are trained with extensive compute resources until performance gains plateau, focusing primarily on increasing model sizes rather than optimizing the efficient compute frontier that balances performance and compute budgets. Our investigation is grounded in a massive dataset consisting of 939 million protein sequences. We trained over 300 models ranging from 3.5 million to 10.7 billion parameters on 5 to 200 billion unique tokens, to investigate the relations between model sizes, training token numbers, and objectives. First, we observed the effect of diminishing returns for the Causal Language Model (CLM) and that of overfitting for the Masked Language Model~(MLM) when repeating the commonly used Uniref database. To address this, we included metagenomic protein sequences in the training set to increase the diversity and avoid the plateau or overfitting effects. Second, we obtained the scaling laws of CLM and MLM on Transformer, tailored to the specific characteristics of protein sequence data. Third, we observe a transfer scaling phenomenon from CLM to MLM, further demonstrating the effectiveness of transfer through scaling behaviors based on estimated Effectively Transferred Tokens. Finally, to validate our scaling laws, we compare the large-scale versions of ESM-2 and PROGEN2 on downstream tasks, encompassing evaluations of protein generation as well as structure- and function-related tasks, all within less or equivalent pre-training compute budgets.
LayerDAG: A Layerwise Autoregressive Diffusion Model for Directed Acyclic Graph Generation
Nov 04, 2024



Directed acyclic graphs (DAGs) serve as crucial data representations in domains such as hardware synthesis and compiler/program optimization for computing systems. DAG generative models facilitate the creation of synthetic DAGs, which can be used for benchmarking computing systems while preserving intellectual property. However, generating realistic DAGs is challenging due to their inherent directional and logical dependencies. This paper introduces LayerDAG, an autoregressive diffusion model, to address these challenges. LayerDAG decouples the strong node dependencies into manageable units that can be processed sequentially. By interpreting the partial order of nodes as a sequence of bipartite graphs, LayerDAG leverages autoregressive generation to model directional dependencies and employs diffusion models to capture logical dependencies within each bipartite graph. Comparative analyses demonstrate that LayerDAG outperforms existing DAG generative models in both expressiveness and generalization, particularly for generating large-scale DAGs with up to 400 nodes-a critical scenario for system benchmarking. Extensive experiments on both synthetic and real-world flow graphs from various computing platforms show that LayerDAG generates valid DAGs with superior statistical properties and benchmarking performance. The synthetic DAGs generated by LayerDAG enhance the training of ML-based surrogate models, resulting in improved accuracy in predicting performance metrics of real-world DAGs across diverse computing platforms.
Simple is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation
Oct 28, 2024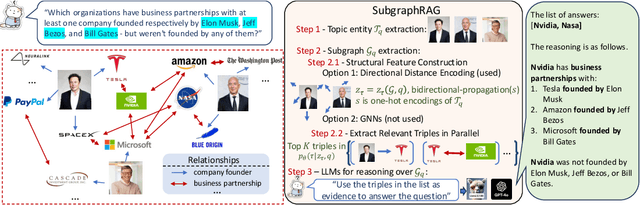


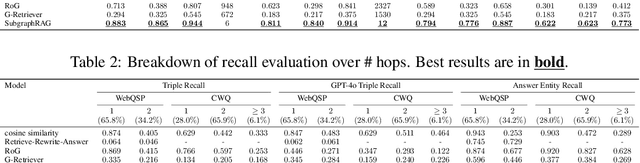
Large Language Models (LLMs) demonstrate strong reasoning abilities but face limitations such as hallucinations and outdated knowledge. Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) addresses these issues by grounding LLM outputs in structured external knowledge from KGs. However, current KG-based RAG frameworks still struggle to optimize the trade-off between retrieval effectiveness and efficiency in identifying a suitable amount of relevant graph information for the LLM to digest. We introduce SubgraphRAG, extending the KG-based RAG framework that retrieves subgraphs and leverages LLMs for reasoning and answer prediction. Our approach innovatively integrates a lightweight multilayer perceptron with a parallel triple-scoring mechanism for efficient and flexible subgraph retrieval while encoding directional structural distances to enhance retrieval effectiveness. The size of retrieved subgraphs can be flexibly adjusted to match the query's need and the downstream LLM's capabilities. This design strikes a balance between model complexity and reasoning power, enabling scalable and generalizable retrieval processes. Notably, based on our retrieved subgraphs, smaller LLMs like Llama3.1-8B-Instruct deliver competitive results with explainable reasoning, while larger models like GPT-4o achieve state-of-the-art accuracy compared with previous baselines -- all without fine-tuning. Extensive evaluations on the WebQSP and CWQ benchmarks highlight SubgraphRAG's strengths in efficiency, accuracy, and reliability by reducing hallucinations and improving response grounding.
A Survey of Deep Graph Learning under Distribution Shifts: from Graph Out-of-Distribution Generalization to Adaptation
Oct 25, 2024Distribution shifts on graphs -- the discrepancies in data distribution between training and employing a graph machine learning model -- are ubiquitous and often unavoidable in real-world scenarios. These shifts may severely deteriorate model performance, posing significant challenges for reliable graph machine learning. Consequently, there has been a surge in research on graph machine learning under distribution shifts, aiming to train models to achieve satisfactory performance on out-of-distribution (OOD) test data. In our survey, we provide an up-to-date and forward-looking review of deep graph learning under distribution shifts. Specifically, we cover three primary scenarios: graph OOD generalization, training-time graph OOD adaptation, and test-time graph OOD adaptation. We begin by formally formulating the problems and discussing various types of distribution shifts that can affect graph learning, such as covariate shifts and concept shifts. To provide a better understanding of the literature, we systematically categorize the existing models based on our proposed taxonomy and investigate the adopted techniques behind. We also summarize commonly used datasets in this research area to facilitate further investigation. Finally, we point out promising research directions and the corresponding challenges to encourage further study in this vital domain. Additionally, we provide a continuously updated reading list at https://github.com/kaize0409/Awesome-Graph-OOD.
Towards Stable, Globally Expressive Graph Representations with Laplacian Eigenvectors
Oct 13, 2024



Graph neural networks (GNNs) have achieved remarkable success in a variety of machine learning tasks over graph data. Existing GNNs usually rely on message passing, i.e., computing node representations by gathering information from the neighborhood, to build their underlying computational graphs. They are known fairly limited in expressive power, and often fail to capture global characteristics of graphs. To overcome the issue, a popular solution is to use Laplacian eigenvectors as additional node features, as they contain global positional information of nodes, and can serve as extra node identifiers aiding GNNs to separate structurally similar nodes. For such an approach, properly handling the orthogonal group symmetry among eigenvectors with equal eigenvalue is crucial for its stability and generalizability. However, using a naive orthogonal group invariant encoder for each separate eigenspace may not keep the full expressivity in the Laplacian eigenvectors. Moreover, computing such invariants inevitably entails a hard split of Laplacian eigenvalues according to their numerical identity, which suffers from great instability when the graph structure is perturbed. In this paper, we propose a novel method exploiting Laplacian eigenvectors to generate stable and globally expressive graph representations. The main difference from previous works is that (i) our method utilizes learnable orthogonal group invariant representations for each Laplacian eigenspace, based upon powerful orthogonal group equivariant neural network layers already well studied in the literature, and that (ii) our method deals with numerically close eigenvalues in a smooth fashion, ensuring its better robustness against perturbations. Experiments on various graph learning benchmarks witness the competitive performance of our method, especially its great potential to learn global properties of graphs.
Privately Learning from Graphs with Applications in Fine-tuning Large Language Models
Oct 10, 2024



Graphs offer unique insights into relationships and interactions between entities, complementing data modalities like text, images, and videos. By incorporating relational information from graph data, AI models can extend their capabilities beyond traditional tasks. However, relational data in sensitive domains such as finance and healthcare often contain private information, making privacy preservation crucial. Existing privacy-preserving methods, such as DP-SGD, which rely on gradient decoupling assumptions, are not well-suited for relational learning due to the inherent dependencies between coupled training samples. To address this challenge, we propose a privacy-preserving relational learning pipeline that decouples dependencies in sampled relations during training, ensuring differential privacy through a tailored application of DP-SGD. We apply this method to fine-tune large language models (LLMs) on sensitive graph data, and tackle the associated computational complexities. Our approach is evaluated on LLMs of varying sizes (e.g., BERT, Llama2) using real-world relational data from four text-attributed graphs. The results demonstrate significant improvements in relational learning tasks, all while maintaining robust privacy guarantees during training. Additionally, we explore the trade-offs between privacy, utility, and computational efficiency, offering insights into the practical deployment of our approach. Code is available at https://github.com/Graph-COM/PvGaLM.
A Benchmark on Directed Graph Representation Learning in Hardware Designs
Oct 09, 2024To keep pace with the rapid advancements in design complexity within modern computing systems, directed graph representation learning (DGRL) has become crucial, particularly for encoding circuit netlists, computational graphs, and developing surrogate models for hardware performance prediction. However, DGRL remains relatively unexplored, especially in the hardware domain, mainly due to the lack of comprehensive and user-friendly benchmarks. This study presents a novel benchmark comprising five hardware design datasets and 13 prediction tasks spanning various levels of circuit abstraction. We evaluate 21 DGRL models, employing diverse graph neural networks and graph transformers (GTs) as backbones, enhanced by positional encodings (PEs) tailored for directed graphs. Our results highlight that bidirected (BI) message passing neural networks (MPNNs) and robust PEs significantly enhance model performance. Notably, the top-performing models include PE-enhanced GTs interleaved with BI-MPNN layers and BI-Graph Isomorphism Network, both surpassing baselines across the 13 tasks. Additionally, our investigation into out-of-distribution (OOD) performance emphasizes the urgent need to improve OOD generalization in DGRL models. This benchmark, implemented with a modular codebase, streamlines the evaluation of DGRL models for both hardware and ML practitioners
Convergent Privacy Loss of Noisy-SGD without Convexity and Smoothness
Oct 01, 2024


We study the Differential Privacy (DP) guarantee of hidden-state Noisy-SGD algorithms over a bounded domain. Standard privacy analysis for Noisy-SGD assumes all internal states are revealed, which leads to a divergent R'enyi DP bound with respect to the number of iterations. Ye & Shokri (2022) and Altschuler & Talwar (2022) proved convergent bounds for smooth (strongly) convex losses, and raise open questions about whether these assumptions can be relaxed. We provide positive answers by proving convergent R'enyi DP bound for non-convex non-smooth losses, where we show that requiring losses to have H\"older continuous gradient is sufficient. We also provide a strictly better privacy bound compared to state-of-the-art results for smooth strongly convex losses. Our analysis relies on the improvement of shifted divergence analysis in multiple aspects, including forward Wasserstein distance tracking, identifying the optimal shifts allocation, and the H"older reduction lemma. Our results further elucidate the benefit of hidden-state analysis for DP and its applicability.
Leveraging Inter-Chunk Interactions for Enhanced Retrieval in Large Language Model-Based Question Answering
Aug 06, 2024



Retrieving external knowledge and prompting large language models with relevant information is an effective paradigm to enhance the performance of question-answering tasks. Previous research typically handles paragraphs from external documents in isolation, resulting in a lack of context and ambiguous references, particularly in multi-document and complex tasks. To overcome these challenges, we propose a new retrieval framework IIER, that leverages Inter-chunk Interactions to Enhance Retrieval. This framework captures the internal connections between document chunks by considering three types of interactions: structural, keyword, and semantic. We then construct a unified Chunk-Interaction Graph to represent all external documents comprehensively. Additionally, we design a graph-based evidence chain retriever that utilizes previous paths and chunk interactions to guide the retrieval process. It identifies multiple seed nodes based on the target question and iteratively searches for relevant chunks to gather supporting evidence. This retrieval process refines the context and reasoning chain, aiding the large language model in reasoning and answer generation. Extensive experiments demonstrate that IIER outperforms strong baselines across four datasets, highlighting its effectiveness in improving retrieval and reasoning capabilities.