 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Annotation Makes Language Models Better Few-Shot Learners
Sep 05, 2022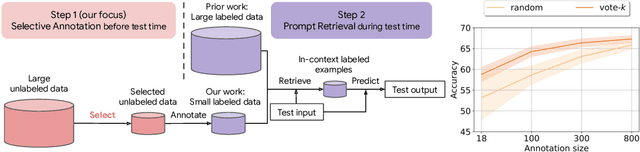
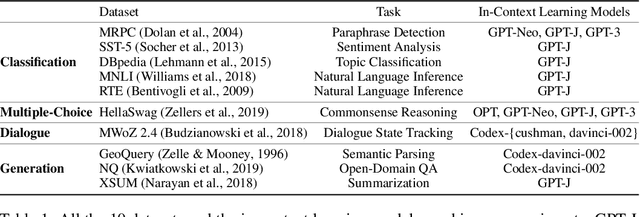
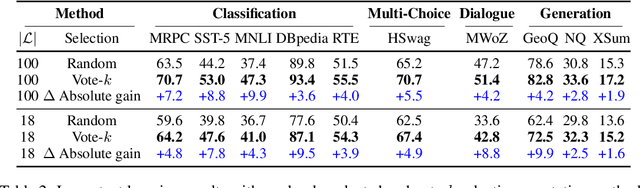
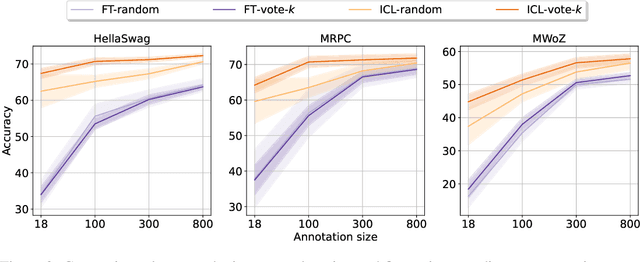
Many recent approaches to natural language tasks are built on the remarkable abilities of large language models. Large language models can perform in-context learning, where they learn a new task from a few task demonstrations, without any parameter updates. This work examines the implications of in-context learning for the creation of datasets for new natural language tasks. Departing from recent in-context learning methods, we formulate an annotation-efficient, two-step framework: selective annotation that chooses a pool of examples to annotate from unlabeled data in advance, followed by prompt retrieval that retrieves task examples from the annotated pool at test time. Based on this framework, we propose an unsupervised, graph-based selective annotation method, voke-k, to select diverse, representative examples to annotate. Extensive experiments on 10 datasets (covering classification, commonsense reasoning, dialogue, and text/code generation) demonstrate that our selective annotation method improves the task performance by a large margin. On average, vote-k achieves a 12.9%/11.4% relative gain under an annotation budget of 18/100, as compared to randomly selecting examples to annotate. Compared to state-of-the-art supervised finetuning approaches, it yields similar performance with 10-100x less annotation cost across 10 tasks. We further analyze the effectiveness of our framework in various scenarios: language models with varying sizes, alternative selective annotation methods, and cases where there is a test data domain shift. We hope that our studies will serve as a basis for data annotations as large language models are increasingly applied to new tasks. Our code is available at https://github.com/HKUNLP/icl-selective-annotation.
Elaboration-Generating Commonsense Question Answering at Scale
Sep 02, 2022
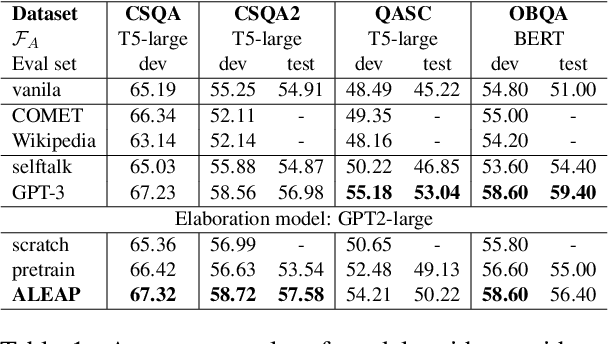
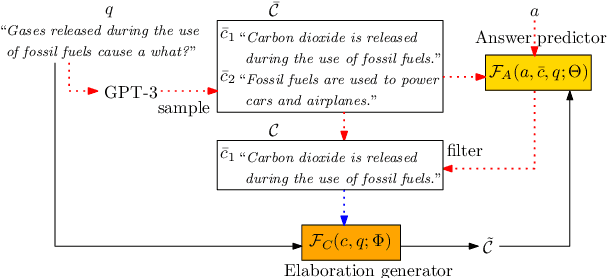

In question answering requiring common sense, language models (e.g., GPT-3) have been used to generate text expressing background knowledge that helps improve performance. Yet the cost of working with such models is very high; in this work, we finetune smaller language models to generate useful intermediate context, referred to here as elaborations. Our framework alternates between updating two language models -- an elaboration generator and an answer predictor -- allowing each to influence the other. Using less than 0.5% of the parameters of GPT-3, our model outperforms alternatives with similar sizes and closes the gap on GPT-3 on four commonsense question answering benchmarks. Human evaluations show that the quality of the generated elaborations is high.
Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models
Aug 05, 2022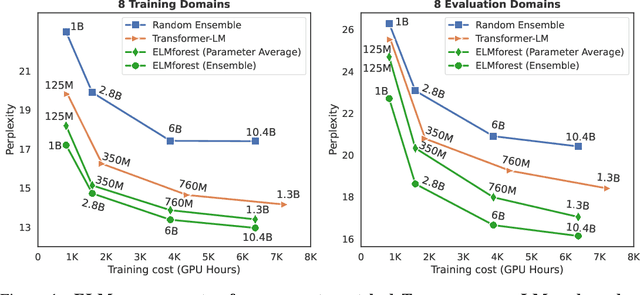
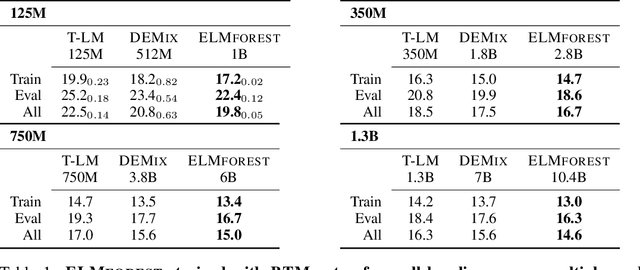
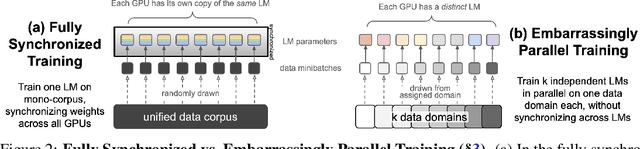

We present Branch-Train-Merge (BTM), a communication-efficient algorithm for embarrassingly parallel training of large language models (LLMs). We show it is possible to independently train subparts of a new class of LLMs on different subsets of the data, eliminating the massive multi-node synchronization currently required to train LLMs. BTM learns a set of independent expert LMs (ELMs), each specialized to a different textual domain, such as scientific or legal text. These ELMs can be added and removed to update data coverage, ensembled to generalize to new domains, or averaged to collapse back to a single LM for efficient inference. New ELMs are learned by branching from (mixtures of) ELMs in the current set, further training the parameters on data for the new domain, and then merging the resulting model back into the set for future use. Experiments show that BTM improves in- and out-of-domain perplexities as compared to GPT-style Transformer LMs, when controlling for training cost. Through extensive analysis, we show that these results are robust to different ELM initialization schemes, but require expert domain specialization; LM ensembles with random data splits do not perform well. We also present a study of scaling BTM into a new corpus of 64 domains (192B whitespace-separated tokens in total); the resulting LM (22.4B total parameters) performs as well as a Transformer LM trained with 2.5 times more compute. These gains grow with the number of domains, suggesting more aggressive parallelism could be used to efficiently train larger models in future work.
RealTime QA: What's the Answer Right Now?
Jul 27, 2022
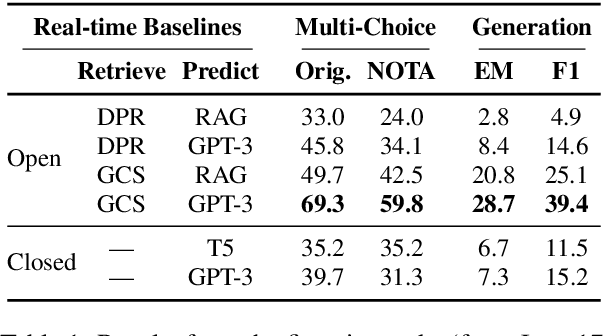
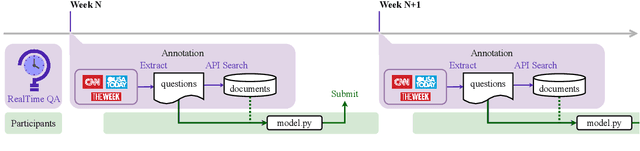
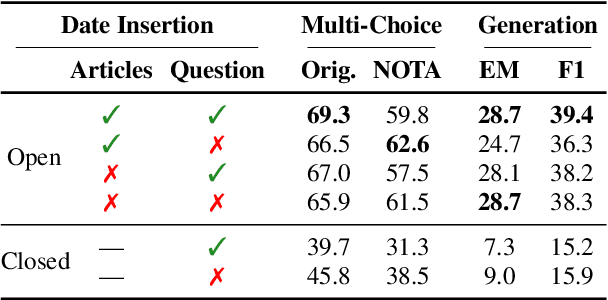
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open domain QA datasets and pursues, instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this preliminary report presents real-time evaluation results over the past month. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
Measuring the Carbon Intensity of AI in Cloud Instances
Jun 10, 2022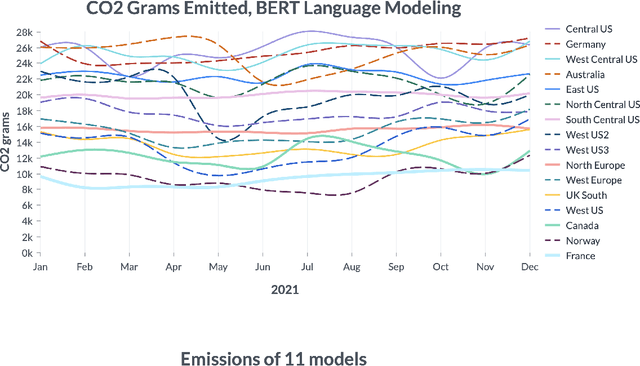

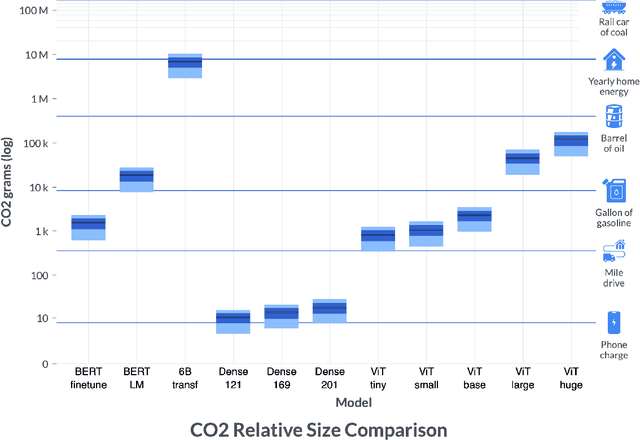

By providing unprecedented access to computational resources, cloud computing has enabled rapid growth in technologies such as machine learning, the computational demands of which incur a high energy cost and a commensurate carbon footprint. As a result, recent scholarship has called for better estimates of the greenhouse gas impact of AI: data scientists today do not have easy or reliable access to measurements of this information, precluding development of actionable tactics. Cloud providers presenting information about software carbon intensity to users is a fundamental stepping stone towards minimizing emissions. In this paper, we provide a framework for measuring software carbon intensity, and propose to measure operational carbon emissions by using location-based and time-specific marginal emissions data per energy unit. We provide measurements of operational software carbon intensity for a set of modern models for natural language processing and computer vision, and a wide range of model sizes, including pretraining of a 6.1 billion parameter language model. We then evaluate a suite of approaches for reducing emissions on the Microsoft Azure cloud compute platform: using cloud instances in different geographic regions, using cloud instances at different times of day, and dynamically pausing cloud instances when the marginal carbon intensity is above a certain threshold. We confirm previous results that the geographic region of the data center plays a significant role in the carbon intensity for a given cloud instance, and find that choosing an appropriate region can have the largest operational emissions reduction impact. We also show that the time of day has notable impact on operational software carbon intensity. Finally, we conclude with recommendations for how machine learning practitioners can use software carbon intensity information to reduce environmental impact.
Unsupervised Learning of Hierarchical Conversation Structure
May 24, 2022



Human conversations can evolve in many different ways, creating challenges for automatic understanding and summarization. Goal-oriented conversations often have meaningful sub-dialogue structure, but it can be highly domain-dependent. This work introduces an unsupervised approach to learning hierarchical conversation structure, including turn and sub-dialogue segment labels, corresponding roughly to dialogue acts and sub-tasks, respectively. The decoded structure is shown to be useful in enhancing neural models of language for three conversation-level understanding tasks. Further, the learned finite-state sub-dialogue network is made interpretable through automatic summarization. Our code and trained models are available at \url{https://github.com/boru-roylu/THETA}.
Twist Decoding: Diverse Generators Guide Each Other
May 19, 2022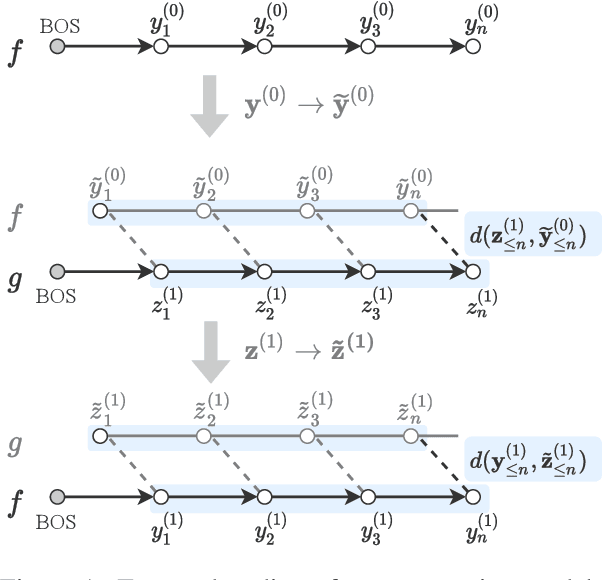
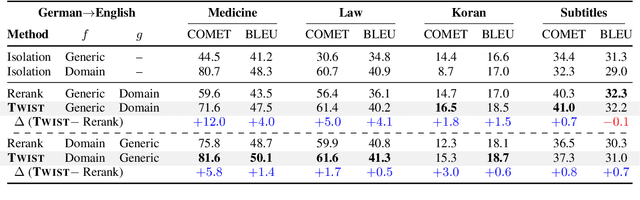

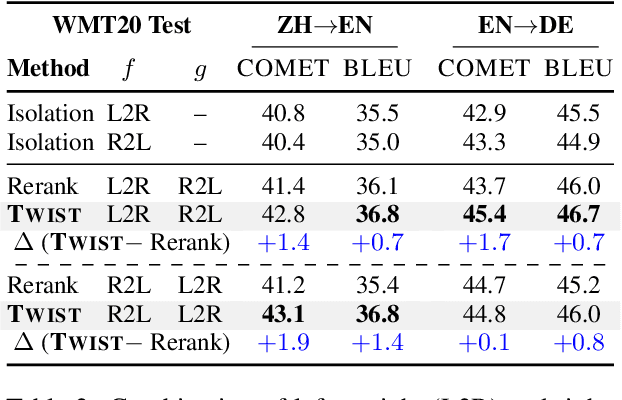
Natural language generation technology has recently seen remarkable progress with large-scale training, and many natural language applications are now built upon a wide range of generation models. Combining diverse models may lead to further progress, but conventional ensembling (e.g., shallow fusion) requires that they share vocabulary/tokenization schemes. We introduce Twist decoding, a simple and general inference algorithm that generates text while benefiting from diverse models. Our method does not assume the vocabulary, tokenization or even generation order is shared. Our extensive evaluations on machine translation and scientific paper summarization demonstrate that Twist decoding substantially outperforms each model decoded in isolation over various scenarios, including cases where domain-specific and general-purpose models are both available. Twist decoding also consistently outperforms the popular reranking heuristic where output candidates from one model is rescored by another. We hope that our work will encourage researchers and practitioners to examine generation models collectively, not just independently, and to seek out models with complementary strengths to the currently available models.
Beam Decoding with Controlled Patience
Apr 29, 2022
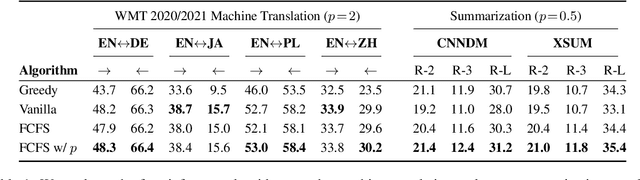


Text generation with beam search has proven successful in a wide range of applications. The commonly-used implementation of beam decoding follows a first come, first served heuristic: it keeps a set of already completed sequences over time steps and stops when the size of this set reaches the beam size. We introduce a patience factor, a simple modification to this decoding algorithm, that generalizes the stopping criterion and provides flexibility to the depth of search. Extensive empirical results demonstrate that the patience factor improves decoding performance of strong pretrained models on news text summarization and machine translation over diverse language pairs, with a negligible inference slowdown. Our approach only modifies one line of code and can be thus readily incorporated in any implementation.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

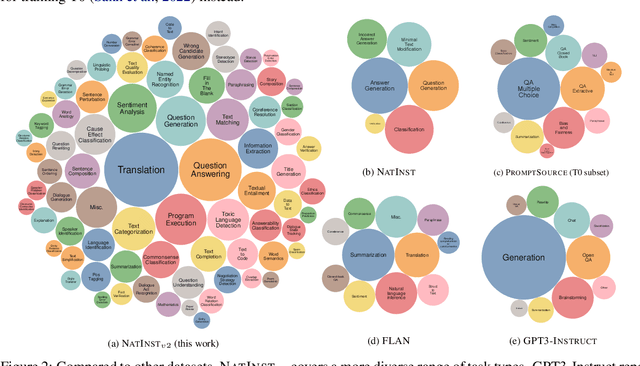
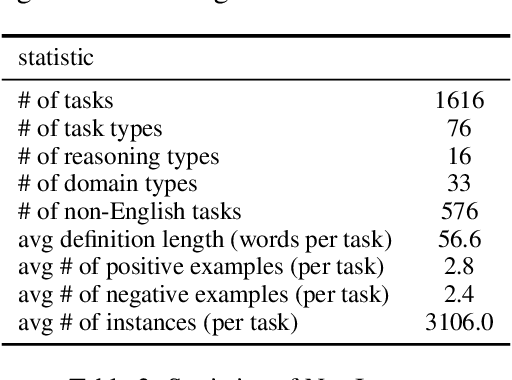
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
In-Context Learning for Few-Shot Dialogue State Tracking
Mar 16, 2022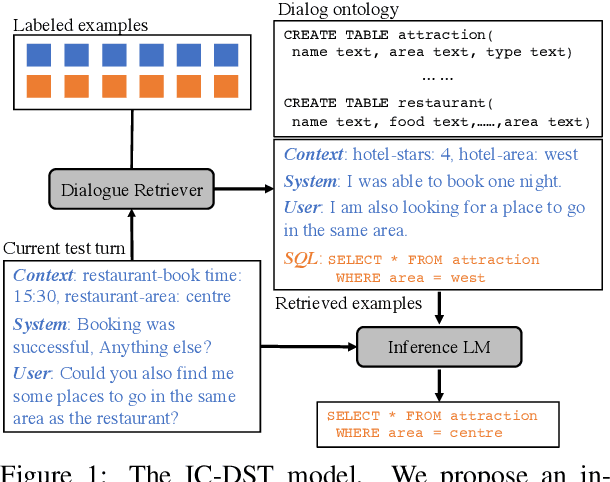
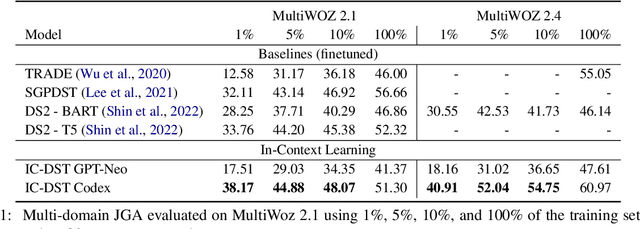
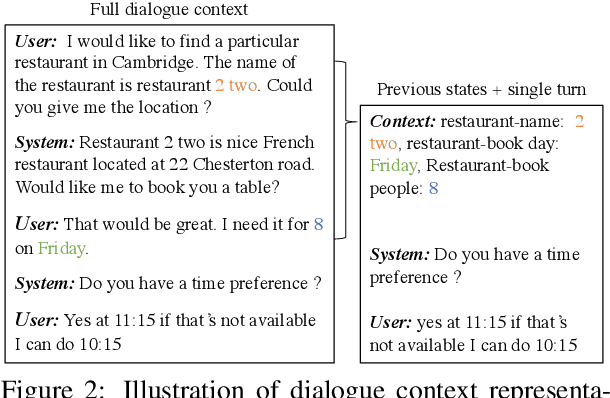
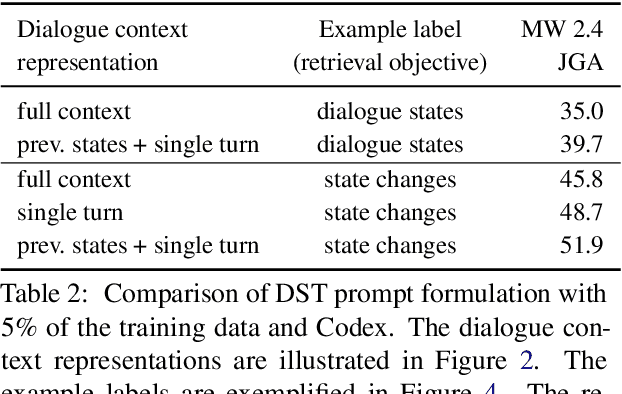
Collecting and annotating task-oriented dialogues is time-consuming and costly. Thus, few-shot learning for dialogue tasks presents an exciting opportunity. In this work, we propose an in-context (IC) learning framework for few-shot dialogue state tracking (DST), where a large pre-trained language model (LM) takes a test instance and a few annotated examples as input, and directly decodes the dialogue states without any parameter updates. This makes the LM more flexible and scalable compared to prior few-shot DST work when adapting to new domains and scenarios. We study ways to formulate dialogue context into prompts for LMs and propose an efficient approach to retrieve dialogues as exemplars given a test instance and a selection pool of few-shot examples. To better leverage the pre-trained LMs, we also reformulate DST into a text-to-SQL problem. Empirical results on MultiWOZ 2.1 and 2.4 show that our method IC-DST outperforms previous fine-tuned state-of-the-art models in few-shot settings.