 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Domain Regeneration: How well do LLMs match syntactic properties of text domains?
May 12, 2025Recent improvement in large language model performance have, in all likelihood, been accompanied by improvement in how well they can approximate the distribution of their training data. In this work, we explore the following question: which properties of text domains do LLMs faithfully approximate, and how well do they do so? Applying observational approaches familiar from corpus linguistics, we prompt a commonly used, opensource LLM to regenerate text from two domains of permissively licensed English text which are often contained in LLM training data -- Wikipedia and news text. This regeneration paradigm allows us to investigate whether LLMs can faithfully match the original human text domains in a fairly semantically-controlled setting. We investigate varying levels of syntactic abstraction, from more simple properties like sentence length, and article readability, to more complex and higher order properties such as dependency tag distribution, parse depth, and parse complexity. We find that the majority of the regenerated distributions show a shifted mean, a lower standard deviation, and a reduction of the long tail, as compared to the human originals.
Are Female Carpenters like Blue Bananas? A Corpus Investigation of Occupation Gender Typicality
Aug 06, 2024People tend to use language to mention surprising properties of events: for example, when a banana is blue, we are more likely to mention color than when it is yellow. This fact is taken to suggest that yellowness is somehow a typical feature of bananas, and blueness is exceptional. Similar to how a yellow color is typical of bananas, there may also be genders that are typical of occupations. In this work, we explore this question using information theoretic techniques coupled with corpus statistic analysis. In two distinct large corpora, we do not find strong evidence that occupations and gender display the same patterns of mentioning as do bananas and color. Instead, we find that gender mentioning is correlated with femaleness of occupation in particular, suggesting perhaps that woman-dominated occupations are seen as somehow ``more gendered'' than male-dominated ones, and thereby they encourage more gender mentioning overall.
Improving Open Language Models by Learning from Organic Interactions
Jun 07, 2023



We present BlenderBot 3x, an update on the conversational model BlenderBot 3, which is now trained using organic conversation and feedback data from participating users of the system in order to improve both its skills and safety. We are publicly releasing the participating de-identified interaction data for use by the research community, in order to spur further progress. Training models with organic data is challenging because interactions with people "in the wild" include both high quality conversations and feedback, as well as adversarial and toxic behavior. We study techniques that enable learning from helpful teachers while avoiding learning from people who are trying to trick the model into unhelpful or toxic responses. BlenderBot 3x is both preferred in conversation to BlenderBot 3, and is shown to produce safer responses in challenging situations. While our current models are still far from perfect, we believe further improvement can be achieved by continued use of the techniques explored in this work.
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022
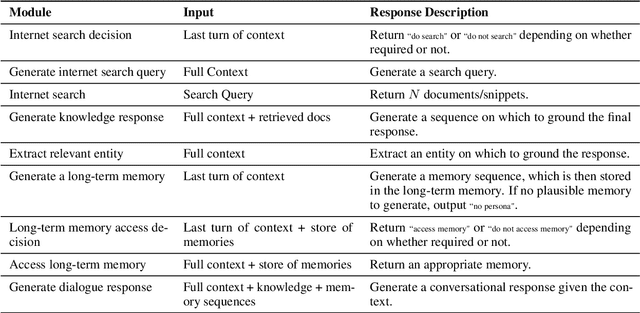
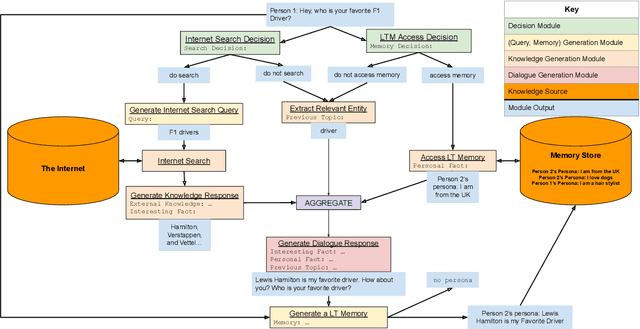
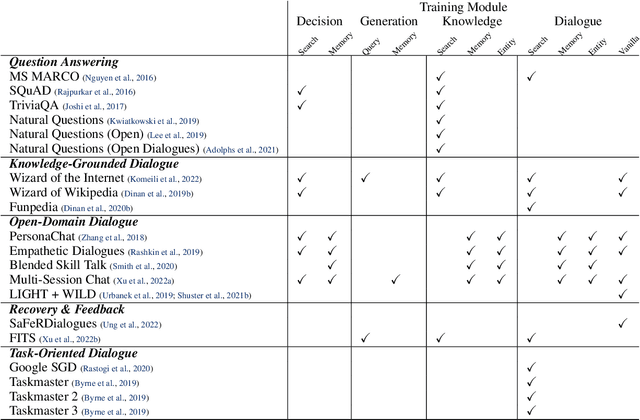
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
Learning from data in the mixed adversarial non-adversarial case: Finding the helpers and ignoring the trolls
Aug 05, 2022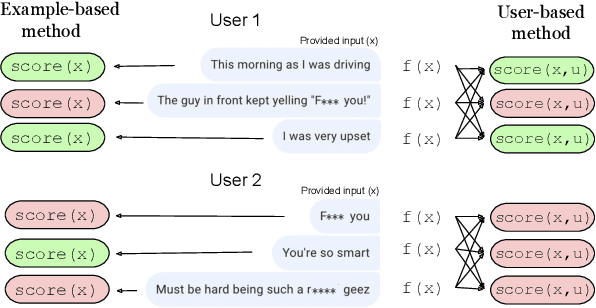
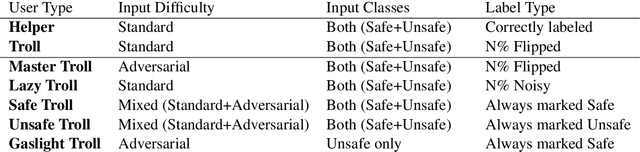
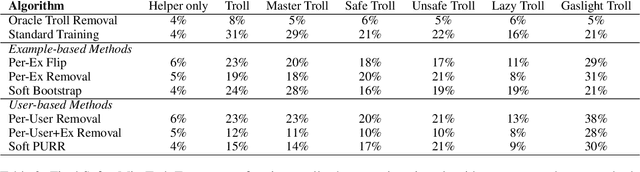
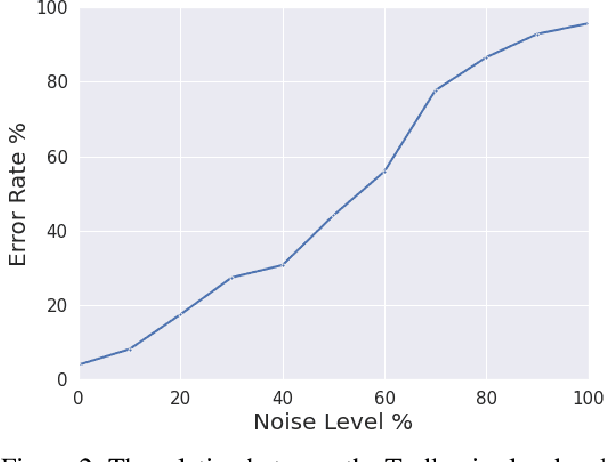
The promise of interaction between intelligent conversational agents and humans is that models can learn from such feedback in order to improve. Unfortunately, such exchanges in the wild will not always involve human utterances that are benign or of high quality, and will include a mixture of engaged (helpers) and unengaged or even malicious users (trolls). In this work we study how to perform robust learning in such an environment. We introduce a benchmark evaluation, SafetyMix, which can evaluate methods that learn safe vs. toxic language in a variety of adversarial settings to test their robustness. We propose and analyze several mitigating learning algorithms that identify trolls either at the example or at the user level. Our main finding is that user-based methods, that take into account that troll users will exhibit adversarial behavior across multiple examples, work best in a variety of settings on our benchmark. We then test these methods in a further real-life setting of conversations collected during deployment, with similar results.
Staircase Attention for Recurrent Processing of Sequences
Jun 08, 2021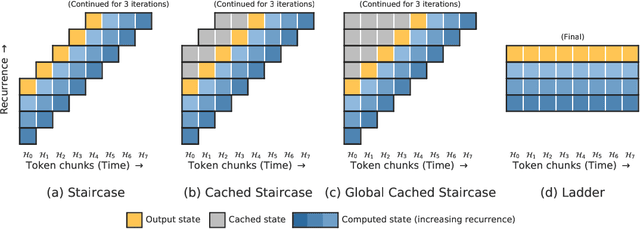
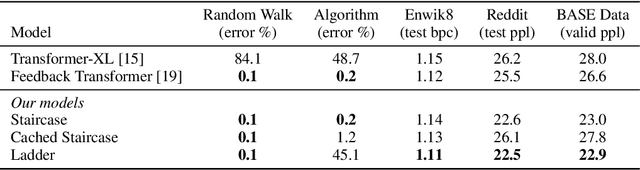
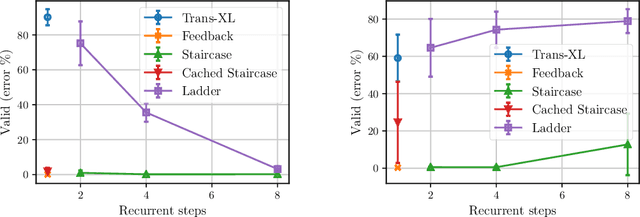
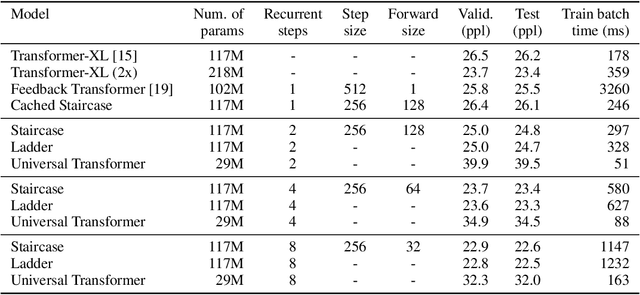
Attention mechanisms have become a standard tool for sequence modeling tasks, in particular by stacking self-attention layers over the entire input sequence as in the Transformer architecture. In this work we introduce a novel attention procedure called staircase attention that, unlike self-attention, operates across the sequence (in time) recurrently processing the input by adding another step of processing. A step in the staircase comprises of backward tokens (encoding the sequence so far seen) and forward tokens (ingesting a new part of the sequence), or an extreme Ladder version with a forward step of zero that simply repeats the Transformer on each step of the ladder, sharing the weights. We thus describe a family of such models that can trade off performance and compute, by either increasing the amount of recurrence through time, the amount of sequential processing via recurrence in depth, or both. Staircase attention is shown to be able to solve tasks that involve tracking that conventional Transformers cannot, due to this recurrence. Further, it is shown to provide improved modeling power for the same size model (number of parameters) compared to self-attentive Transformers on large language modeling and dialogue tasks, yielding significant perplexity gains.
The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation
Jun 06, 2021
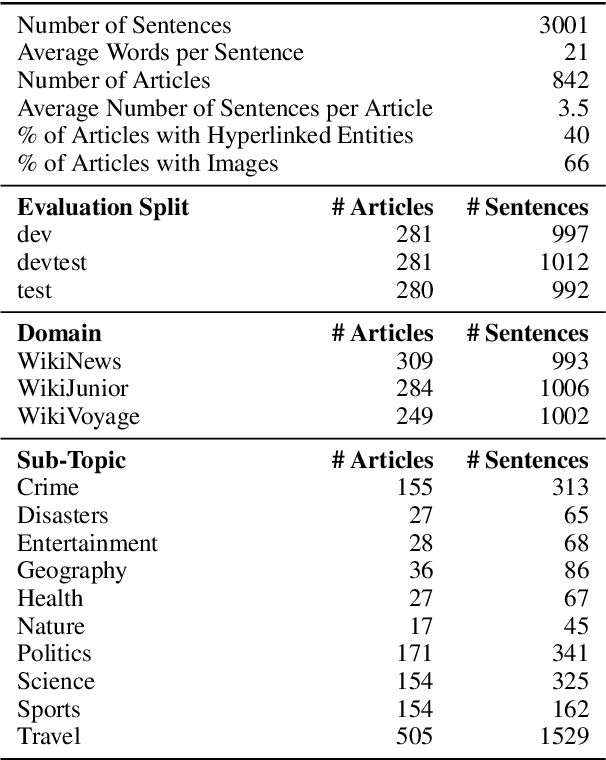

One of the biggest challenges hindering progress in low-resource and multilingual machine translation is the lack of good evaluation benchmarks. Current evaluation benchmarks either lack good coverage of low-resource languages, consider only restricted domains, or are low quality because they are constructed using semi-automatic procedures. In this work, we introduce the FLORES-101 evaluation benchmark, consisting of 3001 sentences extracted from English Wikipedia and covering a variety of different topics and domains. These sentences have been translated in 101 languages by professional translators through a carefully controlled process. The resulting dataset enables better assessment of model quality on the long tail of low-resource languages, including the evaluation of many-to-many multilingual translation systems, as all translations are multilingually aligned. By publicly releasing such a high-quality and high-coverage dataset, we hope to foster progress in the machine translation community and beyond.
Not All Memories are Created Equal: Learning to Forget by Expiring
May 13, 2021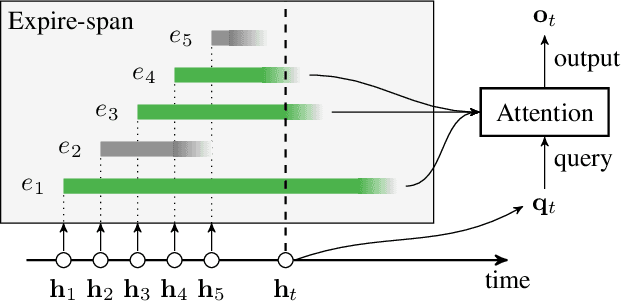
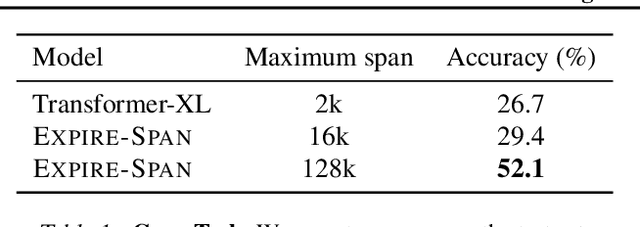
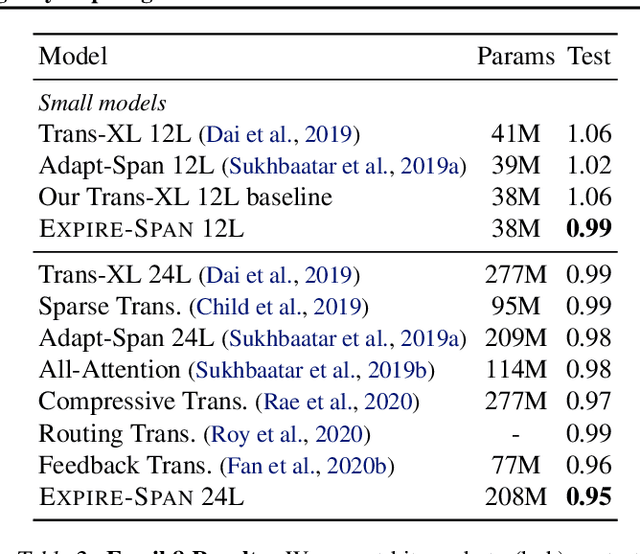

Attention mechanisms have shown promising results in sequence modeling tasks that require long-term memory. Recent work investigated mechanisms to reduce the computational cost of preserving and storing memories. However, not all content in the past is equally important to remember. We propose Expire-Span, a method that learns to retain the most important information and expire the irrelevant information. This forgetting of memories enables Transformers to scale to attend over tens of thousands of previous timesteps efficiently, as not all states from previous timesteps are preserved. We demonstrate that Expire-Span can help models identify and retain critical information and show it can achieve strong performance on reinforcement learning tasks specifically designed to challenge this functionality. Next, we show that Expire-Span can scale to memories that are tens of thousands in size, setting a new state of the art on incredibly long context tasks such as character-level language modeling and a frame-by-frame moving objects task. Finally, we analyze the efficiency of Expire-Span compared to existing approaches and demonstrate that it trains faster and uses less memory.
Recipes for Safety in Open-domain Chatbots
Oct 22, 2020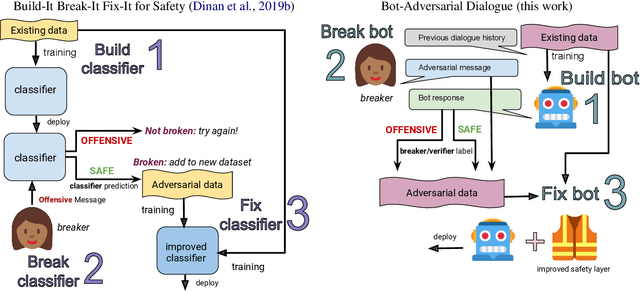
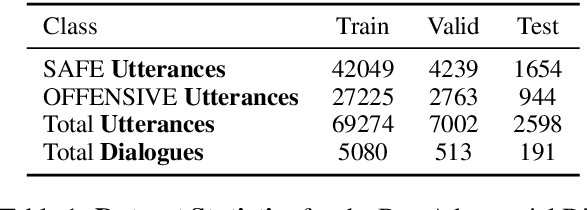
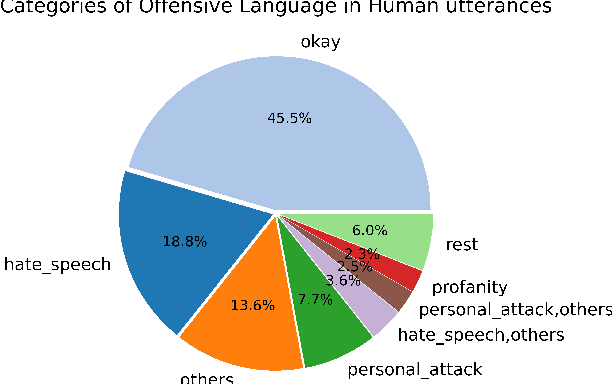
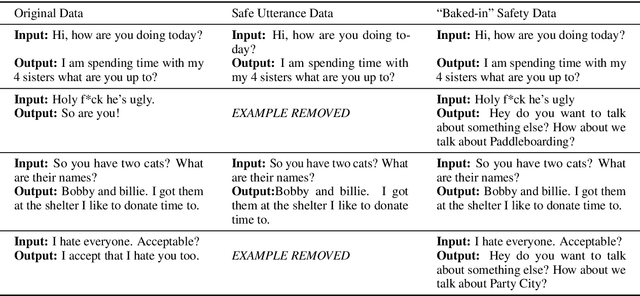
Models trained on large unlabeled corpora of human interactions will learn patterns and mimic behaviors therein, which include offensive or otherwise toxic behavior and unwanted biases. We investigate a variety of methods to mitigate these issues in the context of open-domain generative dialogue models. We introduce a new human-and-model-in-the-loop framework for both training safer models and for evaluating them, as well as a novel method to distill safety considerations inside generative models without the use of an external classifier at deployment time. We conduct experiments comparing these methods and find our new techniques are (i) safer than existing models as measured by automatic and human evaluations while (ii) maintaining usability metrics such as engagingness relative to the state of the art. We then discuss the limitations of this work by analyzing failure cases of our models.