 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMPT2BOX: Uncovering Entailment Structure among LLM Prompts
Mar 22, 2026To discover the weaknesses of LLMs, researchers often embed prompts into a vector space and cluster them to extract insightful patterns. However, vector embeddings primarily capture topical similarity. As a result, prompts that share a topic but differ in specificity, and consequently in difficulty, are often represented similarly, making fine-grained weakness analysis difficult. To address this limitation, we propose PROMPT2BOX, which embeds prompts into a box embedding space using a trained encoder. The encoder, trained on existing and synthesized datasets, outputs box embeddings that capture not only semantic similarity but also specificity relations between prompts (e.g., "writing an adventure story" is more specific than "writing a story"). We further develop a novel dimension reduction technique for box embeddings to facilitate dataset visualization and comparison. Our experiments demonstrate that box embeddings consistently capture prompt specificity better than vector baselines. On the downstream task of creating hierarchical clustering trees for 17 LLMs from the UltraFeedback dataset, PROMPT2BOX can identify 8.9\% more LLM weaknesses than vector baselines and achieves an approximately 33\% stronger correlation between hierarchical depth and instruction specificity.
CoKe: Customizable Fine-Grained Story Evaluation via Chain-of-Keyword Rationalization
Mar 21, 2025Evaluating creative text such as human-written stories using language models has always been a challenging task -- owing to the subjectivity of multi-annotator ratings. To mimic the thinking process of humans, chain of thought (CoT) generates free-text explanations that help guide a model's predictions and Self-Consistency (SC) marginalizes predictions over multiple generated explanations. In this study, we discover that the widely-used self-consistency reasoning methods cause suboptimal results due to an objective mismatch between generating 'fluent-looking' explanations vs. actually leading to a good rating prediction for an aspect of a story. To overcome this challenge, we propose $\textbf{C}$hain-$\textbf{o}$f-$\textbf{Ke}$ywords (CoKe), that generates a sequence of keywords $\textit{before}$ generating a free-text rationale, that guide the rating prediction of our evaluation language model. Then, we generate a diverse set of such keywords, and aggregate the scores corresponding to these generations. On the StoryER dataset, CoKe based on our small fine-tuned evaluation models not only reach human-level performance and significantly outperform GPT-4 with a 2x boost in correlation with human annotators, but also requires drastically less number of parameters.
Explaining and Improving Contrastive Decoding by Extrapolating the Probabilities of a Huge and Hypothetical LM
Nov 03, 2024



Contrastive decoding (CD) (Li et al., 2023) improves the next-token distribution of a large expert language model (LM) using a small amateur LM. Although CD is applied to various LMs and domains to enhance open-ended text generation, it is still unclear why CD often works well, when it could fail, and how we can make it better. To deepen our understanding of CD, we first theoretically prove that CD could be viewed as linearly extrapolating the next-token logits from a huge and hypothetical LM. We also highlight that the linear extrapolation could make CD unable to output the most obvious answers that have already been assigned high probabilities by the amateur LM. To overcome CD's limitation, we propose a new unsupervised decoding method called $\mathbf{A}$symptotic $\mathbf{P}$robability $\mathbf{D}$ecoding (APD). APD explicitly extrapolates the probability curves from the LMs of different sizes to infer the asymptotic probabilities from an infinitely large LM without inducing more inference costs than CD. In FactualityPrompts, an open-ended text generation benchmark, sampling using APD significantly boosts factuality in comparison to the CD sampling and its variants, and achieves state-of-the-art results for Pythia 6.9B and OPT 6.7B. Furthermore, in five commonsense QA datasets, APD is often significantly better than CD and achieves a similar effect of using a larger LLM. For example, the perplexity of APD on top of Pythia 6.9B is even lower than the perplexity of Pythia 12B in CommonsenseQA and LAMBADA.
LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
Oct 09, 2024



Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
CS4: Measuring the Creativity of Large Language Models Automatically by Controlling the Number of Story-Writing Constraints
Oct 05, 2024



Evaluating the creativity of large language models (LLMs) in story writing is difficult because LLM-generated stories could seemingly look creative but be very similar to some existing stories in their huge and proprietary training corpus. To overcome this challenge, we introduce a novel benchmark dataset with varying levels of prompt specificity: CS4 ($\mathbf{C}$omparing the $\mathbf{S}$kill of $\mathbf{C}$reating $\mathbf{S}$tories by $\mathbf{C}$ontrolling the $\mathbf{S}$ynthesized $\mathbf{C}$onstraint $\mathbf{S}$pecificity). By increasing the number of requirements/constraints in the prompt, we can increase the prompt specificity and hinder LLMs from retelling high-quality narratives in their training data. Consequently, CS4 empowers us to indirectly measure the LLMs' creativity without human annotations. Our experiments on LLaMA, Gemma, and Mistral not only highlight the creativity challenges LLMs face when dealing with highly specific prompts but also reveal that different LLMs perform very differently under different numbers of constraints and achieve different balances between the model's instruction-following ability and narrative coherence. Additionally, our experiments on OLMo suggest that Learning from Human Feedback (LHF) can help LLMs select better stories from their training data but has limited influence in boosting LLMs' ability to produce creative stories that are unseen in the training corpora. The benchmark is released at https://github.com/anirudhlakkaraju/cs4_benchmark.
REAL Sampling: Boosting Factuality and Diversity of Open-Ended Generation via Asymptotic Entropy
Jun 11, 2024



Decoding methods for large language models (LLMs) usually struggle with the tradeoff between ensuring factuality and maintaining diversity. For example, a higher p threshold in the nucleus (top-p) sampling increases the diversity but decreases the factuality, and vice versa. In this paper, we propose REAL (Residual Entropy from Asymptotic Line) sampling, a decoding method that achieves improved factuality and diversity over nucleus sampling by predicting an adaptive threshold of $p$. Specifically, REAL sampling predicts the step-wise likelihood of an LLM to hallucinate, and lowers the p threshold when an LLM is likely to hallucinate. Otherwise, REAL sampling increases the p threshold to boost the diversity. To predict the step-wise hallucination likelihood without supervision, we construct a Token-level Hallucination Forecasting (THF) model to predict the asymptotic entropy (i.e., inherent uncertainty) of the next token by extrapolating the next-token entropies from a series of LLMs with different sizes. If a LLM's entropy is higher than the asymptotic entropy (i.e., the LLM is more uncertain than it should be), the THF model predicts a high hallucination hazard, which leads to a lower p threshold in REAL sampling. In the FactualityPrompts benchmark, we demonstrate that REAL sampling based on a 70M THF model can substantially improve the factuality and diversity of 7B LLMs simultaneously, judged by both retrieval-based metrics and human evaluation. After combined with contrastive decoding, REAL sampling outperforms 9 sampling methods, and generates texts that are more factual than the greedy sampling and more diverse than the nucleus sampling with $p=0.5$. Furthermore, the predicted asymptotic entropy is also a useful unsupervised signal for hallucination detection tasks.
To Copy, or not to Copy; That is a Critical Issue of the Output Softmax Layer in Neural Sequential Recommenders
Oct 21, 2023



Recent studies suggest that the existing neural models have difficulty handling repeated items in sequential recommendation tasks. However, our understanding of this difficulty is still limited. In this study, we substantially advance this field by identifying a major source of the problem: the single hidden state embedding and static item embeddings in the output softmax layer. Specifically, the similarity structure of the global item embeddings in the softmax layer sometimes forces the single hidden state embedding to be close to new items when copying is a better choice, while sometimes forcing the hidden state to be close to the items from the input inappropriately. To alleviate the problem, we adapt the recently-proposed softmax alternatives such as softmax-CPR to sequential recommendation tasks and demonstrate that the new softmax architectures unleash the capability of the neural encoder on learning when to copy and when to exclude the items from the input sequence. By only making some simple modifications on the output softmax layer for SASRec and GRU4Rec, softmax-CPR achieves consistent improvement in 12 datasets. With almost the same model size, our best method not only improves the average NDCG@10 of GRU4Rec in 5 datasets with duplicated items by 10% (4%-17% individually) but also improves 7 datasets without duplicated items by 24% (8%-39%)!
Encoding Multi-Domain Scientific Papers by Ensembling Multiple CLS Tokens
Sep 08, 2023Many useful tasks on scientific documents, such as topic classification and citation prediction, involve corpora that span multiple scientific domains. Typically, such tasks are accomplished by representing the text with a vector embedding obtained from a Transformer's single CLS token. In this paper, we argue that using multiple CLS tokens could make a Transformer better specialize to multiple scientific domains. We present Multi2SPE: it encourages each of multiple CLS tokens to learn diverse ways of aggregating token embeddings, then sums them up together to create a single vector representation. We also propose our new multi-domain benchmark, Multi-SciDocs, to test scientific paper vector encoders under multi-domain settings. We show that Multi2SPE reduces error by up to 25 percent in multi-domain citation prediction, while requiring only a negligible amount of computation in addition to one BERT forward pass.
Revisiting the Architectures like Pointer Networks to Efficiently Improve the Next Word Distribution, Summarization Factuality, and Beyond
May 20, 2023



Is the output softmax layer, which is adopted by most language models (LMs), always the best way to compute the next word probability? Given so many attention layers in a modern transformer-based LM, are the pointer networks redundant nowadays? In this study, we discover that the answers to both questions are no. This is because the softmax bottleneck sometimes prevents the LMs from predicting the desired distribution and the pointer networks can be used to break the bottleneck efficiently. Based on the finding, we propose several softmax alternatives by simplifying the pointer networks and accelerating the word-by-word rerankers. In GPT-2, our proposals are significantly better and more efficient than mixture of softmax, a state-of-the-art softmax alternative. In summarization experiments, without significantly decreasing its training/testing speed, our best method based on T5-Small improves factCC score by 2 points in CNN/DM and XSUM dataset, and improves MAUVE scores by 30% in BookSum paragraph-level dataset.
Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling
Oct 10, 2022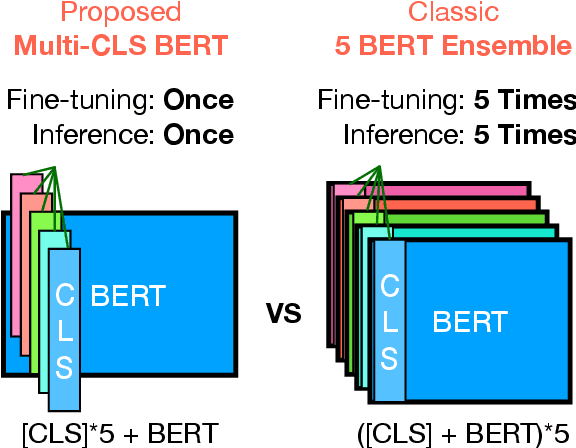
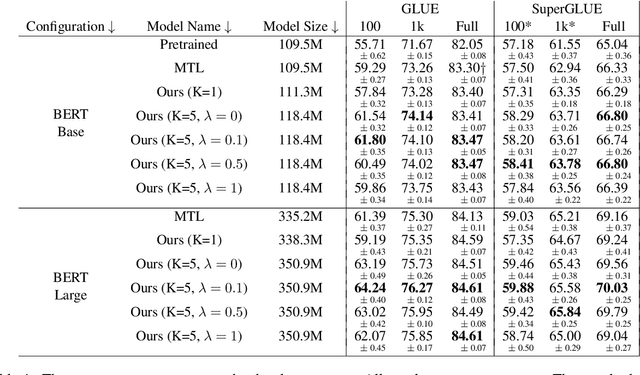
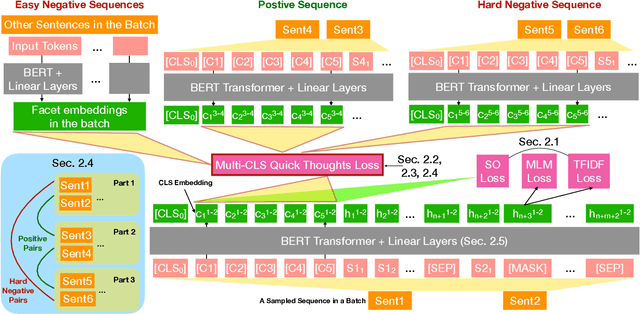
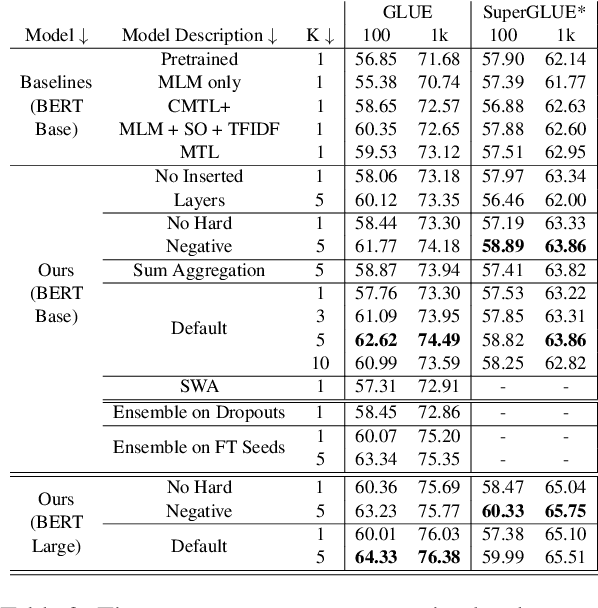
Ensembling BERT models often significantly improves accuracy, but at the cost of significantly more computation and memory footprint. In this work, we propose Multi-CLS BERT, a novel ensembling method for CLS-based prediction tasks that is almost as efficient as a single BERT model. Multi-CLS BERT uses multiple CLS tokens with a parameterization and objective that encourages their diversity. Thus instead of fine-tuning each BERT model in an ensemble (and running them all at test time), we need only fine-tune our single Multi-CLS BERT model (and run the one model at test time, ensembling just the multiple final CLS embeddings). To test its effectiveness, we build Multi-CLS BERT on top of a state-of-the-art pretraining method for BERT (Aroca-Ouellette and Rudzicz, 2020). In experiments on GLUE and SuperGLUE we show that our Multi-CLS BERT reliably improves both overall accuracy and confidence estimation. When only 100 training samples are available in GLUE, the Multi-CLS BERT_Base model can even outperform the corresponding BERT_Large model. We analyze the behavior of our Multi-CLS BERT, showing that it has many of the same characteristics and behavior as a typical BERT 5-way ensemble, but with nearly 4-times less computation and memory.