 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLINGO : Visually Debiasing Natural Language Instructions to Support Task Diversity
Apr 12, 2023Cross-task generalization is a significant outcome that defines mastery in natural language understanding. Humans show a remarkable aptitude for this, and can solve many different types of tasks, given definitions in the form of textual instructions and a small set of examples. Recent work with pre-trained language models mimics this learning style: users can define and exemplify a task for the model to attempt as a series of natural language prompts or instructions. While prompting approaches have led to higher cross-task generalization compared to traditional supervised learning, analyzing 'bias' in the task instructions given to the model is a difficult problem, and has thus been relatively unexplored. For instance, are we truly modeling a task, or are we modeling a user's instructions? To help investigate this, we develop LINGO, a novel visual analytics interface that supports an effective, task-driven workflow to (1) help identify bias in natural language task instructions, (2) alter (or create) task instructions to reduce bias, and (3) evaluate pre-trained model performance on debiased task instructions. To robustly evaluate LINGO, we conduct a user study with both novice and expert instruction creators, over a dataset of 1,616 linguistic tasks and their natural language instructions, spanning 55 different languages. For both user groups, LINGO promotes the creation of more difficult tasks for pre-trained models, that contain higher linguistic diversity and lower instruction bias. We additionally discuss how the insights learned in developing and evaluating LINGO can aid in the design of future dashboards that aim to minimize the effort involved in prompt creation across multiple domains.
Real-Time Visual Feedback to Guide Benchmark Creation: A Human-and-Metric-in-the-Loop Workflow
Feb 09, 2023Recent research has shown that language models exploit `artifacts' in benchmarks to solve tasks, rather than truly learning them, leading to inflated model performance. In pursuit of creating better benchmarks, we propose VAIDA, a novel benchmark creation paradigm for NLP, that focuses on guiding crowdworkers, an under-explored facet of addressing benchmark idiosyncrasies. VAIDA facilitates sample correction by providing realtime visual feedback and recommendations to improve sample quality. Our approach is domain, model, task, and metric agnostic, and constitutes a paradigm shift for robust, validated, and dynamic benchmark creation via human-and-metric-in-the-loop workflows. We evaluate via expert review and a user study with NASA TLX. We find that VAIDA decreases effort, frustration, mental, and temporal demands of crowdworkers and analysts, simultaneously increasing the performance of both user groups with a 45.8% decrease in the level of artifacts in created samples. As a by product of our user study, we observe that created samples are adversarial across models, leading to decreases of 31.3% (BERT), 22.5% (RoBERTa), 14.98% (GPT-3 fewshot) in performance.
A Survey of Parameters Associated with the Quality of Benchmarks in NLP
Oct 14, 2022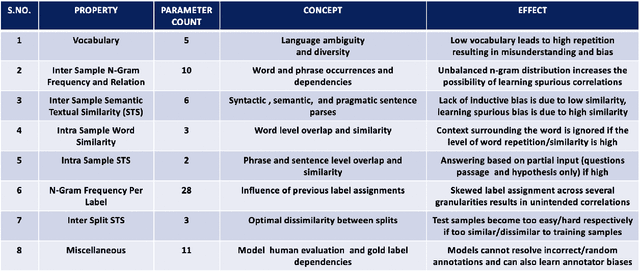
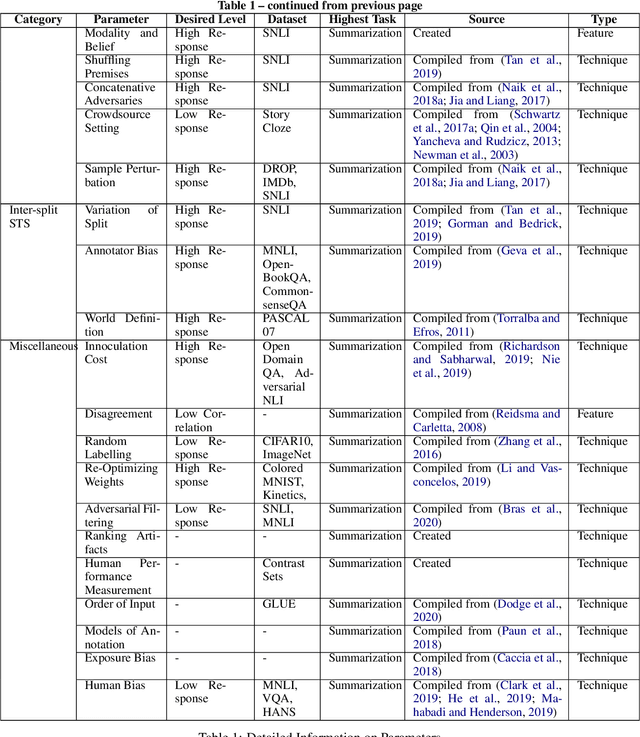
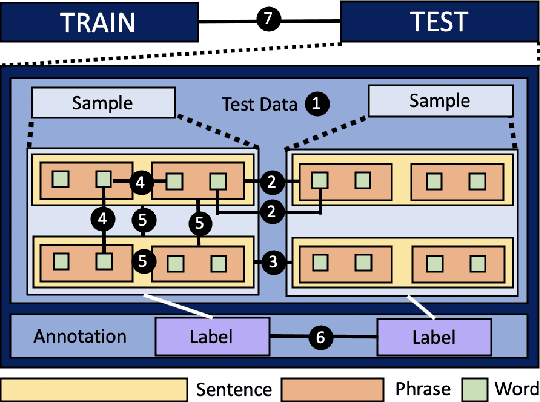
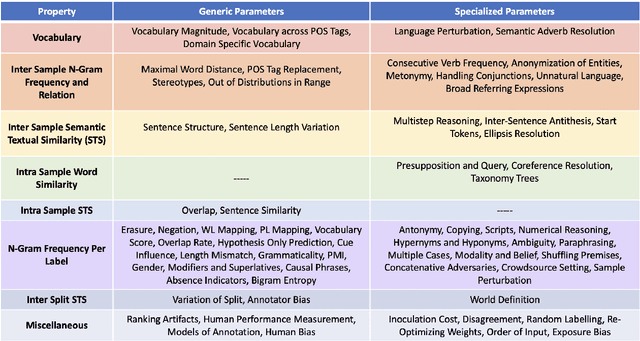
Several benchmarks have been built with heavy investment in resources to track our progress in NLP. Thousands of papers published in response to those benchmarks have competed to top leaderboards, with models often surpassing human performance. However, recent studies have shown that models triumph over several popular benchmarks just by overfitting on spurious biases, without truly learning the desired task. Despite this finding, benchmarking, while trying to tackle bias, still relies on workarounds, which do not fully utilize the resources invested in benchmark creation, due to the discarding of low quality data, and cover limited sets of bias. A potential solution to these issues -- a metric quantifying quality -- remains underexplored. Inspired by successful quality indices in several domains such as power, food, and water, we take the first step towards a metric by identifying certain language properties that can represent various possible interactions leading to biases in a benchmark. We look for bias related parameters which can potentially help pave our way towards the metric. We survey existing works and identify parameters capturing various properties of bias, their origins, types and impact on performance, generalization, and robustness. Our analysis spans over datasets and a hierarchy of tasks ranging from NLI to Summarization, ensuring that our parameters are generic and are not overfitted towards a specific task or dataset. We also develop certain parameters in this process.
Hardness of Samples Need to be Quantified for a Reliable Evaluation System: Exploring Potential Opportunities with a New Task
Oct 14, 2022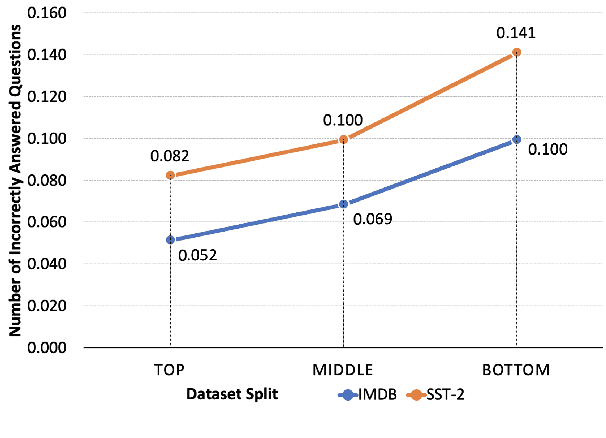
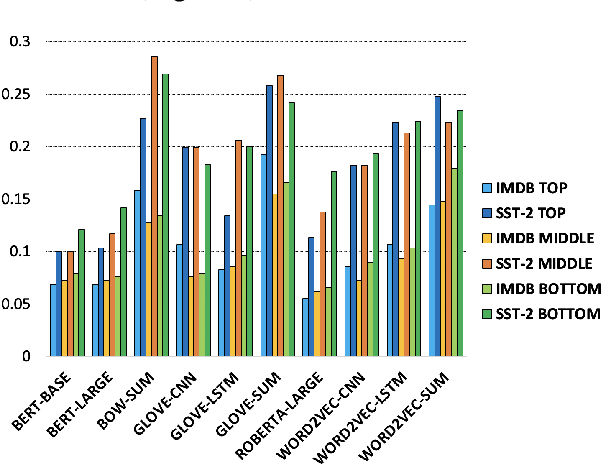
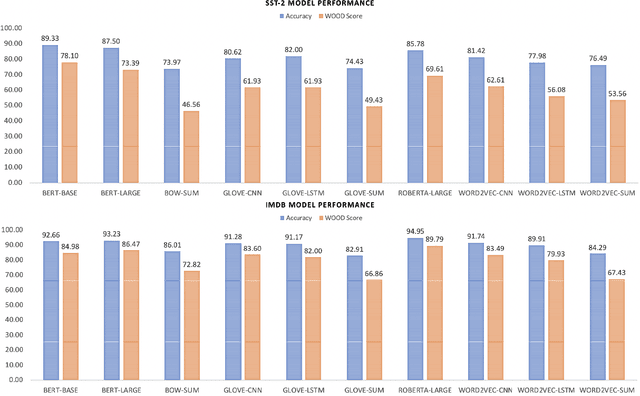
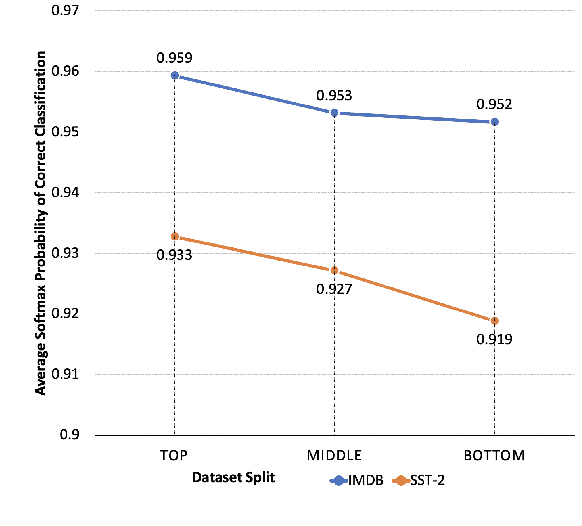
Evaluation of models on benchmarks is unreliable without knowing the degree of sample hardness; this subsequently overestimates the capability of AI systems and limits their adoption in real world applications. We propose a Data Scoring task that requires assignment of each unannotated sample in a benchmark a score between 0 to 1, where 0 signifies easy and 1 signifies hard. Use of unannotated samples in our task design is inspired from humans who can determine a question difficulty without knowing its correct answer. This also rules out the use of methods involving model based supervision (since they require sample annotations to get trained), eliminating potential biases associated with models in deciding sample difficulty. We propose a method based on Semantic Textual Similarity (STS) for this task; we validate our method by showing that existing models are more accurate with respect to the easier sample-chunks than with respect to the harder sample-chunks. Finally we demonstrate five novel applications.
Investigating the Failure Modes of the AUC metric and Exploring Alternatives for Evaluating Systems in Safety Critical Applications
Oct 10, 2022
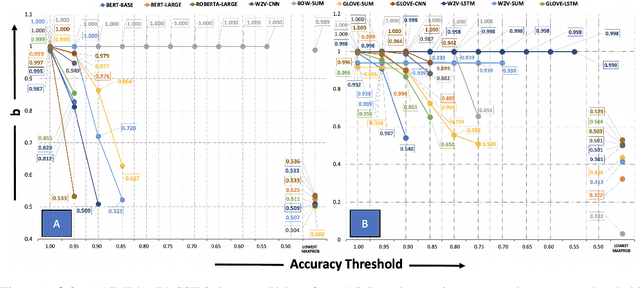
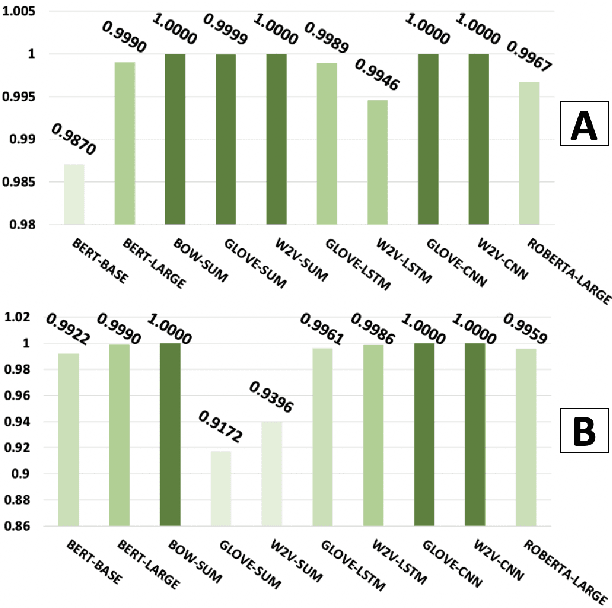

With the increasing importance of safety requirements associated with the use of black box models, evaluation of selective answering capability of models has been critical. Area under the curve (AUC) is used as a metric for this purpose. We find limitations in AUC; e.g., a model having higher AUC is not always better in performing selective answering. We propose three alternate metrics that fix the identified limitations. On experimenting with ten models, our results using the new metrics show that newer and larger pre-trained models do not necessarily show better performance in selective answering. We hope our insights will help develop better models tailored for safety-critical applications.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

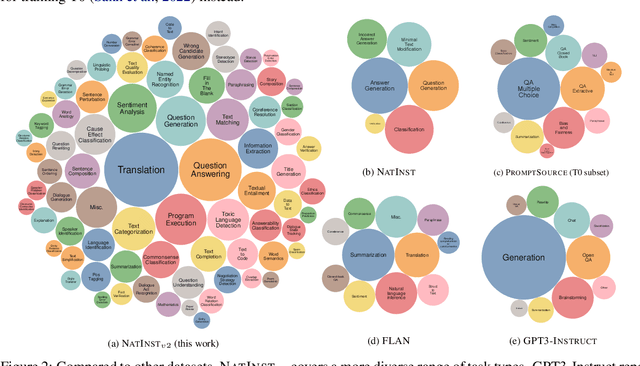
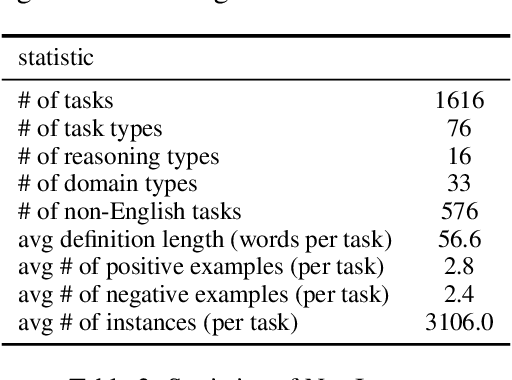
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
A Proposal to Study "Is High Quality Data All We Need?"
Mar 12, 2022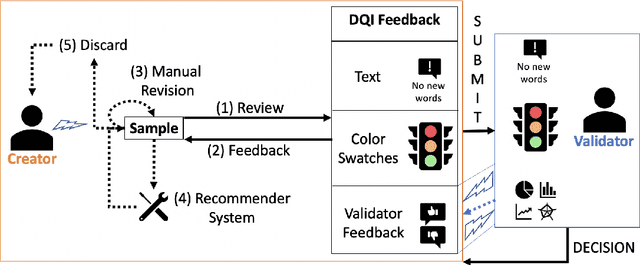

Even though deep neural models have achieved superhuman performance on many popular benchmarks, they have failed to generalize to OOD or adversarial datasets. Conventional approaches aimed at increasing robustness include developing increasingly large models and augmentation with large scale datasets. However, orthogonal to these trends, we hypothesize that a smaller, high quality dataset is what we need. Our hypothesis is based on the fact that deep neural networks are data driven models, and data is what leads/misleads models. In this work, we propose an empirical study that examines how to select a subset of and/or create high quality benchmark data, for a model to learn effectively. We seek to answer if big datasets are truly needed to learn a task, and whether a smaller subset of high quality data can replace big datasets. We plan to investigate both data pruning and data creation paradigms to generate high quality datasets.
Front Contribution instead of Back Propagation
Jun 10, 2021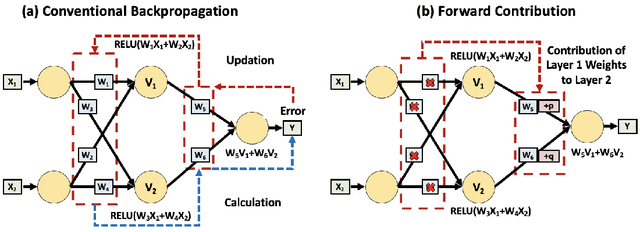
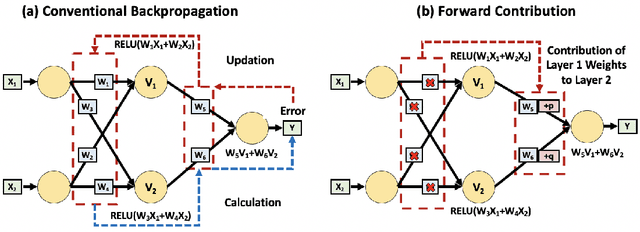
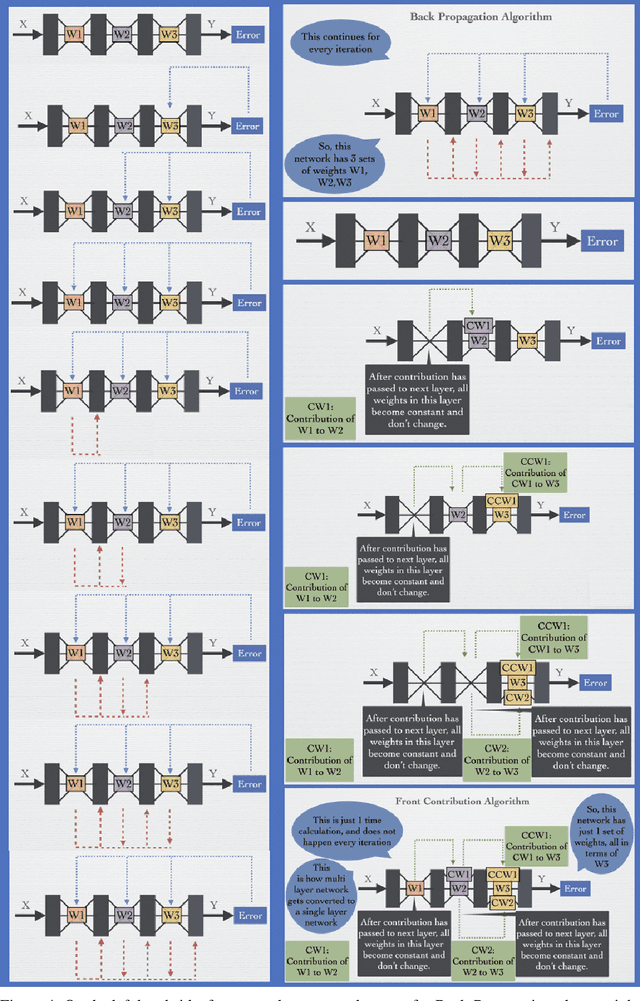
Deep Learning's outstanding track record across several domains has stemmed from the use of error backpropagation (BP). Several studies, however, have shown that it is impossible to execute BP in a real brain. Also, BP still serves as an important and unsolved bottleneck for memory usage and speed. We propose a simple, novel algorithm, the Front-Contribution algorithm, as a compact alternative to BP. The contributions of all weights with respect to the final layer weights are calculated before training commences and all the contributions are appended to weights of the final layer, i.e., the effective final layer weights are a non-linear function of themselves. Our algorithm then essentially collapses the network, precluding the necessity for weight updation of all weights not in the final layer. This reduction in parameters results in lower memory usage and higher training speed. We show that our algorithm produces the exact same output as BP, in contrast to several recently proposed algorithms approximating BP. Our preliminary experiments demonstrate the efficacy of the proposed algorithm. Our work provides a foundation to effectively utilize these presently under-explored "front contributions", and serves to inspire the next generation of training algorithms.
How Robust are Model Rankings: A Leaderboard Customization Approach for Equitable Evaluation
Jun 10, 2021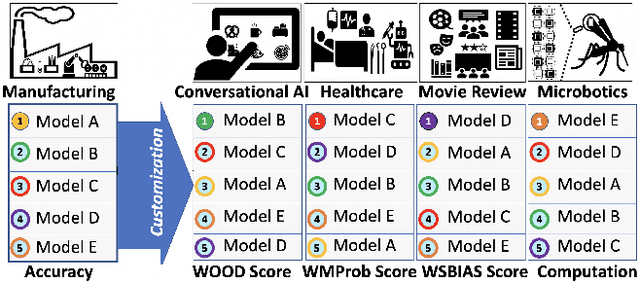
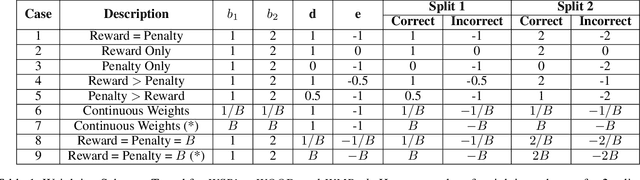
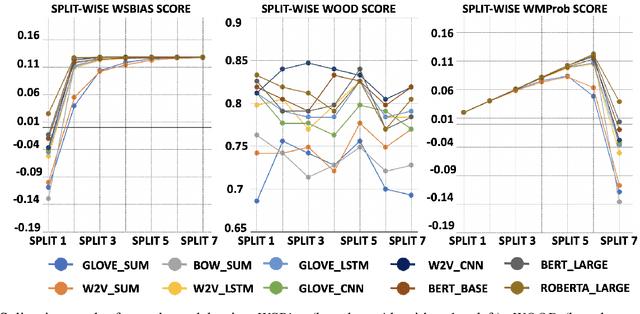
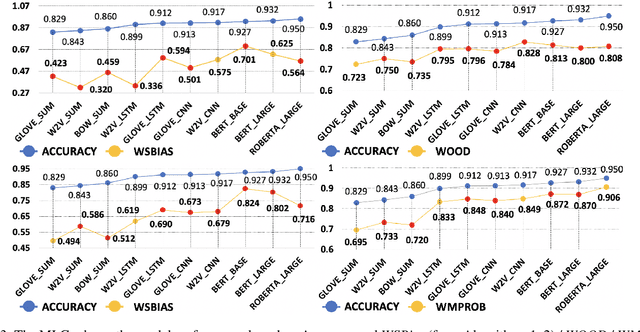
Models that top leaderboards often perform unsatisfactorily when deployed in real world applications; this has necessitated rigorous and expensive pre-deployment model testing. A hitherto unexplored facet of model performance is: Are our leaderboards doing equitable evaluation? In this paper, we introduce a task-agnostic method to probe leaderboards by weighting samples based on their `difficulty' level. We find that leaderboards can be adversarially attacked and top performing models may not always be the best models. We subsequently propose alternate evaluation metrics. Our experiments on 10 models show changes in model ranking and an overall reduction in previously reported performance -- thus rectifying the overestimation of AI systems' capabilities. Inspired by behavioral testing principles, we further develop a prototype of a visual analytics tool that enables leaderboard revamping through customization, based on an end user's focus area. This helps users analyze models' strengths and weaknesses, and guides them in the selection of a model best suited for their application scenario. In a user study, members of various commercial product development teams, covering 5 focus areas, find that our prototype reduces pre-deployment development and testing effort by 41% on average.
DQI: A Guide to Benchmark Evaluation
Aug 10, 2020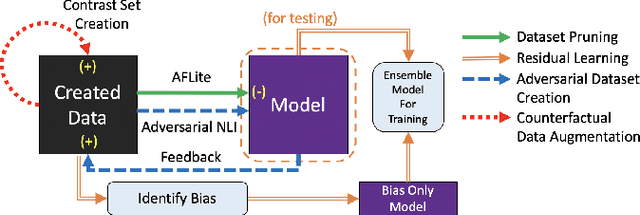


A `state of the art' model A surpasses humans in a benchmark B, but fails on similar benchmarks C, D, and E. What does B have that the other benchmarks do not? Recent research provides the answer: spurious bias. However, developing A to solve benchmarks B through E does not guarantee that it will solve future benchmarks. To progress towards a model that `truly learns' an underlying task, we need to quantify the differences between successive benchmarks, as opposed to existing binary and black-box approaches. We propose a novel approach to solve this underexplored task of quantifying benchmark quality by debuting a data quality metric: DQI.