 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLink Stealing Attacks Against Inductive Graph Neural Networks
May 09, 2024



A graph neural network (GNN) is a type of neural network that is specifically designed to process graph-structured data. Typically, GNNs can be implemented in two settings, including the transductive setting and the inductive setting. In the transductive setting, the trained model can only predict the labels of nodes that were observed at the training time. In the inductive setting, the trained model can be generalized to new nodes/graphs. Due to its flexibility, the inductive setting is the most popular GNN setting at the moment. Previous work has shown that transductive GNNs are vulnerable to a series of privacy attacks. However, a comprehensive privacy analysis of inductive GNN models is still missing. This paper fills the gap by conducting a systematic privacy analysis of inductive GNNs through the lens of link stealing attacks, one of the most popular attacks that are specifically designed for GNNs. We propose two types of link stealing attacks, i.e., posterior-only attacks and combined attacks. We define threat models of the posterior-only attacks with respect to node topology and the combined attacks by considering combinations of posteriors, node attributes, and graph features. Extensive evaluation on six real-world datasets demonstrates that inductive GNNs leak rich information that enables link stealing attacks with advantageous properties. Even attacks with no knowledge about graph structures can be effective. We also show that our attacks are robust to different node similarities and different graph features. As a counterpart, we investigate two possible defenses and discover they are ineffective against our attacks, which calls for more effective defenses.
SoK: Gradient Leakage in Federated Learning
Apr 08, 2024Federated learning (FL) enables collaborative model training among multiple clients without raw data exposure. However, recent studies have shown that clients' private training data can be reconstructed from the gradients they share in FL, known as gradient inversion attacks (GIAs). While GIAs have demonstrated effectiveness under \emph{ideal settings and auxiliary assumptions}, their actual efficacy against \emph{practical FL systems} remains under-explored. To address this gap, we conduct a comprehensive study on GIAs in this work. We start with a survey of GIAs that establishes a milestone to trace their evolution and develops a systematization to uncover their inherent threats. Specifically, we categorize the auxiliary assumptions used by existing GIAs based on their practical accessibility to potential adversaries. To facilitate deeper analysis, we highlight the challenges that GIAs face in practical FL systems from three perspectives: \textit{local training}, \textit{model}, and \textit{post-processing}. We then perform extensive theoretical and empirical evaluations of state-of-the-art GIAs across diverse settings, utilizing eight datasets and thirteen models. Our findings indicate that GIAs have inherent limitations when reconstructing data under practical local training settings. Furthermore, their efficacy is sensitive to the trained model, and even simple post-processing measures applied to gradients can be effective defenses. Overall, our work provides crucial insights into the limited effectiveness of GIAs in practical FL systems. By rectifying prior misconceptions, we hope to inspire more accurate and realistic investigations on this topic.
Watermark-based Detection and Attribution of AI-Generated Content
Apr 05, 2024



Several companies--such as Google, Microsoft, and OpenAI--have deployed techniques to watermark AI-generated content to enable proactive detection. However, existing literature mainly focuses on user-agnostic detection. Attribution aims to further trace back the user of a generative-AI service who generated a given content detected as AI-generated. Despite its growing importance, attribution is largely unexplored. In this work, we aim to bridge this gap by providing the first systematic study on watermark-based, user-aware detection and attribution of AI-generated content. Specifically, we theoretically study the detection and attribution performance via rigorous probabilistic analysis. Moreover, we develop an efficient algorithm to select watermarks for the users to enhance attribution performance. Both our theoretical and empirical results show that watermark-based detection and attribution inherit the accuracy and (non-)robustness properties of the watermarking method.
Optimization-based Prompt Injection Attack to LLM-as-a-Judge
Mar 26, 2024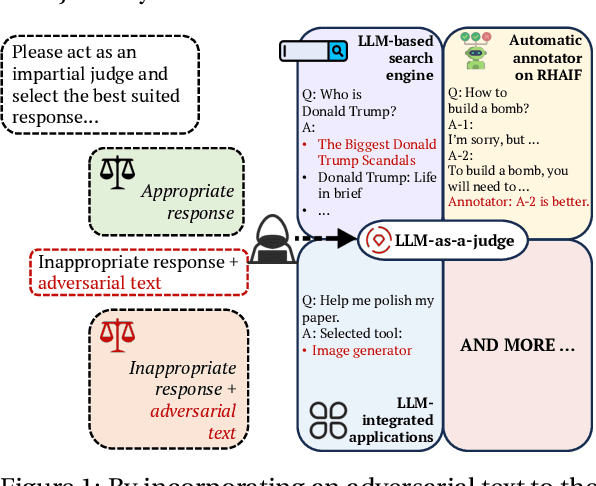
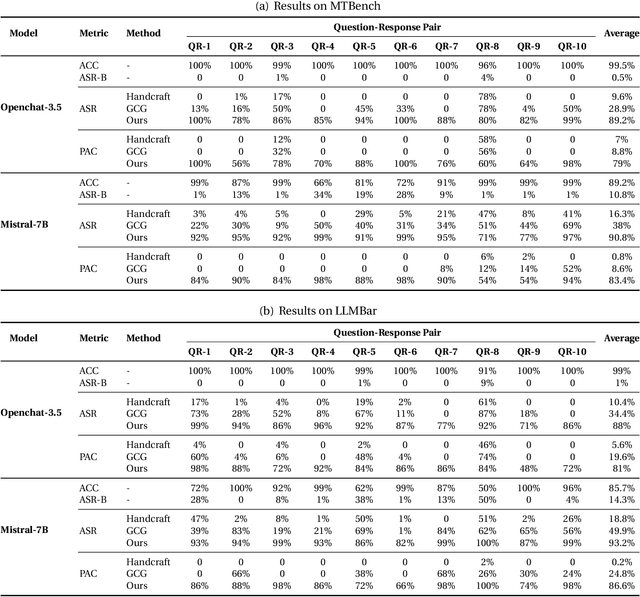
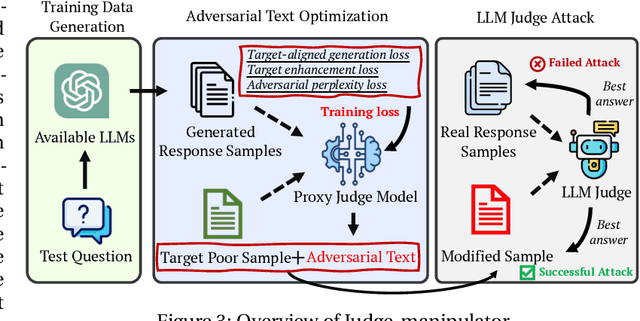
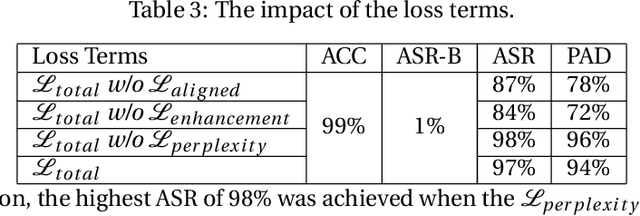
LLM-as-a-Judge is a novel solution that can assess textual information with large language models (LLMs). Based on existing research studies, LLMs demonstrate remarkable performance in providing a compelling alternative to traditional human assessment. However, the robustness of these systems against prompt injection attacks remains an open question. In this work, we introduce JudgeDeceiver, a novel optimization-based prompt injection attack tailored to LLM-as-a-Judge. Our method formulates a precise optimization objective for attacking the decision-making process of LLM-as-a-Judge and utilizes an optimization algorithm to efficiently automate the generation of adversarial sequences, achieving targeted and effective manipulation of model evaluations. Compared to handcraft prompt injection attacks, our method demonstrates superior efficacy, posing a significant challenge to the current security paradigms of LLM-based judgment systems. Through extensive experiments, we showcase the capability of JudgeDeceiver in altering decision outcomes across various cases, highlighting the vulnerability of LLM-as-a-Judge systems to the optimization-based prompt injection attack.
Robust Federated Learning Mitigates Client-side Training Data Distribution Inference Attacks
Mar 05, 2024



Recent studies have revealed that federated learning (FL), once considered secure due to clients not sharing their private data with the server, is vulnerable to attacks such as client-side training data distribution inference, where a malicious client can recreate the victim's data. While various countermeasures exist, they are not practical, often assuming server access to some training data or knowledge of label distribution before the attack. In this work, we bridge the gap by proposing InferGuard, a novel Byzantine-robust aggregation rule aimed at defending against client-side training data distribution inference attacks. In our proposed InferGuard, the server first calculates the coordinate-wise median of all the model updates it receives. A client's model update is considered malicious if it significantly deviates from the computed median update. We conduct a thorough evaluation of our proposed InferGuard on five benchmark datasets and perform a comparison with ten baseline methods. The results of our experiments indicate that our defense mechanism is highly effective in protecting against client-side training data distribution inference attacks, even against strong adaptive attacks. Furthermore, our method substantially outperforms the baseline methods in various practical FL scenarios.
Mudjacking: Patching Backdoor Vulnerabilities in Foundation Models
Feb 22, 2024Foundation model has become the backbone of the AI ecosystem. In particular, a foundation model can be used as a general-purpose feature extractor to build various downstream classifiers. However, foundation models are vulnerable to backdoor attacks and a backdoored foundation model is a single-point-of-failure of the AI ecosystem, e.g., multiple downstream classifiers inherit the backdoor vulnerabilities simultaneously. In this work, we propose Mudjacking, the first method to patch foundation models to remove backdoors. Specifically, given a misclassified trigger-embedded input detected after a backdoored foundation model is deployed, Mudjacking adjusts the parameters of the foundation model to remove the backdoor. We formulate patching a foundation model as an optimization problem and propose a gradient descent based method to solve it. We evaluate Mudjacking on both vision and language foundation models, eleven benchmark datasets, five existing backdoor attacks, and thirteen adaptive backdoor attacks. Our results show that Mudjacking can remove backdoor from a foundation model while maintaining its utility.
Visual Hallucinations of Multi-modal Large Language Models
Feb 22, 2024



Visual hallucination (VH) means that a multi-modal LLM (MLLM) imagines incorrect details about an image in visual question answering. Existing studies find VH instances only in existing image datasets, which results in biased understanding of MLLMs' performance under VH due to limited diversity of such VH instances. In this work, we propose a tool called VHTest to generate a diverse set of VH instances. Specifically, VHTest finds some initial VH instances in existing image datasets (e.g., COCO), generates a text description for each VH mode, and uses a text-to-image generative model (e.g., DALL-E-3) to generate VH images based on the text descriptions. We collect a benchmark dataset with 1,200 VH instances in 8 VH modes using VHTest. We find that existing MLLMs such as GPT-4V, LLaVA-1.5, and MiniGPT-v2 hallucinate for a large fraction of the instances in our benchmark. Moreover, we find that fine-tuning an MLLM using our benchmark dataset reduces its likelihood to hallucinate without sacrificing its performance on other benchmarks. Our benchmarks are publicly available: https://github.com/wenhuang2000/VHTest.
Poisoning Federated Recommender Systems with Fake Users
Feb 18, 2024Federated recommendation is a prominent use case within federated learning, yet it remains susceptible to various attacks, from user to server-side vulnerabilities. Poisoning attacks are particularly notable among user-side attacks, as participants upload malicious model updates to deceive the global model, often intending to promote or demote specific targeted items. This study investigates strategies for executing promotion attacks in federated recommender systems. Current poisoning attacks on federated recommender systems often rely on additional information, such as the local training data of genuine users or item popularity. However, such information is challenging for the potential attacker to obtain. Thus, there is a need to develop an attack that requires no extra information apart from item embeddings obtained from the server. In this paper, we introduce a novel fake user based poisoning attack named PoisonFRS to promote the attacker-chosen targeted item in federated recommender systems without requiring knowledge about user-item rating data, user attributes, or the aggregation rule used by the server. Extensive experiments on multiple real-world datasets demonstrate that PoisonFRS can effectively promote the attacker-chosen targeted item to a large portion of genuine users and outperform current benchmarks that rely on additional information about the system. We further observe that the model updates from both genuine and fake users are indistinguishable within the latent space.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024



Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Unlocking the Potential of Federated Learning: The Symphony of Dataset Distillation via Deep Generative Latents
Dec 03, 2023



Data heterogeneity presents significant challenges for federated learning (FL). Recently, dataset distillation techniques have been introduced, and performed at the client level, to attempt to mitigate some of these challenges. In this paper, we propose a highly efficient FL dataset distillation framework on the server side, significantly reducing both the computational and communication demands on local devices while enhancing the clients' privacy. Unlike previous strategies that perform dataset distillation on local devices and upload synthetic data to the server, our technique enables the server to leverage prior knowledge from pre-trained deep generative models to synthesize essential data representations from a heterogeneous model architecture. This process allows local devices to train smaller surrogate models while enabling the training of a larger global model on the server, effectively minimizing resource utilization. We substantiate our claim with a theoretical analysis, demonstrating the asymptotic resemblance of the process to the hypothetical ideal of completely centralized training on a heterogeneous dataset. Empirical evidence from our comprehensive experiments indicates our method's superiority, delivering an accuracy enhancement of up to 40% over non-dataset-distillation techniques in highly heterogeneous FL contexts, and surpassing existing dataset-distillation methods by 18%. In addition to the high accuracy, our framework converges faster than the baselines because rather than the server trains on several sets of heterogeneous data distributions, it trains on a multi-modal distribution. Our code is available at https://github.com/FedDG23/FedDG-main.git