 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Optimality Guarantees for Solving Continuous Observation POMDPs through Particle Belief MDP Approximation
Oct 10, 2022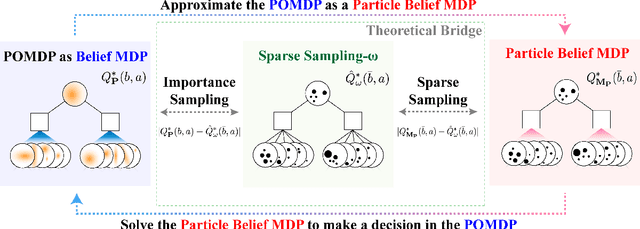
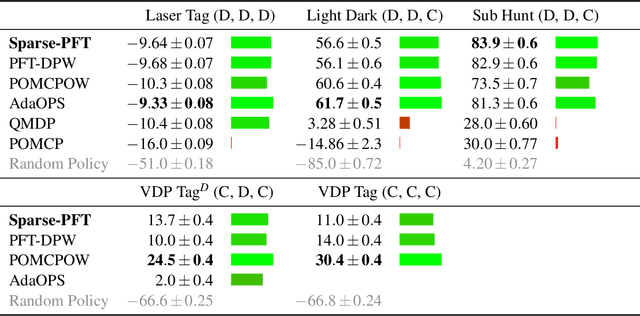
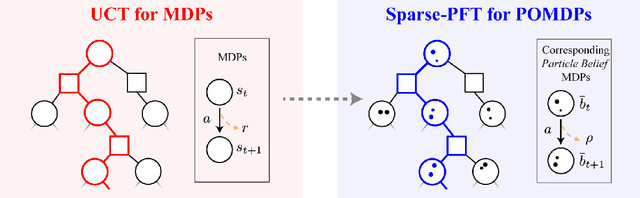
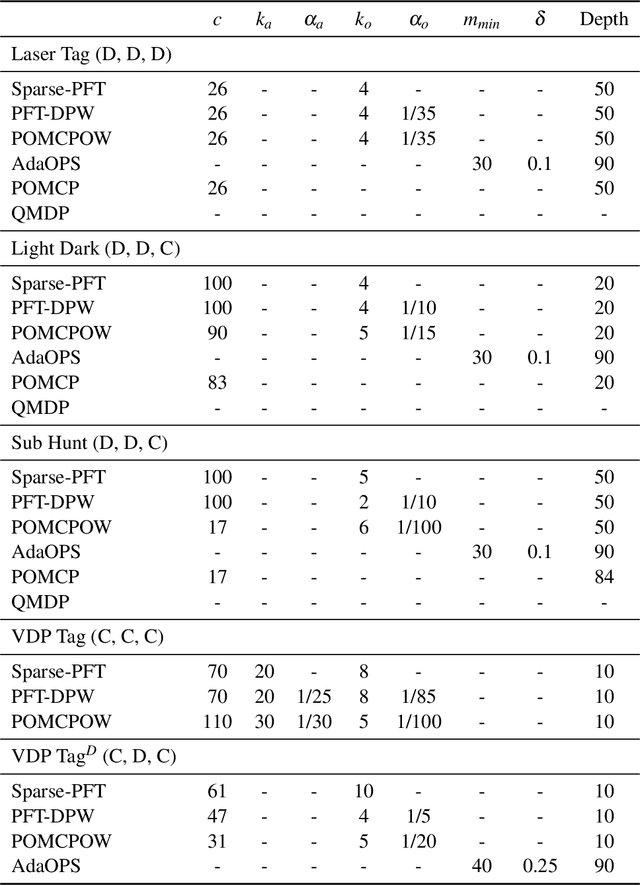
Partially observable Markov decision processes (POMDPs) provide a flexible representation for real-world decision and control problems. However, POMDPs are notoriously difficult to solve, especially when the state and observation spaces are continuous or hybrid, which is often the case for physical systems. While recent online sampling-based POMDP algorithms that plan with observation likelihood weighting have shown practical effectiveness, a general theory bounding the approximation error of the particle filtering techniques that these algorithms use has not previously been proposed. Our main contribution is to formally justify that optimality guarantees in a finite sample particle belief MDP (PB-MDP) approximation of a POMDP/belief MDP yields optimality guarantees in the original POMDP as well. This fundamental bridge between PB-MDPs and POMDPs allows us to adapt any sampling-based MDP algorithm of choice to a POMDP by solving the corresponding particle belief MDP approximation and preserve the convergence guarantees in the POMDP. Practically, this means additionally assuming access to the observation density model, and simply swapping out the state transition generative model with a particle filtering-based model, which only increases the computational complexity by a factor of $\mathcal{O}(C)$, with $C$ the number of particles in a particle belief state. In addition to our theoretical contribution, we perform five numerical experiments on benchmark POMDPs to demonstrate that a simple MDP algorithm adapted using PB-MDP approximation, Sparse-PFT, achieves performance competitive with other leading continuous observation POMDP solvers.
LOPR: Latent Occupancy PRediction using Generative Models
Oct 03, 2022
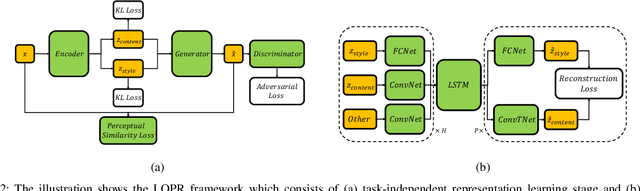
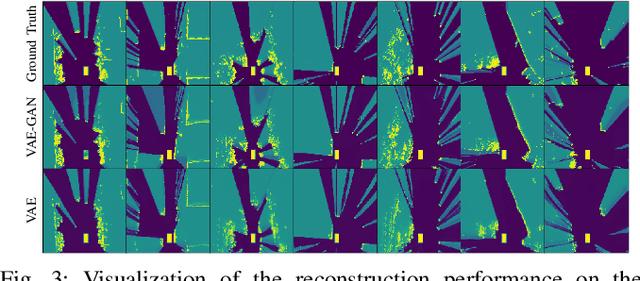

Environment prediction frameworks are essential for autonomous vehicles to facilitate safe maneuvers in a dynamic environment. Previous approaches have used occupancy grid maps as a bird's eye-view representation of the scene and optimized the prediction architectures directly in pixel space. Although these methods have had some success in spatiotemporal prediction, they are, at times, hindered by unrealistic and incorrect predictions. We postulate that the quality and realism of the forecasted occupancy grids can be improved with the use of generative models. We propose a framework that decomposes occupancy grid prediction into task-independent low-dimensional representation learning and task-dependent prediction in the latent space. We demonstrate that our approach achieves state-of-the-art performance on the real-world autonomous driving dataset, NuScenes.
Backward Reachability Analysis of Neural Feedback Loops: Techniques for Linear and Nonlinear Systems
Sep 28, 2022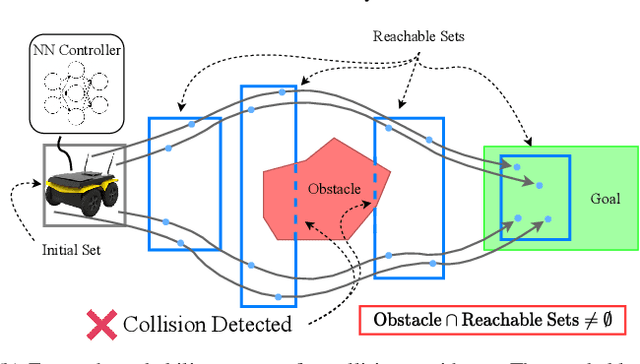

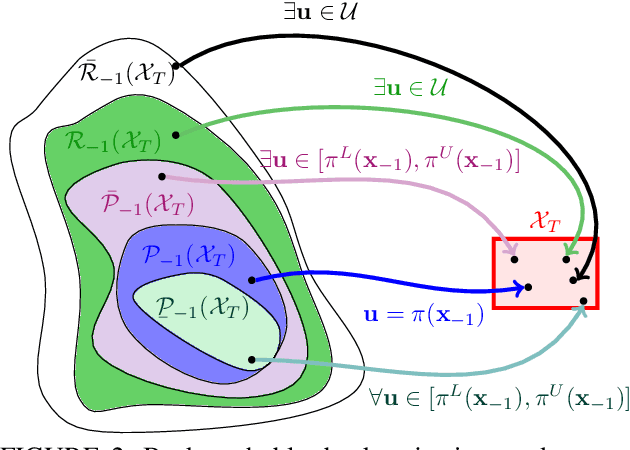

The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify safe behavior. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to efficiently find an over-approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present frameworks for calculating BP over-approximations for both linear and nonlinear systems with control policies represented by feedforward NNs and propose computationally efficient strategies. We use numerical results from a variety of models to showcase the proposed algorithms, including a demonstration of safety certification for a 6D system.
Dynamics-Aware Spatiotemporal Occupancy Prediction in Urban Environments
Sep 27, 2022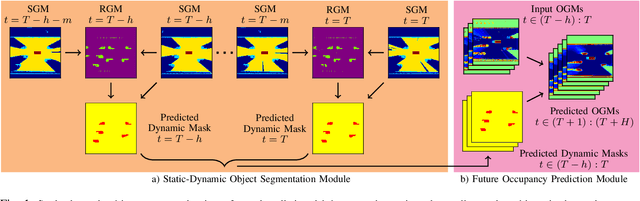

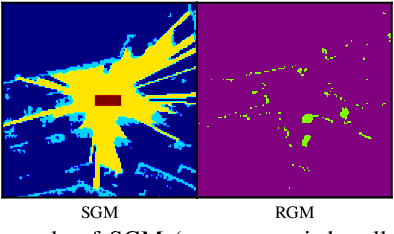
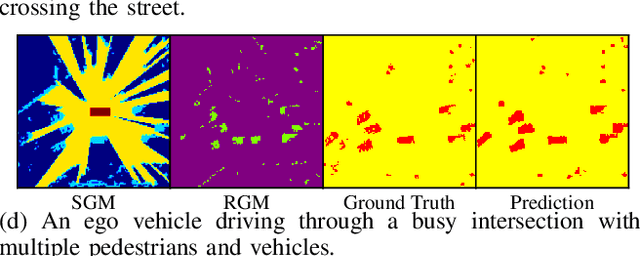
Detection and segmentation of moving obstacles, along with prediction of the future occupancy states of the local environment, are essential for autonomous vehicles to proactively make safe and informed decisions. In this paper, we propose a framework that integrates the two capabilities together using deep neural network architectures. Our method first detects and segments moving objects in the scene, and uses this information to predict the spatiotemporal evolution of the environment around autonomous vehicles. To address the problem of direct integration of both static-dynamic object segmentation and environment prediction models, we propose using occupancy-based environment representations across the whole framework. Our method is validated on the real-world Waymo Open Dataset and demonstrates higher prediction accuracy than baseline methods.
Collaborative Decision Making Using Action Suggestions
Sep 27, 2022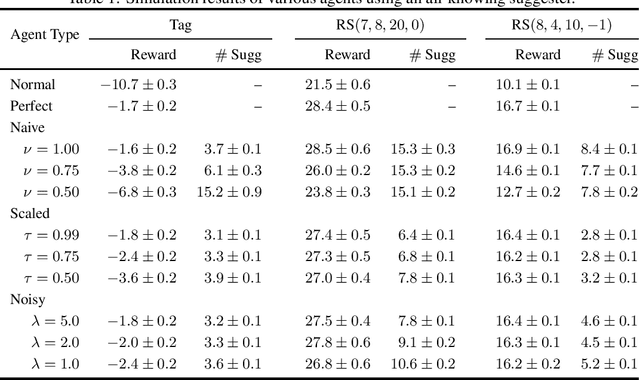
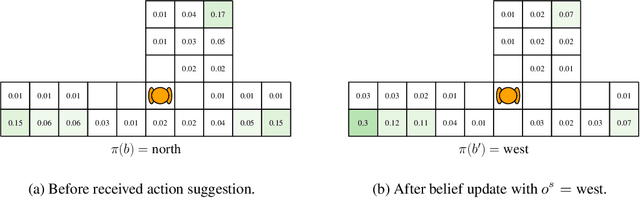
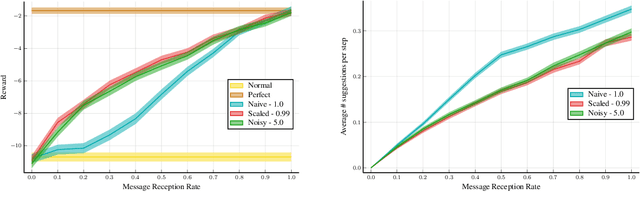
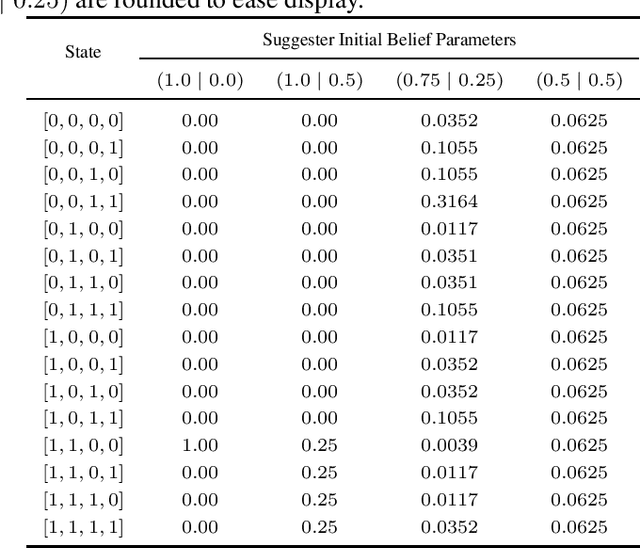
The level of autonomy is increasing in systems spanning multiple domains, but these systems still experience failures. One way to mitigate the risk of failures is to integrate human oversight of the autonomous systems and rely on the human to take control when the autonomy fails. In this work, we formulate a method of collaborative decision making through action suggestions that improves action selection without taking control of the system. Our approach uses each suggestion efficiently by incorporating the implicit information shared through suggestions to modify the agent's belief and achieves better performance with fewer suggestions than naively following the suggested actions. We assume collaborative agents share the same objective and communicate through valid actions. By assuming the suggested action is dependent only on the state, we can incorporate the suggested action as an independent observation of the environment. The assumption of a collaborative environment enables us to use the agent's policy to estimate the distribution over action suggestions. We propose two methods that use suggested actions and demonstrate the approach through simulated experiments. The proposed methodology results in increased performance while also being robust to suboptimal suggestions.
Sequential Bayesian Optimization for Adaptive Informative Path Planning with Multimodal Sensing
Sep 16, 2022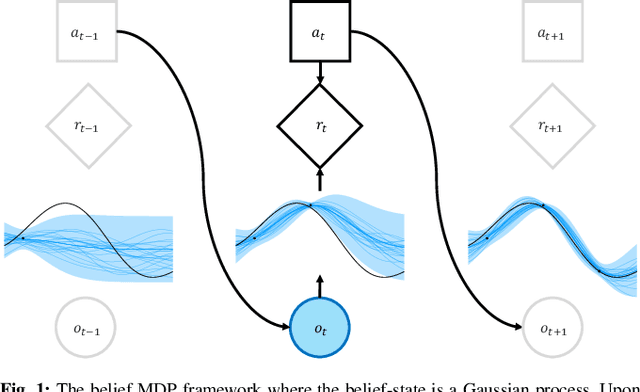
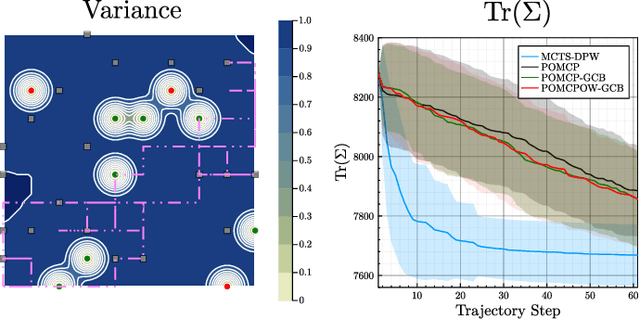
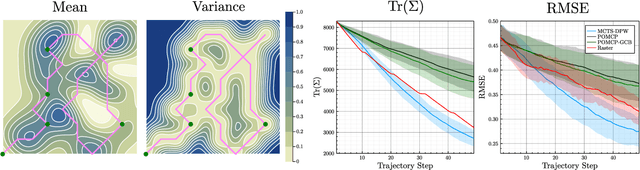

Adaptive Informative Path Planning with Multimodal Sensing (AIPPMS) considers the problem of an agent equipped with multiple sensors, each with different sensing accuracy and energy costs. The agent's goal is to explore the environment and gather information subject to its resource constraints in unknown, partially observable environments. Previous work has focused on the less general Adaptive Informative Path Planning (AIPP) problem, which considers only the effect of the agent's movement on received observations. The AIPPMS problem adds additional complexity by requiring that the agent reasons jointly about the effects of sensing and movement while balancing resource constraints with information objectives. We formulate the AIPPMS problem as a belief Markov decision process with Gaussian process beliefs and solve it using a sequential Bayesian optimization approach with online planning. Our approach consistently outperforms previous AIPPMS solutions by more than doubling the average reward received in almost every experiment while also reducing the root-mean-square error in the environment belief by 50%. We completely open-source our implementation to aid in further development and comparison.
Multi-Objective Policy Gradients with Topological Constraints
Sep 15, 2022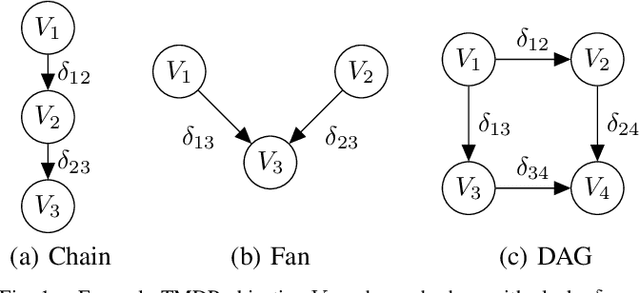
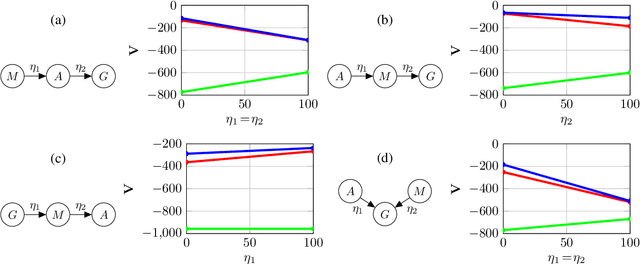

Multi-objective optimization models that encode ordered sequential constraints provide a solution to model various challenging problems including encoding preferences, modeling a curriculum, and enforcing measures of safety. A recently developed theory of topological Markov decision processes (TMDPs) captures this range of problems for the case of discrete states and actions. In this work, we extend TMDPs towards continuous spaces and unknown transition dynamics by formulating, proving, and implementing the policy gradient theorem for TMDPs. This theoretical result enables the creation of TMDP learning algorithms that use function approximators, and can generalize existing deep reinforcement learning (DRL) approaches. Specifically, we present a new algorithm for a policy gradient in TMDPs by a simple extension of the proximal policy optimization (PPO) algorithm. We demonstrate this on a real-world multiple-objective navigation problem with an arbitrary ordering of objectives both in simulation and on a real robot.
Risk-aware Meta-level Decision Making for Exploration Under Uncertainty
Sep 12, 2022
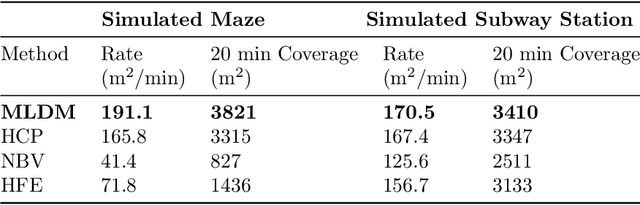
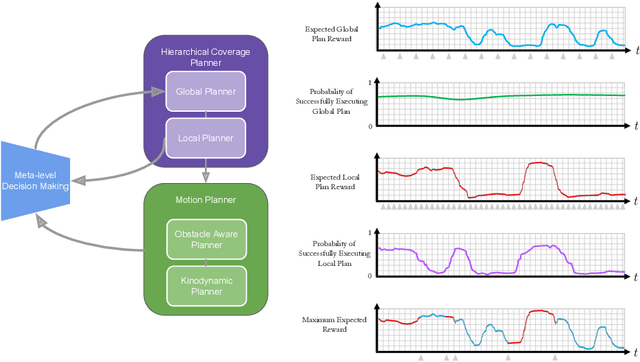
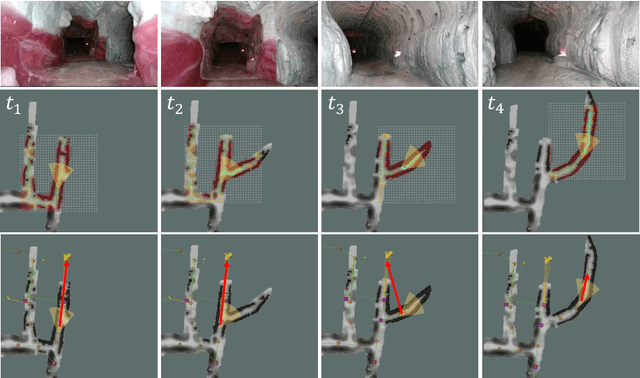
Robotic exploration of unknown environments is fundamentally a problem of decision making under uncertainty where the robot must account for uncertainty in sensor measurements, localization, action execution, as well as many other factors. For large-scale exploration applications, autonomous systems must overcome the challenges of sequentially deciding which areas of the environment are valuable to explore while safely evaluating the risks associated with obstacles and hazardous terrain. In this work, we propose a risk-aware meta-level decision making framework to balance the tradeoffs associated with local and global exploration. Meta-level decision making builds upon classical hierarchical coverage planners by switching between local and global policies with the overall objective of selecting the policy that is most likely to maximize reward in a stochastic environment. We use information about the environment history, traversability risk, and kinodynamic constraints to reason about the probability of successful policy execution to switch between local and global policies. We have validated our solution in both simulation and on a variety of large-scale real world hardware tests. Our results show that by balancing local and global exploration we are able to significantly explore large-scale environments more efficiently.
EvolveHypergraph: Group-Aware Dynamic Relational Reasoning for Trajectory Prediction
Aug 10, 2022
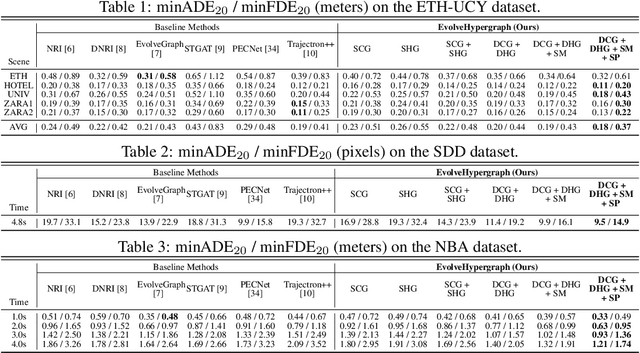
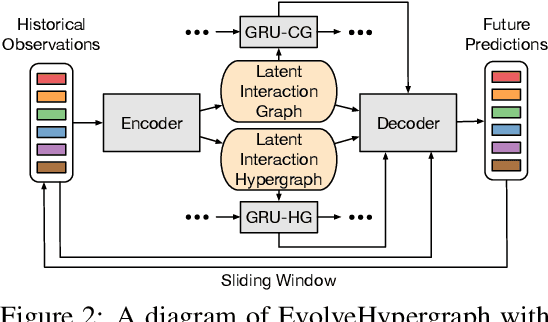
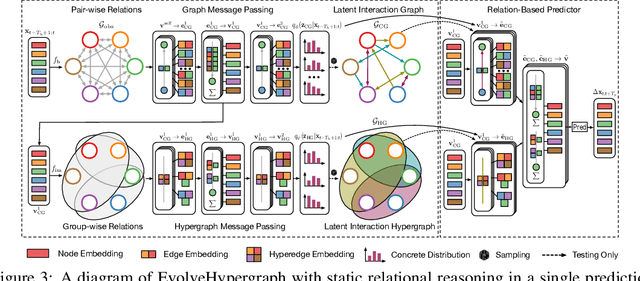
While the modeling of pair-wise relations has been widely studied in multi-agent interacting systems, its ability to capture higher-level and larger-scale group-wise activities is limited. In this paper, we propose a group-aware relational reasoning approach (named EvolveHypergraph) with explicit inference of the underlying dynamically evolving relational structures, and we demonstrate its effectiveness for multi-agent trajectory prediction. In addition to the edges between a pair of nodes (i.e., agents), we propose to infer hyperedges that adaptively connect multiple nodes to enable group-aware relational reasoning in an unsupervised manner without fixing the number of hyperedges. The proposed approach infers the dynamically evolving relation graphs and hypergraphs over time to capture the evolution of relations, which are used by the trajectory predictor to obtain future states. Moreover, we propose to regularize the smoothness of the relation evolution and the sparsity of the inferred graphs or hypergraphs, which effectively improves training stability and enhances the explainability of inferred relations. The proposed approach is validated on both synthetic crowd simulations and multiple real-world benchmark datasets. Our approach infers explainable, reasonable group-aware relations and achieves state-of-the-art performance in long-term prediction.
Uncertainty-Aware Online Merge Planning with Learned Driver Behavior
Jul 11, 2022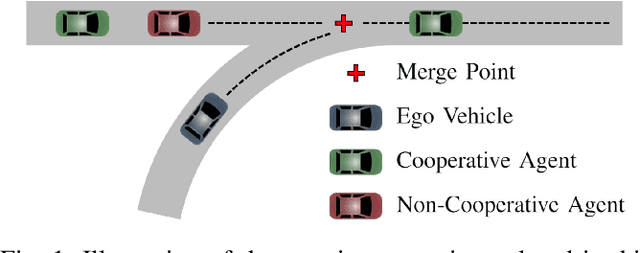
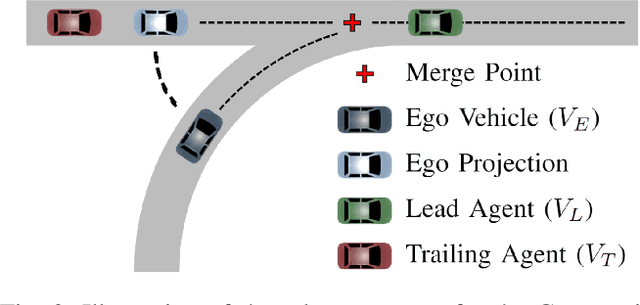
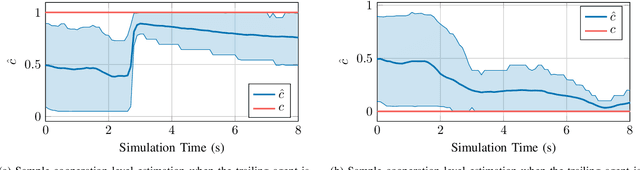
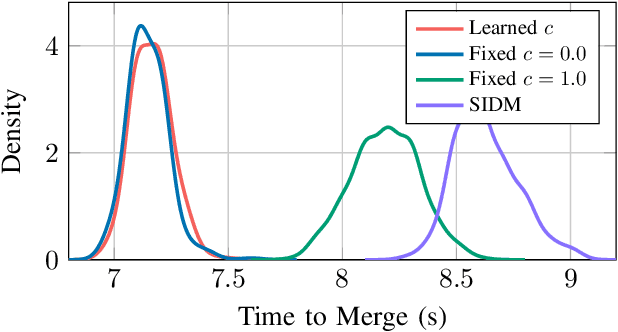
Safe and reliable autonomy solutions are a critical component of next-generation intelligent transportation systems. Autonomous vehicles in such systems must reason about complex and dynamic driving scenes in real time and anticipate the behavior of nearby drivers. Human driving behavior is highly nuanced and specific to individual traffic participants. For example, drivers might display cooperative or non-cooperative behaviors in the presence of merging vehicles. These behaviors must be estimated and incorporated in the planning process for safe and efficient driving. In this work, we present a framework for estimating the cooperation level of drivers on a freeway and plan merging maneuvers with the drivers' latent behaviors explicitly modeled. The latent parameter estimation problem is solved using a particle filter to approximate the probability distribution over the cooperation level. A partially observable Markov decision process (POMDP) that includes the latent state estimate is solved online to extract a policy for a merging vehicle. We evaluate our method in a high-fidelity automotive simulator against methods that are agnostic to latent states or rely on $\textit{a priori}$ assumptions about actor behavior.