 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoCon: Pseudo-label Refinement via Online Clustering and Prototypical Consistency for Efficient Semi-supervised Learning
Mar 22, 2023



Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually underperform. ProtoCon refines the pseudo-labels by leveraging their nearest neighbours' information. The neighbours are identified as the training proceeds using an online clustering approach operating in an embedding space trained via a prototypical loss to encourage well-formed clusters. The online nature of ProtoCon allows it to utilise the label history of the entire dataset in one training cycle to refine labels in the following cycle without the need to store image embeddings. Hence, it can seamlessly scale to larger datasets at a low cost. Finally, ProtoCon addresses the poor training signal in the initial phase of training (due to fewer confident predictions) by introducing an auxiliary self-supervised loss. It delivers significant gains and faster convergence over state-of-the-art across 5 datasets, including CIFARs, ImageNet and DomainNet.
MARLIN: Masked Autoencoder for facial video Representation LearnINg
Nov 12, 2022



This paper proposes a self-supervised approach to learn universal facial representations from videos, that can transfer across a variety of facial analysis tasks such as Facial Attribute Recognition (FAR), Facial Expression Recognition (FER), DeepFake Detection (DFD), and Lip Synchronization (LS). Our proposed framework, named MARLIN, is a facial video masked autoencoder, that learns highly robust and generic facial embeddings from abundantly available non-annotated web crawled facial videos. As a challenging auxiliary task, MARLIN reconstructs the spatio-temporal details of the face from the densely masked facial regions which mainly include eyes, nose, mouth, lips, and skin to capture local and global aspects that in turn help in encoding generic and transferable features. Through a variety of experiments on diverse downstream tasks, we demonstrate MARLIN to be an excellent facial video encoder as well as feature extractor, that performs consistently well across a variety of downstream tasks including FAR (1.13% gain over supervised benchmark), FER (2.64% gain over unsupervised benchmark), DFD (1.86% gain over unsupervised benchmark), LS (29.36% gain for Frechet Inception Distance), and even in low data regime. Our codes and pre-trained models will be made public.
LAVA: Label-efficient Visual Learning and Adaptation
Oct 19, 2022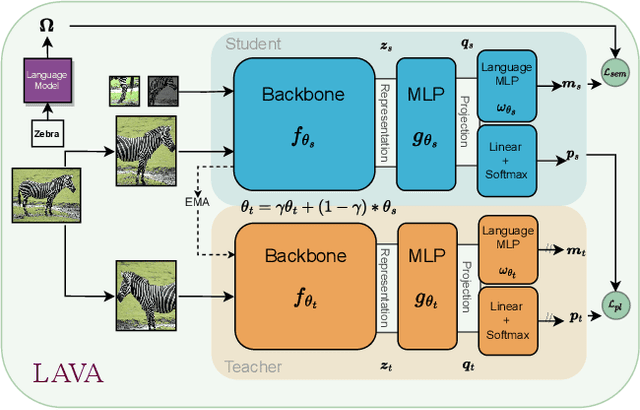


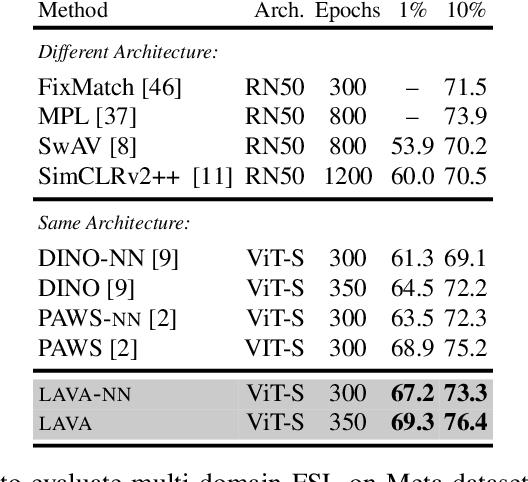
We present LAVA, a simple yet effective method for multi-domain visual transfer learning with limited data. LAVA builds on a few recent innovations to enable adapting to partially labelled datasets with class and domain shifts. First, LAVA learns self-supervised visual representations on the source dataset and ground them using class label semantics to overcome transfer collapse problems associated with supervised pretraining. Secondly, LAVA maximises the gains from unlabelled target data via a novel method which uses multi-crop augmentations to obtain highly robust pseudo-labels. By combining these ingredients, LAVA achieves a new state-of-the-art on ImageNet semi-supervised protocol, as well as on 7 out of 10 datasets in multi-domain few-shot learning on the Meta-dataset. Code and models are made available.
CLIP model is an Efficient Continual Learner
Oct 06, 2022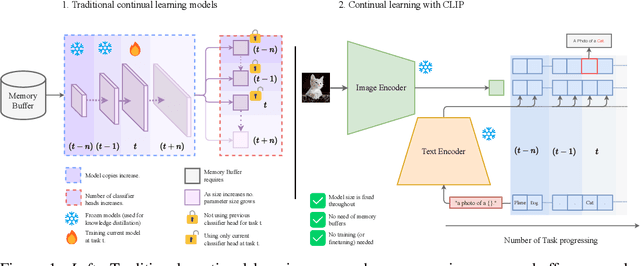
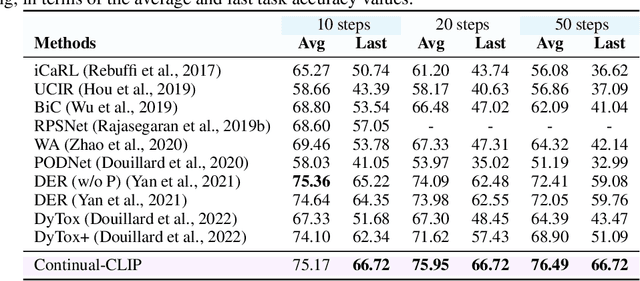
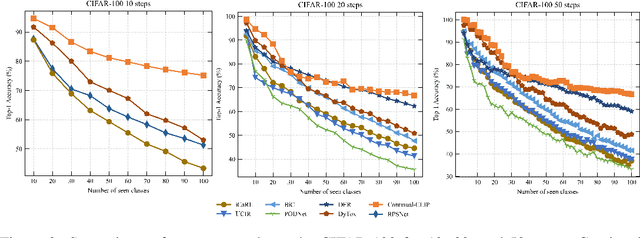
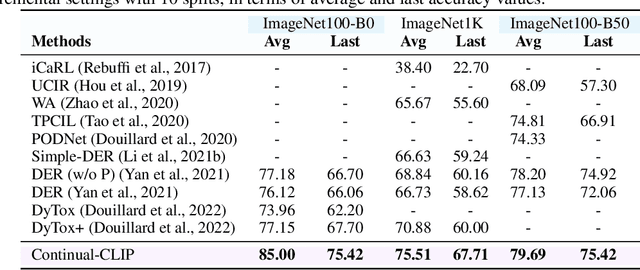
The continual learning setting aims to learn new tasks over time without forgetting the previous ones. The literature reports several significant efforts to tackle this problem with limited or no access to previous task data. Among such efforts, typical solutions offer sophisticated techniques involving memory replay, knowledge distillation, model regularization, and dynamic network expansion. The resulting methods have a retraining cost at each learning task, dedicated memory requirements, and setting-specific design choices. In this work, we show that a frozen CLIP (Contrastive Language-Image Pretraining) model offers astounding continual learning performance without any fine-tuning (zero-shot evaluation). We evaluate CLIP under a variety of settings including class-incremental, domain-incremental and task-agnostic incremental learning on five popular benchmarks (ImageNet-100 & 1K, CORe50, CIFAR-100, and TinyImageNet). Without any bells and whistles, the CLIP model outperforms the state-of-the-art continual learning approaches in the majority of the settings. We show the effect on the CLIP model's performance by varying text inputs with simple prompt templates. To the best of our knowledge, this is the first work to report the CLIP zero-shot performance in a continual setting. We advocate the use of this strong yet embarrassingly simple baseline for future comparisons in the continual learning tasks.
Hybrid Window Attention Based Transformer Architecture for Brain Tumor Segmentation
Sep 16, 2022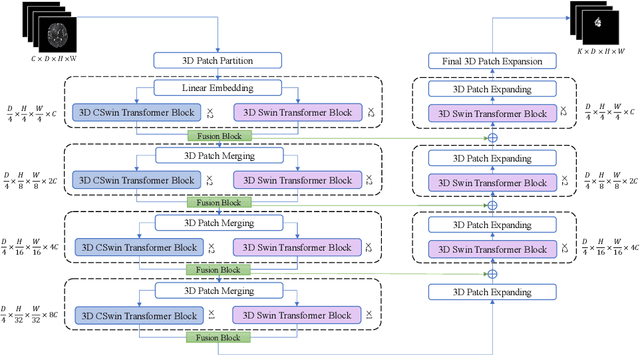
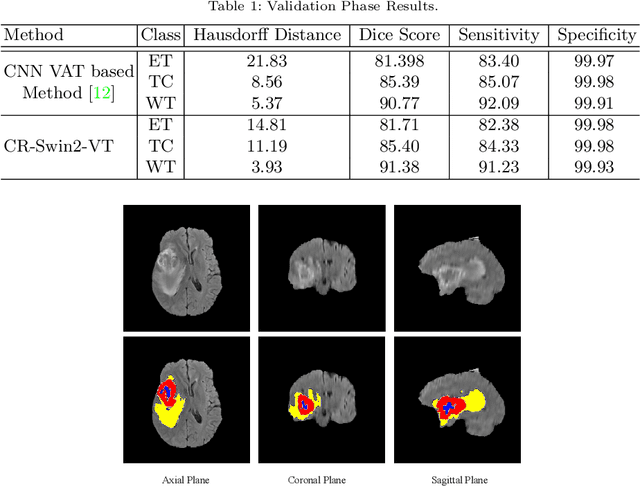
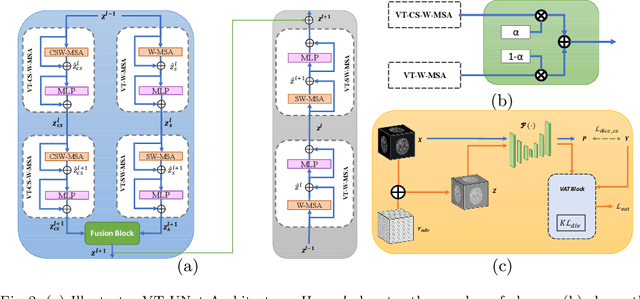
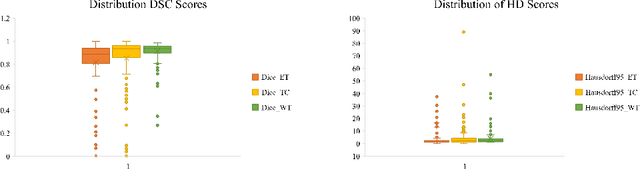
As intensities of MRI volumes are inconsistent across institutes, it is essential to extract universal features of multi-modal MRIs to precisely segment brain tumors. In this concept, we propose a volumetric vision transformer that follows two windowing strategies in attention for extracting fine features and local distributional smoothness (LDS) during model training inspired by virtual adversarial training (VAT) to make the model robust. We trained and evaluated network architecture on the FeTS Challenge 2022 dataset. Our performance on the online validation dataset is as follows: Dice Similarity Score of 81.71%, 91.38% and 85.40%; Hausdorff Distance (95%) of 14.81 mm, 3.93 mm, 11.18 mm for the enhancing tumor, whole tumor, and tumor core, respectively. Overall, the experimental results verify our method's effectiveness by yielding better performance in segmentation accuracy for each tumor sub-region. Our code implementation is publicly available : https://github.com/himashi92/vizviva_fets_2022
Defense against Privacy Leakage in Federated Learning
Sep 13, 2022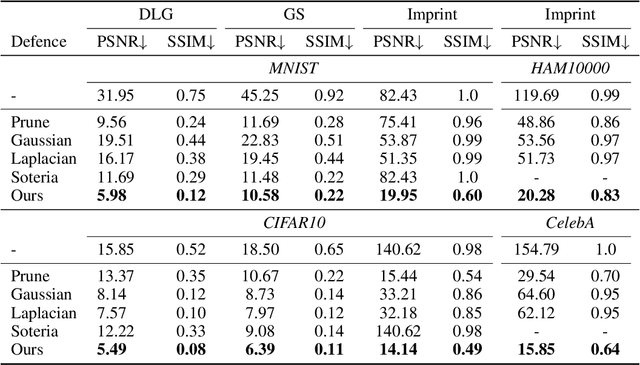
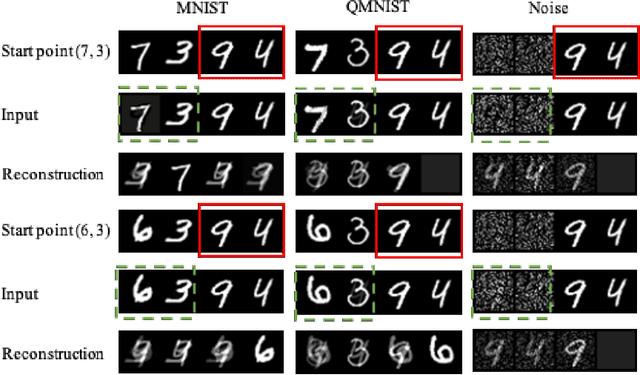
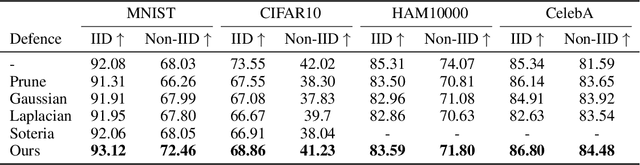

Federated Learning (FL) provides a promising distributed learning paradigm, since it seeks to protect users privacy by not sharing their private training data. Recent research has demonstrated, however, that FL is susceptible to model inversion attacks, which can reconstruct users' private data by eavesdropping on shared gradients. Existing defense solutions cannot survive stronger attacks and exhibit a poor trade-off between privacy and performance. In this paper, we present a straightforward yet effective defense strategy based on obfuscating the gradients of sensitive data with concealing data. Specifically, we alter a few samples within a mini batch to mimic the sensitive data at the gradient levels. Using a gradient projection technique, our method seeks to obscure sensitive data without sacrificing FL performance. Our extensive evaluations demonstrate that, compared to other defenses, our technique offers the highest level of protection while preserving FL performance. Our source code is located in the repository.
'Labelling the Gaps': A Weakly Supervised Automatic Eye Gaze Estimation
Aug 12, 2022
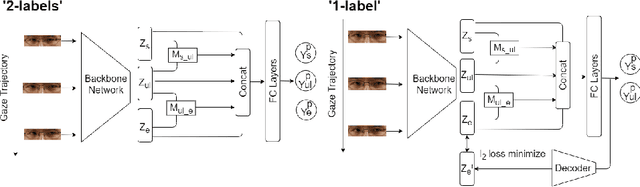
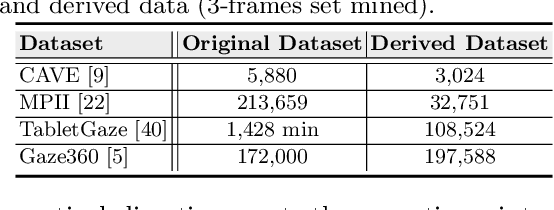
Over the past few years, there has been an increasing interest to interpret gaze direction in an unconstrained environment with limited supervision. Owing to data curation and annotation issues, replicating gaze estimation method to other platforms, such as unconstrained outdoor or AR/VR, might lead to significant drop in performance due to insufficient availability of accurately annotated data for model training. In this paper, we explore an interesting yet challenging problem of gaze estimation method with a limited amount of labelled data. The proposed method distills knowledge from the labelled subset with visual features; including identity-specific appearance, gaze trajectory consistency and motion features. Given a gaze trajectory, the method utilizes label information of only the start and the end frames of a gaze sequence. An extension of the proposed method further reduces the requirement of labelled frames to only the start frame with a minor drop in the generated label's quality. We evaluate the proposed method on four benchmark datasets (CAVE, TabletGaze, MPII and Gaze360) as well as web-crawled YouTube videos. Our proposed method reduces the annotation effort to as low as 2.67%, with minimal impact on performance; indicating the potential of our model enabling gaze estimation 'in-the-wild' setup.
AV-Gaze: A Study on the Effectiveness of Audio Guided Visual Attention Estimation for Non-Profilic Faces
Jul 07, 2022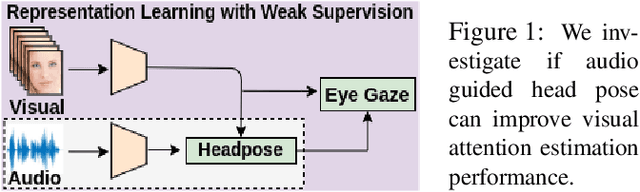
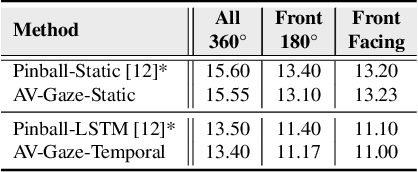
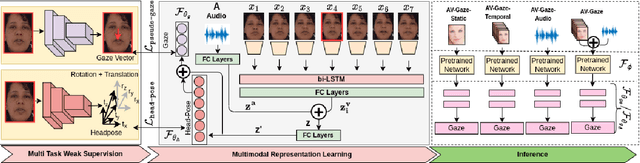
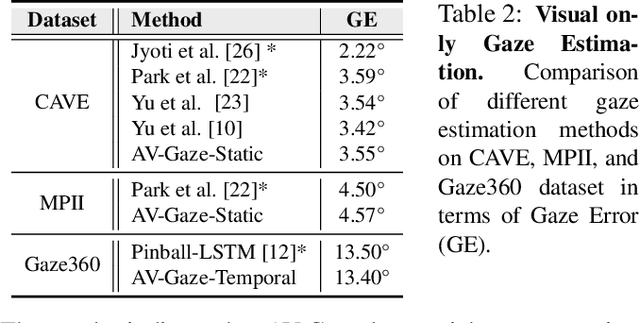
In challenging real-life conditions such as extreme head-pose, occlusions, and low-resolution images where the visual information fails to estimate visual attention/gaze direction, audio signals could provide important and complementary information. In this paper, we explore if audio-guided coarse head-pose can further enhance visual attention estimation performance for non-prolific faces. Since it is difficult to annotate audio signals for estimating the head-pose of the speaker, we use off-the-shelf state-of-the-art models to facilitate cross-modal weak-supervision. During the training phase, the framework learns complementary information from synchronized audio-visual modality. Our model can utilize any of the available modalities i.e. audio, visual or audio-visual for task-specific inference. It is interesting to note that, when AV-Gaze is tested on benchmark datasets with these specific modalities, it achieves competitive results on multiple datasets, while being highly adaptive towards challenging scenarios.
Transformer Scale Gate for Semantic Segmentation
May 14, 2022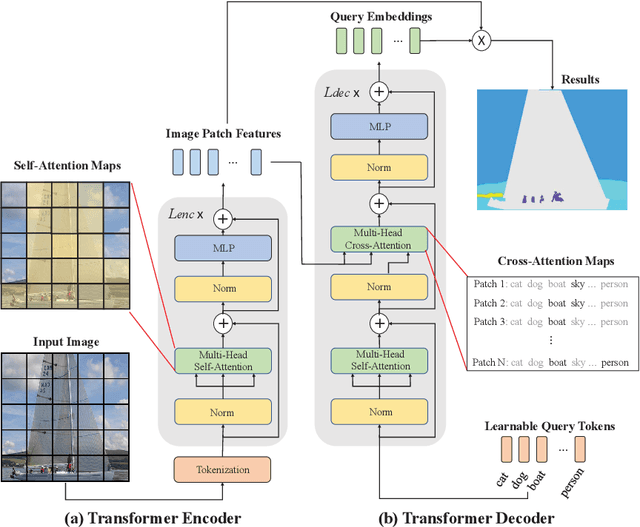
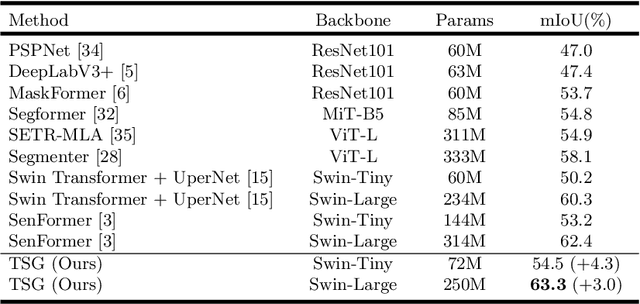

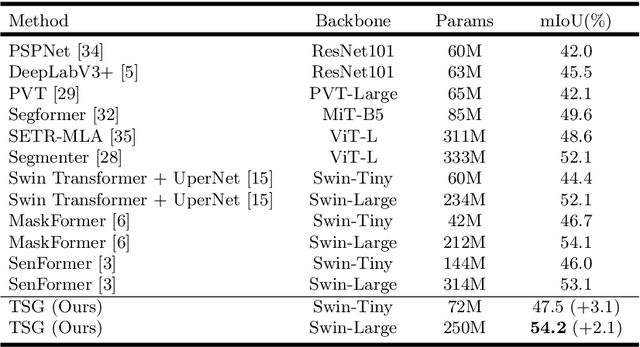
Effectively encoding multi-scale contextual information is crucial for accurate semantic segmentation. Existing transformer-based segmentation models combine features across scales without any selection, where features on sub-optimal scales may degrade segmentation outcomes. Leveraging from the inherent properties of Vision Transformers, we propose a simple yet effective module, Transformer Scale Gate (TSG), to optimally combine multi-scale features.TSG exploits cues in self and cross attentions in Vision Transformers for the scale selection. TSG is a highly flexible plug-and-play module, and can easily be incorporated with any encoder-decoder-based hierarchical vision Transformer architecture. Extensive experiments on the Pascal Context and ADE20K datasets demonstrate that our feature selection strategy achieves consistent gains.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.