 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Stationary Latent Bandits
Dec 01, 2020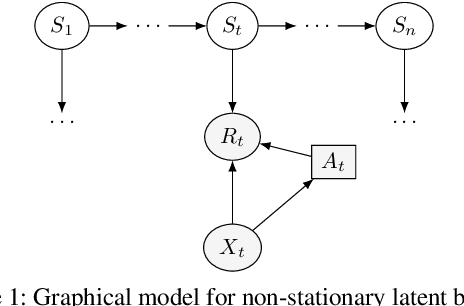
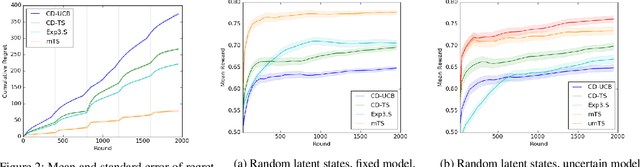
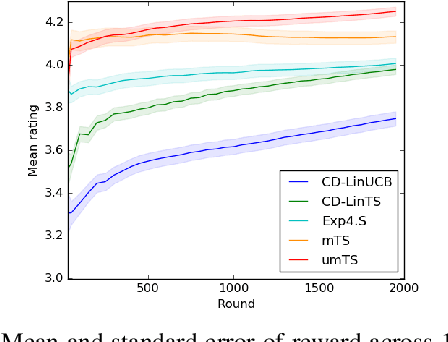
Users of recommender systems often behave in a non-stationary fashion, due to their evolving preferences and tastes over time. In this work, we propose a practical approach for fast personalization to non-stationary users. The key idea is to frame this problem as a latent bandit, where the prototypical models of user behavior are learned offline and the latent state of the user is inferred online from its interactions with the models. We call this problem a non-stationary latent bandit. We propose Thompson sampling algorithms for regret minimization in non-stationary latent bandits, analyze them, and evaluate them on a real-world dataset. The main strength of our approach is that it can be combined with rich offline-learned models, which can be misspecified, and are subsequently fine-tuned online using posterior sampling. In this way, we naturally combine the strengths of offline and online learning.
Soft-Robust Algorithms for Handling Model Misspecification
Nov 30, 2020
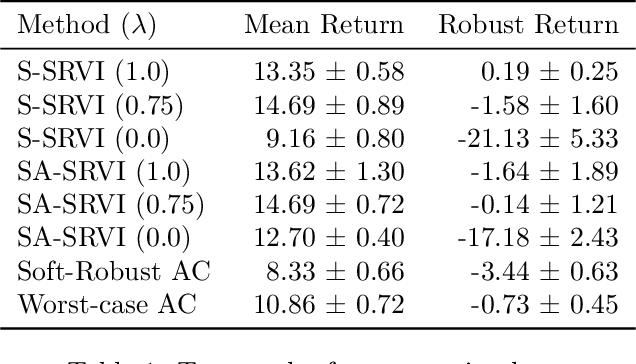
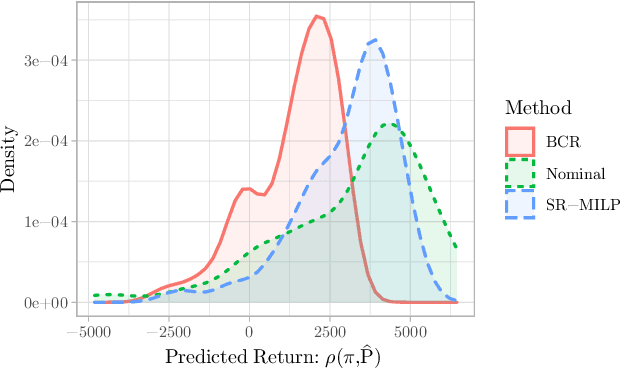
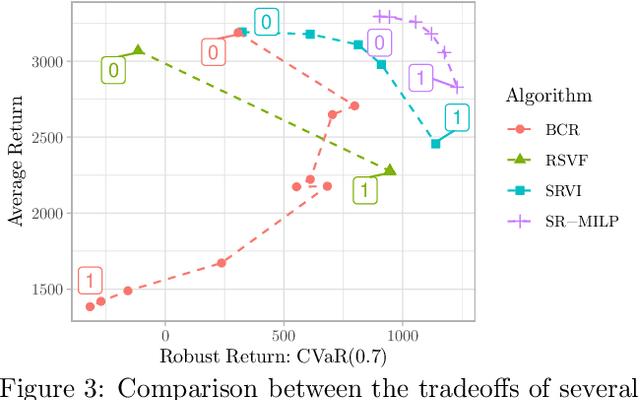
In reinforcement learning, robust policies for high-stakes decision-making problems with limited data are usually computed by optimizing the percentile criterion, which minimizes the probability of a catastrophic failure. Unfortunately, such policies are typically overly conservative as the percentile criterion is non-convex, difficult to optimize, and ignores the mean performance. To overcome these shortcomings, we study the soft-robust criterion, which uses risk measures to balance the mean and percentile criteria better. In this paper, we establish the soft-robust criterion's fundamental properties, show that it is NP-hard to optimize, and propose and analyze two algorithms to optimize it approximately. Our theoretical analyses and empirical evaluations demonstrate that our algorithms compute much less conservative solutions than the existing approximate methods for optimizing the percentile-criterion.
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 17, 2020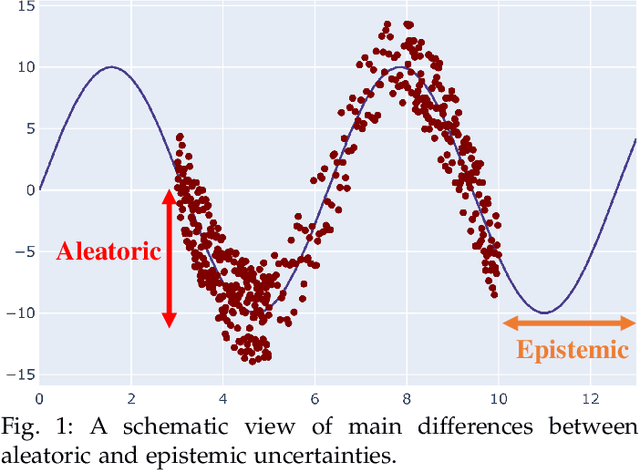
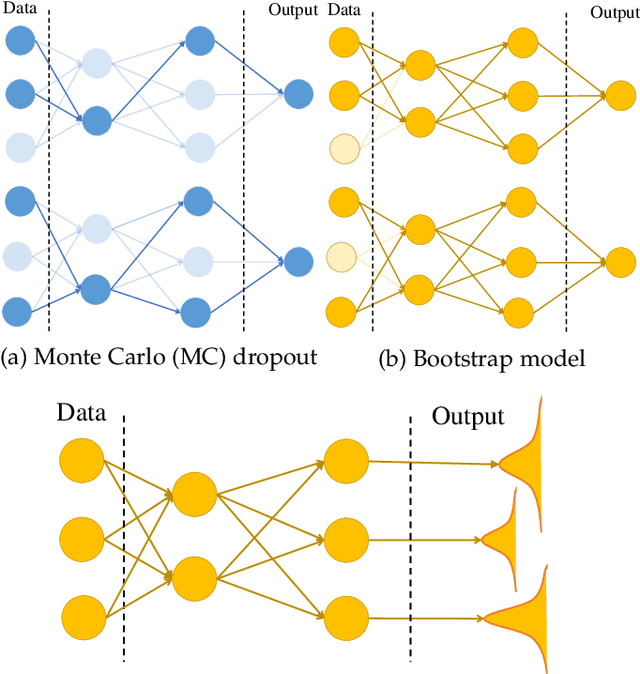
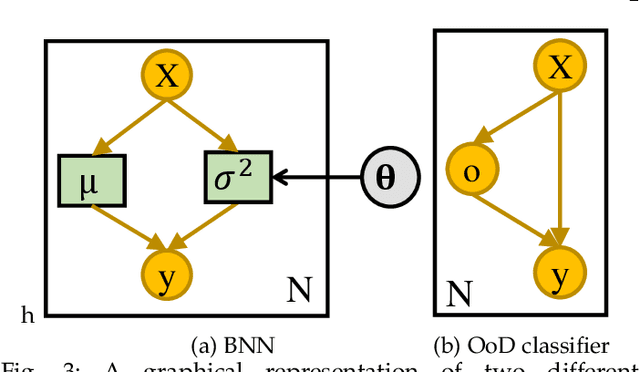
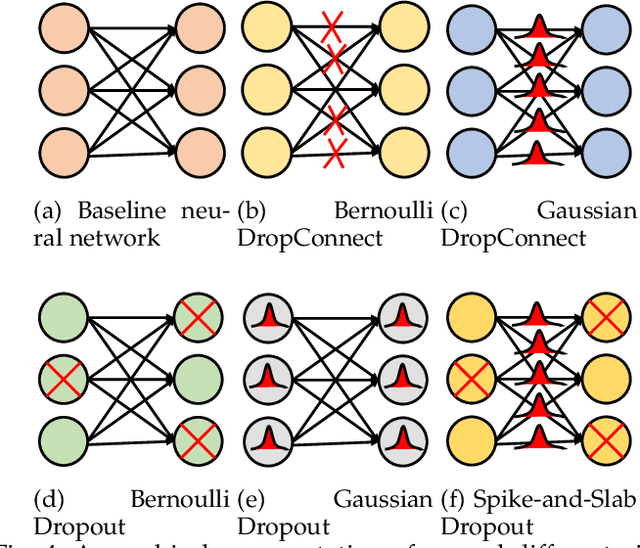
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc. This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
Variance-Reduced Off-Policy Memory-Efficient Policy Search
Sep 14, 2020
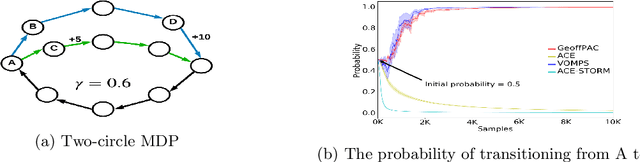
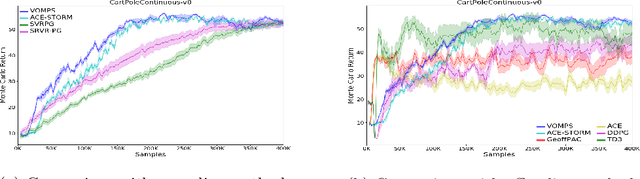
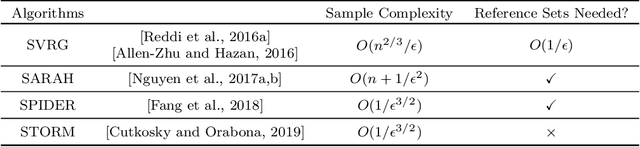
Off-policy policy optimization is a challenging problem in reinforcement learning (RL). The algorithms designed for this problem often suffer from high variance in their estimators, which results in poor sample efficiency, and have issues with convergence. A few variance-reduced on-policy policy gradient algorithms have been recently proposed that use methods from stochastic optimization to reduce the variance of the gradient estimate in the REINFORCE algorithm. However, these algorithms are not designed for the off-policy setting and are memory-inefficient, since they need to collect and store a large ``reference'' batch of samples from time to time. To achieve variance-reduced off-policy-stable policy optimization, we propose an algorithm family that is memory-efficient, stochastically variance-reduced, and capable of learning from off-policy samples. Empirical studies validate the effectiveness of the proposed approaches.
Finite-Sample Analysis of Proximal Gradient TD Algorithms
Jul 03, 2020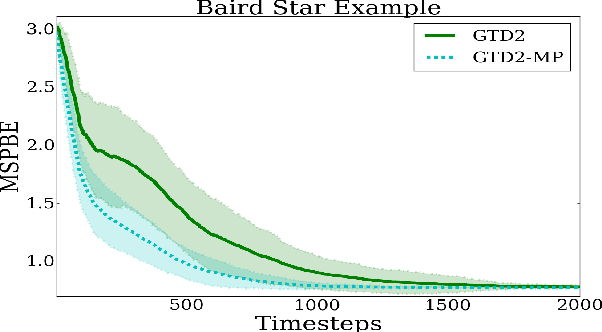
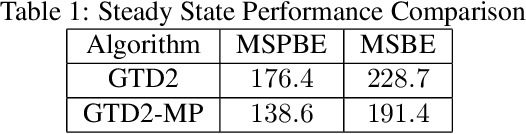
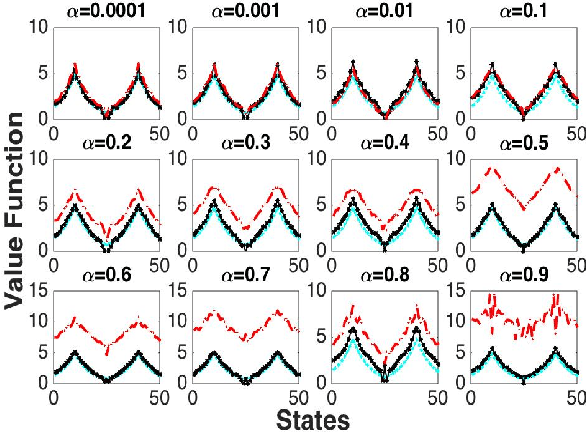
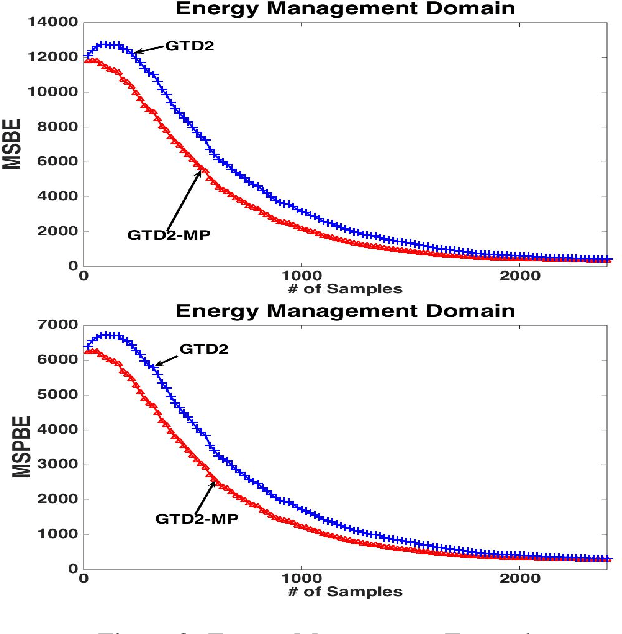
In this paper, we analyze the convergence rate of the gradient temporal difference learning (GTD) family of algorithms. Previous analyses of this class of algorithms use ODE techniques to prove asymptotic convergence, and to the best of our knowledge, no finite-sample analysis has been done. Moreover, there has been not much work on finite-sample analysis for convergent off-policy reinforcement learning algorithms. In this paper, we formulate GTD methods as stochastic gradient algorithms w.r.t.~a primal-dual saddle-point objective function, and then conduct a saddle-point error analysis to obtain finite-sample bounds on their performance. Two revised algorithms are also proposed, namely projected GTD2 and GTD2-MP, which offer improved convergence guarantees and acceleration, respectively. The results of our theoretical analysis show that the GTD family of algorithms are indeed comparable to the existing LSTD methods in off-policy learning scenarios.
Deep Bayesian Quadrature Policy Optimization
Jun 28, 2020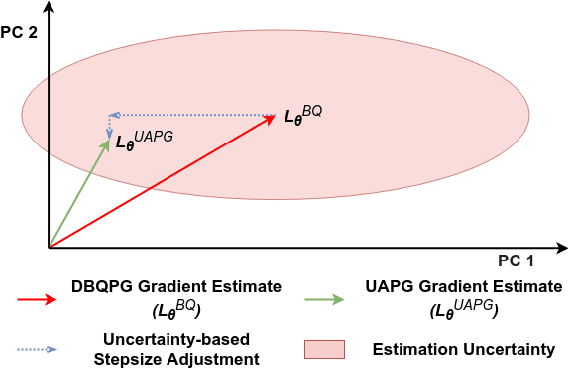

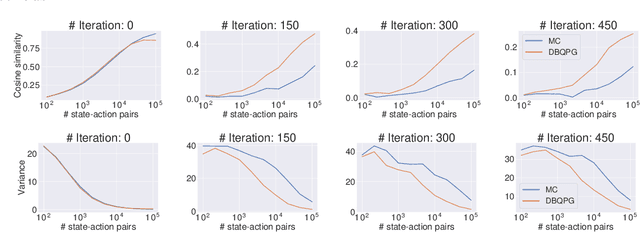
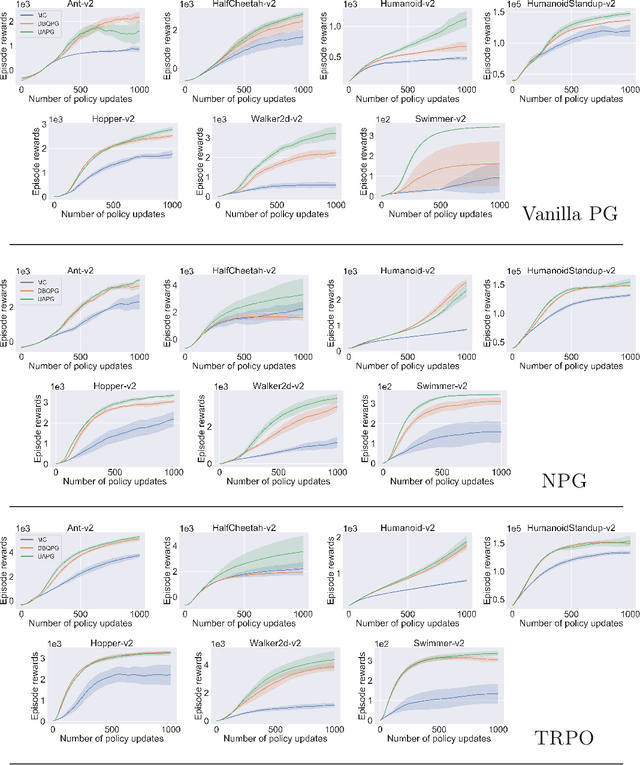
We study the problem of obtaining accurate policy gradient estimates. This challenge manifests in how best to estimate the policy gradient integral equation using a finite number of samples. Monte-Carlo methods have been the default choice for this purpose, despite suffering from high variance in the gradient estimates. On the other hand, more sample efficient alternatives like Bayesian quadrature methods are less scalable due to their high computational complexity. In this work, we propose deep Bayesian quadrature policy gradient (DBQPG), a computationally efficient high-dimensional generalization of Bayesian quadrature, to estimate the policy gradient integral equation. We show that DBQPG can substitute Monte-Carlo estimation in policy gradient methods, and demonstrate its effectiveness on a set of continuous control benchmarks for robotic locomotion. In comparison to Monte-Carlo estimation, DBQPG provides (i) more accurate gradient estimates with a significantly lower variance, (ii) a consistent improvement in the sample complexity and average return for several on-policy deep policy gradient algorithms, and, (iii) a methodological way to quantify the uncertainty in gradient estimation that can be incorporated to further improve the performance.
Variational Model-based Policy Optimization
Jun 24, 2020
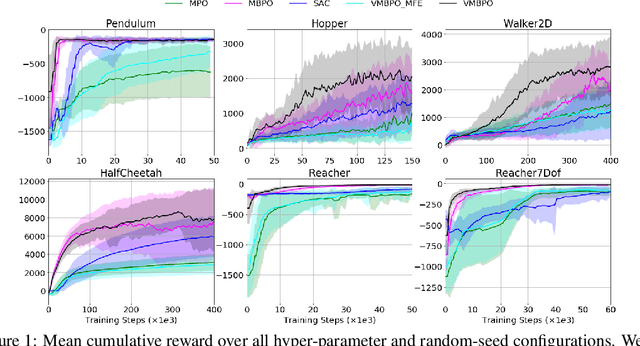
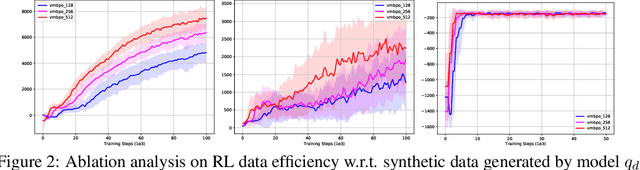
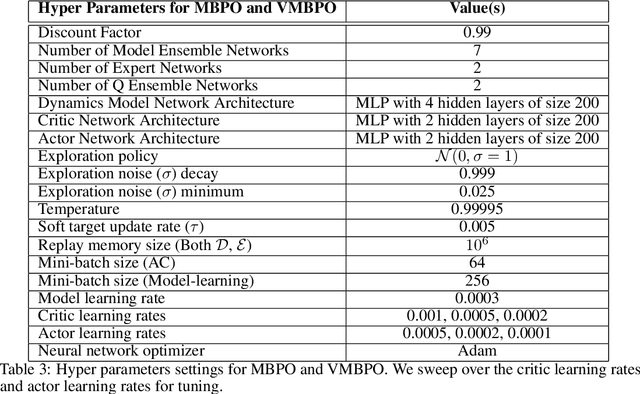
Model-based reinforcement learning (RL) algorithms allow us to combine model-generated data with those collected from interaction with the real system in order to alleviate the data efficiency problem in RL. However, designing such algorithms is often challenging because the bias in simulated data may overshadow the ease of data generation. A potential solution to this challenge is to jointly learn and improve model and policy using a universal objective function. In this paper, we leverage the connection between RL and probabilistic inference, and formulate such an objective function as a variational lower-bound of a log-likelihood. This allows us to use expectation maximization (EM) and iteratively fix a baseline policy and learn a variational distribution, consisting of a model and a policy (E-step), followed by improving the baseline policy given the learned variational distribution (M-step). We propose model-based and model-free policy iteration (actor-critic) style algorithms for the E-step and show how the variational distribution learned by them can be used to optimize the M-step in a fully model-based fashion. Our experiments on a number of continuous control tasks show that despite being more complex, our model-based (E-step) algorithm, called {\em variational model-based policy optimization} (VMBPO), is more sample-efficient and robust to hyper-parameter tuning than its model-free (E-step) counterpart. Using the same control tasks, we also compare VMBPO with several state-of-the-art model-based and model-free RL algorithms and show its sample efficiency and performance.
Control-Aware Representations for Model-based Reinforcement Learning
Jun 24, 2020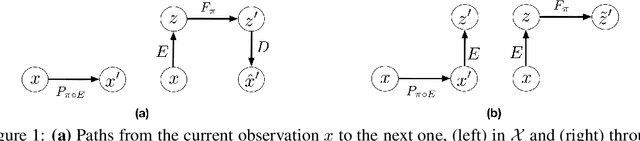

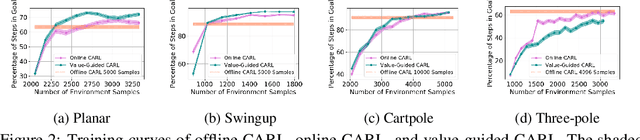
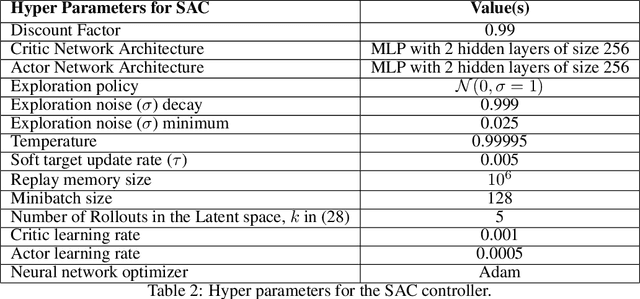
A major challenge in modern reinforcement learning (RL) is efficient control of dynamical systems from high-dimensional sensory observations. Learning controllable embedding (LCE) is a promising approach that addresses this challenge by embedding the observations into a lower-dimensional latent space, estimating the latent dynamics, and utilizing it to perform control in the latent space. Two important questions in this area are how to learn a representation that is amenable to the control problem at hand, and how to achieve an end-to-end framework for representation learning and control. In this paper, we take a few steps towards addressing these questions. We first formulate a LCE model to learn representations that are suitable to be used by a policy iteration style algorithm in the latent space. We call this model control-aware representation learning (CARL). We derive a loss function for CARL that has close connection to the prediction, consistency, and curvature (PCC) principle for representation learning. We derive three implementations of CARL. In the offline implementation, we replace the locally-linear control algorithm (e.g.,~iLQR) used by the existing LCE methods with a RL algorithm, namely model-based soft actor-critic, and show that it results in significant improvement. In online CARL, we interleave representation learning and control, and demonstrate further gain in performance. Finally, we propose value-guided CARL, a variation in which we optimize a weighted version of the CARL loss function, where the weights depend on the TD-error of the current policy. We evaluate the proposed algorithms by extensive experiments on benchmark tasks and compare them with several LCE baselines.
Stochastic Bandits with Linear Constraints
Jun 17, 2020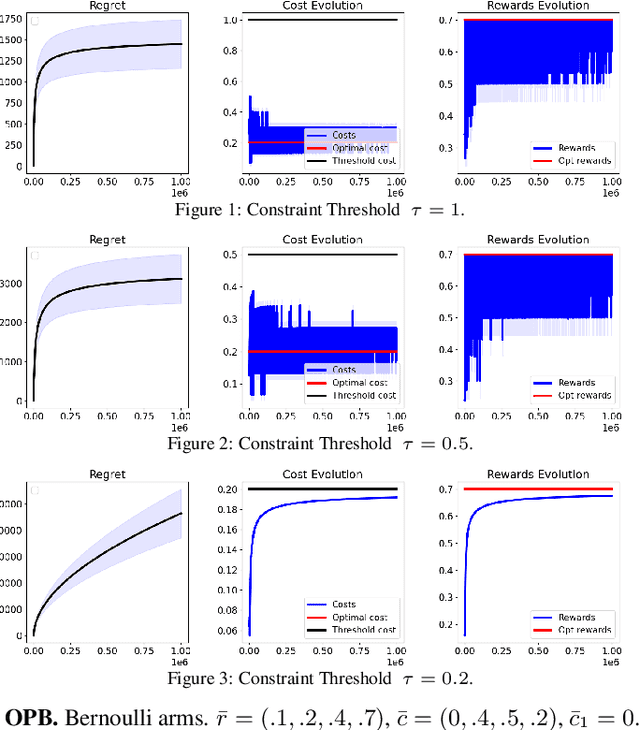
We study a constrained contextual linear bandit setting, where the goal of the agent is to produce a sequence of policies, whose expected cumulative reward over the course of $T$ rounds is maximum, and each has an expected cost below a certain threshold $\tau$. We propose an upper-confidence bound algorithm for this problem, called optimistic pessimistic linear bandit (OPLB), and prove an $\widetilde{\mathcal{O}}(\frac{d\sqrt{T}}{\tau-c_0})$ bound on its $T$-round regret, where the denominator is the difference between the constraint threshold and the cost of a known feasible action. We further specialize our results to multi-armed bandits and propose a computationally efficient algorithm for this setting. We prove a regret bound of $\widetilde{\mathcal{O}}(\frac{\sqrt{KT}}{\tau - c_0})$ for this algorithm in $K$-armed bandits, which is a $\sqrt{K}$ improvement over the regret bound we obtain by simply casting multi-armed bandits as an instance of contextual linear bandits and using the regret bound of OPLB. We also prove a lower-bound for the problem studied in the paper and provide simulations to validate our theoretical results.
Mirror Descent Policy Optimization
Jun 09, 2020

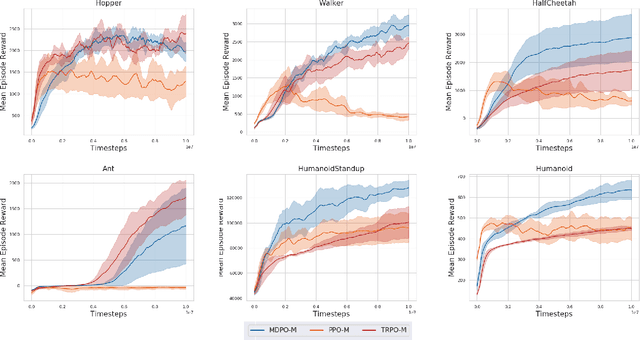
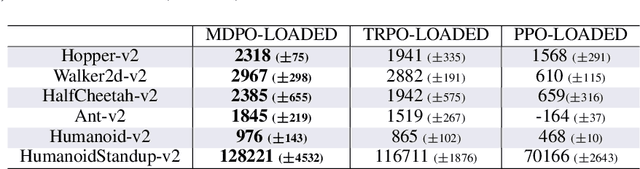
We propose deep Reinforcement Learning (RL) algorithms inspired by mirror descent, a well-known first-order trust region optimization method for solving constrained convex problems. Our approach, which we call as Mirror Descent Policy Optimization (MDPO), is based on the idea of iteratively solving a `trust-region' problem that minimizes a sum of two terms: a linearization of the objective function and a proximity term that restricts two consecutive updates to be close to each other. Following this approach we derive on-policy and off-policy variants of the MDPO algorithm and analyze their performance while emphasizing important implementation details, motivated by the existing theoretical framework. We highlight the connections between on-policy MDPO and two popular trust region RL algorithms: TRPO and PPO, and conduct a comprehensive empirical comparison of these algorithms. We then derive off-policy MDPO and compare its performance to existing approaches. Importantly, we show that the theoretical framework of MDPO can be scaled to deep RL while achieving good performance on popular benchmarks.