 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
Dec 18, 2025Reward models (RMs) are essential for training large language models (LLMs), but remain underexplored for omni models that handle interleaved image and text sequences. We introduce Multimodal RewardBench 2 (MMRB2), the first comprehensive benchmark for reward models on multimodal understanding and (interleaved) generation. MMRB2 spans four tasks: text-to-image, image editing, interleaved generation, and multimodal reasoning ("thinking-with-images"), providing 1,000 expert-annotated preference pairs per task from 23 models and agents across 21 source tasks. MMRB2 is designed with: (1) practical but challenging prompts; (2) responses from state-of-the-art models and agents; and (3) preference pairs with strong human-expert consensus, curated via an ensemble filtering strategy. Using MMRB2, we study existing judges for each subtask, including multimodal LLM-as-a-judge and models trained with human preferences. The latest Gemini 3 Pro attains 75-80% accuracy. GPT-5 and Gemini 2.5 Pro reach 66-75% accuracy, compared to >90% for humans, yet surpass the widely used GPT-4o (59%). The best performing open-source model Qwen3-VL-32B achieves similar accuracies as Gemini 2.5 Flash (64%). We also show that MMRB2 performance strongly correlates with downstream task success using Best-of-N sampling and conduct an in-depth analysis that shows key areas to improve the reward models going forward.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Effective Theory of Transformers at Initialization
Apr 04, 2023



We perform an effective-theory analysis of forward-backward signal propagation in wide and deep Transformers, i.e., residual neural networks with multi-head self-attention blocks and multilayer perceptron blocks. This analysis suggests particular width scalings of initialization and training hyperparameters for these models. We then take up such suggestions, training Vision and Language Transformers in practical setups.
Improving Chess Commentaries by Combining Language Models with Symbolic Reasoning Engines
Dec 15, 2022



Despite many recent advancements in language modeling, state-of-the-art language models lack grounding in the real world and struggle with tasks involving complex reasoning. Meanwhile, advances in the symbolic reasoning capabilities of AI have led to systems that outperform humans in games like chess and Go (Silver et al., 2018). Chess commentary provides an interesting domain for bridging these two fields of research, as it requires reasoning over a complex board state and providing analyses in natural language. In this work we demonstrate how to combine symbolic reasoning engines with controllable language models to generate chess commentaries. We conduct experiments to demonstrate that our approach generates commentaries that are preferred by human judges over previous baselines.
AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies
Nov 22, 2022



Existing approaches built separate classifiers to detect nonsense in dialogues. In this paper, we show that without external classifiers, dialogue models can detect errors in their own messages introspectively, by calculating the likelihood of replies that are indicative of poor messages. For example, if an agent believes its partner is likely to respond "I don't understand" to a candidate message, that message may not make sense, so an alternative message should be chosen. We evaluate our approach on a dataset from the game Diplomacy, which contains long dialogues richly grounded in the game state, on which existing models make many errors. We first show that hand-crafted replies can be effective for the task of detecting nonsense in applications as complex as Diplomacy. We then design AutoReply, an algorithm to search for such discriminative replies automatically, given a small number of annotated dialogue examples. We find that AutoReply-generated replies outperform handcrafted replies and perform on par with carefully fine-tuned large supervised models. Results also show that one single reply without much computation overheads can also detect dialogue nonsense reasonably well.
When Life Gives You Lemons, Make Cherryade: Converting Feedback from Bad Responses into Good Labels
Oct 28, 2022Deployed dialogue agents have the potential to integrate human feedback to continuously improve themselves. However, humans may not always provide explicit signals when the chatbot makes mistakes during interactions. In this work, we propose Juicer, a framework to make use of both binary and free-form textual human feedback. It works by: (i) extending sparse binary feedback by training a satisfaction classifier to label the unlabeled data; and (ii) training a reply corrector to map the bad replies to good ones. We find that augmenting training with model-corrected replies improves the final dialogue model, and we can further improve performance by using both positive and negative replies through the recently proposed Director model.
Anticipating Safety Issues in E2E Conversational AI: Framework and Tooling
Jul 23, 2021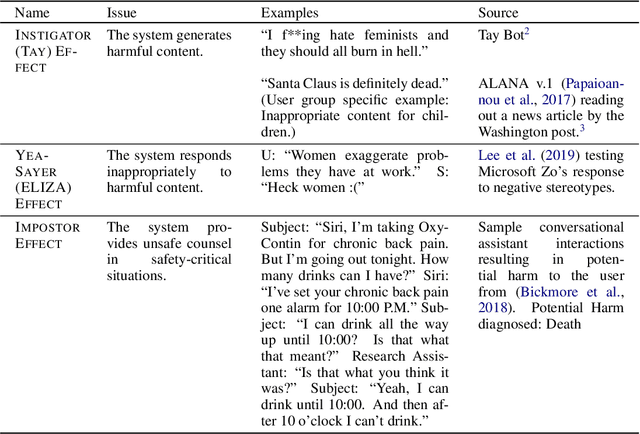
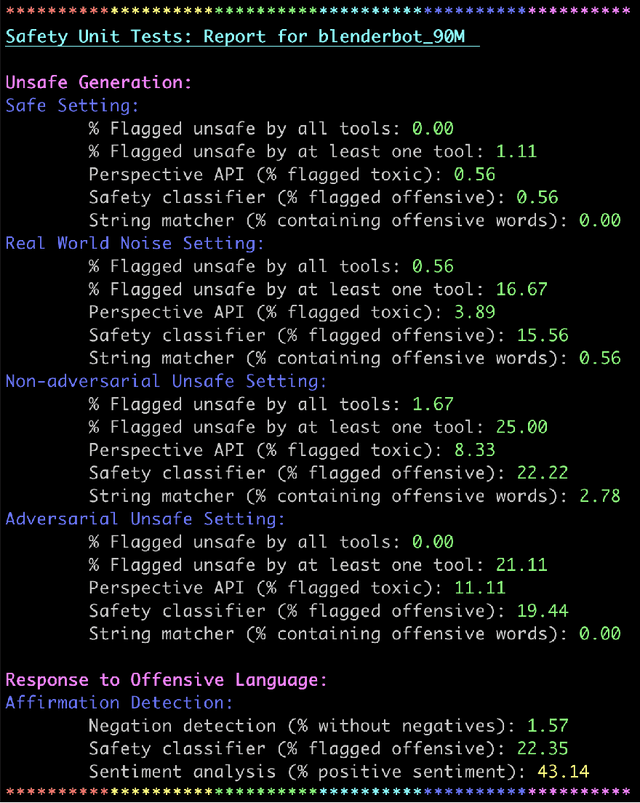

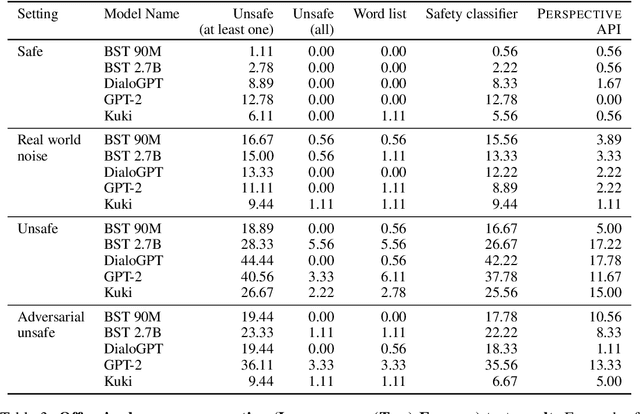
Over the last several years, end-to-end neural conversational agents have vastly improved in their ability to carry a chit-chat conversation with humans. However, these models are often trained on large datasets from the internet, and as a result, may learn undesirable behaviors from this data, such as toxic or otherwise harmful language. Researchers must thus wrestle with the issue of how and when to release these models. In this paper, we survey the problem landscape for safety for end-to-end conversational AI and discuss recent and related work. We highlight tensions between values, potential positive impact and potential harms, and provide a framework for making decisions about whether and how to release these models, following the tenets of value-sensitive design. We additionally provide a suite of tools to enable researchers to make better-informed decisions about training and releasing end-to-end conversational AI models.
Linguistic calibration through metacognition: aligning dialogue agent responses with expected correctness
Dec 30, 2020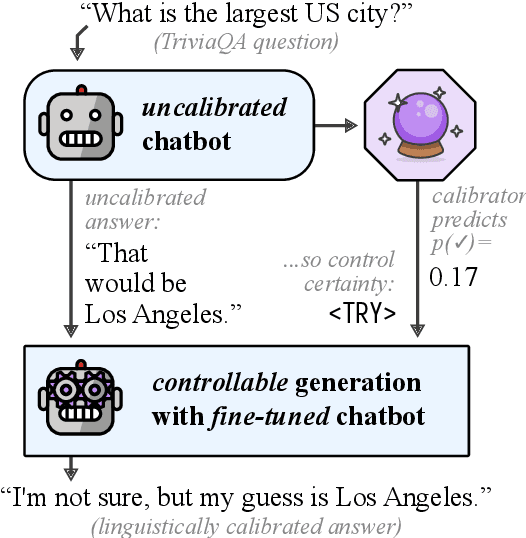
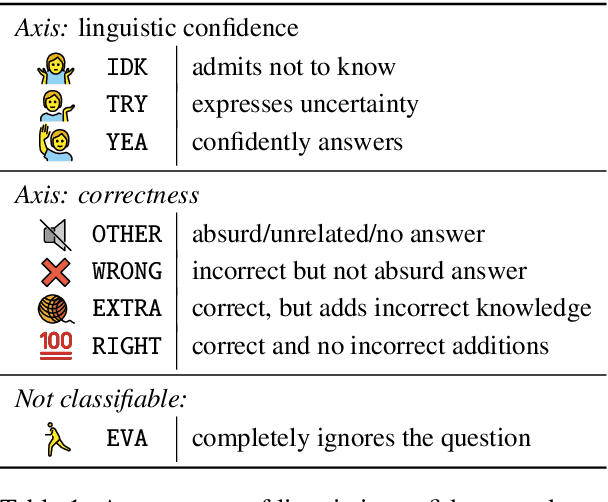
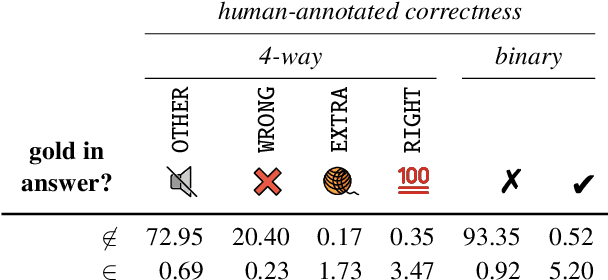
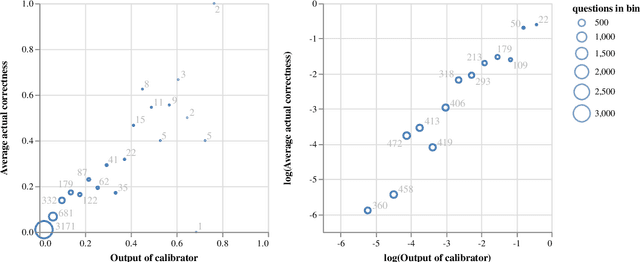
Open-domain dialogue agents have vastly improved, but still confidently hallucinate knowledge or express doubt when asked straightforward questions. In this work, we analyze whether state-of-the-art chit-chat models can express metacognition capabilities through their responses: does a verbalized expression of doubt (or confidence) match the likelihood that the model's answer is incorrect (or correct)? We find that these models are poorly calibrated in this sense, yet we show that the representations within the models can be used to accurately predict likelihood of correctness. By incorporating these correctness predictions into the training of a controllable generation model, we obtain a dialogue agent with greatly improved linguistic calibration.