 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Routing RAG: Binding Selective Retrieval with Knowledge Verbalization
Apr 01, 2025Selective retrieval improves retrieval-augmented generation (RAG) by reducing distractions from low-quality retrievals and improving efficiency. However, existing approaches under-utilize the inherent knowledge of large language models (LLMs), leading to suboptimal retrieval decisions and degraded generation performance. To bridge this gap, we propose Self-Routing RAG (SR-RAG), a novel framework that binds selective retrieval with knowledge verbalization. SR-RAG enables an LLM to dynamically decide between external retrieval and verbalizing its own parametric knowledge. To this end, we design a multi-task objective that jointly optimizes an LLM on knowledge source selection, knowledge verbalization, and response generation. We further introduce dynamic knowledge source inference via nearest neighbor search to improve the accuracy of knowledge source decision under domain shifts. Fine-tuning three LLMs with SR-RAG significantly improves both their response accuracy and inference latency. Compared to the strongest selective retrieval baseline, SR-RAG reduces retrievals by 29% while improving the performance by 5.1%.
CoKe: Customizable Fine-Grained Story Evaluation via Chain-of-Keyword Rationalization
Mar 21, 2025Evaluating creative text such as human-written stories using language models has always been a challenging task -- owing to the subjectivity of multi-annotator ratings. To mimic the thinking process of humans, chain of thought (CoT) generates free-text explanations that help guide a model's predictions and Self-Consistency (SC) marginalizes predictions over multiple generated explanations. In this study, we discover that the widely-used self-consistency reasoning methods cause suboptimal results due to an objective mismatch between generating 'fluent-looking' explanations vs. actually leading to a good rating prediction for an aspect of a story. To overcome this challenge, we propose $\textbf{C}$hain-$\textbf{o}$f-$\textbf{Ke}$ywords (CoKe), that generates a sequence of keywords $\textit{before}$ generating a free-text rationale, that guide the rating prediction of our evaluation language model. Then, we generate a diverse set of such keywords, and aggregate the scores corresponding to these generations. On the StoryER dataset, CoKe based on our small fine-tuned evaluation models not only reach human-level performance and significantly outperform GPT-4 with a 2x boost in correlation with human annotators, but also requires drastically less number of parameters.
OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement
Mar 21, 2025
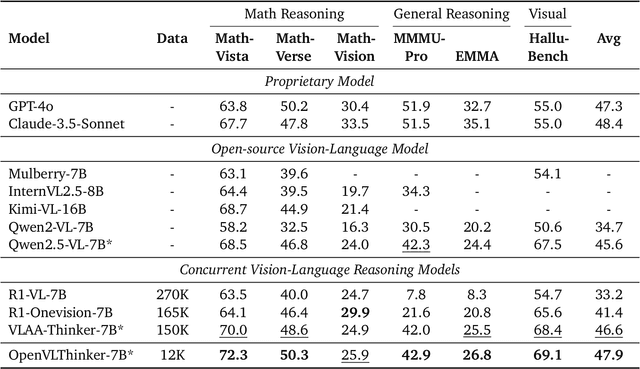
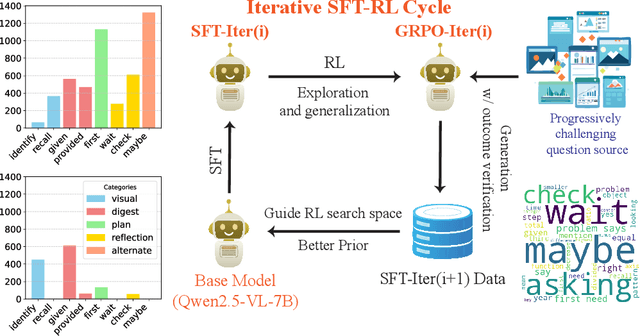
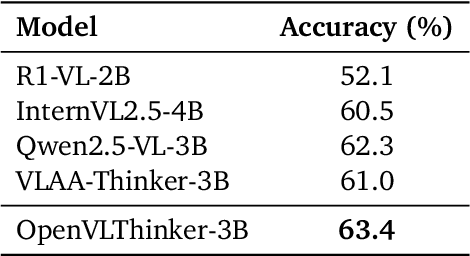
Recent advancements demonstrated by DeepSeek-R1 have shown that complex reasoning abilities in large language models (LLMs), including sophisticated behaviors such as self-verification and self-correction, can be achieved by RL with verifiable rewards and significantly improves model performance on challenging tasks such as AIME. Motivated by these findings, our study investigates whether similar reasoning capabilities can be successfully integrated into large vision-language models (LVLMs) and assesses their impact on challenging multimodal reasoning tasks. We consider an approach that iteratively leverages supervised fine-tuning (SFT) on lightweight training data and Reinforcement Learning (RL) to further improve model generalization. Initially, reasoning capabilities were distilled from pure-text R1 models by generating reasoning steps using high-quality captions of the images sourced from diverse visual datasets. Subsequently, iterative RL training further enhance reasoning skills, with each iteration's RL-improved model generating refined SFT datasets for the next round. This iterative process yielded OpenVLThinker, a LVLM exhibiting consistently improved reasoning performance on challenging benchmarks such as MathVista, MathVerse, and MathVision, demonstrating the potential of our strategy for robust vision-language reasoning. The code, model and data are held at https://github.com/yihedeng9/OpenVLThinker.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
Mar 20, 2025



Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they struggle to generalize these updates to multi-hop reasoning tasks that depend on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we observe that current layer-localized KE approaches, such as MEMIT and WISE, which edit only single or a few model layers, struggle to effectively incorporate updated information into these reasoning pathways. To address this limitation, we propose CaKE (Circuit-aware Knowledge Editing), a novel method that enables more effective integration of updated knowledge in LLMs. CaKE leverages strategically curated data, guided by our circuits-based analysis, that enforces the model to utilize the modified knowledge, stimulating the model to develop appropriate reasoning circuits for newly integrated knowledge. Experimental results show that CaKE enables more accurate and consistent use of updated knowledge across related reasoning tasks, leading to an average of 20% improvement in multi-hop reasoning accuracy on MQuAKE dataset compared to existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
Collapse of Dense Retrievers: Short, Early, and Literal Biases Outranking Factual Evidence
Mar 06, 2025



Dense retrieval models are commonly used in Information Retrieval (IR) applications, such as Retrieval-Augmented Generation (RAG). Since they often serve as the first step in these systems, their robustness is critical to avoid failures. In this work, by repurposing a relation extraction dataset (e.g. Re-DocRED), we design controlled experiments to quantify the impact of heuristic biases, such as favoring shorter documents, in retrievers like Dragon+ and Contriever. Our findings reveal significant vulnerabilities: retrievers often rely on superficial patterns like over-prioritizing document beginnings, shorter documents, repeated entities, and literal matches. Additionally, they tend to overlook whether the document contains the query's answer, lacking deep semantic understanding. Notably, when multiple biases combine, models exhibit catastrophic performance degradation, selecting the answer-containing document in less than 3% of cases over a biased document without the answer. Furthermore, we show that these biases have direct consequences for downstream applications like RAG, where retrieval-preferred documents can mislead LLMs, resulting in a 34% performance drop than not providing any documents at all.
Structured Outputs Enable General-Purpose LLMs to be Medical Experts
Mar 05, 2025Medical question-answering (QA) is a critical task for evaluating how effectively large language models (LLMs) encode clinical knowledge and assessing their potential applications in medicine. Despite showing promise on multiple-choice tests, LLMs frequently struggle with open-ended medical questions, producing responses with dangerous hallucinations or lacking comprehensive coverage of critical aspects. Existing approaches attempt to address these challenges through domain-specific fine-tuning, but this proves resource-intensive and difficult to scale across models. To improve the comprehensiveness and factuality of medical responses, we propose a novel approach utilizing structured medical reasoning. Our method guides LLMs through an seven-step cognitive process inspired by clinical diagnosis, enabling more accurate and complete answers without additional training. Experiments on the MedLFQA benchmark demonstrate that our approach achieves the highest Factuality Score of 85.8, surpassing fine-tuned models. Notably, this improvement transfers to smaller models, highlighting the method's efficiency and scalability. Our code and datasets are available.
Synthia: Novel Concept Design with Affordance Composition
Feb 25, 2025Text-to-image (T2I) models enable rapid concept design, making them widely used in AI-driven design. While recent studies focus on generating semantic and stylistic variations of given design concepts, functional coherence--the integration of multiple affordances into a single coherent concept--remains largely overlooked. In this paper, we introduce SYNTHIA, a framework for generating novel, functionally coherent designs based on desired affordances. Our approach leverages a hierarchical concept ontology that decomposes concepts into parts and affordances, serving as a crucial building block for functionally coherent design. We also develop a curriculum learning scheme based on our ontology that contrastively fine-tunes T2I models to progressively learn affordance composition while maintaining visual novelty. To elaborate, we (i) gradually increase affordance distance, guiding models from basic concept-affordance association to complex affordance compositions that integrate parts of distinct affordances into a single, coherent form, and (ii) enforce visual novelty by employing contrastive objectives to push learned representations away from existing concepts. Experimental results show that SYNTHIA outperforms state-of-the-art T2I models, demonstrating absolute gains of 25.1% and 14.7% for novelty and functional coherence in human evaluation, respectively.
MM-PoisonRAG: Disrupting Multimodal RAG with Local and Global Poisoning Attacks
Feb 25, 2025



Multimodal large language models (MLLMs) equipped with Retrieval Augmented Generation (RAG) leverage both their rich parametric knowledge and the dynamic, external knowledge to excel in tasks such as Question Answering. While RAG enhances MLLMs by grounding responses in query-relevant external knowledge, this reliance poses a critical yet underexplored safety risk: knowledge poisoning attacks, where misinformation or irrelevant knowledge is intentionally injected into external knowledge bases to manipulate model outputs to be incorrect and even harmful. To expose such vulnerabilities in multimodal RAG, we propose MM-PoisonRAG, a novel knowledge poisoning attack framework with two attack strategies: Localized Poisoning Attack (LPA), which injects query-specific misinformation in both text and images for targeted manipulation, and Globalized Poisoning Attack (GPA) to provide false guidance during MLLM generation to elicit nonsensical responses across all queries. We evaluate our attacks across multiple tasks, models, and access settings, demonstrating that LPA successfully manipulates the MLLM to generate attacker-controlled answers, with a success rate of up to 56% on MultiModalQA. Moreover, GPA completely disrupts model generation to 0% accuracy with just a single irrelevant knowledge injection. Our results highlight the urgent need for robust defenses against knowledge poisoning to safeguard multimodal RAG frameworks.
METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling
Feb 24, 2025



Chart generation aims to generate code to produce charts satisfying the desired visual properties, e.g., texts, layout, color, and type. It has great potential to empower the automatic professional report generation in financial analysis, research presentation, education, and healthcare. In this work, we build a vision-language model (VLM) based multi-agent framework for effective automatic chart generation. Generating high-quality charts requires both strong visual design skills and precise coding capabilities that embed the desired visual properties into code. Such a complex multi-modal reasoning process is difficult for direct prompting of VLMs. To resolve these challenges, we propose METAL, a multi-agent framework that decomposes the task of chart generation into the iterative collaboration among specialized agents. METAL achieves 5.2% improvement in accuracy over the current best result in the chart generation task. The METAL framework exhibits the phenomenon of test-time scaling: its performance increases monotonically as the logarithmic computational budget grows from 512 to 8192 tokens. In addition, we find that separating different modalities during the critique process of METAL boosts the self-correction capability of VLMs in the multimodal context.
FIG: Forward-Inverse Generation for Low-Resource Domain-specific Event Detection
Feb 24, 2025



Event Detection (ED) is the task of identifying typed event mentions of interest from natural language text, which benefits domain-specific reasoning in biomedical, legal, and epidemiological domains. However, procuring supervised data for thousands of events for various domains is a laborious and expensive task. To this end, existing works have explored synthetic data generation via forward (generating labels for unlabeled sentences) and inverse (generating sentences from generated labels) generations. However, forward generation often produces noisy labels, while inverse generation struggles with domain drift and incomplete event annotations. To address these challenges, we introduce FIG, a hybrid approach that leverages inverse generation for high-quality data synthesis while anchoring it to domain-specific cues extracted via forward generation on unlabeled target data. FIG further enhances its synthetic data by adding missing annotations through forward generation-based refinement. Experimentation on three ED datasets from diverse domains reveals that FIG outperforms the best baseline achieving average gains of 3.3% F1 and 5.4% F1 in the zero-shot and few-shot settings respectively. Analyzing the generated trigger hit rate and human evaluation substantiates FIG's superior domain alignment and data quality compared to existing baselines.