 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr-CiK: A Testbed for Foresight-Driven Agents
May 27, 2026Time series forecasting in real-world settings often depends not only on historical observations, but also on external context that must be actively discovered from noisy, heterogeneous information sources. Yet existing context-aided forecasting benchmarks typically assume that the supporting context is already provided, leaving open whether agents can identify it on their own. Therefore, we introduce Dr-CiK, a benchmark for evaluating whether agents can retrieve forecasting-relevant supporting context from a document corpus, filter out distractors, distill the retrieved context into forecast-useful evidence, and generate forecasts supported by that evidence. Through context ablations and evaluations of state-of-the-art deep research and forecasting methods paired together, we show that high-quality context substantially improves forecasting performance in Dr-CiK. However, most existing DR agents recover only a small fraction of the ground-truth supporting evidence (usually <5%), are frequently misled by distractors (>80% distractor citations), and can cause forecasters to perform worse with retrieved context than without context. Our results motivate research on foresight-driven agents that search for the right context to predict the future.
Overcoming the Modality Gap in Context-Aided Forecasting
Mar 16, 2026Context-aided forecasting (CAF) holds promise for integrating domain knowledge and forward-looking information, enabling AI systems to surpass traditional statistical methods. However, recent empirical studies reveal a puzzling gap: multimodal models often fail to outperform their unimodal counterparts. We hypothesize that this underperformance stems from poor context quality in existing datasets, as verification is challenging. To address these limitations, we introduce a semi-synthetic data augmentation method that generates contexts both descriptive of temporal dynamics and verifiably complementary to numerical histories. This approach enables massive-scale dataset creation, resulting in CAF-7M, a corpus of 7 million context-augmented time series windows, including a rigorously verified test set. We demonstrate that semi-synthetic pre-training transfers effectively to real-world evaluation, and show clear evidence of context utilization. Our results suggest that dataset quality, rather than architectural limitations, has been the primary bottleneck in context-aided forecasting.
Impermanent: A Live Benchmark for Temporal Generalization in Time Series Forecasting
Mar 10, 2026Recent advances in time-series forecasting increasingly rely on pre-trained foundation-style models. While these models often claim broad generalization, existing evaluation protocols provide limited evidence. Indeed, most current benchmarks use static train-test splits that can easily lead to contamination as foundation models can inadvertently train on test data or perform model selection using test scores, which can inflate performance. We introduce Impermanent, a live benchmark that evaluates forecasting models under open-world temporal change by scoring forecasts sequentially over time on continuously updated data streams, enabling the study of temporal robustness, distributional shift, and performance stability rather than one-off accuracy on a frozen test set. Impermanent is instantiated on GitHub open-source activity, providing a naturally live and highly non-stationary dataset shaped by releases, shifting contributor behavior, platform/tooling changes, and external events. We focus on the top 400 repositories by star count and construct time series from issues opened, pull requests opened, push events, and new stargazers, evaluated over a rolling window with daily updates, alongside standardized protocols and leaderboards for reproducible, ongoing comparison. By shifting evaluation from static accuracy to sustained performance, Impermanent takes a concrete step toward assessing when and whether foundation-level generalization in time-series forecasting can be meaningfully claimed. Code and a live dashboard are available at https://github.com/TimeCopilot/impermanent and https://impermanent.timecopilot.dev.
Beyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs
Aug 13, 2025Forecasting in real-world settings requires models to integrate not only historical data but also relevant contextual information, often available in textual form. While recent work has shown that large language models (LLMs) can be effective context-aided forecasters via na\"ive direct prompting, their full potential remains underexplored. We address this gap with 4 strategies, providing new insights into the zero-shot capabilities of LLMs in this setting. ReDP improves interpretability by eliciting explicit reasoning traces, allowing us to assess the model's reasoning over the context independently from its forecast accuracy. CorDP leverages LLMs solely to refine existing forecasts with context, enhancing their applicability in real-world forecasting pipelines. IC-DP proposes embedding historical examples of context-aided forecasting tasks in the prompt, substantially improving accuracy even for the largest models. Finally, RouteDP optimizes resource efficiency by using LLMs to estimate task difficulty, and routing the most challenging tasks to larger models. Evaluated on different kinds of context-aided forecasting tasks from the CiK benchmark, our strategies demonstrate distinct benefits over na\"ive prompting across LLMs of different sizes and families. These results open the door to further simple yet effective improvements in LLM-based context-aided forecasting.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
dsld: A Socially Relevant Tool for Teaching Statistics
Nov 06, 2024



The growing power of data science can play a crucial role in addressing social discrimination, necessitating nuanced understanding and effective mitigation strategies of potential biases. Data Science Looks At Discrimination (dsld) is an R and Python package designed to provide users with a comprehensive toolkit of statistical and graphical methods for assessing possible discrimination related to protected groups, such as race, gender, and age. Our software offers techniques for discrimination analysis by identifying and mitigating confounding variables, along with methods for reducing bias in predictive models. In educational settings, dsld offers instructors powerful tools to teach important statistical principles through motivating real world examples of discrimination analysis. The inclusion of an 80-page Quarto book further supports users, from statistics educators to legal professionals, in effectively applying these analytical tools to real world scenarios.
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .
Lag-Llama: Towards Foundation Models for Time Series Forecasting
Oct 12, 2023



Aiming to build foundation models for time-series forecasting and study their scaling behavior, we present here our work-in-progress on Lag-Llama, a general-purpose univariate probabilistic time-series forecasting model trained on a large collection of time-series data. The model shows good zero-shot prediction capabilities on unseen "out-of-distribution" time-series datasets, outperforming supervised baselines. We use smoothly broken power-laws to fit and predict model scaling behavior. The open source code is made available at https://github.com/kashif/pytorch-transformer-ts.
TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series
Oct 02, 2023



We introduce a new model for multivariate probabilistic time series prediction, designed to flexibly address a range of tasks including forecasting, interpolation, and their combinations. Building on copula theory, we propose a simplified objective for the recently-introduced transformer-based attentional copulas (TACTiS), wherein the number of distributional parameters now scales linearly with the number of variables instead of factorially. The new objective requires the introduction of a training curriculum, which goes hand-in-hand with necessary changes to the original architecture. We show that the resulting model has significantly better training dynamics and achieves state-of-the-art performance across diverse real-world forecasting tasks, while maintaining the flexibility of prior work, such as seamless handling of unaligned and unevenly-sampled time series.
Extremely Simple Activation Shaping for Out-of-Distribution Detection
Sep 20, 2022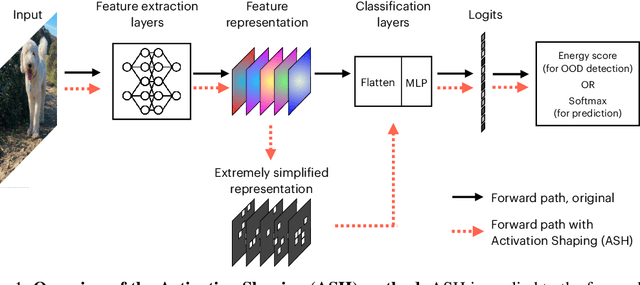


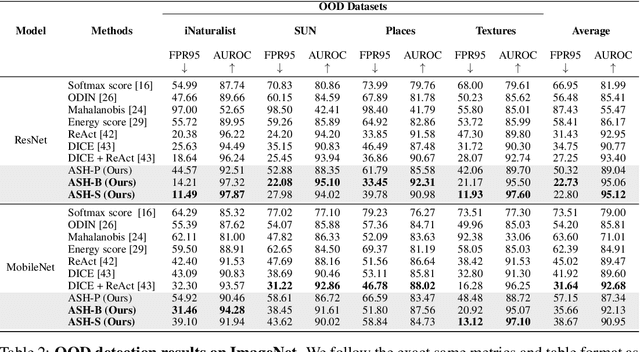
The separation between training and deployment of machine learning models implies that not all scenarios encountered in deployment can be anticipated during training, and therefore relying solely on advancements in training has its limits. Out-of-distribution (OOD) detection is an important area that stress-tests a model's ability to handle unseen situations: Do models know when they don't know? Existing OOD detection methods either incur extra training steps, additional data or make nontrivial modifications to the trained network. In contrast, in this work, we propose an extremely simple, post-hoc, on-the-fly activation shaping method, ASH, where a large portion (e.g. 90%) of a sample's activation at a late layer is removed, and the rest (e.g. 10%) simplified or lightly adjusted. The shaping is applied at inference time, and does not require any statistics calculated from training data. Experiments show that such a simple treatment enhances in-distribution and out-of-distribution sample distinction so as to allow state-of-the-art OOD detection on ImageNet, and does not noticeably deteriorate the in-distribution accuracy. We release alongside the paper two calls for explanation and validation, believing the collective power to further validate and understand the discovery. Calls, video and code can be found at: https://andrijazz.github.io/ash