 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Quantization Shapes Bias in Large Language Models
Aug 25, 2025
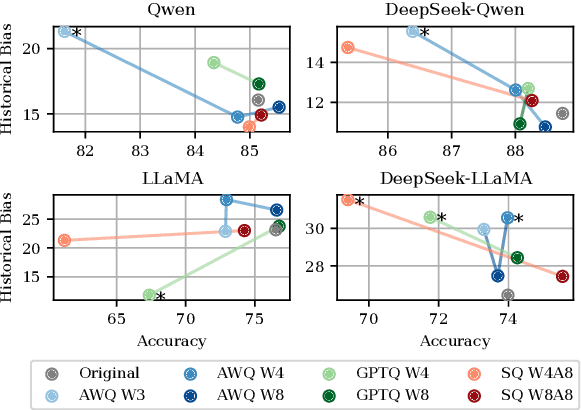
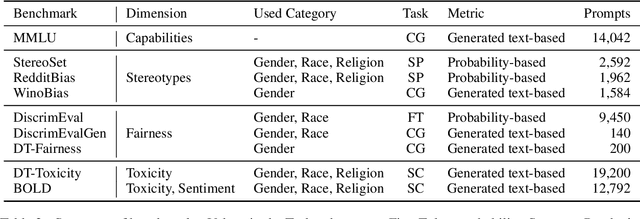
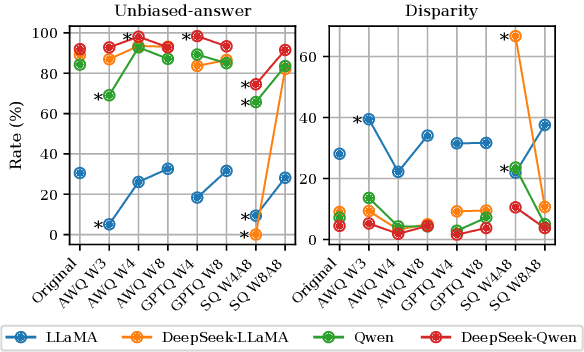
This work presents a comprehensive evaluation of how quantization affects model bias, with particular attention to its impact on individual demographic subgroups. We focus on weight and activation quantization strategies and examine their effects across a broad range of bias types, including stereotypes, toxicity, sentiment, and fairness. We employ both probabilistic and generated text-based metrics across nine benchmarks and evaluate models varying in architecture family and reasoning ability. Our findings show that quantization has a nuanced impact on bias: while it can reduce model toxicity and does not significantly impact sentiment, it tends to slightly increase stereotypes and unfairness in generative tasks, especially under aggressive compression. These trends are generally consistent across demographic categories and model types, although their magnitude depends on the specific setting. Overall, our results highlight the importance of carefully balancing efficiency and ethical considerations when applying quantization in practice.
Don't Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning
May 23, 2025Reasoning large language models (LLMs) heavily rely on scaling test-time compute to perform complex reasoning tasks by generating extensive "thinking" chains. While demonstrating impressive results, this approach incurs significant computational costs and inference time. In this work, we challenge the assumption that long thinking chains results in better reasoning capabilities. We first demonstrate that shorter reasoning chains within individual questions are significantly more likely to yield correct answers - up to 34.5% more accurate than the longest chain sampled for the same question. Based on these results, we suggest short-m@k, a novel reasoning LLM inference method. Our method executes k independent generations in parallel and halts computation once the first m thinking processes are done. The final answer is chosen using majority voting among these m chains. Basic short-1@k demonstrates similar or even superior performance over standard majority voting in low-compute settings - using up to 40% fewer thinking tokens. short-3@k, while slightly less efficient than short-1@k, consistently surpasses majority voting across all compute budgets, while still being substantially faster (up to 33% wall time reduction). Inspired by our results, we finetune an LLM using short, long, and randomly selected reasoning chains. We then observe that training on the shorter ones leads to better performance. Our findings suggest rethinking current methods of test-time compute in reasoning LLMs, emphasizing that longer "thinking" does not necessarily translate to improved performance and can, counter-intuitively, lead to degraded results.
Follow the Flow: On Information Flow Across Textual Tokens in Text-to-Image Models
Apr 01, 2025Text-to-Image (T2I) models often suffer from issues such as semantic leakage, incorrect feature binding, and omissions of key concepts in the generated image. This work studies these phenomena by looking into the role of information flow between textual token representations. To this end, we generate images by applying the diffusion component on a subset of contextual token representations in a given prompt and observe several interesting phenomena. First, in many cases, a word or multiword expression is fully represented by one or two tokens, while other tokens are redundant. For example, in "San Francisco's Golden Gate Bridge", the token "gate" alone captures the full expression. We demonstrate the redundancy of these tokens by removing them after textual encoding and generating an image from the resulting representation. Surprisingly, we find that this process not only maintains image generation performance but also reduces errors by 21\% compared to standard generation. We then show that information can also flow between different expressions in a sentence, which often leads to semantic leakage. Based on this observation, we propose a simple, training-free method to mitigate semantic leakage: replacing the leaked item's representation after the textual encoding with its uncontextualized representation. Remarkably, this simple approach reduces semantic leakage by 85\%. Overall, our work provides a comprehensive analysis of information flow across textual tokens in T2I models, offering both novel insights and practical benefits.
On Pruning State-Space LLMs
Feb 26, 2025



Recent work proposed state-space models (SSMs) as an efficient alternative to transformer-based LLMs. Can these models be pruned to further reduce their computation costs? We adapt several pruning methods to the SSM structure, and apply them to four SSM-based LLMs across multiple tasks. We find that such models are quite robust to some pruning methods (e.g. WANDA), while using other methods lead to fast performance degradation.
From Tokens to Words: On the Inner Lexicon of LLMs
Oct 10, 2024



Natural language is composed of words, but modern LLMs process sub-words as input. A natural question raised by this discrepancy is whether LLMs encode words internally, and if so how. We present evidence that LLMs engage in an intrinsic detokenization process, where sub-word sequences are combined into coherent word representations. Our experiments show that this process takes place primarily within the early and middle layers of the model. They also show that it is robust to non-morphemic splits, typos and perhaps importantly-to out-of-vocabulary words: when feeding the inner representation of such words to the model as input vectors, it can "understand" them despite never seeing them during training. Our findings suggest that LLMs maintain a latent vocabulary beyond the tokenizer's scope. These insights provide a practical, finetuning-free application for expanding the vocabulary of pre-trained models. By enabling the addition of new vocabulary words, we reduce input length and inference iterations, which reduces both space and model latency, with little to no loss in model accuracy.
Attend First, Consolidate Later: On the Importance of Attention in Different LLM Layers
Sep 05, 2024



In decoder-based LLMs, the representation of a given layer serves two purposes: as input to the next layer during the computation of the current token; and as input to the attention mechanism of future tokens. In this work, we show that the importance of the latter role might be overestimated. To show that, we start by manipulating the representations of previous tokens; e.g. by replacing the hidden states at some layer k with random vectors. Our experimenting with four LLMs and four tasks show that this operation often leads to small to negligible drop in performance. Importantly, this happens if the manipulation occurs in the top part of the model-k is in the final 30-50% of the layers. In contrast, doing the same manipulation in earlier layers might lead to chance level performance. We continue by switching the hidden state of certain tokens with hidden states of other tokens from another prompt; e.g., replacing the word "Italy" with "France" in "What is the capital of Italy?". We find that when applying this switch in the top 1/3 of the model, the model ignores it (answering "Rome"). However if we apply it before, the model conforms to the switch ("Paris"). Our results hint at a two stage process in transformer-based LLMs: the first part gathers input from previous tokens, while the second mainly processes that information internally.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.
Accelerating Speculative Decoding using Dynamic Speculation Length
May 07, 2024



Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method depends on the speculation length (SL) - the number of tokens generated by the draft model at each iteration. The vast majority of speculative decoding approaches use the same SL for all iterations. In this work, we show that this practice is suboptimal. We introduce DISCO, a DynamIc SpeCulation length Optimization method that uses a classifier to dynamically adjust the SL at each iteration, while provably preserving the decoding quality. Experiments with four benchmarks demonstrate average speedup gains of 10.3% relative to our best baselines.
Beyond Performance: Quantifying and Mitigating Label Bias in LLMs
May 04, 2024Large language models (LLMs) have shown remarkable adaptability to diverse tasks, by leveraging context prompts containing instructions, or minimal input-output examples. However, recent work revealed they also exhibit label bias -- an undesirable preference toward predicting certain answers over others. Still, detecting and measuring this bias reliably and at scale has remained relatively unexplored. In this study, we evaluate different approaches to quantifying label bias in a model's predictions, conducting a comprehensive investigation across 279 classification tasks and ten LLMs. Our investigation reveals substantial label bias in models both before and after debiasing attempts, as well as highlights the importance of outcomes-based evaluation metrics, which were not previously used in this regard. We further propose a novel label bias calibration method tailored for few-shot prompting, which outperforms recent calibration approaches for both improving performance and mitigating label bias. Our results emphasize that label bias in the predictions of LLMs remains a barrier to their reliability.
The Larger the Better? Improved LLM Code-Generation via Budget Reallocation
Mar 31, 2024



It is a common belief that large language models (LLMs) are better than smaller-sized ones. However, larger models also require significantly more time and compute during inference. This begs the question: what happens when both models operate under the same budget? (e.g., compute, run-time). To address this question, we analyze code generation LLMs of various sizes and make comparisons such as running a 70B model once vs. generating five outputs from a 13B model and selecting one. Our findings reveal that, in a standard unit-test setup, the repeated use of smaller models can yield consistent improvements, with gains of up to 15% across five tasks. On the other hand, in scenarios where unit-tests are unavailable, a ranking-based selection of candidates from the smaller model falls short of the performance of a single output from larger ones. Our results highlight the potential of using smaller models instead of larger ones, and the importance of studying approaches for ranking LLM outputs.