 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecipes for building an open-domain chatbot
Apr 30, 2020
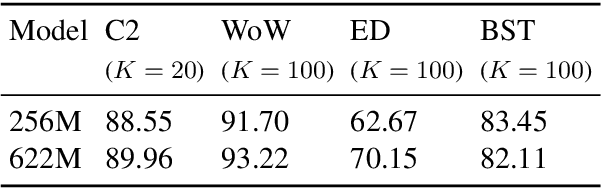
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent persona. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
General Purpose Text Embeddings from Pre-trained Language Models for Scalable Inference
Apr 29, 2020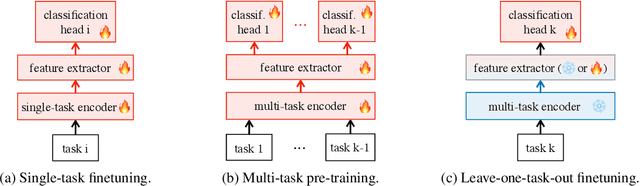
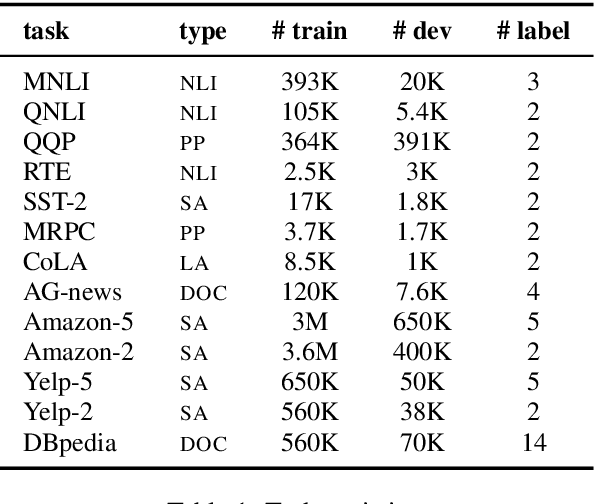
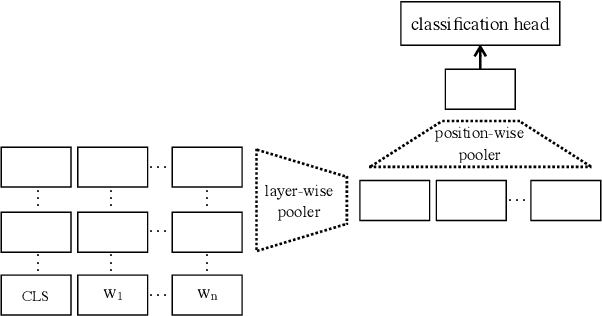
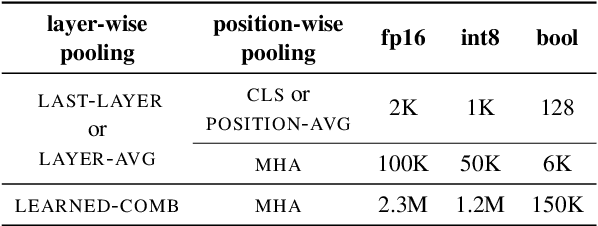
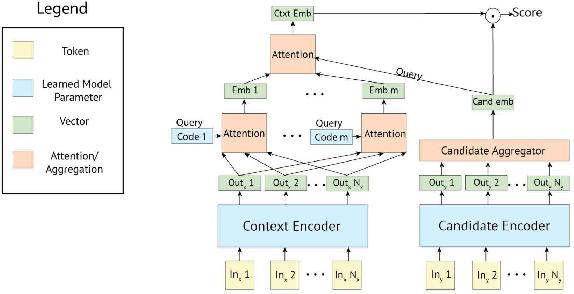
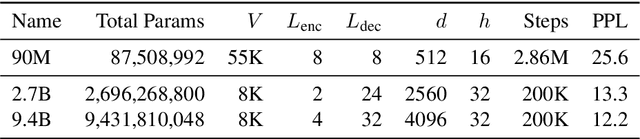
The state of the art on many NLP tasks is currently achieved by large pre-trained language models, which require a considerable amount of computation. We explore a setting where many different predictions are made on a single piece of text. In that case, some of the computational cost during inference can be amortized over the different tasks using a shared text encoder. We compare approaches for training such an encoder and show that encoders pre-trained over multiple tasks generalize well to unseen tasks. We also compare ways of extracting fixed- and limited-size representations from this encoder, including different ways of pooling features extracted from multiple layers or positions. Our best approach compares favorably to knowledge distillation, achieving higher accuracy and lower computational cost once the system is handling around 7 tasks. Further, we show that through binary quantization, we can reduce the size of the extracted representations by a factor of 16 making it feasible to store them for later use. The resulting method offers a compelling solution for using large-scale pre-trained models at a fraction of the computational cost when multiple tasks are performed on the same text.
Residual Energy-Based Models for Text Generation
Apr 22, 2020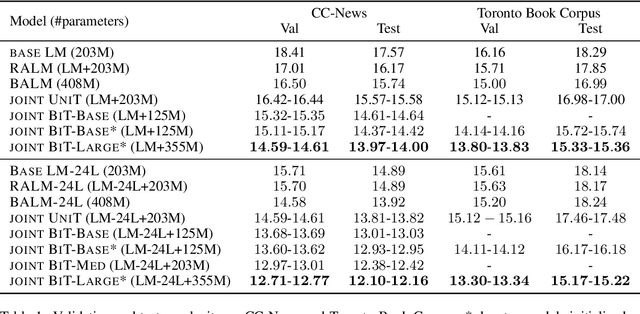
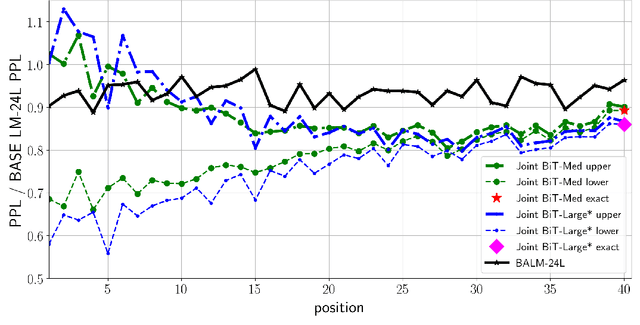
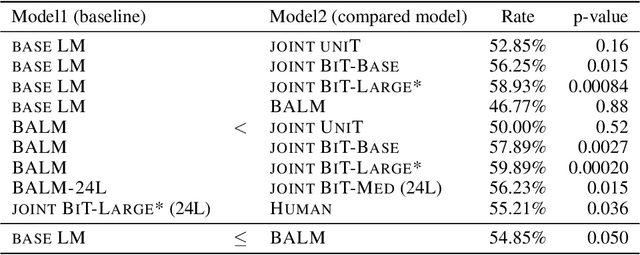
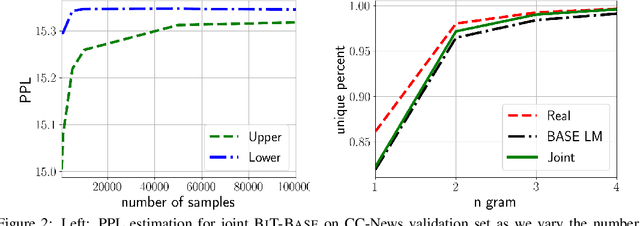
Text generation is ubiquitous in many NLP tasks, from summarization, to dialogue and machine translation. The dominant parametric approach is based on locally normalized models which predict one word at a time. While these work remarkably well, they are plagued by exposure bias due to the greedy nature of the generation process. In this work, we investigate un-normalized energy-based models (EBMs) which operate not at the token but at the sequence level. In order to make training tractable, we first work in the residual of a pretrained locally normalized language model and second we train using noise contrastive estimation. Furthermore, since the EBM works at the sequence level, we can leverage pretrained bi-directional contextual representations, such as BERT and RoBERTa. Our experiments on two large language modeling datasets show that residual EBMs yield lower perplexity compared to locally normalized baselines. Moreover, generation via importance sampling is very efficient and of higher quality than the baseline models according to human evaluation.
* published at ICLR 2020. arXiv admin note: substantial text overlap with arXiv:2004.10188
Energy-Based Models for Text
Apr 06, 2020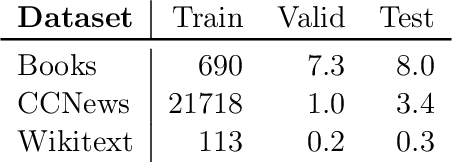
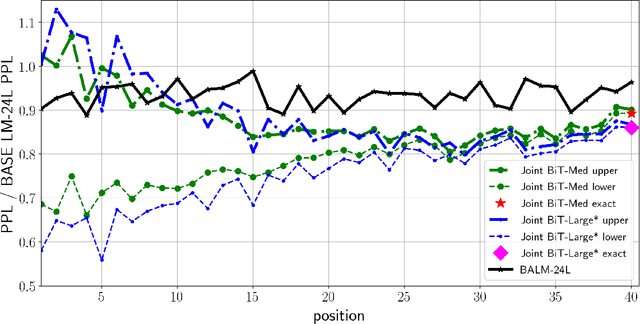

Current large-scale auto-regressive language models display impressive fluency and can generate convincing text. In this work we start by asking the question: Can the generations of these models be reliably distinguished from real text by statistical discriminators? We find experimentally that the answer is affirmative when we have access to the training data for the model, and guardedly affirmative even if we do not. This suggests that the auto-regressive models can be improved by incorporating the (globally normalized) discriminators into the generative process. We give a formalism for this using the Energy-Based Model framework, and show that it indeed improves the results of the generative models, measured both in terms of perplexity and in terms of human evaluation.
How Decoding Strategies Affect the Verifiability of Generated Text
Nov 09, 2019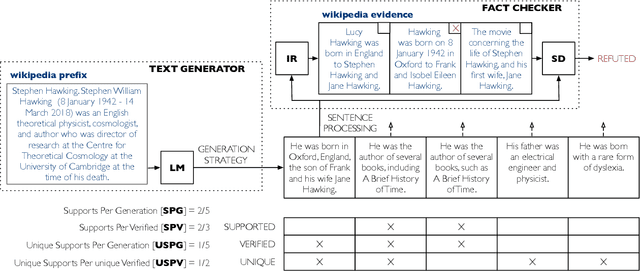
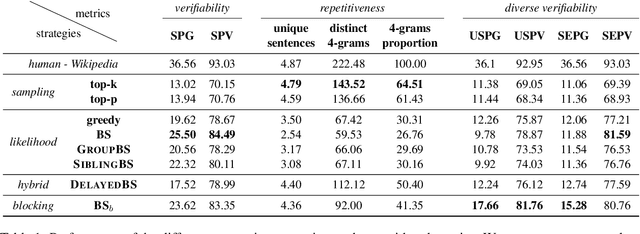
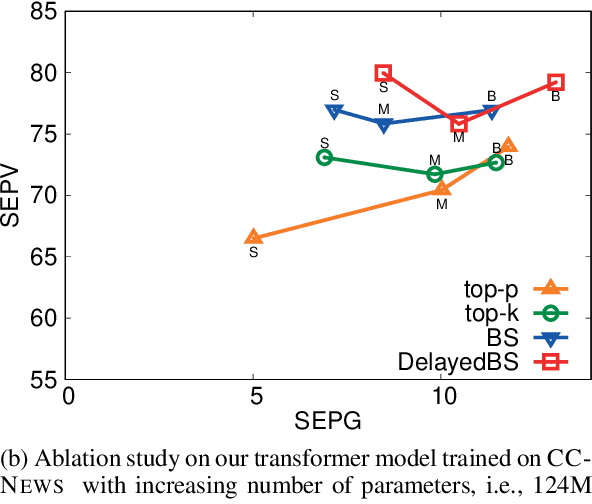

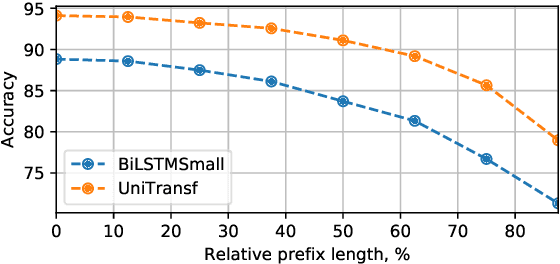
Language models are of considerable importance. They are used for pretraining, finetuning, and rescoring in downstream applications, and as is as a test-bed and benchmark for progress in natural language understanding. One fundamental question regards the way we should generate text from a language model. It is well known that different decoding strategies can have dramatic impact on the quality of the generated text and using the most likely sequence under the model distribution, e.g., via beam search, generally leads to degenerate and repetitive outputs. While generation strategies such as top-k and nucleus sampling lead to more natural and less repetitive generations, the true cost of avoiding the highest scoring solution is hard to quantify. In this paper, we argue that verifiability, i.e., the consistency of the generated text with factual knowledge, is a suitable metric for measuring this cost. We use an automatic fact-checking system to calculate new metrics as a function of the number of supported claims per sentence and find that sampling-based generation strategies, such as top-k, indeed lead to less verifiable text. This finding holds across various dimensions, such as model size, training data size and parameters of the generation strategy. Based on this finding, we introduce a simple and effective generation strategy for producing non-repetitive and more verifiable (in comparison to other methods) text.
Unsupervised Cross-lingual Representation Learning at Scale
Nov 05, 2019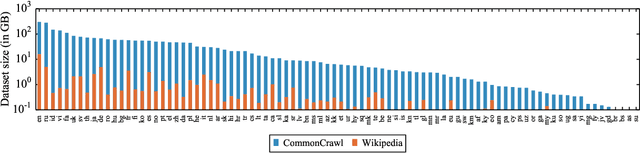
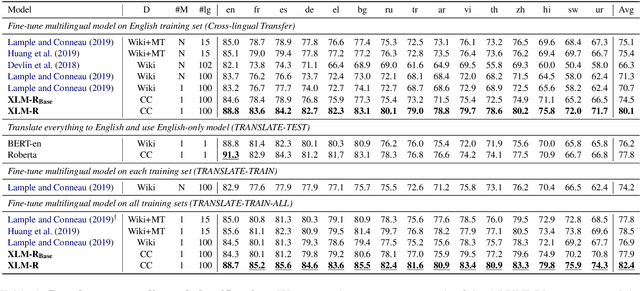
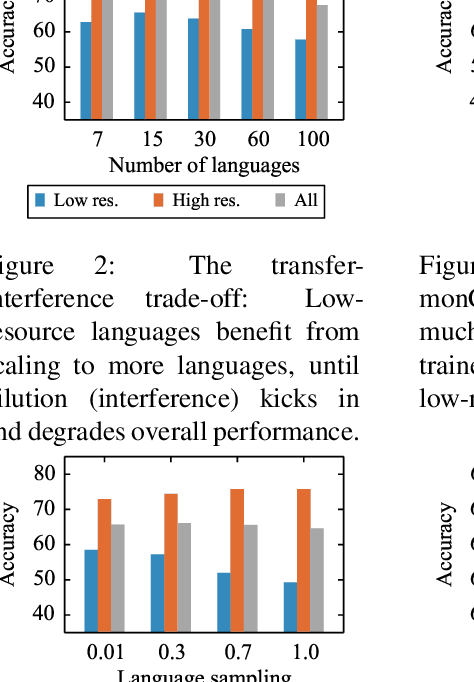
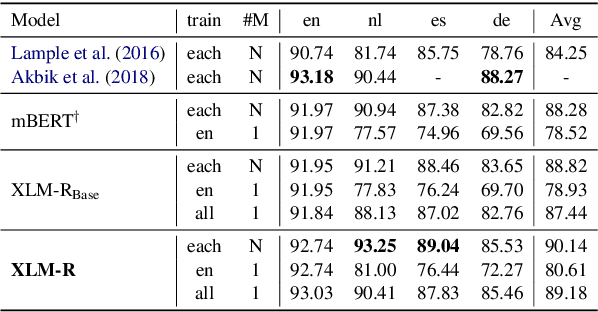
This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a wide range of cross-lingual transfer tasks. We train a Transformer-based masked language model on one hundred languages, using more than two terabytes of filtered CommonCrawl data. Our model, dubbed XLM-R, significantly outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model. We also present a detailed empirical evaluation of the key factors that are required to achieve these gains, including the trade-offs between (1) positive transfer and capacity dilution and (2) the performance of high and low resource languages at scale. Finally, we show, for the first time, the possibility of multilingual modeling without sacrificing per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We will make XLM-R code, data, and models publicly available.
Mix-review: Alleviate Forgetting in the Pretrain-Finetune Framework for Neural Language Generation Models
Oct 29, 2019
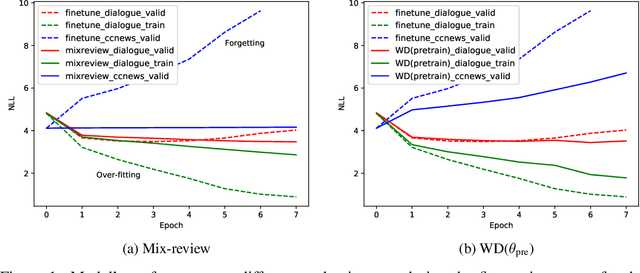
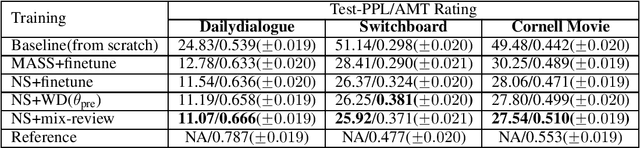
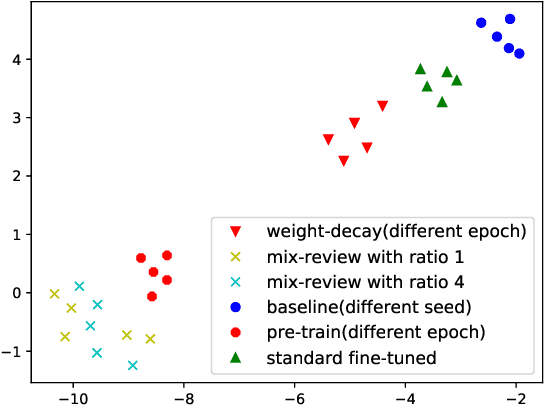
In this work, we study how the large-scale pretrain-finetune framework changes the behavior of a neural language generator. We focus on the transformer encoder-decoder model for the open-domain dialogue response generation task. We find that after standard fine-tuning, the model forgets important language generation skills acquired during large-scale pre-training. We demonstrate the forgetting phenomenon through a detailed behavior analysis from the perspectives of context sensitivity and knowledge transfer. Adopting the concept of data mixing, we propose an intuitive fine-tuning strategy named "mix-review". We find that mix-review effectively regularize the fine-tuning process, and the forgetting problem is largely alleviated. Finally, we discuss interesting behavior of the resulting dialogue model and its implications.
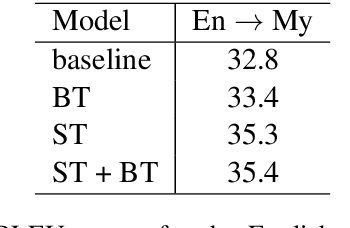
Facebook AI's WAT19 Myanmar-English Translation Task Submission
Oct 15, 2019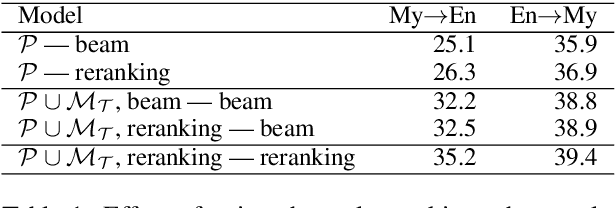
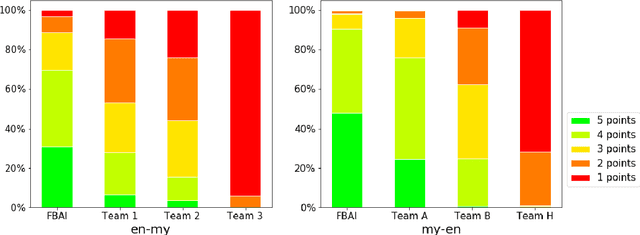
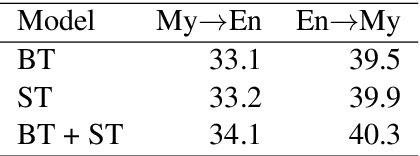
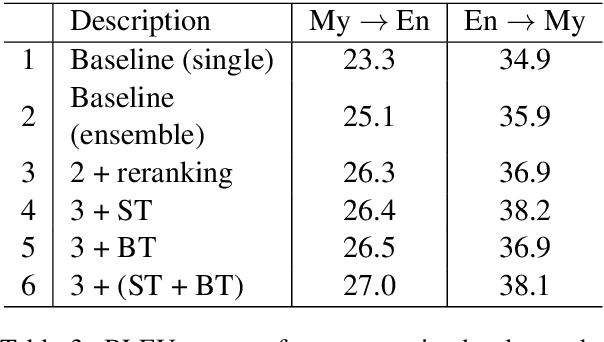
This paper describes Facebook AI's submission to the WAT 2019 Myanmar-English translation task. Our baseline systems are BPE-based transformer models. We explore methods to leverage monolingual data to improve generalization, including self-training, back-translation and their combination. We further improve results by using noisy channel re-ranking and ensembling. We demonstrate that these techniques can significantly improve not only a system trained with additional monolingual data, but even the baseline system trained exclusively on the provided small parallel dataset. Our system ranks first in both directions according to human evaluation and BLEU, with a gain of over 8 BLEU points above the second best system.
The Source-Target Domain Mismatch Problem in Machine Translation
Sep 28, 2019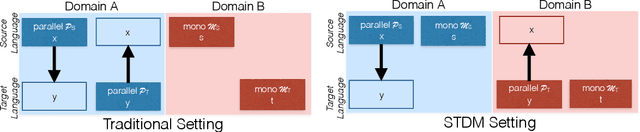
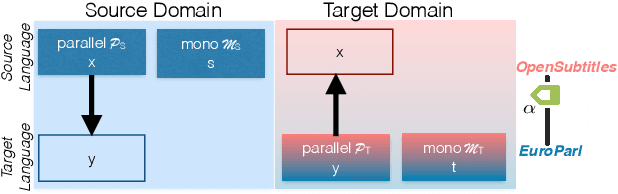
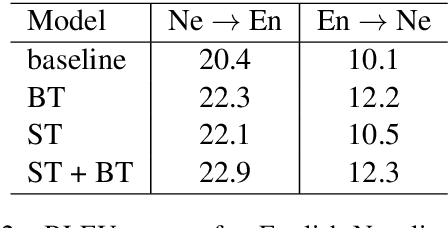
While we live in an increasingly interconnected world, different places still exhibit strikingly different cultures and many events we experience in our every day life pertain only to the specific place we live in. As a result, people often talk about different things in different parts of the world. In this work we study the effect of local context in machine translation and postulate that particularly in low resource settings this causes the domains of the source and target language to greatly mismatch, as the two languages are often spoken in further apart regions of the world with more distinctive cultural traits and unrelated local events. In this work we first propose a controlled setting to carefully analyze the source-target domain mismatch, and its dependence on the amount of parallel and monolingual data. Second, we test both a model trained with back-translation and one trained with self-training. The latter leverages in-domain source monolingual data but uses potentially incorrect target references. We found that these two approaches are often complementary to each other. For instance, on a low-resource Nepali-English dataset the combined approach improves upon the baseline using just parallel data by 2.5 BLEU points, and by 0.6 BLEU point when compared to back-translation.
On The Evaluation of Machine Translation Systems Trained With Back-Translation
Aug 14, 2019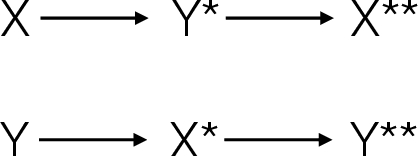
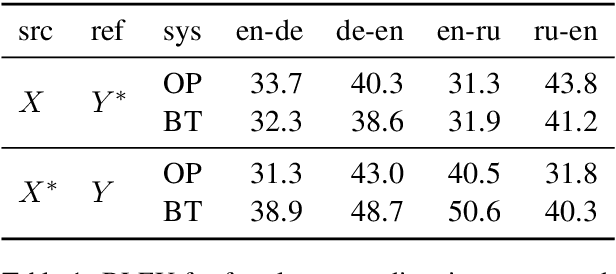
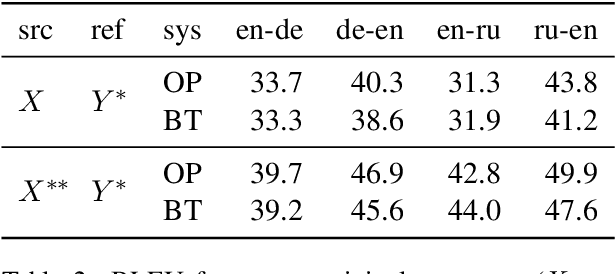
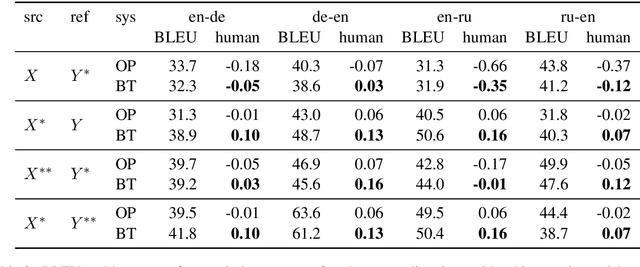
Back-translation is a widely used data augmentation technique which leverages target monolingual data. However, its effectiveness has been challenged since automatic metrics such as BLEU only show significant improvements for test examples where the source itself is a translation, or translationese. This is believed to be due to translationese inputs better matching the back-translated training data. In this work, we show that this conjecture is not empirically supported and that back-translation improves translation quality of both naturally occurring text as well as translationese according to professional human translators. We provide empirical evidence to support the view that back-translation is preferred by humans because it produces more fluent outputs. BLEU cannot capture human preferences because references are translationese when source sentences are natural text. We recommend complementing BLEU with a language model score to measure fluency.