 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranching Strategies Based on Subgraph GNNs: A Study on Theoretical Promise versus Practical Reality
Dec 10, 2025Graph Neural Networks (GNNs) have emerged as a promising approach for ``learning to branch'' in Mixed-Integer Linear Programming (MILP). While standard Message-Passing GNNs (MPNNs) are efficient, they theoretically lack the expressive power to fully represent MILP structures. Conversely, higher-order GNNs (like 2-FGNNs) are expressive but computationally prohibitive. In this work, we investigate Subgraph GNNs as a theoretical middle ground. Crucially, while previous work [Chen et al., 2025] demonstrated that GNNs with 3-WL expressive power can approximate Strong Branching, we prove a sharper result: node-anchored Subgraph GNNs whose expressive power is strictly lower than 3-WL [Zhang et al., 2023] are sufficient to approximate Strong Branching scores. However, our extensive empirical evaluation on four benchmark datasets reveals a stark contrast between theory and practice. While node-anchored Subgraph GNNs theoretically offer superior branching decisions, their $O(n)$ complexity overhead results in significant memory bottlenecks and slower solving times than MPNNs and heuristics. Our results indicate that for MILP branching, the computational cost of expressive GNNs currently outweighs their gains in decision quality, suggesting that future research must focus on efficiency-preserving expressivity.
RoboMatch: A Mobile-Manipulation Teleoperation Platform with Auto-Matching Network Architecture for Long-Horizon Manipulation
Sep 10, 2025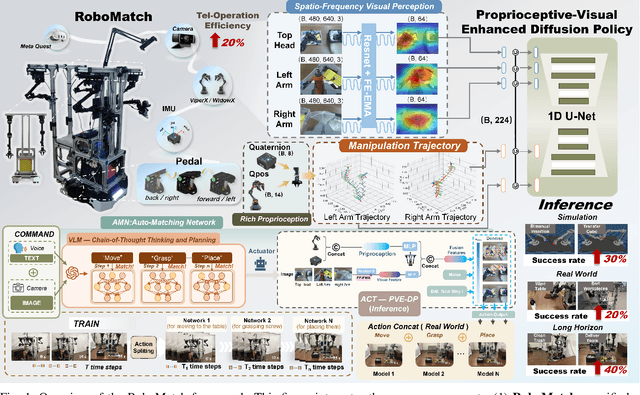

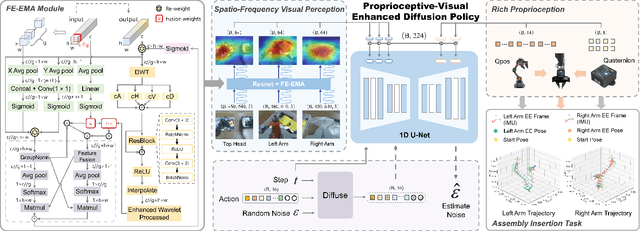
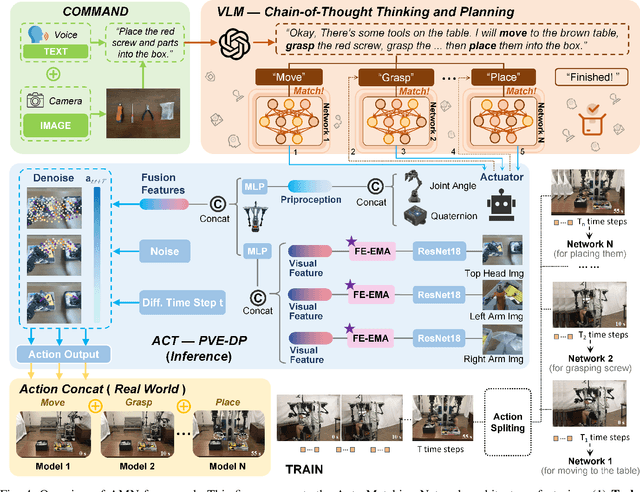
This paper presents RoboMatch, a novel unified teleoperation platform for mobile manipulation with an auto-matching network architecture, designed to tackle long-horizon tasks in dynamic environments. Our system enhances teleoperation performance, data collection efficiency, task accuracy, and operational stability. The core of RoboMatch is a cockpit-style control interface that enables synchronous operation of the mobile base and dual arms, significantly improving control precision and data collection. Moreover, we introduce the Proprioceptive-Visual Enhanced Diffusion Policy (PVE-DP), which leverages Discrete Wavelet Transform (DWT) for multi-scale visual feature extraction and integrates high-precision IMUs at the end-effector to enrich proprioceptive feedback, substantially boosting fine manipulation performance. Furthermore, we propose an Auto-Matching Network (AMN) architecture that decomposes long-horizon tasks into logical sequences and dynamically assigns lightweight pre-trained models for distributed inference. Experimental results demonstrate that our approach improves data collection efficiency by over 20%, increases task success rates by 20-30% with PVE-DP, and enhances long-horizon inference performance by approximately 40% with AMN, offering a robust solution for complex manipulation tasks.
Quantized but Deceptive? A Multi-Dimensional Truthfulness Evaluation of Quantized LLMs
Aug 26, 2025Quantization enables efficient deployment of large language models (LLMs) in resource-constrained environments by significantly reducing memory and computation costs. While quantized LLMs often maintain performance on perplexity and zero-shot tasks, their impact on truthfulness-whether generating truthful or deceptive responses-remains largely unexplored. In this work, we introduce TruthfulnessEval, a comprehensive evaluation framework for assessing the truthfulness of quantized LLMs across three dimensions: (1) Truthfulness on Logical Reasoning; (2) Truthfulness on Common Sense; and (3) Truthfulness on Imitative Falsehoods. Using this framework, we examine mainstream quantization techniques (ranging from 4-bit to extreme 2-bit) across several open-source LLMs. Surprisingly, we find that while quantized models retain internally truthful representations, they are more susceptible to producing false outputs under misleading prompts. To probe this vulnerability, we test 15 rephrased variants of "honest", "neutral" and "deceptive" prompts and observe that "deceptive" prompts can override truth-consistent behavior, whereas "honest" and "neutral" prompts maintain stable outputs. Further, we reveal that quantized models "know" the truth internally yet still produce false outputs when guided by "deceptive" prompts via layer-wise probing and PCA visualizations. Our findings provide insights into future designs of quantization-aware alignment and truthfulness interventions.
When Truthful Representations Flip Under Deceptive Instructions?
Jul 29, 2025Large language models (LLMs) tend to follow maliciously crafted instructions to generate deceptive responses, posing safety challenges. How deceptive instructions alter the internal representations of LLM compared to truthful ones remains poorly understood beyond output analysis. To bridge this gap, we investigate when and how these representations ``flip'', such as from truthful to deceptive, under deceptive versus truthful/neutral instructions. Analyzing the internal representations of Llama-3.1-8B-Instruct and Gemma-2-9B-Instruct on a factual verification task, we find the model's instructed True/False output is predictable via linear probes across all conditions based on the internal representation. Further, we use Sparse Autoencoders (SAEs) to show that the Deceptive instructions induce significant representational shifts compared to Truthful/Neutral representations (which are similar), concentrated in early-to-mid layers and detectable even on complex datasets. We also identify specific SAE features highly sensitive to deceptive instruction and use targeted visualizations to confirm distinct truthful/deceptive representational subspaces. % Our analysis pinpoints layer-wise and feature-level correlates of instructed dishonesty, offering insights for LLM detection and control. Our findings expose feature- and layer-level signatures of deception, offering new insights for detecting and mitigating instructed dishonesty in LLMs.
FAEDKV: Infinite-Window Fourier Transform for Unbiased KV Cache Compression
Jul 26, 2025



The efficacy of Large Language Models (LLMs) in long-context tasks is often hampered by the substantial memory footprint and computational demands of the Key-Value (KV) cache. Current compression strategies, including token eviction and learned projections, frequently lead to biased representations -- either by overemphasizing recent/high-attention tokens or by repeatedly degrading information from earlier context -- and may require costly model retraining. We present FAEDKV (Frequency-Adaptive Infinite-Window for KV cache), a novel, training-free KV cache compression framework that ensures unbiased information retention. FAEDKV operates by transforming the KV cache into the frequency domain using a proposed Infinite-Window Fourier Transform (IWDFT). This approach allows for the equalized contribution of all tokens to the compressed representation, effectively preserving both early and recent contextual information. A preliminary frequency ablation study identifies critical spectral components for layer-wise, targeted compression. Experiments on LongBench benchmark demonstrate FAEDKV's superiority over existing methods by up to 22\%. In addition, our method shows superior, position-agnostic retrieval accuracy on the Needle-In-A-Haystack task compared to compression based approaches.
Learning Efficient and Generalizable Graph Retriever for Knowledge-Graph Question Answering
Jun 11, 2025Large Language Models (LLMs) have shown strong inductive reasoning ability across various domains, but their reliability is hindered by the outdated knowledge and hallucinations. Retrieval-Augmented Generation mitigates these issues by grounding LLMs with external knowledge; however, most existing RAG pipelines rely on unstructured text, limiting interpretability and structured reasoning. Knowledge graphs, which represent facts as relational triples, offer a more structured and compact alternative. Recent studies have explored integrating knowledge graphs with LLMs for knowledge graph question answering (KGQA), with a significant proportion adopting the retrieve-then-reasoning paradigm. In this framework, graph-based retrievers have demonstrated strong empirical performance, yet they still face challenges in generalization ability. In this work, we propose RAPL, a novel framework for efficient and effective graph retrieval in KGQA. RAPL addresses these limitations through three aspects: (1) a two-stage labeling strategy that combines heuristic signals with parametric models to provide causally grounded supervision; (2) a model-agnostic graph transformation approach to capture both intra- and inter-triple interactions, thereby enhancing representational capacity; and (3) a path-based reasoning strategy that facilitates learning from the injected rational knowledge, and supports downstream reasoner through structured inputs. Empirically, RAPL outperforms state-of-the-art methods by $2.66\%-20.34\%$, and significantly reduces the performance gap between smaller and more powerful LLM-based reasoners, as well as the gap under cross-dataset settings, highlighting its superior retrieval capability and generalizability. Codes are available at: https://github.com/tianyao-aka/RAPL.
NAM: A Normalization Attention Model for Personalized Product Search In Fliggy
Jun 10, 2025Personalized product search provides significant benefits to e-commerce platforms by extracting more accurate user preferences from historical behaviors. Previous studies largely focused on the user factors when personalizing the search query, while ignoring the item perspective, which leads to the following two challenges that we summarize in this paper: First, previous approaches relying only on co-occurrence frequency tend to overestimate the conversion rates for popular items and underestimate those for long-tail items, resulting in inaccurate item similarities; Second, user purchasing propensity is highly heterogeneous according to the popularity of the target item: it is less correlated with the user's historical behavior for a popular item and more correlated for a long-tail item. To address these challenges, in this paper we propose NAM, a Normalization Attention Model, which optimizes ''when to personalize'' by utilizing Inverse Item Frequency (IIF) and employing a gating mechanism, as well as optimizes ''how to personalize'' by normalizing the attention mechanism from a global perspective. Through comprehensive experiments, we demonstrate that our proposed NAM model significantly outperforms state-of-the-art baseline models. Furthermore, we conducted an online A/B test at Fliggy, and obtained a significant improvement of 0.8% over the latest production system in conversion rate.
Differentially Private Relational Learning with Entity-level Privacy Guarantees
Jun 10, 2025Learning with relational and network-structured data is increasingly vital in sensitive domains where protecting the privacy of individual entities is paramount. Differential Privacy (DP) offers a principled approach for quantifying privacy risks, with DP-SGD emerging as a standard mechanism for private model training. However, directly applying DP-SGD to relational learning is challenging due to two key factors: (i) entities often participate in multiple relations, resulting in high and difficult-to-control sensitivity; and (ii) relational learning typically involves multi-stage, potentially coupled (interdependent) sampling procedures that make standard privacy amplification analyses inapplicable. This work presents a principled framework for relational learning with formal entity-level DP guarantees. We provide a rigorous sensitivity analysis and introduce an adaptive gradient clipping scheme that modulates clipping thresholds based on entity occurrence frequency. We also extend the privacy amplification results to a tractable subclass of coupled sampling, where the dependence arises only through sample sizes. These contributions lead to a tailored DP-SGD variant for relational data with provable privacy guarantees. Experiments on fine-tuning text encoders over text-attributed network-structured relational data demonstrate the strong utility-privacy trade-offs of our approach. Our code is available at https://github.com/Graph-COM/Node_DP.
Graph-KV: Breaking Sequence via Injecting Structural Biases into Large Language Models
Jun 09, 2025Modern large language models (LLMs) are inherently auto-regressive, requiring input to be serialized into flat sequences regardless of their structural dependencies. This serialization hinders the model's ability to leverage structural inductive biases, especially in tasks such as retrieval-augmented generation (RAG) and reasoning on data with native graph structures, where inter-segment dependencies are crucial. We introduce Graph-KV with the potential to overcome this limitation. Graph-KV leverages the KV-cache of text segments as condensed representations and governs their interaction through structural inductive biases. In this framework, 'target' segments selectively attend only to the KV-caches of their designated 'source' segments, rather than all preceding segments in a serialized sequence. This approach induces a graph-structured block mask, sparsifying attention and enabling a message-passing-like step within the LLM. Furthermore, strategically allocated positional encodings for source and target segments reduce positional bias and context window consumption. We evaluate Graph-KV across three scenarios: (1) seven RAG benchmarks spanning direct inference, multi-hop reasoning, and long-document understanding; (2) Arxiv-QA, a novel academic paper QA task with full-text scientific papers structured as citation ego-graphs; and (3) paper topic classification within a citation network. By effectively reducing positional bias and harnessing structural inductive biases, Graph-KV substantially outperforms baselines, including standard costly sequential encoding, across various settings. Code and the Graph-KV data are publicly available.
Do LLMs Really Forget? Evaluating Unlearning with Knowledge Correlation and Confidence Awareness
Jun 06, 2025



Machine unlearning techniques aim to mitigate unintended memorization in large language models (LLMs). However, existing approaches predominantly focus on the explicit removal of isolated facts, often overlooking latent inferential dependencies and the non-deterministic nature of knowledge within LLMs. Consequently, facts presumed forgotten may persist implicitly through correlated information. To address these challenges, we propose a knowledge unlearning evaluation framework that more accurately captures the implicit structure of real-world knowledge by representing relevant factual contexts as knowledge graphs with associated confidence scores. We further develop an inference-based evaluation protocol leveraging powerful LLMs as judges; these judges reason over the extracted knowledge subgraph to determine unlearning success. Our LLM judges utilize carefully designed prompts and are calibrated against human evaluations to ensure their trustworthiness and stability. Extensive experiments on our newly constructed benchmark demonstrate that our framework provides a more realistic and rigorous assessment of unlearning performance. Moreover, our findings reveal that current evaluation strategies tend to overestimate unlearning effectiveness. Our code is publicly available at https://github.com/Graph-COM/Knowledge_Unlearning.git.