 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Level Data-Use Auditing of Visual ML Models
Mar 28, 2025The growing trend of legal disputes over the unauthorized use of data in machine learning (ML) systems highlights the urgent need for reliable data-use auditing mechanisms to ensure accountability and transparency in ML. In this paper, we present the first proactive instance-level data-use auditing method designed to enable data owners to audit the use of their individual data instances in ML models, providing more fine-grained auditing results. Our approach integrates any black-box membership inference technique with a sequential hypothesis test, providing a quantifiable and tunable false-detection rate. We evaluate our method on three types of visual ML models: image classifiers, visual encoders, and Contrastive Image-Language Pretraining (CLIP) models. In additional, we apply our method to evaluate the performance of two state-of-the-art approximate unlearning methods. Our findings reveal that neither method successfully removes the influence of the unlearned data instances from image classifiers and CLIP models even if sacrificing model utility by $10.33\%$.
A General Framework for Data-Use Auditing of ML Models
Jul 21, 2024Auditing the use of data in training machine-learning (ML) models is an increasingly pressing challenge, as myriad ML practitioners routinely leverage the effort of content creators to train models without their permission. In this paper, we propose a general method to audit an ML model for the use of a data-owner's data in training, without prior knowledge of the ML task for which the data might be used. Our method leverages any existing black-box membership inference method, together with a sequential hypothesis test of our own design, to detect data use with a quantifiable, tunable false-detection rate. We show the effectiveness of our proposed framework by applying it to audit data use in two types of ML models, namely image classifiers and foundation models.
Concealing Backdoor Model Updates in Federated Learning by Trigger-Optimized Data Poisoning
May 10, 2024



Federated Learning (FL) is a decentralized machine learning method that enables participants to collaboratively train a model without sharing their private data. Despite its privacy and scalability benefits, FL is susceptible to backdoor attacks, where adversaries poison the local training data of a subset of clients using a backdoor trigger, aiming to make the aggregated model produce malicious results when the same backdoor condition is met by an inference-time input. Existing backdoor attacks in FL suffer from common deficiencies: fixed trigger patterns and reliance on the assistance of model poisoning. State-of-the-art defenses based on Byzantine-robust aggregation exhibit a good defense performance on these attacks because of the significant divergence between malicious and benign model updates. To effectively conceal malicious model updates among benign ones, we propose DPOT, a backdoor attack strategy in FL that dynamically constructs backdoor objectives by optimizing a backdoor trigger, making backdoor data have minimal effect on model updates. We provide theoretical justifications for DPOT's attacking principle and display experimental results showing that DPOT, via only a data-poisoning attack, effectively undermines state-of-the-art defenses and outperforms existing backdoor attack techniques on various datasets.
Mudjacking: Patching Backdoor Vulnerabilities in Foundation Models
Feb 22, 2024Foundation model has become the backbone of the AI ecosystem. In particular, a foundation model can be used as a general-purpose feature extractor to build various downstream classifiers. However, foundation models are vulnerable to backdoor attacks and a backdoored foundation model is a single-point-of-failure of the AI ecosystem, e.g., multiple downstream classifiers inherit the backdoor vulnerabilities simultaneously. In this work, we propose Mudjacking, the first method to patch foundation models to remove backdoors. Specifically, given a misclassified trigger-embedded input detected after a backdoored foundation model is deployed, Mudjacking adjusts the parameters of the foundation model to remove the backdoor. We formulate patching a foundation model as an optimization problem and propose a gradient descent based method to solve it. We evaluate Mudjacking on both vision and language foundation models, eleven benchmark datasets, five existing backdoor attacks, and thirteen adaptive backdoor attacks. Our results show that Mudjacking can remove backdoor from a foundation model while maintaining its utility.
Mendata: A Framework to Purify Manipulated Training Data
Dec 03, 2023Untrusted data used to train a model might have been manipulated to endow the learned model with hidden properties that the data contributor might later exploit. Data purification aims to remove such manipulations prior to training the model. We propose Mendata, a novel framework to purify manipulated training data. Starting from a small reference dataset in which a large majority of the inputs are clean, Mendata perturbs the training inputs so that they retain their utility but are distributed similarly (as measured by Wasserstein distance) to the reference data, thereby eliminating hidden properties from the learned model. A key challenge is how to find such perturbations, which we address by formulating a min-max optimization problem and developing a two-step method to iteratively solve it. We demonstrate the effectiveness of Mendata by applying it to defeat state-of-the-art data poisoning and data tracing techniques.
Group-based Robustness: A General Framework for Customized Robustness in the Real World
Jun 29, 2023Machine-learning models are known to be vulnerable to evasion attacks that perturb model inputs to induce misclassifications. In this work, we identify real-world scenarios where the true threat cannot be assessed accurately by existing attacks. Specifically, we find that conventional metrics measuring targeted and untargeted robustness do not appropriately reflect a model's ability to withstand attacks from one set of source classes to another set of target classes. To address the shortcomings of existing methods, we formally define a new metric, termed group-based robustness, that complements existing metrics and is better-suited for evaluating model performance in certain attack scenarios. We show empirically that group-based robustness allows us to distinguish between models' vulnerability against specific threat models in situations where traditional robustness metrics do not apply. Moreover, to measure group-based robustness efficiently and accurately, we 1) propose two loss functions and 2) identify three new attack strategies. We show empirically that with comparable success rates, finding evasive samples using our new loss functions saves computation by a factor as large as the number of targeted classes, and finding evasive samples using our new attack strategies saves time by up to 99\% compared to brute-force search methods. Finally, we propose a defense method that increases group-based robustness by up to 3.52$\times$.
Constrained Gradient Descent: A Powerful and Principled Evasion Attack Against Neural Networks
Dec 28, 2021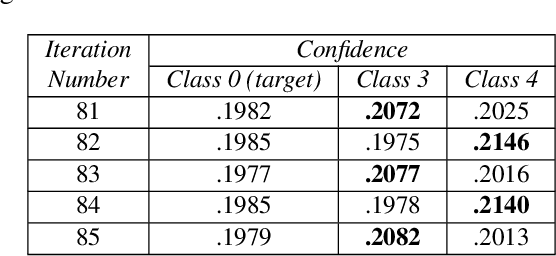
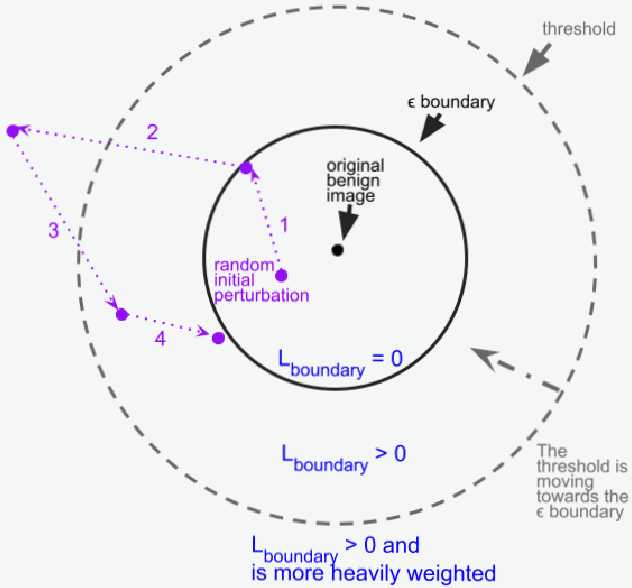
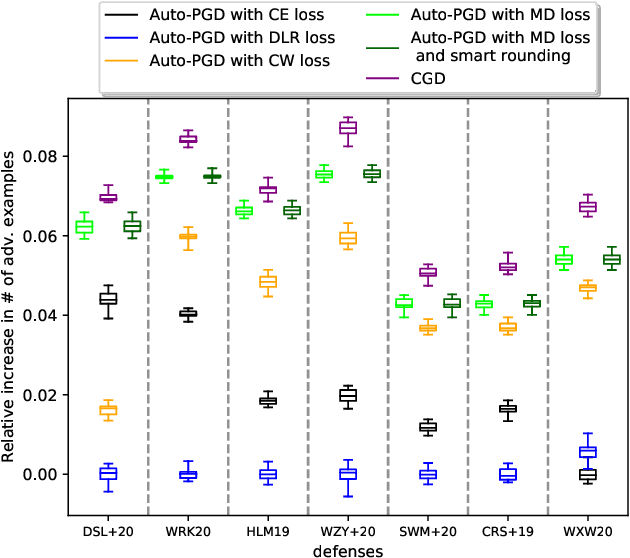
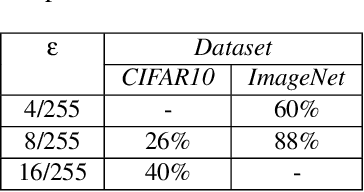
Minimal adversarial perturbations added to inputs have been shown to be effective at fooling deep neural networks. In this paper, we introduce several innovations that make white-box targeted attacks follow the intuition of the attacker's goal: to trick the model to assign a higher probability to the target class than to any other, while staying within a specified distance from the original input. First, we propose a new loss function that explicitly captures the goal of targeted attacks, in particular, by using the logits of all classes instead of just a subset, as is common. We show that Auto-PGD with this loss function finds more adversarial examples than it does with other commonly used loss functions. Second, we propose a new attack method that uses a further developed version of our loss function capturing both the misclassification objective and the $L_{\infty}$ distance limit $\epsilon$. This new attack method is relatively 1.5--4.2% more successful on the CIFAR10 dataset and relatively 8.2--14.9% more successful on the ImageNet dataset, than the next best state-of-the-art attack. We confirm using statistical tests that our attack outperforms state-of-the-art attacks on different datasets and values of $\epsilon$ and against different defenses.
Defense Through Diverse Directions
Mar 24, 2020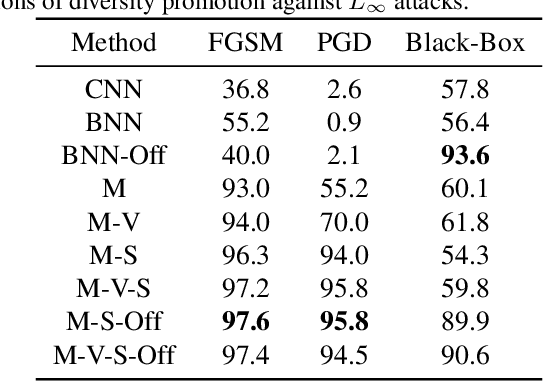
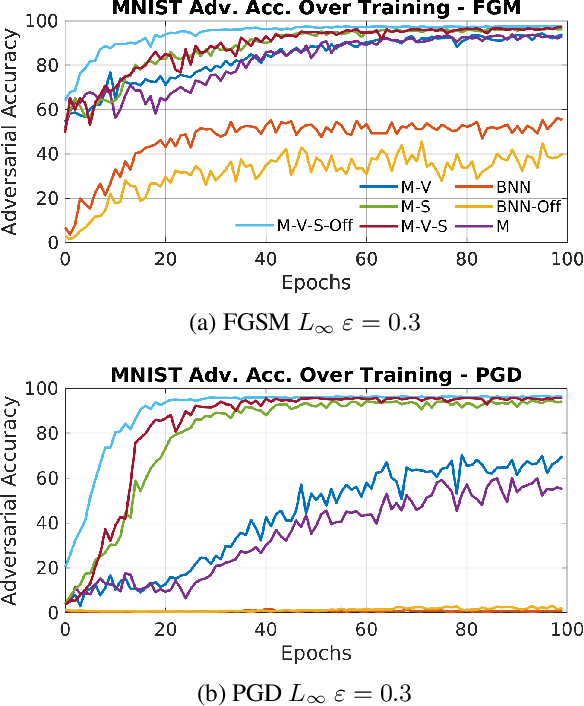
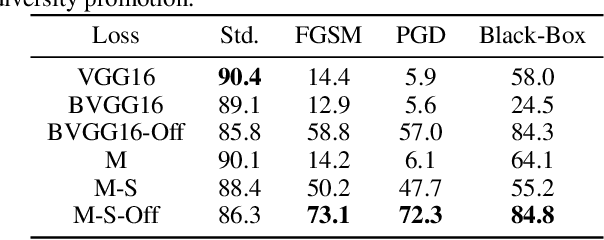
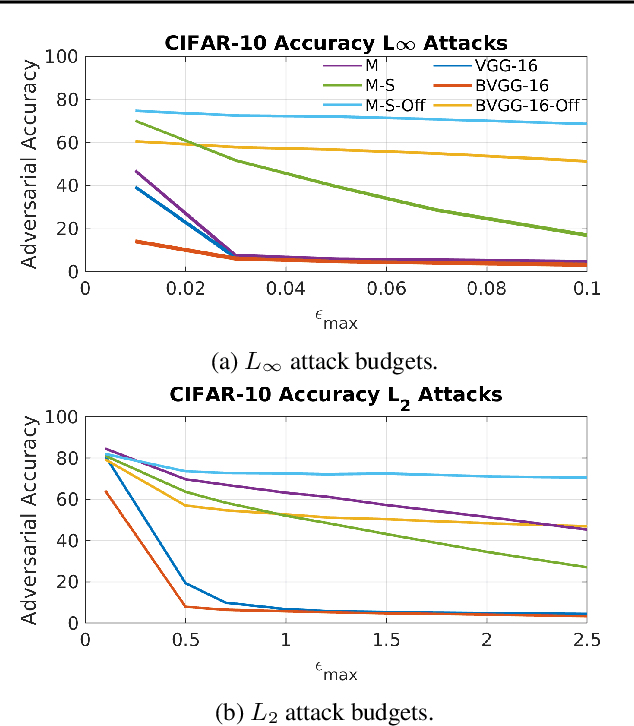
In this work we develop a novel Bayesian neural network methodology to achieve strong adversarial robustness without the need for online adversarial training. Unlike previous efforts in this direction, we do not rely solely on the stochasticity of network weights by minimizing the divergence between the learned parameter distribution and a prior. Instead, we additionally require that the model maintain some expected uncertainty with respect to all input covariates. We demonstrate that by encouraging the network to distribute evenly across inputs, the network becomes less susceptible to localized, brittle features which imparts a natural robustness to targeted perturbations. We show empirical robustness on several benchmark datasets.
Optimization-Guided Binary Diversification to Mislead Neural Networks for Malware Detection
Dec 19, 2019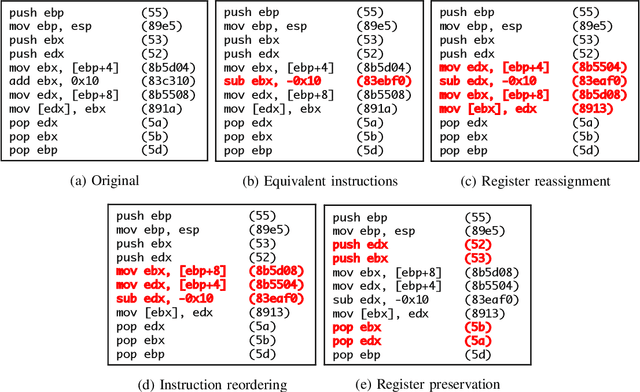

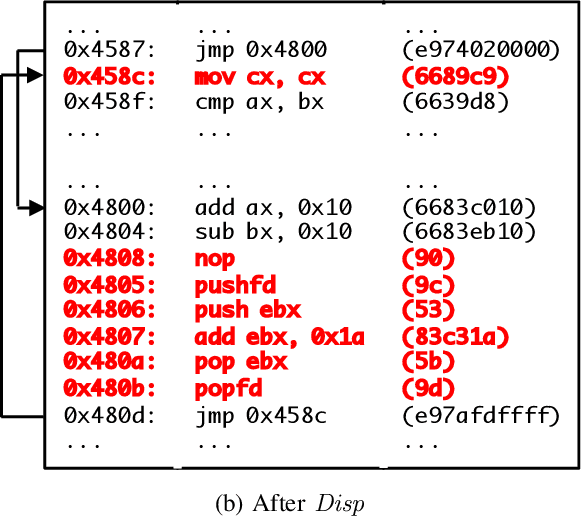
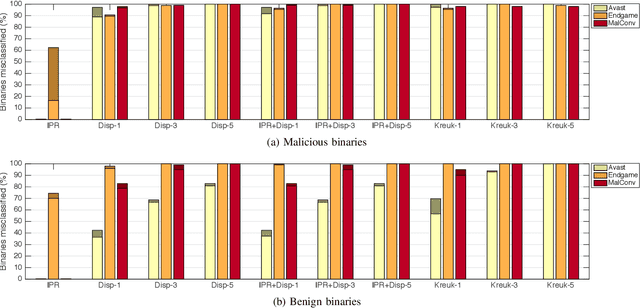
Motivated by the transformative impact of deep neural networks (DNNs) on different areas (e.g., image and speech recognition), researchers and anti-virus vendors are proposing end-to-end DNNs for malware detection from raw bytes that do not require manual feature engineering. Given the security sensitivity of the task that these DNNs aim to solve, it is important to assess their susceptibility to evasion. In this work, we propose an attack that guides binary-diversification tools via optimization to mislead DNNs for malware detection while preserving the functionality of binaries. Unlike previous attacks on such DNNs, ours manipulates instructions that are a functional part of the binary, which makes it particularly challenging to defend against. We evaluated our attack against three DNNs in white-box and black-box settings, and found that it can often achieve success rates near 100%. Moreover, we found that our attack can fool some commercial anti-viruses, in certain cases with a success rate of 85%. We explored several defenses, both new and old, and identified some that can successfully prevent over 80% of our evasion attempts. However, these defenses may still be susceptible to evasion by adaptive attackers, and so we advocate for augmenting malware-detection systems with methods that do not rely on machine learning.
$n$-ML: Mitigating Adversarial Examples via Ensembles of Topologically Manipulated Classifiers
Dec 19, 2019

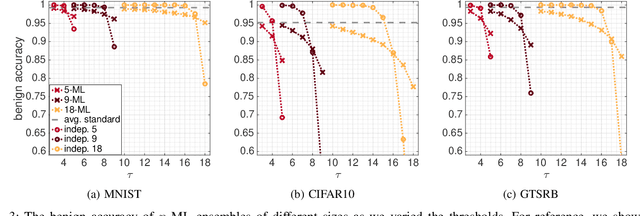
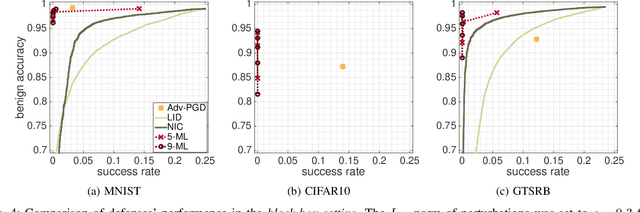
This paper proposes a new defense called $n$-ML against adversarial examples, i.e., inputs crafted by perturbing benign inputs by small amounts to induce misclassifications by classifiers. Inspired by $n$-version programming, $n$-ML trains an ensemble of $n$ classifiers, and inputs are classified by a vote of the classifiers in the ensemble. Unlike prior such approaches, however, the classifiers in the ensemble are trained specifically to classify adversarial examples differently, rendering it very difficult for an adversarial example to obtain enough votes to be misclassified. We show that $n$-ML roughly retains the benign classification accuracies of state-of-the-art models on the MNIST, CIFAR10, and GTSRB datasets, while simultaneously defending against adversarial examples with better resilience than the best defenses known to date and, in most cases, with lower classification-time overhead.