 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Imprint
Jun 07, 2021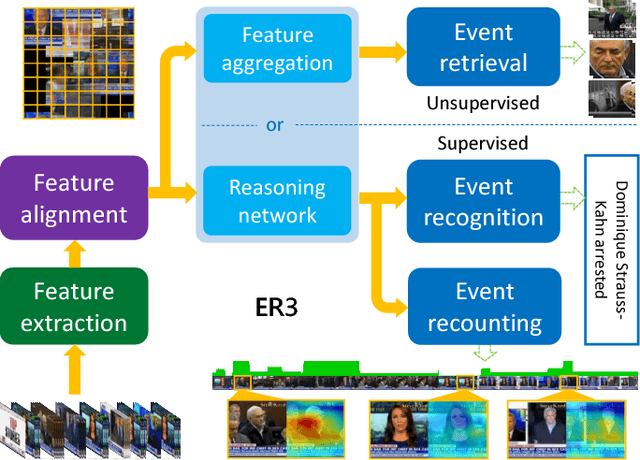


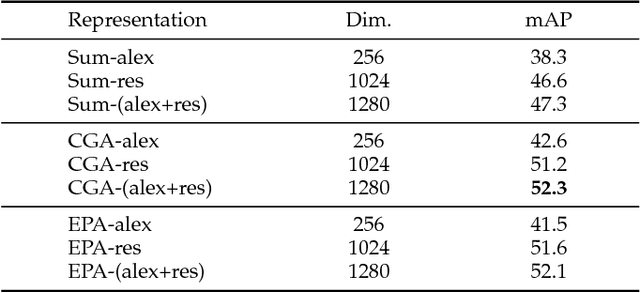
A new unified video analytics framework (ER3) is proposed for complex event retrieval, recognition and recounting, based on the proposed video imprint representation, which exploits temporal correlations among image features across video frames. With the video imprint representation, it is convenient to reverse map back to both temporal and spatial locations in video frames, allowing for both key frame identification and key areas localization within each frame. In the proposed framework, a dedicated feature alignment module is incorporated for redundancy removal across frames to produce the tensor representation, i.e., the video imprint. Subsequently, the video imprint is individually fed into both a reasoning network and a feature aggregation module, for event recognition/recounting and event retrieval tasks, respectively. Thanks to its attention mechanism inspired by the memory networks used in language modeling, the proposed reasoning network is capable of simultaneous event category recognition and localization of the key pieces of evidence for event recounting. In addition, the latent structure in our reasoning network highlights the areas of the video imprint, which can be directly used for event recounting. With the event retrieval task, the compact video representation aggregated from the video imprint contributes to better retrieval results than existing state-of-the-art methods.
Compositional Processing Emerges in Neural Networks Solving Math Problems
May 19, 2021
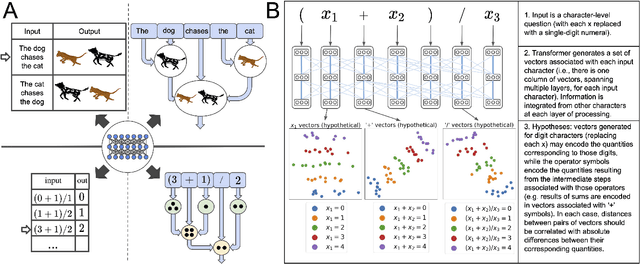
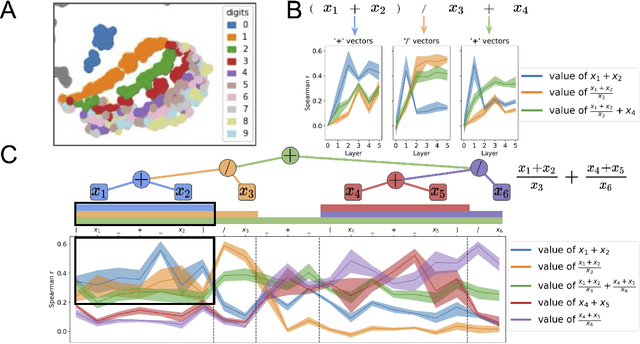
A longstanding question in cognitive science concerns the learning mechanisms underlying compositionality in human cognition. Humans can infer the structured relationships (e.g., grammatical rules) implicit in their sensory observations (e.g., auditory speech), and use this knowledge to guide the composition of simpler meanings into complex wholes. Recent progress in artificial neural networks has shown that when large models are trained on enough linguistic data, grammatical structure emerges in their representations. We extend this work to the domain of mathematical reasoning, where it is possible to formulate precise hypotheses about how meanings (e.g., the quantities corresponding to numerals) should be composed according to structured rules (e.g., order of operations). Our work shows that neural networks are not only able to infer something about the structured relationships implicit in their training data, but can also deploy this knowledge to guide the composition of individual meanings into composite wholes.
High-resolution land cover change from low-resolution labels: Simple baselines for the 2021 IEEE GRSS Data Fusion Contest
Jan 04, 2021
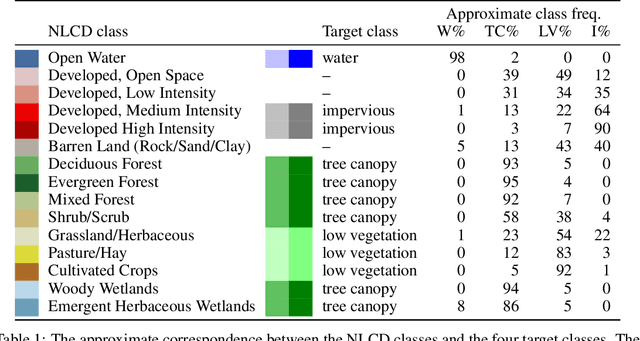

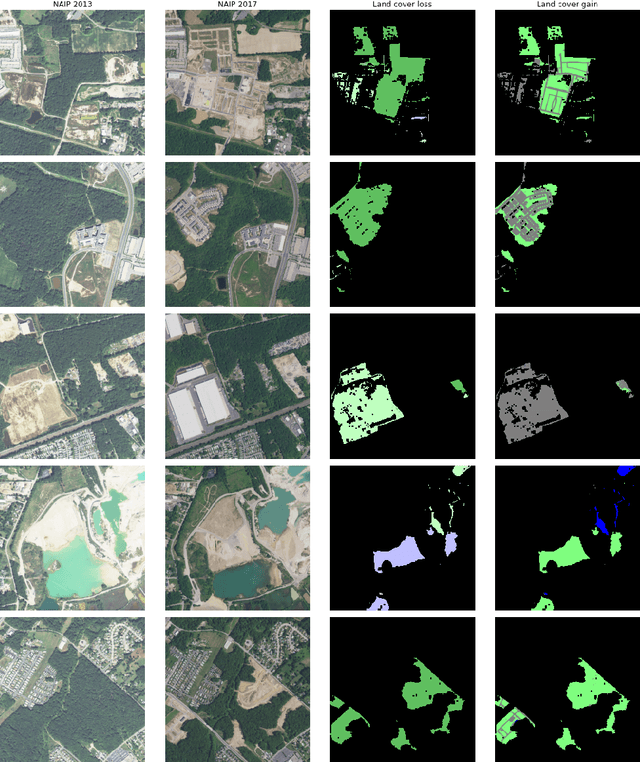
We present simple algorithms for land cover change detection in the 2021 IEEE GRSS Data Fusion Contest. The task of the contest is to create high-resolution (1m / pixel) land cover change maps of a study area in Maryland, USA, given multi-resolution imagery and label data. We study several baseline models for this task and discuss directions for further research. See https://dfc2021.blob.core.windows.net/competition-data/dfc2021_index.txt for the data and https://github.com/calebrob6/dfc2021-msd-baseline for an implementation of these baselines.
Mining self-similarity: Label super-resolution with epitomic representations
Apr 24, 2020
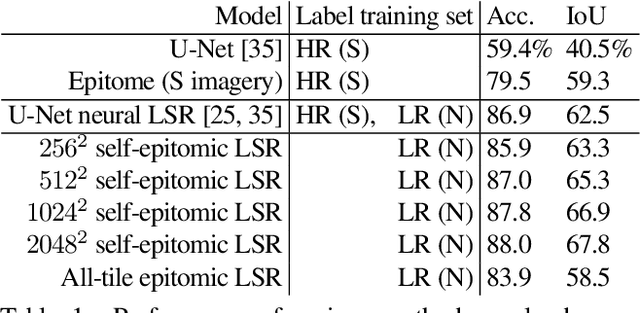

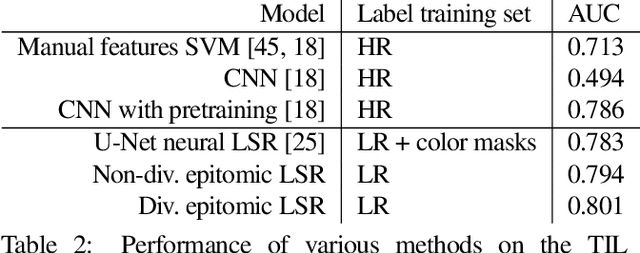
We show that simple patch-based models, such as epitomes, can have superior performance to the current state of the art in semantic segmentation and label super-resolution, which uses deep convolutional neural networks. We derive a new training algorithm for epitomes which allows, for the first time, learning from very large data sets and derive a label super-resolution algorithm as a statistical inference algorithm over epitomic representations. We illustrate our methods on land cover mapping and medical image analysis tasks.
The GeoLifeCLEF 2020 Dataset
Apr 08, 2020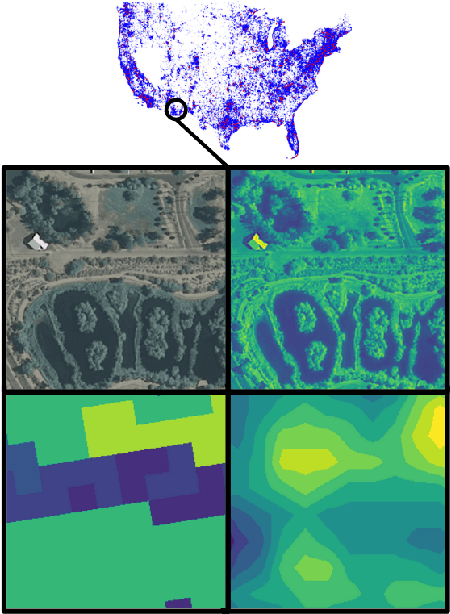
Understanding the geographic distribution of species is a key concern in conservation. By pairing species occurrences with environmental features, researchers can model the relationship between an environment and the species which may be found there. To facilitate research in this area, we present the GeoLifeCLEF 2020 dataset, which consists of 1.9 million species observations paired with high-resolution remote sensing imagery, land cover data, and altitude, in addition to traditional low-resolution climate and soil variables. We also discuss the GeoLifeCLEF 2020 competition, which aims to use this dataset to advance the state-of-the-art in location-based species recommendation.
Local Context Normalization: Revisiting Local Normalization
Dec 13, 2019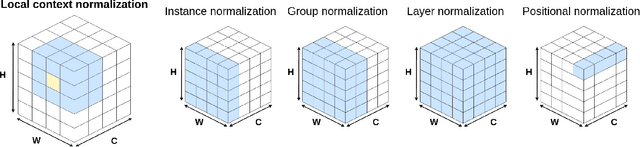
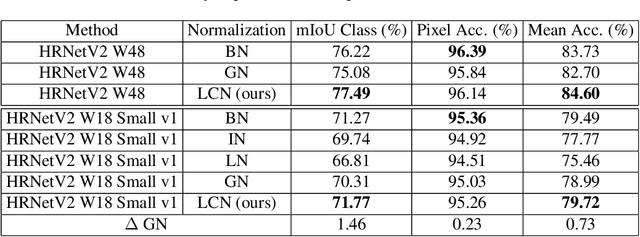
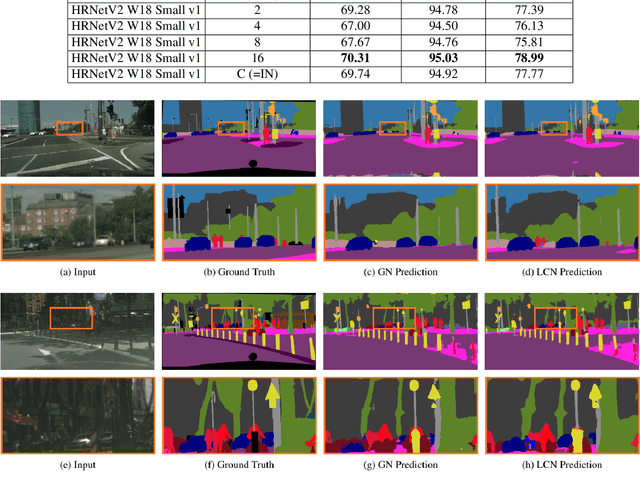

Normalization layers have been shown to improve convergence in deep neural networks. In many vision applications the local spatial context of the features is important, but most common normalization schemes includingGroup Normalization (GN), Instance Normalization (IN), and Layer Normalization (LN) normalize over the entire spatial dimension of a feature. This can wash out important signals and degrade performance. For example, in applications that use satellite imagery, input images can be arbitrarily large; consequently, it is nonsensical to normalize over the entire area. Positional Normalization (PN), on the other hand, only normalizes over a single spatial position at a time. A natural compromise is to normalize features by local context, while also taking into account group level information. In this paper, we propose Local Context Normalization (LCN): a normalization layer where every feature is normalized based on a window around it and the filters in its group. We propose an algorithmic solution to make LCN efficient for arbitrary window sizes, even if every point in the image has a unique window. LCN outperforms its Batch Normalization (BN), GN, IN, and LN counterparts for object detection, semantic segmentation, and instance segmentation applications in several benchmark datasets, while keeping performance independent of the batch size and facilitating transfer learning.
A deep active learning system for species identification and counting in camera trap images
Oct 22, 2019

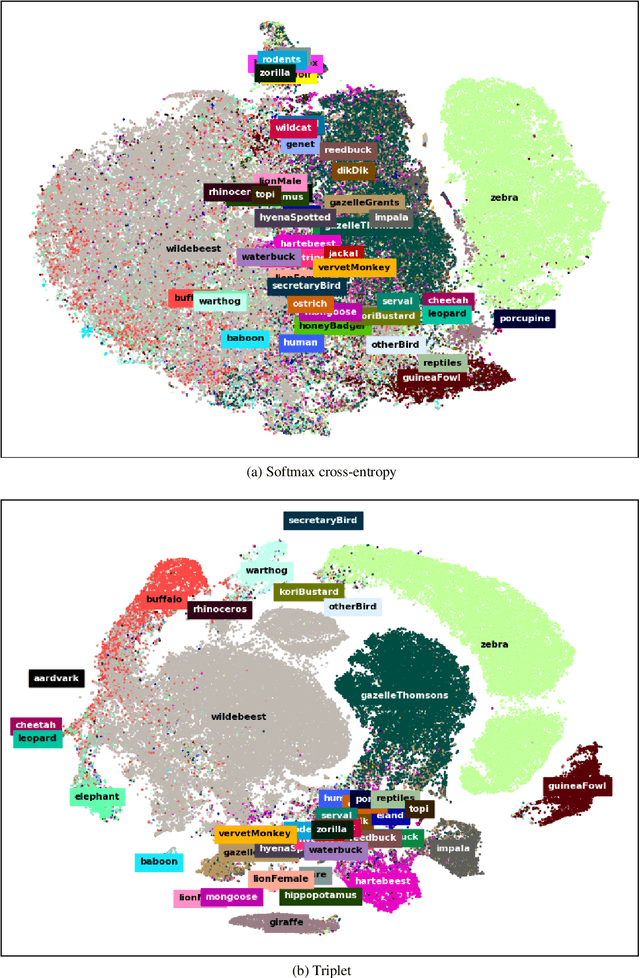
Biodiversity conservation depends on accurate, up-to-date information about wildlife population distributions. Motion-activated cameras, also known as camera traps, are a critical tool for population surveys, as they are cheap and non-intrusive. However, extracting useful information from camera trap images is a cumbersome process: a typical camera trap survey may produce millions of images that require slow, expensive manual review. Consequently, critical information is often lost due to resource limitations, and critical conservation questions may be answered too slowly to support decision-making. Computer vision is poised to dramatically increase efficiency in image-based biodiversity surveys, and recent studies have harnessed deep learning techniques for automatic information extraction from camera trap images. However, the accuracy of results depends on the amount, quality, and diversity of the data available to train models, and the literature has focused on projects with millions of relevant, labeled training images. Many camera trap projects do not have a large set of labeled images and hence cannot benefit from existing machine learning techniques. Furthermore, even projects that do have labeled data from similar ecosystems have struggled to adopt deep learning methods because image classification models overfit to specific image backgrounds (i.e., camera locations). In this paper, we focus not on automating the labeling of camera trap images, but on accelerating this process. We combine the power of machine intelligence and human intelligence to build a scalable, fast, and accurate active learning system to minimize the manual work required to identify and count animals in camera trap images. Our proposed scheme can match the state of the art accuracy on a 3.2 million image dataset with as few as 14,100 manual labels, which means decreasing manual labeling effort by over 99.5%.
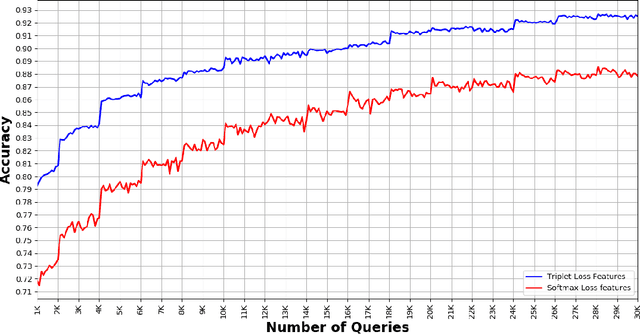
Enhancing the Transformer with Explicit Relational Encoding for Math Problem Solving
Oct 15, 2019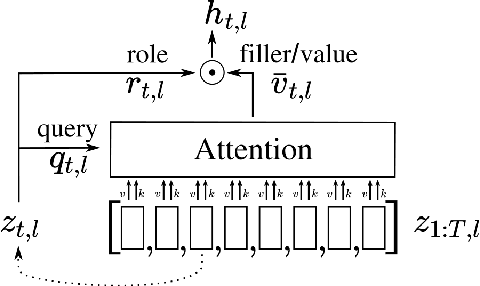
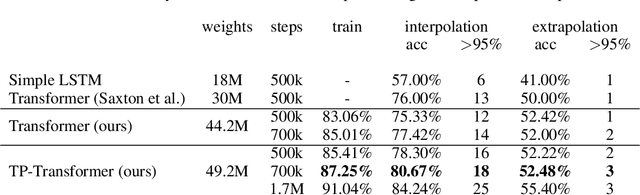
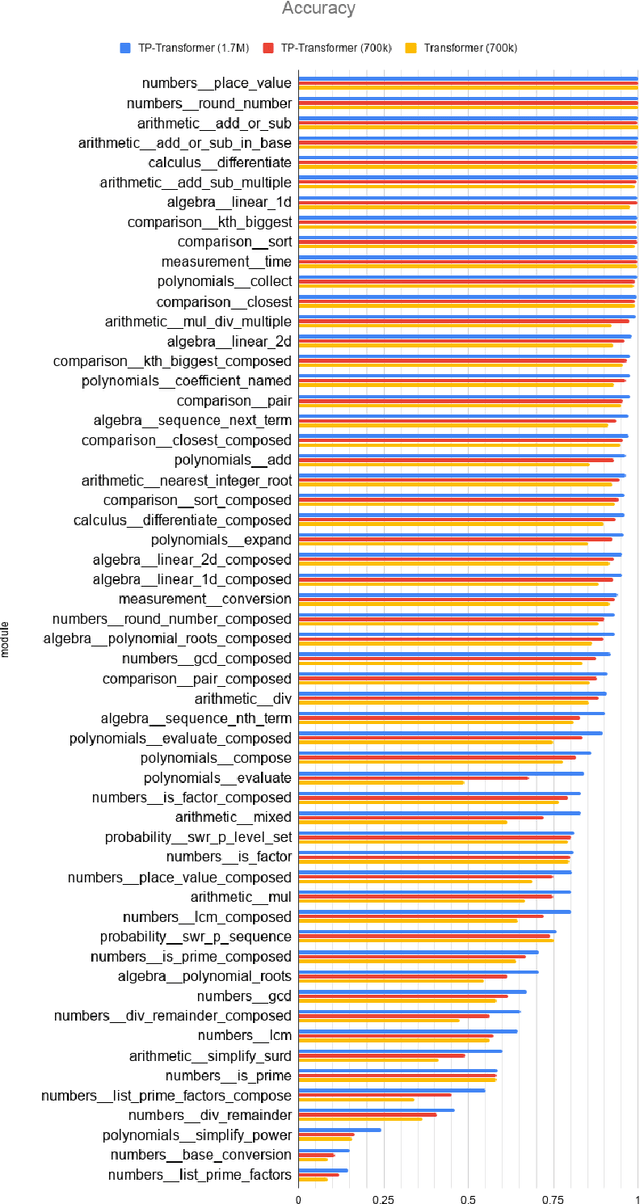

We incorporate Tensor-Product Representations within the Transformer in order to better support the explicit representation of relation structure. Our Tensor-Product Transformer (TP-Transformer) sets a new state of the art on the recently-introduced Mathematics Dataset containing 56 categories of free-form math word-problems. The essential component of the model is a novel attention mechanism, called TP-Attention, which explicitly encodes the relations between each Transformer cell and the other cells from which values have been retrieved by attention. TP-Attention goes beyond linear combination of retrieved values, strengthening representation-building and resolving ambiguities introduced by multiple layers of standard attention. The TP-Transformer's attention maps give better insights into how it is capable of solving the Mathematics Dataset's challenging problems. Pretrained models and code will be made available after publication.
Human-Machine Collaboration for Fast Land Cover Mapping
Jun 26, 2019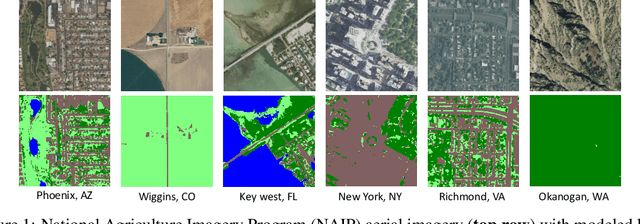
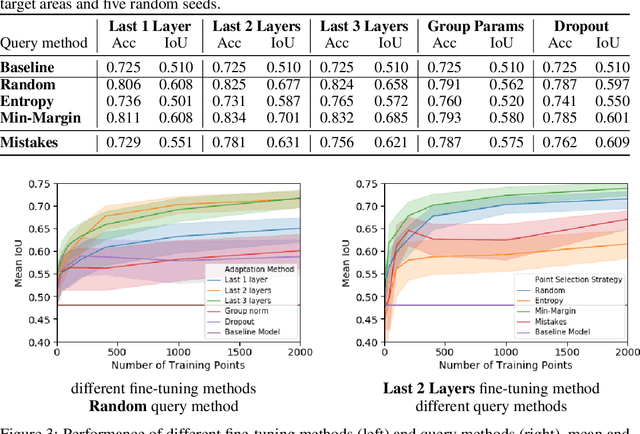
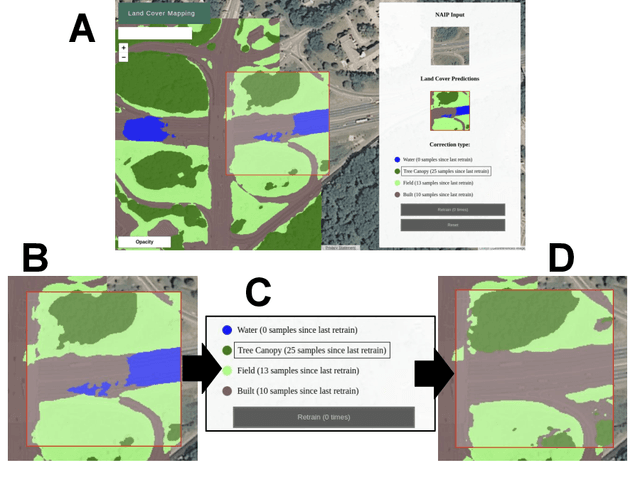
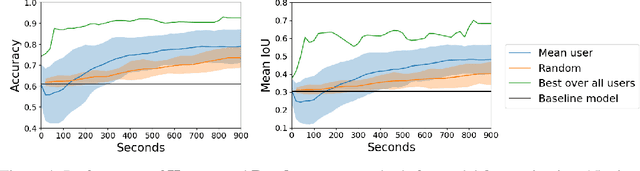
We propose incorporating human labelers in a model fine-tuning system that provides immediate user feedback. In our framework, human labelers can interactively query model predictions on unlabeled data, choose which data to label, and see the resulting effect on the model's predictions. This bi-directional feedback loop allows humans to learn how the model responds to new data. Our hypothesis is that this rich feedback allows human labelers to create mental models that enable them to better choose which biases to introduce to the model. We compare human-selected points to points selected using standard active learning methods. We further investigate how the fine-tuning methodology impacts the human labelers' performance. We implement this framework for fine-tuning high-resolution land cover segmentation models. Specifically, we fine-tune a deep neural network -- trained to segment high-resolution aerial imagery into different land cover classes in Maryland, USA -- to a new spatial area in New York, USA. The tight loop turns the algorithm and the human operator into a hybrid system that can produce land cover maps of a large area much more efficiently than the traditional workflows. Our framework has applications in geospatial machine learning settings where there is a practically limitless supply of unlabeled data, of which only a small fraction can feasibly be labeled through human efforts.
Label Super Resolution with Inter-Instance Loss
Apr 09, 2019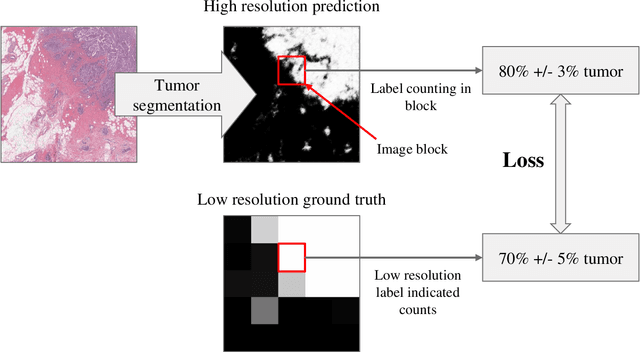
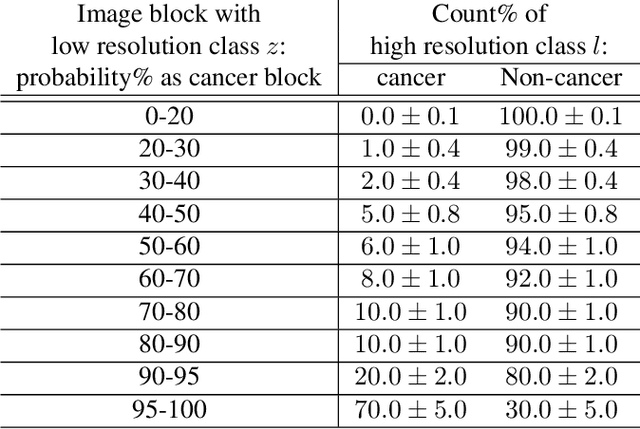
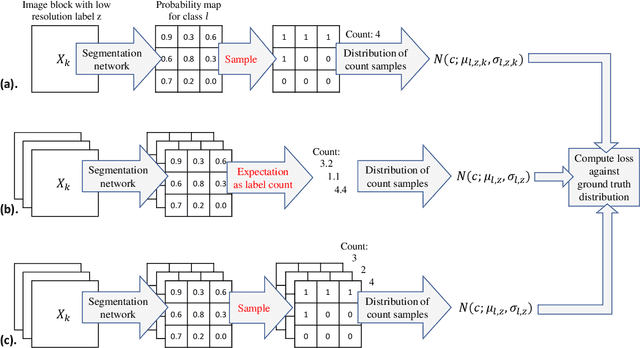

For the task of semantic segmentation, high-resolution (pixel-level) ground truth is very expensive to collect, especially for high resolution images such as gigapixel pathology images. On the other hand, collecting low resolution labels (labels for a block of pixels) for these high resolution images is much more cost efficient. Conventional methods trained on these low-resolution labels are only capable of giving low-resolution predictions. The existing state-of-the-art label super resolution (LSR) method is capable of predicting high resolution labels, using only low-resolution supervision, given the joint distribution between low resolution and high resolution labels. However, it does not consider the inter-instance variance which is crucial in the ideal mathematical formulation. In this work, we propose a novel loss function modeling the inter-instance variance. We test our method on two real world applications: cell detection in multiplex immunohistochemistry (IHC) images, and infiltrating breast cancer region segmentation in histopathology slides. Experimental results show the effectiveness of our method.