 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditP23: 3D Editing via Propagation of Image Prompts to Multi-View
Jun 25, 2025We present EditP23, a method for mask-free 3D editing that propagates 2D image edits to multi-view representations in a 3D-consistent manner. In contrast to traditional approaches that rely on text-based prompting or explicit spatial masks, EditP23 enables intuitive edits by conditioning on a pair of images: an original view and its user-edited counterpart. These image prompts are used to guide an edit-aware flow in the latent space of a pre-trained multi-view diffusion model, allowing the edit to be coherently propagated across views. Our method operates in a feed-forward manner, without optimization, and preserves the identity of the original object, in both structure and appearance. We demonstrate its effectiveness across a range of object categories and editing scenarios, achieving high fidelity to the source while requiring no manual masks.
Text2Mesh: Text-Driven Neural Stylization for Meshes
Dec 06, 2021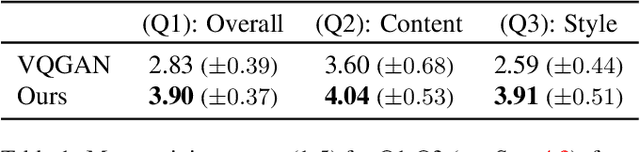


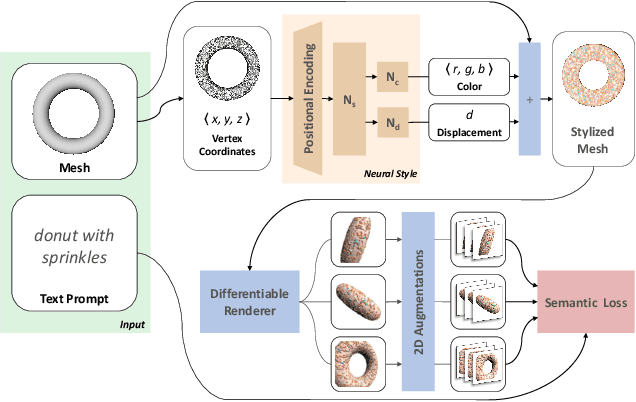
In this work, we develop intuitive controls for editing the style of 3D objects. Our framework, Text2Mesh, stylizes a 3D mesh by predicting color and local geometric details which conform to a target text prompt. We consider a disentangled representation of a 3D object using a fixed mesh input (content) coupled with a learned neural network, which we term neural style field network. In order to modify style, we obtain a similarity score between a text prompt (describing style) and a stylized mesh by harnessing the representational power of CLIP. Text2Mesh requires neither a pre-trained generative model nor a specialized 3D mesh dataset. It can handle low-quality meshes (non-manifold, boundaries, etc.) with arbitrary genus, and does not require UV parameterization. We demonstrate the ability of our technique to synthesize a myriad of styles over a wide variety of 3D meshes.